
こんにちは。GMOインターネットグループ株式会社の新里です。
最近はChatGPTのAPIを使った物をよく見かけるようになってきましたね。ここでは、ChatGPTのAPIを使ってニュース記事の問い合わせをしてみた内容について記載します。
ChatGPTを使うとき、APIを直接実行したりプロンプトを工夫しても良いのですが、できれば最新のニュース記事や文章を使いたくなります。
目次
何をするか?
GMOのニュース記事はRSSで配信されていました。https://www.gmo.jp/rss/
このニュース記事を使ってChatGPTに色々と聞いてみようといった感じです。
そして、質問はこの3点です。
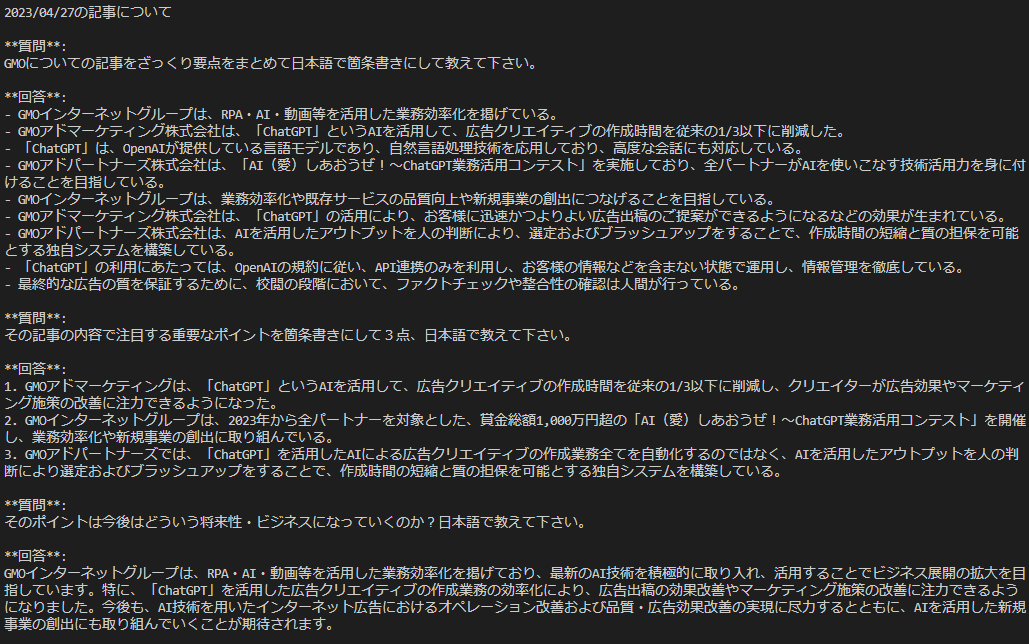
- GMOについての記事をざっくり要点をまとめて。
- その記事の内容で注目する重要なポイントを3点箇条書きにして。
- そのポイントは今後はどういう将来性・ビジネスになっていくのか?
以下は2023/04/27日のニュース記事を自社のHPに対してクローリングして、ChatGPTに問い合わせたものです。
日本語で教えて下さいと付け加えているのは、たまに英語で返事をしてくるので、「日本語で答えて下さい」と言語の指定を行っています。
毎日いろいろなニュースが配信されていて、それをチェックするのも面倒なので、まとめて教えて貰って、ニュースになった内容のサマリー・どういう将来性があるか?教えてよ!!といった感じですね。
あと、テキスト以外にもPDFのような記事を組み込んだり、ニュース以外のデータをじゃんじゃん取り込んで使うのもありですね。
コード全体
いきなりコード全体です。環境はDjangoのCommandで使います。ざっくりこんな感じのコマンドで使えるようにしておくと、バッチでslackに記事をまとめて通知みたいなこともしています。
# 記事の取得(引数に日にちで、何日前のデータか?といった感じ)
python manage.py rss_batch crawl 1
# 記事の解析結果(引数は同じ)
python manage.py rss_batch article1
コード全体は以下です。
import logging
import os
import environ
import chromadb
import feedparser
from datetime import datetime, timedelta, date
from django.conf import settings
from django.core.management.base import BaseCommand
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains import ConversationalRetrievalChain
from chromadb.config import Settings
from chromadb.utils import embedding_functions
from newspaper import Article, Config
logger = logging.getLogger(__name__)
class Command(BaseCommand):
def add_arguments(self, parser):
parser.add_argument('attrs', nargs='+', type=str)
def getcontent(self, days):
yesterday = datetime.now() - timedelta(days)
client = chromadb.Client(Settings(
chroma_db_impl="duckdb+parquet",
persist_directory=os.environ["CHROMA_DB_DIR"]
))
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key=os.environ["OPENAI_API_KEY"],
model_name="text-embedding-ada-002"
)
collection = client.get_or_create_collection(
name="langchain" + yesterday.strftime('%Y%m%d'),
embedding_function=openai_ef)
# fetch feed
rss = feedparser.parse('https://www.gmo.jp/rss/')
for item in rss.entries:
updateTime= datetime.strptime(item.published,
'%Y-%m-%d %H:%M:%S').strftime('%Y/%m/%d')
if updateTime == yesterday.strftime('%Y/%m/%d'):
try:
config = Config()
config.request_timeout = 20
website = Article(item.link, language='ja', config=config)
website.download()
website.parse()
website.nlp()
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 400,
chunk_overlap = 0,
length_function = len,
)
docs = text_splitter.create_documents([website.text],
metadatas=[{"source": item.link}])
for idx, doc in enumerate(docs):
collection.add(documents=[doc.page_content,],
metadatas=[doc.metadata,],
ids=[doc.metadata['source']+"_"+str(idx),])
except Exception as e:
logger.error(e)
continue
client.persist()
def select_day_article(self, days):
yesterday = date.today() - timedelta(days)
print (f"{yesterday.strftime('%Y/%m/%d')}の記事について")
embeddings = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=os.environ["CHROMA_DB_DIR"],
collection_name="langchain" + yesterday.strftime('%Y%m%d'),
embedding_function=embeddings)
retriever = vectordb.as_retriever()
retriever.search_kwargs['distance_metric'] = 'cos'
retriever.search_kwargs['fetch_k'] = 40
retriever.search_kwargs['maximal_marginal_relevance'] = True
retriever.search_kwargs['k'] = 8
llm = ChatOpenAI(temperature=0.7, model_name="gpt-3.5-turbo")
# llm = ChatOpenAI(temperature=0.7, model_name="gpt-4")
qa = ConversationalRetrievalChain.from_llm(llm, retriever, return_source_documents=True)
questions = ["GMOについての記事をざっくり要点をまとめて日本語で箇条書きにして教えて下さい。",
"その記事の内容で注目する重要なポイントを箇条書きにして3点、日本語で教えて下さい。",
"そのポイントは今後はどういう将来性・ビジネスになっていくのか?日本語で教えて下さい。"]
chat_history = []
for q in questions:
result = qa({"question": q, "chat_history": chat_history})
chat_history.append((q, result['answer']))
print(f"**質問**: \n{q} \n")
print(f"**回答**: \n{result['answer']} \n")
def handle(self, *args, **options):
env = environ.Env()
env.read_env(os.path.join(settings.BASE_DIR, ".env"))
os.environ["OPENAI_API_KEY"] = os.environ["OPENAI_API_KEY"]
attrs = options['attrs']
if attrs[0] == "crawl":
self.getcontent(int(attrs[1]))
elif attrs[0] == "article":
self.select_day_article(int(attrs[1]))必要なモジュールは以下です。
pip install chromadb feedparser langchain newspaper
ざっくり内容の説明
流れは非常に簡単です。
■ データの取得
・RSSフィードからデータを取得してくる(feedparser)
・特定の日の記事から本文を取得してくる(newspaper)
・ベクトル化する(text-embedding-ada-002)
・ベクタストアにデータとして保存する(chroma)
■ Chat GPTとのやりとり
・ベクタストアの設定をする(chroma)
・ベクタストア経由でOpenAIに質問をする(ConversationalRetrievalChain)
ここではGMOのRSSフィードからデータを取り込んで、Chromaに日付付きのコレクション名で保存していますが、他のRSSフィードやデータを別々のコレクションに取り込んでおくのもありですね。
また、LangChainが強力に使えるので、積極的に使っているところです。OpenAI SDKのAPIを直接実行するのも良いですが、問い合わせのモデルが充実しているのでLangChainは非常に便利ですね。
ただ、ポイントになるのは “retriever.search_kwargs” の近隣探索をしている所になりそうです。L2/L1/max/cos/dot(デフォルトはL2ノルム)といった方法、MMRに送るドキュメント数の調整、そして最終的な探索数(k=8)を多くするとGPTの文字数制限でエラーが起きたりするので要調整になりますね。
ChatGPT UIに組み込んでみる
ChatGPTライクなUIを開発しているchatbot-uiにサクッと組み込んでました。自由な問い合わせでWeb UIで使えるので、これはこれで便利な感じになりますね。
そして、同じくDjangoをバックエンドにして、ニュースで公開されているPDFの記事を組み込んでみました。chatbot-ui(フロントエンド)はNext.jsで作られていました。
「GMOとくとくBBに関係した最近のニュースを教えてちょ」と聞いています。
GPT-3.5、GPT-4(32K)、PDFなどの文章、ニュース記事でモデルを切り替えて使えるのでカスタマイズした問い合わせを色々と並べて使ったりしても良いかもです。
参考
色々と作りにあたって参考にさせて頂いた記事を紹介しておきます。
LangChain
話題の ChatGPT + LangChain で ChatGPT が学習していない最新の OSS ソースコードを爆速でウォークスルーする
ChatGPT風の画面を表示できるChatbot UIをFastAPIで作成した自作LangChainサーバに接続させる方法
ブログの著者欄
新里 祐教
GMOインターネットグループ株式会社
プログラマー。GMOインターネットグループにて開発案件・新規事業開発に携わる。またオープンソースの開発や色々なアイデアを形にして展示をするなどの活動を行っている。
採用情報

関連記事
-

【中編】Hack-1グランプリ2026 デモデーレポート|ついにグランプリ決定!最優秀賞チームに開発秘話を聞く
デザイン
-

【前編】Hack-1グランプリ2026 デモデーレポート|AI時代の学生ハッカソンに圧倒される2日間。「小さくなる日本」をどう表現する?
デザイン
-

【インタビュー後編】育休明けに直面した「AI時代」 GMOペパボのプリンシパルデザイナー・佐藤咲が歩む「共創」の道
デザイン
-

【後編】エージェンティックAIの「アウトプット品質安定化」を実現 GMOインターネットが実践する「ハーネスエンジニアリング」とは?ーEngineering Journey
技術情報
-

ハーネスエンジニアリングの本質 ー従来の開発規律を、エージェントが回せるように再設計する
技術情報
-

【前編】エージェンティックAIの「アウトプット品質安定化」を実現 GMOインターネットが実践する「ハーネスエンジニアリング」とは?ーEngineering Journey
技術情報

KEYWORD
CATEGORY
-
技術情報(590)
-
イベント(235)
-
カルチャー(59)
-
デザイン(67)
TAG
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI TALK
- AI 機械学習強化学習
- AI/機械学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI活用事例
- AI駆動
- AMD
- APT攻撃
- AWX
- Behind the Scenes
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- ConoHaVPS
- CS
- CSS
- CTF
- DC
- Designship
- Desiner
- developer
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- engineering
- Engineering Journey
- eVTOL
- expert
- EXPERT CROSS
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOインターネットグループ陸上部 – GMOロボッツ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- Good Morning
- GPU
- GPUクラウド
- GTB
- Hack-1グランプリ
- Hack‐1グランプリ
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- Japan Drone
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- エージェンティックAI
- オブジェクト指向
- オンボーディング
- お名前.com
- クリエイター
- クリエイターインタビュー
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ハーネスエンジニアリング
- バックエンド
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- フロントエンド
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- ロボティクス
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 技術書典20
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 映像制作
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 空飛ぶクルマ
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-

【後編】デザイナーとしての自分を形作る「気合と反復」。対話を通じて実践する、豊田恵二郎の制作哲学
デザイン
-

【前編】創業時から変わらない「一貫性」で業界をリード GMO Flatt Security CCO・豊田恵二郎が語る、「エンジニアの背中を預かる」姿勢
デザイン
-

【第2回・AI TALK】GMOサイバーセキュリティ byイエラエ・三村 聡志さんに聞く、AI時代の攻撃と防御のいま
技術情報
-
【中編】Hack-1グランプリ2026 デモデーレポート|ついにグランプリ決定!最優秀賞チームに開発秘話を聞く
デザイン
-
【前編】Hack-1グランプリ2026 デモデーレポート|AI時代の学生ハッカソンに圧倒される2日間。「小さくなる日本」をどう表現する?
デザイン
-

【Expert Cross #1】“人生2周目”のエキスパートが挑む、「つながり」の構築と認知拡大
技術情報
採用情報

SNS FOLLOW
