
本記事では、2021年5月23日にGMOインターネットのエンジニアが登壇した、「お名前.comにおける長続きさせるバックエンド側の開発・保守について」のセッション内容をお届けいたします。
目次
はじめに
このセッションでは、20年以上運用している「お名前.com」のレガシーな大規模システムのバックエンドに日々どう向き合って、開発・保守を行い改善させているかを記します。
日々、レガシーシステムと向き合い奮闘されている方のお役に立てたら幸いです。
お名前.comの紹介
まず、お名前.comの紹介をいたします。

お名前.comは、国内最大級のドメイン公式登録サービスで、.com .net .jpドメインなど、580種類以上のドメイン取得が可能です。
日本初の公式レジストラーとして1999年にサービス開始しています。
どのような時代かといえば、同年にでてきたものは、ユーロ(通貨)、i-mode、ADSL、Bluetoothなどがあります。
お名前.comは1999年、22年前にサービスを開始していることは、先に説明したとおり、この時代のJavaどうだったのでしょうか?
当時のJavaのバージョンは、JDK1.2でした。今はJava16です。
とても古いバージョンであることは明白ですね。
J2SEに正規表現の実装がなかったり、ジェネリクスがなかったりでした。
そして、開発環境のEclipseは普及しておりませんでした。
お名前.comのバックエンドは、2001年からJavaを採用しています。
ちなみに、2001年以前のお名前.comのバックエンドは、Perlで実装されていました。
そして、お名前.comバックエンド技術仕様変遷(2001~)は次のとおりです。
Java
JDK1.3 ⇒ 1.4 ⇒ 1.5 ⇒ 1.7 ⇒ 1.8 ⇒ Open JDK11
文字コード
Shift-JIS ⇒ UTF-8
バージョン管理
CVS ⇒ SVN ⇒ Git
ビルドツール
Ant ⇒ Gradle
フレームワーク
なし ⇒ Struts1 ⇒ Struts2 ⇒ SpringMVC4
CI/CD
なし ⇒ Jenkins ⇒ Algo
コンテナ
なし ⇒ コンテナ(Docker K8s)
ご覧のように、少なくない技術仕様変遷をたどっていっています。そして、修正・変更時の技術・アーキテクチャにあわせて継ぎはぎで、修正・変更されていってましした。すると…当たり前ですが、レガシーになっていたのです。
レガシーシステムとは
そもそも、レガシーシステムとはなんでしょうか?Wikipediaによりますと、次のように記載されています。
レガシーシステムとは、
主にコンピュータの分野で、
代替すべき新しい技術などのために
古くなったコンピュータの
システムや技術などのことである。
上記でご説明した通り、お名前.comはレガシーとなっており、以下のように@SuppressWarningsと警告メッセージは、積もっていました。


レガシーシステムにどのように向き合っているのか
お名前.comバックエンドの概要
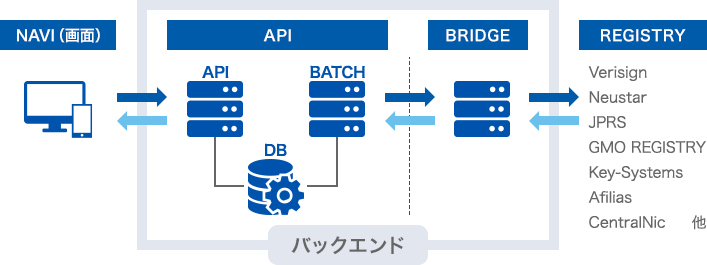
まず、お名前.comのバックエンドのシステム構成について説明いたします。
お名前.comのバックエンドは、画面側から呼ばれるAPI群で、その内訳は、リアルタイムに呼ばれて処理するAPI、定期的に処理するBATCH。
そして、API、BATCHからデータを参照・更新するデータストアのDB。
それと、実際のドメインを管理するレジストリとのやりとりをするBRIDGEで構成されています。
APIと画面は分かれているのは、メンテナンス中でAPI利用不可の状態でも、WEBページは表示でき、PC・スマホ マルチプラットフォーム開発を容易にするためで、APIとBRIDGEは分かれているのは、レジストリごとに通信における約束事(仕様)が異なるため、BRIDGEを分けることでレジストリごと仕様の違いを吸収するためです。
日々の業務でしていること
次に、日々の業務でしていることを説明いたします。
日々の業務でしていること、業務内容に伴う悩ます問題は以下の2つです。

そして、20年以上続いているシステムなので、多機能な大規模システムなのはもちろん、先に説明したとおり、長年、修正・変更時の技術・アーキテクチャにあわせて継ぎはぎされていますので、実際に作業するときには、影響箇所がないか、膨大な量のプログラムを確認して、数々の困難を乗り越えて変更 or 不具合修正を完了させて、リリースさせます。
作業が大変なのはもちろんですが、リリースしても不具合が発生することあります。
日々悩ます問題
難易度が高く作業工数がかかる
日々悩ます問題の1つめの「難易度が高く作業工数がかかる」から掘り下げていきます。
なぜ難易度が高く、作業工数がかかるのかといいますと、上記の通りプログラムが修正・変更時の技術・アーキテクチャにあわせて継ぎはぎされており、既存のプログラムの内容を読み解くのが困難なためです。
いくつか例を用いて説明いたします。
例1:最新のJavaのAPI、文法で統一されていない
Javaジェネリクス実装前後に改修したプログラムで、ジェネリクスの有無の差異があります。ジェネリクスのないプログラムだと、オブジェクトの型がわかりません。実際の処理の箇所を確認しないとどの型かわからなので、読み解くのが容易ではありません。
/** List of Domain */
private List domain = new ArrayList();
private Set accountServices = new HashSet();
private Set defaultContacts = new HashSet(); /** ResultHeader格納リスト */
private List<ResultHeader> results = new ArrayList<ResultHeader>();
/** Service(API)のレスポンスをMapに変換した結果を全て格納 */
private Map<String, Object> option = new HashMap<String, Object>();
private Map<String, List> optionList = new HashMap<String, List>();例2:機能によっては使用しているORマッパーが違うものがあるので
プログラムの変更がある場合に、ORマッパーごとに適切な対応が必要
private static HbmDomainBean getActiveDomainBean(Sql sql, String domainName) {
return (HbmDomainBean) sql.createCriteria(HbmDomainBean.class)
.createAlias(*****)
.add(Restrictions.eq(*****))
.add(Restrictions.eq(*****))
.add(Restrictions.eq(*****))
.addOrder(Order.desc(*****))
.uniqueResult();
} public List<Domain> findByActiveDomainName(String domainName) {
return domainJpaRepository
.findByActiveDomainName(domainName)
.stream()
.filter(Objects::nonNull)
.map(DomainEntity::toDomain)
.collect(Collectors.toList());
}例3:新旧の構文が入り混じっている(添え字有のfor文、添え字無のfor文)
些細なことかも知れませんが、コードのレベルが統一されてないので、読み解いて変更するには地味に負荷がかかります。
for (int i = 0; i < ns.size(); i++) {
updatensArray[i] = ((HostBean) ns.get(i)).getHostName();
} for( HbmGmoponMappingBean hbmGmoponMappingBean : hbmGmoponMappingBeanList ){
hbmGmoponMappingBean.setDelflg(1);
sql.update(hbmGmoponMappingBean);
}例4:以前に採用していたフレームワークに依存するネーミングが残っている
お名前.comが以前に採用していたフレームワークはStrutsで、現在は、Springなのですが、Strutsに依存するAction、Formとかのネーミング残っています。
Strutsを知っている人は、Action、Formなどのネーミングが何の役割をもつかピンときますが、Springしか知らない人は、Action、Formとネーミングされているプログラムはどの役割かわかりかねますよね。
これもプログラマーを悩ます要因です。
public class DnssecUpdateAction extends ApiActionBase implements DnssecModelForm, SingleMarker {public interface DomainBaseModelForm extends ModelForm {例5:機能に適しているアーキテクチャ・技術でなく、時代ごとに合わせたものになっている
時代ごとに、技術だけでなく、アーキテクチャも変わっていて、OOPだったり、DI+AOPだったり、バラバラです。
近年に実装されたものは、次のようなAOPが実装されていますが、昔に実装されているものはOOPのみだったりで、プログラムを読み解くのが困難です。
@SuppressWarnings("serial")
public abstract class DesInterceptorBase implements HandlerInterceptor {
protected static final Logger logger = LogManager.getLogger(LogConstants.LOG4J_APP);
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
}
@SuppressWarnings({ "rawtypes", "unchecked" })
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
これらの例から、要因として「技術負債」があることがわかりました。
相次ぐ想定してない不具合発生
次に日々悩ます問題の2つめは「相次ぐ想定してない不具合発生」です。
なぜ、想定してない不具合が発生する?かといいますと、20年以上続いている多機能な大規模システムゆえ、全てを把握するのは困難で適切な対処を行うのが難しいためです。
日々を悩ます問題1つめので記した通り、プログラムを確認しても既存の実装の意図が読み解けない独自仕様なので答えを見つけるのが容易ではありません。
また、仕様の内容は口頭でのみで伝わってた箇所があったり、古いものに関しては誰も知らないパターンもあったりします。
要因としては「仕様把握の属人化」です。
ここまでで記した日々悩ます問題の2つをどう施策したか説明いたします。
日々悩ます問題の施策
技術負債
まず、日々悩ます問題の1つめの「技術負債」ですが、よく聞く施策案として、リプレース、リファクタすればいいのでは?というのがあります。
リプレースした機能があると、その部分は一時はレガシーでなくなります。
でも時間がたつと、いずれレガシーになります。
こつこつリファクタが必要、且つ量が膨大であることを鑑みると、あまり現実的ではありません。なので、解決ではなく断続的な対応が必要と考えました。
また、リプレースしても人によって、実装が偏ってオレオレ実装になることと、コードレビューしても、レビューアに偏るチェックになる可能性があります。
こちらについては、実装・コードレビューを俯瞰したチェックが必要と考えました。
以上のことから、「技術負債」については、コードレビューだけでは仕様を俯瞰して確認できないと判断しました。
- 視野の狭い対処を抑止する
- コードの偏りを緩和させ、可読性向上させる
上記2点を踏まえ、対策として「仕様レビュー」を実施することにしました。
仕様把握が属人化
日々悩ます問題の2つめの「仕様把握が属人化」は、よく聞く施策案として「ドキュメントを整備」「仕様はソース、ドキュメントを見ましょう」というのがあげられます。
ドキュメントを整備は、ソフトウェア開発を行うにあたって必ずしているはずです。ですが、22年も続いていると不足分や不整合が積もっていても不思議ではありません。また「仕様はソース、ドキュメントを見ましょう」は正論ですが、実装に関わってないと、理解が困難なので慣れが必要になります。
以上のことを踏まえ、対策として「タスク共有会」を実施することにしました。日々悩ます問題と施策をまとめると次のとおりです。

日々悩ます問題の施策詳細
日々悩ます問題を解消するために行っている施策の詳細をお伝えしていきます。
仕様レビュー
まず、技術負債の対策として実施した「仕様レビューをする」についてです。
基本的に、チャットツールでやりとりを行い、期限はだいたい2・3日で進めています。そして、コードレビューは変更箇所に限った確認になりがちなので、仕様を俯瞰して確認するようにする。
どのようにしているかといいますと、レビューアだけでなく、複数人から意見をいただくようにし、実装の偏りがないようにしています。
実際に行ってみますと、設計のノウハウ・エンジニアの底上げができ、複数人からの意見があるので、実装の偏りがなくなるようになりました。
だいたい意見が別れるので、最後は多数決で進めるようにしています。
タスク共有会
次に仕様把握の属人化の対策として実施した「タスク共有会」です。
定期的に業務の勉強会や情報共有をし、属人化解消しました。
特定の人しか知らない状況をなくし、リスクを分散することを目的としています。実際に気をつけていることは以下です。
- ドキュメントに記載が不足していた仕様が発覚したら、ドキュメントは更新する
- 大きな機能の変更があった場合は出来る限り開催し、メンバーが知らない状況を作らない
まとめ
最後にまとめです。
ここまでレガシーシステムにどう向き合っているかお話ししました。
そして、日々悩ます問題として「技術負債」「仕様把握が属人化」の2つ要因がありました。その施策として、仕様を俯瞰できコードの偏りを緩和する「仕様レビュー」、属人化解消のための「タスク共有会」を行うようにしました。
ただ、これで全て解消できているわけではありません。
今後の課題として、技術・アーキテクチャの統一されていないプログラムは、コツコツリファクタするしかないように考えていますが、チームとしてどう対処しようか検討しています。まだまだレガシーとの挑戦は続きます。
本エントリーが、レガシーと戦うエンジニアのみなさまの一助となれば幸いです。
ブログの著者欄
小林 隆晴
GMOインターネットグループ株式会社
2018年11月GMOインターネットグループ株式会社に入社。 システム統括本部アプリケーション開発本部ドメイン開発部ドメインプロダクトチーム所属 主にお名前.comのドメインのバックエンドの運用・保守・開発に携わっています。
採用情報


関連記事







KEYWORD
CATEGORY
-
技術情報(589)
-
イベント(233)
-
カルチャー(57)
-
デザイン(65)
TAG
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI TALK
- AI 機械学習強化学習
- AI/機械学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI活用事例
- AI駆動
- AMD
- APT攻撃
- AWX
- Behind the Scenes
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- ConoHaVPS
- CS
- CSS
- CTF
- DC
- Designship
- Desiner
- developer
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- engineering
- Engineering Journey
- eVTOL
- EXPERT CROSS
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOインターネットグループ陸上部 – GMOロボッツ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- Good Morning
- GPU
- GPUクラウド
- GTB
- Hack-1グランプリ
- Hack‐1グランプリ
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- Japan Drone
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- エージェンティックAI
- オブジェクト指向
- オンボーディング
- お名前.com
- クリエイター
- クリエイターインタビュー
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ハーネスエンジニアリング
- バックエンド
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- フロントエンド
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- ロボティクス
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 技術書典20
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 映像制作
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 空飛ぶクルマ
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-

【中編】Hack-1グランプリ2026 デモデーレポート|ついにグランプリ決定!最優秀賞チームに開発秘話を聞く
デザイン
-

【前編】Hack-1グランプリ2026 デモデーレポート|AI時代の学生ハッカソンに圧倒される2日間。「小さくなる日本」をどう表現する?
デザイン
-

【Expert Cross #1】“人生2周目”のエキスパートが挑む、「つながり」の構築と認知拡大
技術情報
-

【第1回・AI TALK】SUZURI・minne事業部CTO 黒瀧さんに聞く、AI活用の現在地と未来
技術情報
-

【Hack-1グランプリ2026 キックオフレポート】約150名の学生がハイブリッド形式で集結
イベント
-

【インタビュー後編】育休明けに直面した「AI時代」 GMOペパボのプリンシパルデザイナー・佐藤咲が歩む「共創」の道
デザイン
採用情報
SNS FOLLOW
