
こんにちは。新里です。
日本科学未来館でロボットを使った実証実験を行ってきました。対話を行い、案内〜移動するロボットを実際に来館者がいる中で行うというのは、「対話というコミュニケーション」「人流がある中でのロボットの移動」をはじめとして、非常に多くの学びがありました。ここでは、実証実験の技術的な要素や実装、うまくいかなかった点・学びがあった点について少しばかし記載します。
目次
実証実験の内容
日本科学未来館の展示フロアを自律移動しながら、来館者と対話を行い、展示解説から館内案内までを多言語(日英中韓)で行う対話型AIロボットの実証実験を行いました。
来館者との対話はAIが行って、移動はもちろん自律移動です。
展示フロアは日本科学未来館5Fのプラネタリークライシスの常設展示のエリアを利用させて頂きました。開催概要はこちらに記載してあります。

いわゆる案内ロボットです。IT技術に慣れ親しんだ方なら「ロボットと話をして、欲しい情報や気付きを与えてくれて(展示の説明をしてくれて)、行きたい所に案内してくれる」というのが容易に想像できるでしょう。いつでも声をかけられるロボット・スタッフ(科学コミュニケーター)が興味に合わせて展示を解説し、案内してほしい場所まで一緒に連れて行ってくれる体験・技術検証を行いました。
ロボットと対話
まず最初に案内するロボットと来館者との対話というのは、次の図のような、来館者からの質問や話題に対応するといった事が考えられます。この来館者との対話の内容は、日本未来科学館の情報・展示フロアの情報・展示パネルに基づく情報を利用しているため(RAG:Retrieval Augmented Generation)、展示内容に関連した内容での対話になります。
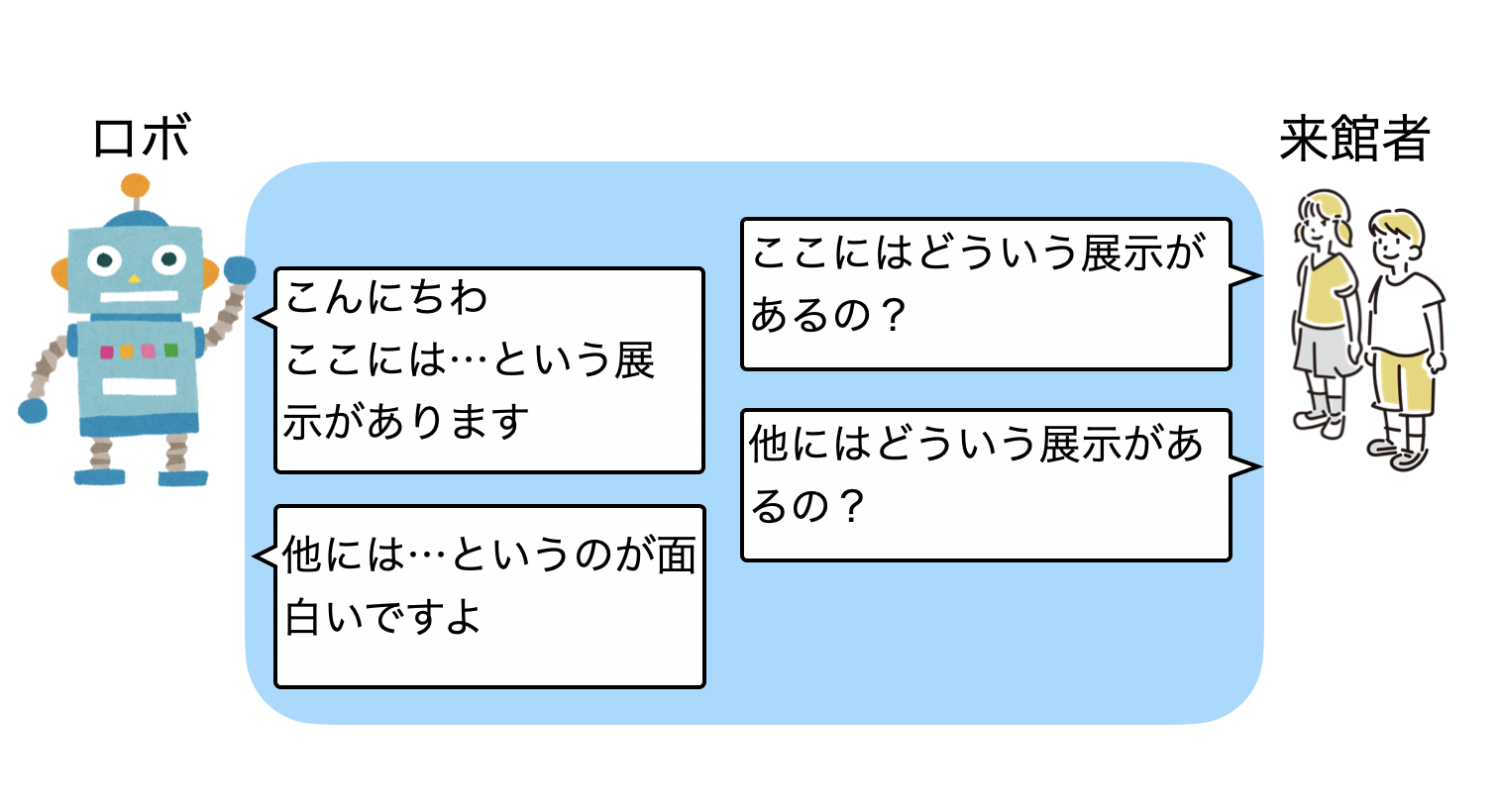
ロボットからの対話
来館者からの話かけ以外にも、ロボットが近くの来館者を検知したら、ロボットの方から来館者に話かけます。来館者の方から知らないヒト(ロボット)に話かけるのは、ハードルが高いですね。そこで、ロボットの方から話しかけることで、コミュニケーションのきっかけを作ることにしました。
またフロアの展示情報をRAGのデータとして持っているので、ロボットが対話の中から「この展示・パネルに移動して案内する」という事も考えられます。
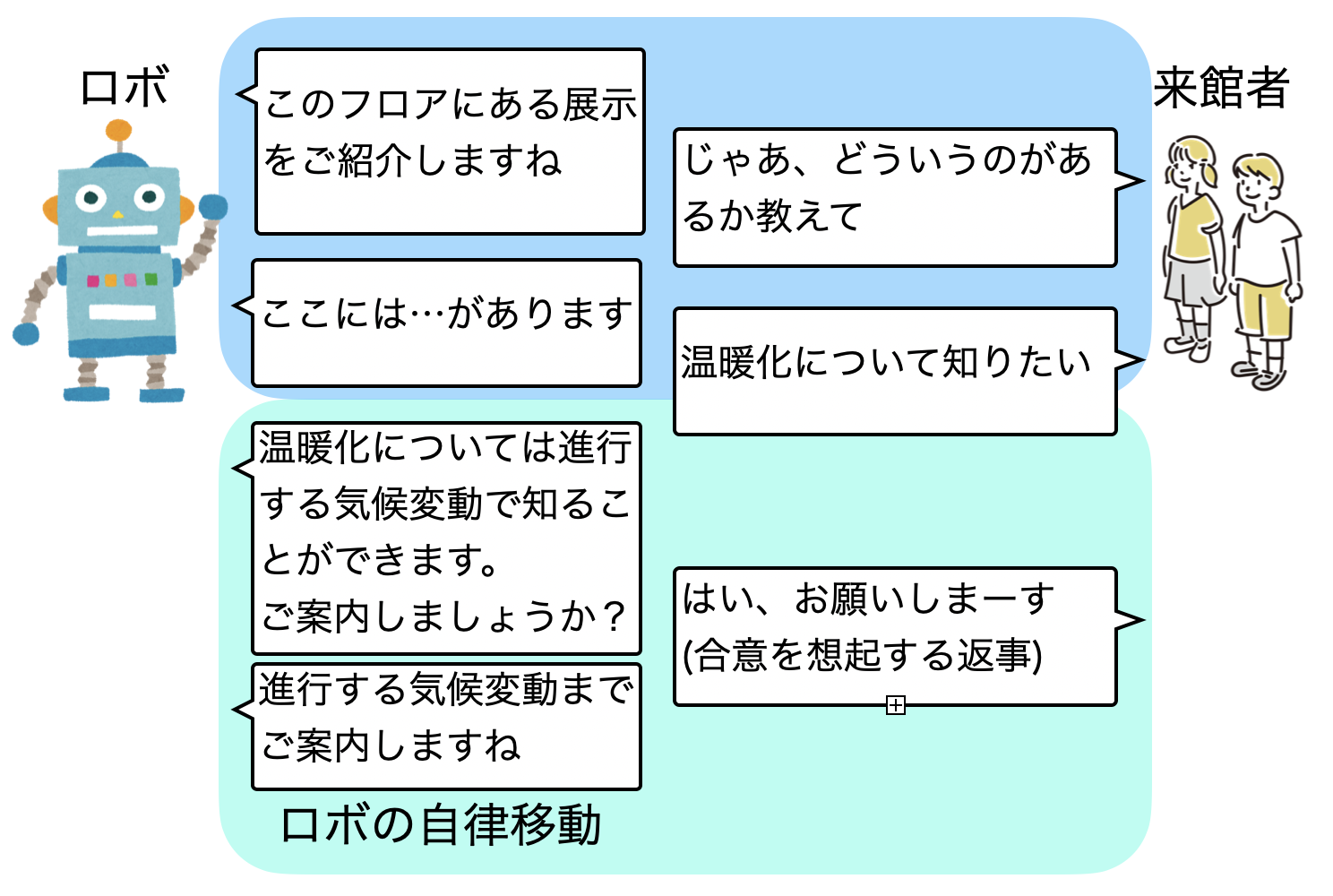
実装する時に議論を行ったのが、以下の図のように「温暖化について知りたい」というとき、最も関連する「進行する気候変動」という場所(POI:Point of Interest)を案内することになりますが、いきなり移動・案内するべきかどうか?ということでした。
いきなり移動案内するより、3 Way handshakeのように合意形成が行われてから移動するのが自然です。そこで、合意に相当するような自然言語での返事があったら、ロボットを移動案内させるようにしました。以下の例では、「はい、おねがいしまーす」が合意となっていますが、「よろしくちゃん」「じゃ、お願い」といった感じでも合意されたものとして処理しています。
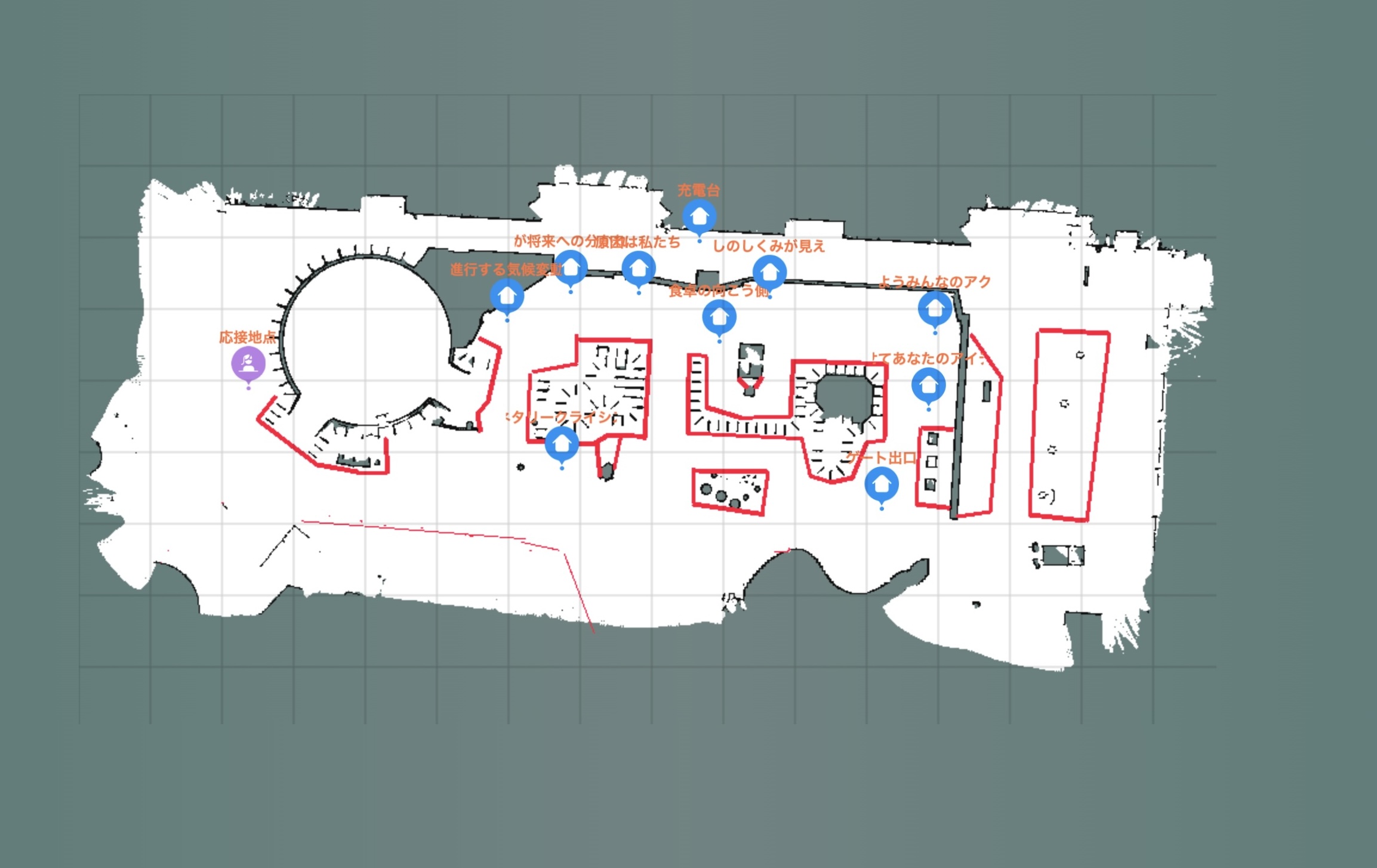
ロボットの移動には、地図と移動先のPOI情報が必要なので、実証実験を行うフロアの地図を事前に作成しています。以下の図は実証実験を行ったプラネタリークライシスのフロアマップです。赤線は侵入禁止エリアで、青色がPOI・展示パネルがある場所ですね。位置情報はAI側と共有して、来館者との対話の中から移動案内を行うといった感じです。
位置情報と対話
ロボットは自分の位置情報(XY)、地点(POI)に居るか?を常に把握しています。位置情報を持つことで、来館者がそのパネルの前に居るときの応答も変わってきます。
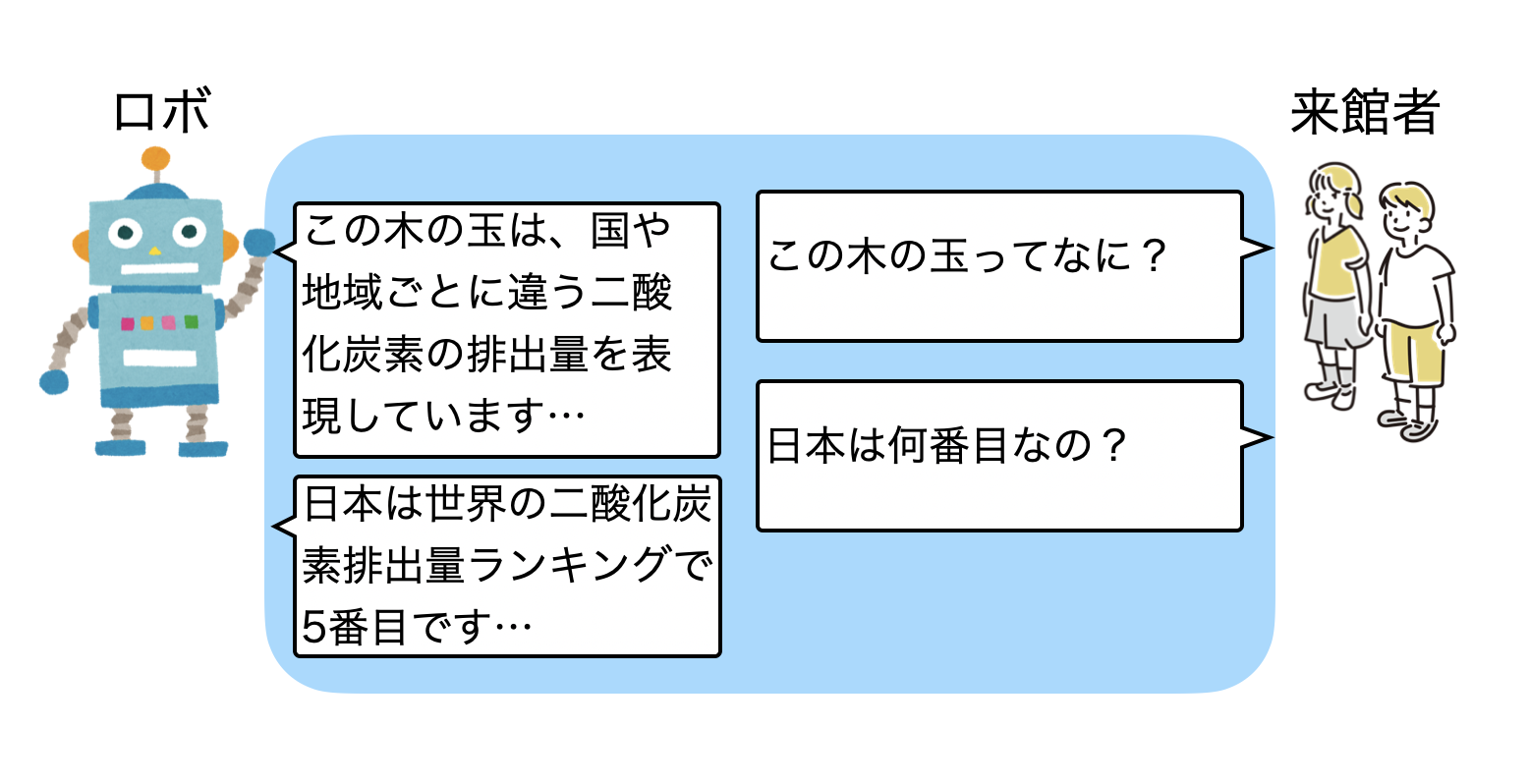
例えば、以下のようにプラネタリークライシス内にある「原因は私たち」にロボットが居るとき、「この木の玉ってなに?」「どこ産の木なの?」といった事をロボットに聞くと、「原因は私たち」でのデータに基づいた内容で対話することが出来ます。
「日本は何番目なの?」といった抽象的な質問に対しても、この場所に関連した応答に変わるというわけです。

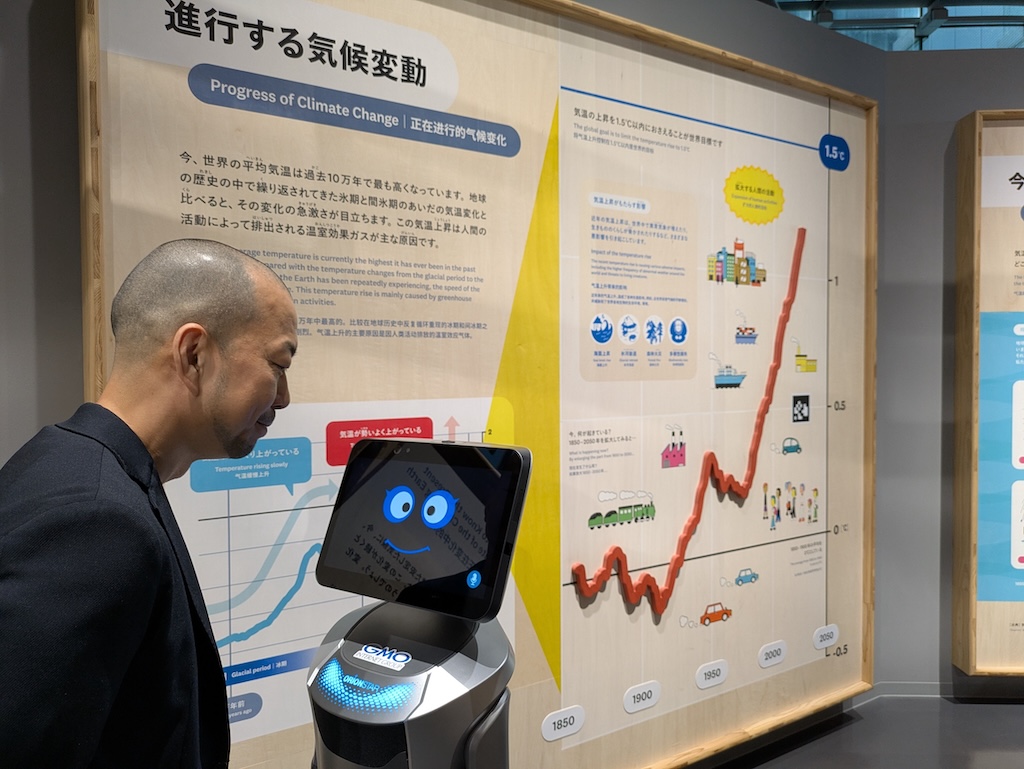
他にも、「変動する気候変動」にロボットが居るとき、「この赤いギザギザってなに?」(温度変化のグラフ)という抽象的な質問や、「これって触ってみてもいいの?」といった展示されている物の扱いなども、展示内容に合わせて対話することができるようになっています。
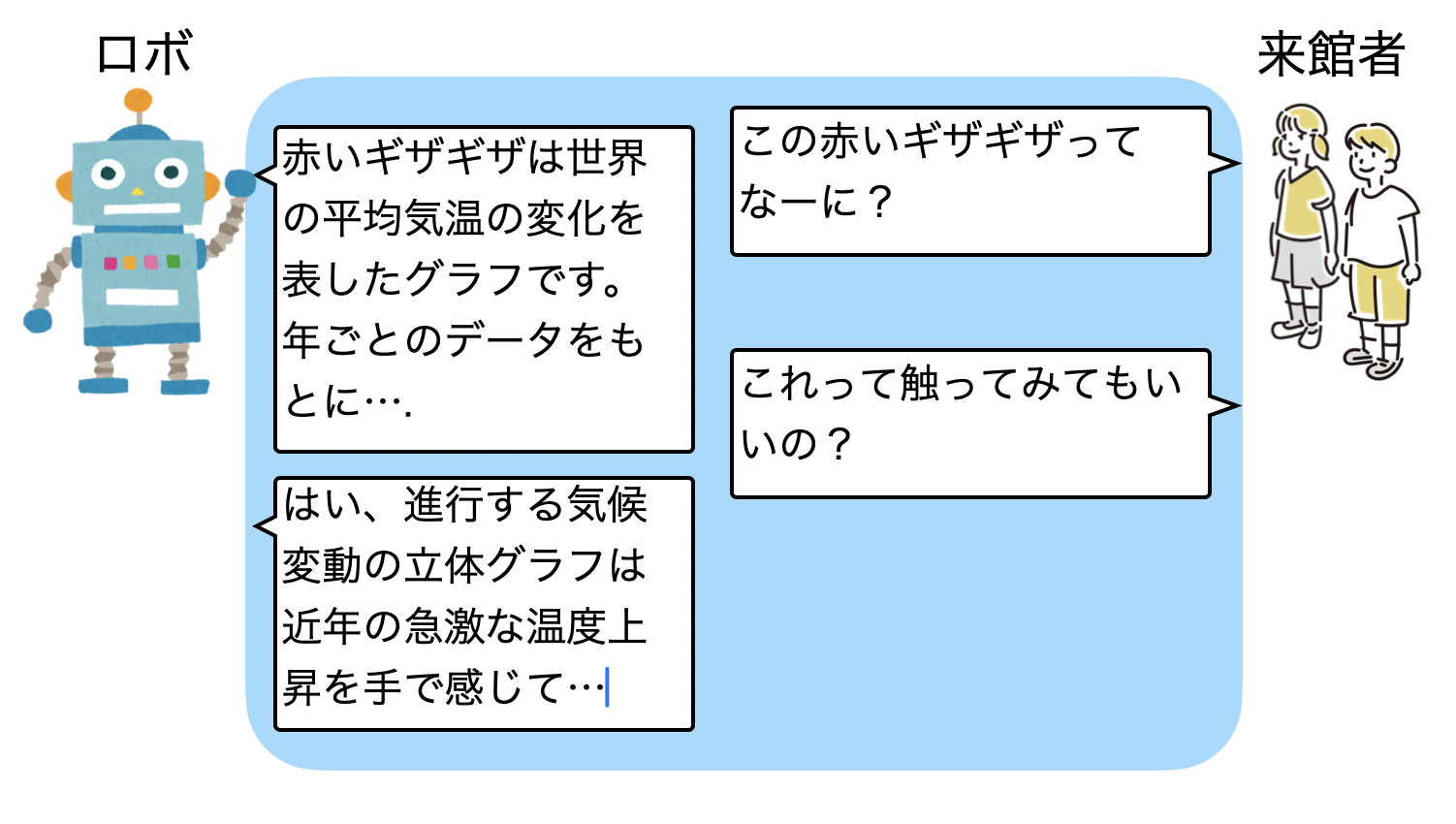
その他の対話
他にもロボットと来館者の対話・案内をさせるために、色々な機能を入れています。
■ 巡回
ロボットは周辺に居る来館者を認識して話かけますが、近くに来館者が居ない・誰もロボットに話かけない事が想定されます。そこで、ある一定時間・同じ場所に居て何もアクションが無かった場合、他の場所に移動して来館者を探しに行きます。
■ ツアー
初めて展示エリアに来た来館者が、全体的に順路立てて説明・対話を行えるように、パネルを順番に説明・対話を行って移動する機能を付けています。
他にも対話を行うときの文字列長の調整(長い説明だと止めたくなる、短い説明だと物足りない)、ロボットと対話するときの待ち時間・待ち時間中の処理(音を流すことで考慮中という表現にする)、対話する来館者の音声を拾えるようにロボット正面へのマイク指向性をもたせる、など、来館者とAIロボットが円滑に対話するために、非常に多くのことを考慮する必要がありました。それらは後述する、「多くの気づき」で記しておきます。
ロボットの実装
今回の実証実験ではOrionstar NOVAをロボットとして利用しました。AI 部分はGMO自社でデータ整備から行って、ロボットのアプリケーションもスクラッチで実装したので、ロボット筐体として利用した事にはなります。
午前・午後の計4時間動作させて、フル充電から60%ほどの消費されたので、移動・対話などを行って10%/時間 と見ておいて良さそうだと感じました。

対話を行う顔
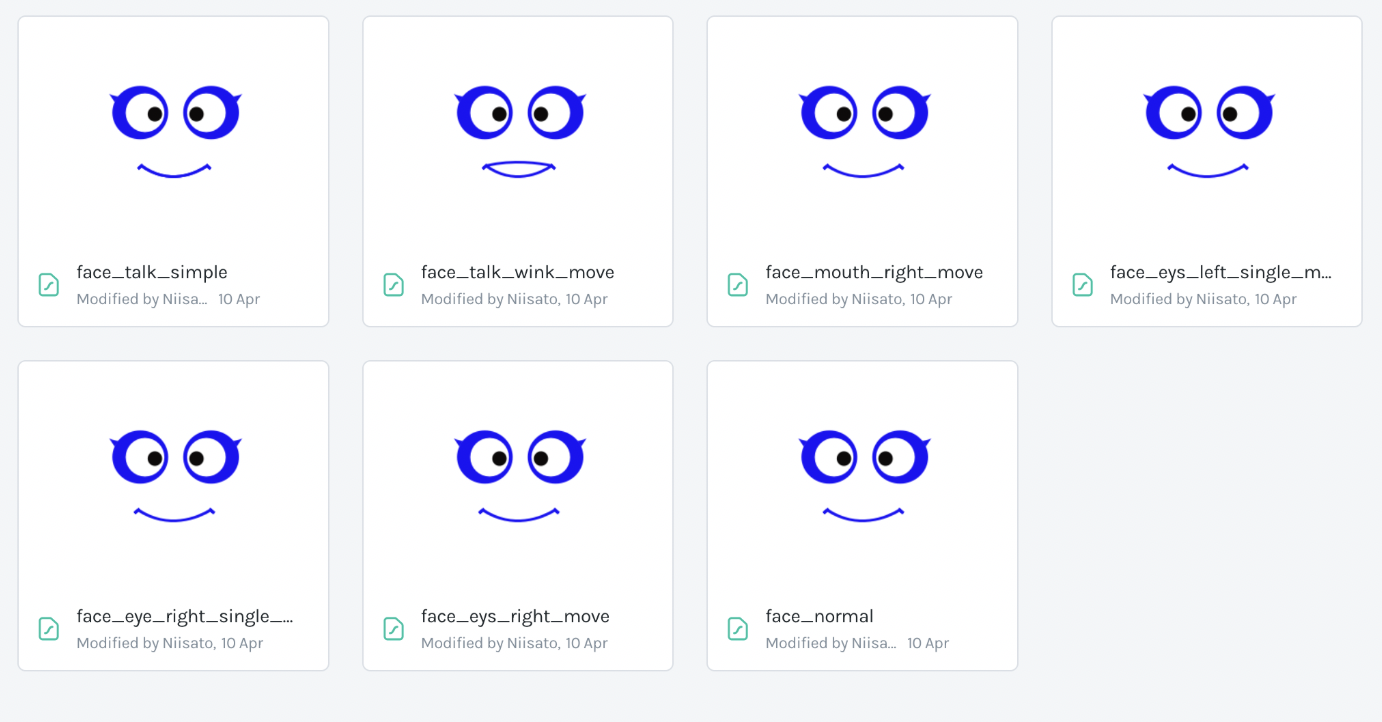
画面にはシンプルな顔を表示するようにしました。何もしていないときの表情をFigma・Lottieで基本構成を作成してJSON化して組み込んでいます。表情は5種類の通常パターンと、対話時は口を動かす2種類を利用しています。
ヒトの感情一覧、ロボットとの対話における感情表現のパターンについての研究などもあります。シンプルな目と口だけで恐怖・嫌悪・怒り・悲しみについて除去して、喜び・驚き・平穏・興味だけで話をしている時も、通常とウィンクをする驚きという種類で用意してみました。
実際の対話画面は現状も含め、どういう表現が良いのか?というのは模索中です。例えば、以下が実際の対話時の画面ですが、ポイントは…
・音声認識した文字列を左下に表示
・AI からの応答待ちでThinking Bubbleを表示
・対話ボタンを右下に用意
■ 音声認識した文字列を左下に表示
多言語でのSTT(STT : Speech To Text)は必ずしも正確ではありません。結構な言語推定ミスも発生しました。話した音声から話者の言語を推定して、テキストにしていますが、必ずしも話者の音声を正しく文字に出来るとは限らないため、左下に実際に話したテキストを表示させるようにしています。
■ AI からの応答待ちでThinking Bubbleを表示
AI からの応答は即時完結するわけでは無く、応答待ちが発生します。なるべく高速に処理するようにしていますが、利用環境のネットワーク状態にも依存して待ち時間は発生します。そのため、Thinking Bubbleを表示して場をつなぐようにしてみました。
■ 対話ボタンを右下に用意
そして、対話ボタンです。
多くの開発者は自動音声認識(Speech to Text)を行って対話を行えばいいだろう?と思うでしょう。僕もそうでした。最初に実装した時は対話ボタンはありませんでした。自動音声認識で1対1の対話環境なら問題ないでしょう。しかし、実際の現場で不特定多数の環境では無理がありました。
一般的な不特定多数の来館者が行き交う環境において、リアルタイム声紋トラッキングSTT(話者ダイアライぜーションによるSTTが、不特定多数の来館者が行き交う環境で、高い精度で実現できれば素敵ですが…)でも無い限り、話かける音声の混在・話者のタイミングで自動音声認識は難しかったです。ロボットのマイクの指向性を正面に向かせて、なるべく正面からの対話で音を拾うようにしたり、環境ノイズ除去などを行いましたが、不特定多数の音声・ノイズ・言葉が混じってマイクで拾ってしまう環境で、どうやってロボット対話している来館者を特定してSTTを高精度に実現出来るのか?というのは課題のひとつです。(無音検出・文節の区切りなど、どこまで話している?という処理も含めて)
そこで、ボタンを用意してロボットに話かける来館者は、マイクボタンを押して話をして貰うという事になりました。

AI でコード生成をガンガン使った
途中から僕、コードをほぼ書いていません。
生成AI・Agent を使いまくりました。
「AI がロボットのコードを書いて、来館者を案内をする」というのを想像したら、使わないわけにはいかないですね。また全範囲的に生成AI・Agentを使ったロボット・プログラミングの実装で、どういう影響・信頼性が保てるか?というのを検証する意味もあります。
ちなみに、コード以外にもLottieのJSONデザインファイル・画面デザインも途中から微修正はAgentに任せています。「この部分にデザイン要素を追加したい。条件は…」といった感じで、途中からデザインもAI任せです。
ただし、全て生成AI・Agent任せにすると上手くいきません。基本アーキテクチャ・骨組み部分はヒトが作って、あとの実装はAI・Agentに依頼する感じですね。また指示・設計・仕様・実装内容のレビューを行うのはヒトです。必ずしも意図した通りの実装やコード、もちろん実際に動かしてみたらデグレして動かない…というのもあります。
以下、僕の感じているAgentの使い方を少し紹介します。開発環境はVScodeです。
■ AI Agentはペアプロの相手
全て生成AIに全て作って貰おうとは最初から期待していません。あくまでもペアプロで一緒に開発を行う相手として使っています。そのくらいの感覚で十分とも言えます。
■ プロジェクト全体を把握させる
いきなり「こういう実装をして欲しい」とだけ言っても出てくる実装は期待した通りにならないでしょう。これはヒトも一緒です。全体をまず俯瞰して、プロジェクト全体を読み込ませて、どういうプロジェクトで何をしているのか?というのを把握させてから、コード生成や相談をするようにしています。
■ 複数モデルを使う
個人的には資料を作らせるならこれ、ログ・テキスト解析をさせるならこれ、概要把握はこれ、コード生成のお供はこちら、といった感じでモデルを分けて使っていたりしています。ログからプロトコル〜parserを作って実装するとかは、もう一瞬でやってくれたり、本当に便利ですね。
途中でモデルを変えて使えるAgentもあるので(例えば、Claude〜GPT〜Gemini〜やっぱりGrokのように、途中で変えて使える)、なーんか意図したのと違うなーと思った時は、モデルを切り替えていたりします。
■ かならずヒトが確認する
これはマストですね。 ヒトはミスをする生き物です。同じように機械(AI)もミスはします。
機械がミスをするからダメというなら、ヒトも同じようなものなので、ミスは最初から許容しています。なので、実装・コードの可否は最終的に自分でチェックする、という立場で利用しています。
以下、少しだけロボット本体のコード以外で利用した生成例を記載します。
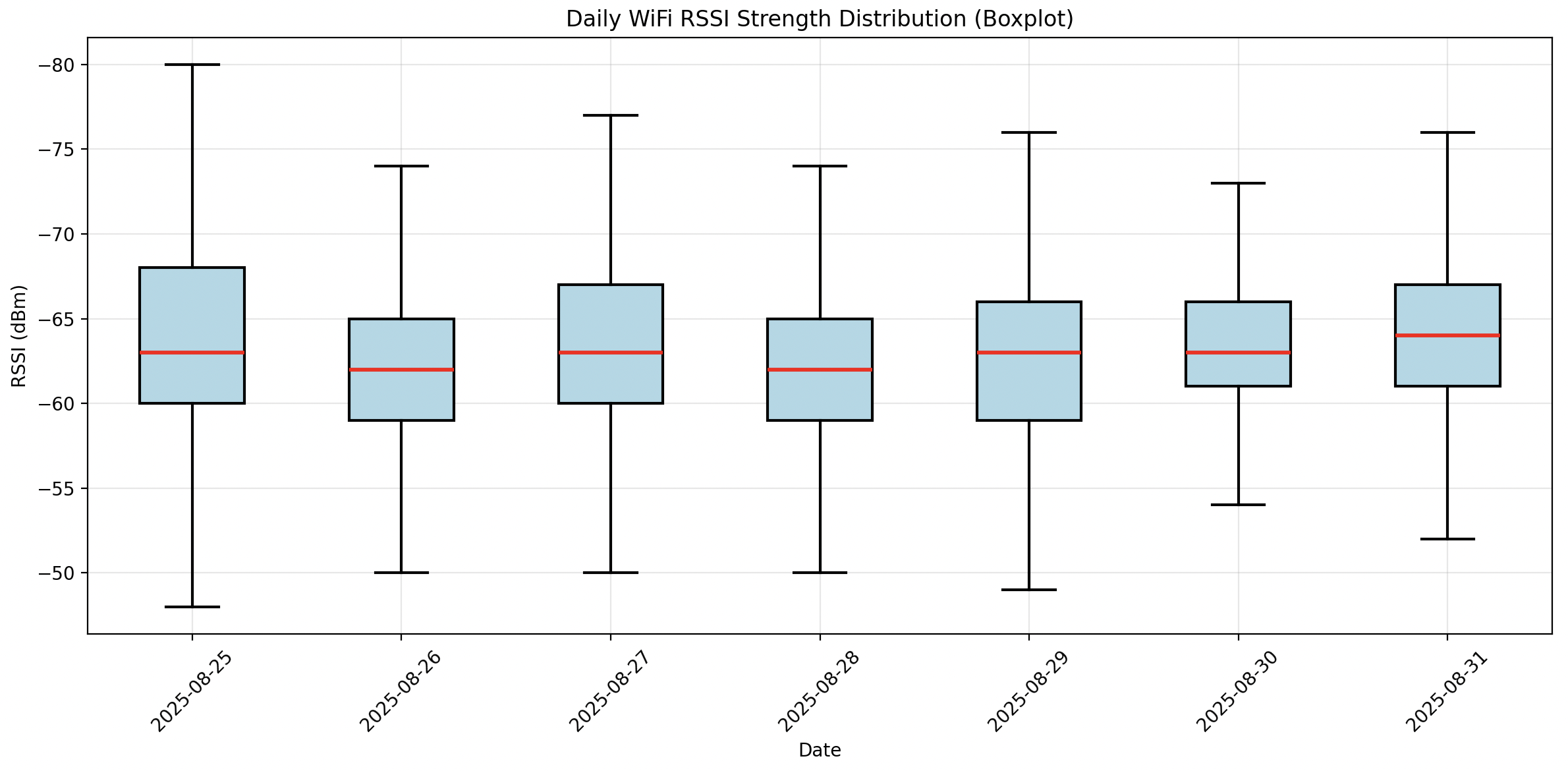
コード生成例.1. WiFi強度グラフ生成
実証実験中のWiFi強度についてログからボクセルグラフを作成して、実証実験レポートで利用します。
この位なら、1,2分もあれば作ってくれますね。ここではGrok Code Fast1で作成しています。
プロンプト
logs 以下に日別のロボットの動作ログがあります。
WiFI電波強度について、日毎のRSSI強度のグラフを作成して下さい。
WIFIのログは、WIFI_INFO として出力してあります。
python で実行する場合、環境は gcp という名前で用意しています。
グラフはboxplotで作成して下さい。結果
コード
import os
import re
import matplotlib.pyplot as plt
from datetime import datetime
from collections import defaultdict
def extract_rssi_from_log(log_path):
"""Extract RSSI values from a single log file."""
rssi_values = []
with open(log_path, 'r', encoding='utf-8') as f:
for line in f:
if 'WIFI_INFO:' in line:
# Extract RSSI value using regex
match = re.search(r'RSSI=(-?\d+)dBm', line)
if match:
rssi = int(match.group(1))
rssi_values.append(rssi)
return rssi_values
def process_all_logs(logs_dir):
"""Process all daily log files and aggregate RSSI by date."""
daily_rssi = defaultdict(list)
# List all date directories
for date_dir in sorted(os.listdir(logs_dir)):
date_path = os.path.join(logs_dir, date_dir)
if os.path.isdir(date_path):
# Assume log file is named YYYY-MM-DD.log
log_file = f"{date_dir}.log"
log_path = os.path.join(date_path, log_file)
if os.path.exists(log_path):
print(f"Processing {log_path}")
rssi_values = extract_rssi_from_log(log_path)
if rssi_values:
daily_rssi[date_dir] = rssi_values
print(f" Found {len(rssi_values)} RSSI measurements")
else:
print(f" No RSSI data found")
return daily_rssi
def create_daily_rssi_graph(daily_rssi):
"""Create a boxplot showing RSSI strength distribution by date."""
dates = []
rssi_data = []
for date, rssi_list in sorted(daily_rssi.items()):
if rssi_list:
dates.append(date)
rssi_data.append(rssi_list)
if not dates:
print("No data to plot")
return
# Create the boxplot
fig, ax = plt.subplots(figsize=(12, 6))
bp = ax.boxplot(rssi_data, patch_artist=True, showfliers=False,
medianprops=dict(color='red', linewidth=2),
whiskerprops=dict(color='black', linewidth=1.5),
capprops=dict(color='black', linewidth=1.5),
boxprops=dict(facecolor='lightblue', color='black', linewidth=1.5))
ax.set_xlabel('Date')
ax.set_ylabel('RSSI (dBm)')
ax.set_title('Daily WiFi RSSI Strength Distribution (Boxplot)')
ax.grid(True, alpha=0.3)
# Set x-axis labels
ax.set_xticklabels(dates, rotation=45)
# Set y-axis to show negative values properly (RSSI is negative)
ax.invert_yaxis()
plt.tight_layout()
plt.savefig('wifi_rssi_daily_boxplot.png', dpi=300, bbox_inches='tight')
plt.show()
def main():
logs_dir = '../logs'
if not os.path.exists(logs_dir):
print(f"Logs directory not found: {logs_dir}")
return
print("Starting WiFi RSSI analysis...")
daily_rssi = process_all_logs(logs_dir)
if daily_rssi:
print(f"\nProcessed {len(daily_rssi)} days of data")
create_daily_rssi_graph(daily_rssi)
print("Graph saved as 'wifi_rssi_daily_boxplot.png'")
else:
print("No RSSI data found in logs")
if __name__ == "__main__":
main()コード生成例.2. Lottie JSONデザイン修正
ちょっと、デザインを修正したいな…という時はめちゃくちゃ便利です。
元となる目鼻口の要素については作成してあるので、微修正は自動で行えます。最初はVector/JSONデータを理解して修正してくれるか?と思いましたが、画像生成のように修正してくれます。
ここではClaude Sonnet 4で作ってもらいました。
プロンプト
face_eye_left_single_move.json
だけど、目の間の距離を少しだけ大きくして、まつ毛もかわいい感じで大きくしてもらえる?結果(before/after)
15pixelづつ左右に移動・まつ毛が少し変わりました。


多くの気付き
振り返ると、今回の実証実験で得られたものは、まさに「気付き」の連続でした。机上でどれだけ未来のロボットを語るよりも、稼働する一台のロボットを現場に置くことで得られる学びは圧倒的です。
7日間の期間中、ロボットの総対話数は約2000回、ロボットの移動案内は約290回ほどありました。
技術について考えて実装することは出来ても、実際に動くロボットが人々の輪に入った時に何が起こるのかは、現場に立って初めて理解できることばかりでした。それは、ロボットとヒトとの関係性を考える上で、何物にも代えがたい貴重な経験・データになりました。
多くの気づきはありますが、その中から何点かご紹介します。
不特定多数の多人数が居る環境での移動・案内
今までLidar/ROS/Mapを使った移動や、色々なセンサー類を使ってきて、混雑環境でも移動もなんとかなるだろう…とは思っていました。
しかし実際にやってみると衝突回避・移動という機能的な側面よりも、「ヒトの中にロボットが居る場合、どういう挙動を取るべきか?」という方が重要だと気付かされます。(以下は今回利用したロボットにあるRGBD・Lidarです。これらを使って移動することになります。)

というのも、A から B という地点にロボットが移動案内する際に、
■来館者やモノへの衝突回避は絶対
これは当然ですね。今回の実証実験では衝突はゼロでした。
もし衝突しそうになったら、無理やりにでもロボットを止めようとは思っていました。
■ 案内地点に到達出来ない
これは機械的なセンサー不具合というよりも、非常に多くの来館者、ロボットに興味を持って近寄ってくる来館者によってロボットの移動が妨げられるケースです。
今回の実証実験では、ロボットは移動困難時に停止、案内が出来なかった旨を発話するようにしています。最初は元の場所に戻るようにしようかとも考えましたが、その場に留まるようにしています。
移動を妨げられた際、ロボットはどういう挙動をすべきか?というのは考えさせられました。
例えば、目の前にBというゴールが見えているのに、来館者の壁で移動が妨げられた場合、ゴールに到達するまで頑張るか?その場で停止するのか?ロボットの発話・アナウンスは?再経路で案内するのか?という事ですね。
目の前にゴールがあっても、ちょっとの距離の差で到達できない(ゴールが見えているのに!!)、もう到達しているのも同然なのに、ゴール出来ていない・再経路案内で逆戻りなんてのは最悪です。
実際にはゴール地点には柔軟性を持たせて、ピンポイントではなくて「1.5Mの範囲であればゴール」としていますが、それでも目の前にゴールがあるのに到達できないケースが多発しました。
すぐ考えられる対策は、カメラで人流をチェックして少ない方の移動経路を使うという方法です。ただし、人流チェックの外部カメラはどうするのか?という、そもそも的な事にもなります。
またロボットからの移動発話を強く言うことで、移動経路を開けて貰うというのも考えられます。「案内しているので、道を開けて下さい」のような発話ですね(来館者にロボットのために、移動して頂くのもどうか…とは思うのと、ヒトの方からしたらロボットが移動するべきと考えるでしょう)。
人の場合、地点移動する際、ぎゅうぎゅうの状態でもなければ、人の間をすり抜けて移動する事も可能です。しかし、ロボットの場合はそうはいきません。
ロボット(AI)と人の音声対話
今回のようなミュージアム、更にはデパートのような商業施設や街なかにロボットが居て、ヒトからロボットに積極的に話かけるという状況・世界はいつか来る、という未来像が描かれることがあります。
知りたい情報があったとき、次のような環境では誰に話かけるでしょう(話かけないという選択も)。
1.ヒトが居る(選択の余地なし)
2.ヒトとロボットが居る(ヒト?ロボ?)
3.ロボットしか居ない(選択の余地なし)
今回の実証実験ではロボットが単体で居るとき、来館者からロボットに話かけることは非常に稀でした。
来館者からロボットに話かけるには、【ロボットしか居ない】多数のロボットが設置されている状況、【ヒトとロボットが居る】社会受容性・ユーザー体験(表情だけではないUX)の何かが必要になると痛感しました。何がその鍵となるのかは、今後も検証を重ねていく必要があります。
他にも、ヒトに対する口調と、ロボットに対する口調は同じになるかどうか?という、ロボットとヒトで接し方の違いが起きるのか?なども興味津々です。
他にも今回の実証実験での対話で気付いたのが…
■ 不特定・多人数が居る時の STT・TTS
1対1での対話と、不特定多数の人流がある中での対話は違うと実感しました。
上記の【■ 対話ボタンを右下に用意】で記載したような機能・実装的な問題、ロボットが多人数から話かけられたとき、誰と対話をするのか?話が長いときに中断したい、話している内容を文字列で見たい(これは実装しました)などなど、ロボットと人のコミュニケーションを成立させるには、非常に多くの条件をクリアする必要がありそうです。
そして一番に感じたのがロボットとの自然なコミュニケーションを考えることで、ヒト同士が自然に対話できている事がそもそもが凄いということでした。
■ 対話の「長さ」と「質」のジレンマ
私達は普段からChatGPT、Gemini、Claudeといった生成AIとの文字列でのチャット・スマホでの利用に慣れ親しんできて、文字列として読む〜対話を行っています。
実際に音声として話すとき、私達は文字数にすると日本語では20〜40文字前後の短い発話(ターン)でやりとりを行っています。文章として読むスピードは、もちろん発話するスピードより早いですね。
ロボットとできるだけ対話・コミュニケーションを行う想定で、最初は40文字程度の短いレスポンスにしていましたが、展示の説明となると、物足りない・説明不足感がします。そこで、実証実験中の後半では応答する文字列長を長くする調整を行いました。すると、今度は長い話を途中で止めたくなってしまいます…
何気ない雑談のようなコミュニケーションと、展示物の説明によるコミュニケーションでは(説明・質問・回答)ではコミュニケーションとしての本質が違うというのに気づきました。
・タスク志向型対話(雑談・質疑応答)
「東京駅への行き方は?」「明日の天気は?」のような、短いやり取りで、特定の情報を効率よく得ることを目的にした、短く・簡潔な対話。
・情報提供型対話(説明・解説)
「この展示について説明して」のような、順序立てて理解すること目的にした、ある程度の長さと詳細な対話。
分かったのが対話の質があるということだけで、間違いなく他にも多種多様な分類があると容易に予想できます。ユーザーの発話の意図をAIが自ら判断し、対話のモードに応じて応答の長さ(トークン数)や詳細度を動的に調整する仕組みが必要になりそうです。
終わりに
他にも本当に多くの気づきがあり、実証実験レポートを作成するなかで、うーん…と考えさせられることばかりでした。
今回、日本科学未来館という場で実証実験を行えたことは、ロボット関係のみならずコンピュータ・AIとヒトとの対話・コミュニケーションという点でも、机上ではなく実地にて多くの知見がありました。
本実証実験の実施にあたり、場所の提供から運営面でのサポートまで、多大なるご協力をいただいた日本科学未来館のスタッフの皆様に心より感謝申し上げます。現場での細やかな配慮やアドバイスを頂き、実地での経験・データは非常に貴重なものになりました。
これらの経験と学びを活かし、人とロボットが自然に共生できる社会の実現に向けて、引き続き開発を進めていきたいと思います。
ブログの著者欄
新里 祐教
GMOインターネットグループ株式会社
プログラマー。GMOインターネットグループにて開発案件・新規事業開発に携わる。またオープンソースの開発や色々なアイデアを形にして展示をするなどの活動を行っている。
採用情報

関連記事
-

攻撃者優位の時代に問われる「使命感」 GMO Flatt Security&GMOサイバーセキュリティ byイエラエが描く、AI時代のセキュリティ構想(後編)ーEngineering Journey
技術情報
-

頂上と裾野の両方から「底上げ」 GMO Flatt Security&GMO サイバーセキュリティ byイエラエが支える、日本のサイバーセキュリティ(前編)ーEngineering Journey
技術情報
-

デザインコンテスト「GMO DESIGN AWARD 2026」開催決定!3年目のテーマは「トキメキ」
デザイン
-

【後編】Hack-1グランプリ2026 デモデーレポート|グランプリ&オーディエンス賞をW受賞!オンライン部門優勝チームにインタビュー
デザイン
-

「AIにデータ渡して大丈夫?」を約款から解決 プロダクトマネージャーが語る「主要AI約款比較」の設計思想と開発秘話
技術情報
-

【中編】Hack-1グランプリ2026 デモデーレポート|ついにグランプリ決定!最優秀賞チームに開発秘話を聞く
デザイン

KEYWORD
CATEGORY
-
技術情報(594)
-
イベント(237)
-
カルチャー(60)
-
デザイン(70)
TAG
- 「Guard」機能
- 「Runner」機能
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI TALK
- AI 機械学習強化学習
- AI/機械学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI活用事例
- AI駆動
- AMD
- APT攻撃
- AWX
- Behind the Scenes
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- ConoHaVPS
- CS
- CSS
- CTF
- DC
- Designship
- Desiner
- developer
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- engineering
- Engineering Journey
- eVTOL
- expert
- EXPERT CROSS
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOインターネットグループ陸上部 – GMOロボッツ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティ byイエラエ
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- GMO天秤AI
- Go
- Good Morning
- GPU
- GPUクラウド
- GTB
- Hack-1グランプリ
- Hack‐1グランプリ
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- Japan Drone
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Takumi byGMO
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- エージェンティックAI
- オブジェクト指向
- オンボーディング
- お名前.com
- クリエイター
- クリエイターインタビュー
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- セキュリティ診断
- ゼロトラスト
- ソフトウェアサプライチェーン
- ソフトウェアサプライチェーン攻撃
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ハーネスエンジニアリング
- バックエンド
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- フロントエンド
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- ロボティクス
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 技術書典20
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 映像制作
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 空飛ぶクルマ
- 脆弱性診断
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 開発者
- 階層ベイズ
- 高機能暗号
PICKUP
-

デザインカンファレンス「Yoitoi Summit 2026」をGMOYours・フクラスにて開催!
デザイン
-
攻撃者優位の時代に問われる「使命感」 GMO Flatt Security&GMOサイバーセキュリティ byイエラエが描く、AI時代のセキュリティ構想(後編)ーEngineering Journey
技術情報
-
頂上と裾野の両方から「底上げ」 GMO Flatt Security&GMO サイバーセキュリティ byイエラエが支える、日本のサイバーセキュリティ(前編)ーEngineering Journey
技術情報
-

【開催レポート】八幡小学校 社会科見学 at GMO kitaQ
カルチャー
-
デザインコンテスト「GMO DESIGN AWARD 2026」開催決定!3年目のテーマは「トキメキ」
デザイン
-

ソフトウェアサプライチェーン攻撃から「エンジニアの背中」を守る。Takumi byGMO・「Guard」機能「Runner」機能 開発の舞台裏ーEngineering Journey
技術情報
採用情報

SNS FOLLOW
