
みなさん、印鑑使ってますか?
最近は物理的な印鑑を使う機会は減ってきましたね。そんな中「さよなら印鑑キャンペーン」という取り組みが2020年6月25日〜2020年9月30日まで行われました。たくさんのご応募、エピソードありがとうございます。
今回は、皆さんから頂いたアンケート・エピソード投稿を分析するシステムをサクッと作った話をします。
目次
さよなら印鑑キャンペーン
GMOインターネットグループでは印鑑廃止の取り組みを進めていて、物理的な印鑑を使うことは無くなりました。GMOサインというサービスを展開しており、印鑑は電子サインでOKといった感じですね。
昨年、さよなら印鑑キャンペーンという印鑑に関わるエピソードや、脱ハンコに賛成・反対といったアンケートが2020年6月25日〜2020年9月30日に行われました。
僕自身の印鑑に関するエピソードだと、印鑑を使うことは1年に1度あるかどうか…で、それも会社以外の事だけですね。ただ、”紙で自筆・印鑑が必須”という事もあったりすると、自筆をすることもほとんど無くなったので、自分の字の汚さを再認識する事もあったりします。
それは突然やってくる
キャンペーンを行っていた事は知っていて、誰か集計を取ったりするんだろうなぁ…と思っていたところ、それは突然やってきました。
「集計するのよろしくお願いします」
「(何のことすか?)了解です」
「至急進めてください」
あ、誰かは僕でしたね。
僕の感覚だと”至急=Now”で今すぐ、数日中に結果を求められるといった感覚なので、早速とりかかる事にしました。データがあれば、要望に応じて集計・分析はできるので問題ありません。ただ、個人データが含まれる内容のため、データの取り扱いは慎重に進めました。
そもそも何を集計したいか?
まずはキャンペーンページを見てみた所、次のようなフォーム・データになっていました。
- 脱ハンコ:賛成・反対
- エピソード:自由記述
- エピソードの場所:自由記述
自由記述という事は日本語の文章を解析する必要がありますね。エピソードに関しては次のような内容です(キャンペーンサイト、エピソード賞から抜粋)。
【賛成】重要な契約の捺印ならいざ知らず、数万円の発注書のハンコにも申請書類が必要で、そのハンコを得るのに、上役の個人印をもらいに回るという作業自体が業務効率を著しく下げていることが非常に無駄。また、電子社印の話ではないのですが、勤怠の申請に上司の個人印を押す文化がまだあるので、上司不在の場合には、その上の人の印があればいいとのことで、何も業務も把握していない人にハンコを得るので通る申請ならば確認など不要ではと思ったことが何度もあります。
電子印なら社内に上司がいなくても対応ができますし個人印も電子でいいのでは、と思っています。
【反対】私は小さい頃から海外にいて大学になって日本に帰国した際に初めて銀行口座を開くために銀行に行った際、印鑑を持って行かずに銀行員の方々に驚かれた事は今でも私の大切な面白ろエピソードです。家をローンで購入する時や大きな買い物をする時に印鑑を押す時のあの緊張感。その度、今から始まる将来の生活を考えながら一回一回大切に印鑑を押しています。ハンコ不要はなんだか悲しいです。
エピソードには賛成・反対という条件が付いているので、ここで関連性が見いだせそうです。
そして、次にどういった集計を行いたいのか?
調査してみたところ、具体的な内容・要件はまったく決まっていませんでした。そこで、重要なエピソードの検索・集計・日本語の処理をうまくしてくれるツールを利用して、まずBI(Business Intelligence)として可視化する事が最優先だと判断しました。そこから、企画やマーケ層が見えてくる事も多いでしょう。
分析方法について
ここからは、集計をするにあたり利用したツールや環境についてお話していきます。
Elastic・Kibanaを利用
Elasticsearch/KibanaはBIツールとして、実績も多数あって非常に有用ですね。Kuromojiの形態素解析/n-gramがあるので、データを入れておけば、アンケート結果を検索する時も非常に便利です。また、ダッシュボードのUIも非常に便利で「非エンジニアでも誰でも使えるだろう」と思っていたので、とりあえず用意することにしました。個人的には、このElasticsearch/Kibanaの組合せで建てたサーバ・システムはかなりあるので、まぁサクッと出来るだろうな…くらいに思っていました。
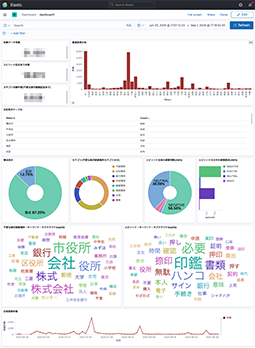
ここで集計している内容は次の通りです。
- データ件数、エピソード記述有り件数、エピソードの場所の記述あり件数
- 投稿者の都道府県・市区町村のリスト
- 脱ハンコ:賛成・反対の割合
- エピソード場所のカテゴリ分け
- エピソードの感情分析(ポジ・ネガ・ニュートラル・混合)
- エピソードから抽出したキーワードリスト(タグクラウド)
- 時間毎の投稿数のグラフ
特に難しい所はありませんね。環境を準備すれば1日もあれば出来るでしょう。
実際に集計したデータから、次のような傾向が見えてきました。(日本の脱ハンコを後押しする「さよなら印鑑キャンペーン」中間報告!から抜粋)
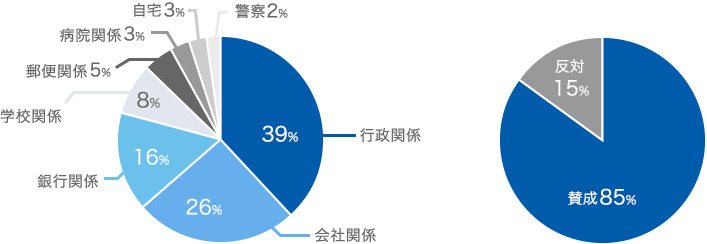
これらも環境を用意しておけば、期間・都道府県・市区町村・賛成/反対・場所単位・キーワード…etcで一瞬にして検索・集計して分析できます。
Dockerで環境構築
1日もあれば用意できる、というのは少し間違っていて、環境自体は一瞬にしてできますね。そこから少しデータを整備して…大抵のデータの可視化・最初の分析までは1日もあれば可能なお手軽さがあります。
ちなみに、何かデータから知りたい…という時は、その何かも要件として分からない事が非常に多いので、とりあえずデータを集計・分析・可視化できて、レポート出来るようになっていれば最初の段階はOKでしょう。さらに深い所まで知りたくなったら、その時はデータに対する知見が溜まっているので、「何か知りたい」というのが具体的になって、適宜対応も可能になっている事の方が多いです。
最近はDockerで環境構築がすぐできるので非常に便利です。基本的な「elasticsearch/kibana/制御用のコンテナ」を一つにまとめて、いつでも(飛び込み案件などで)使えるように用意してあるので、少し抜粋して紹介します。
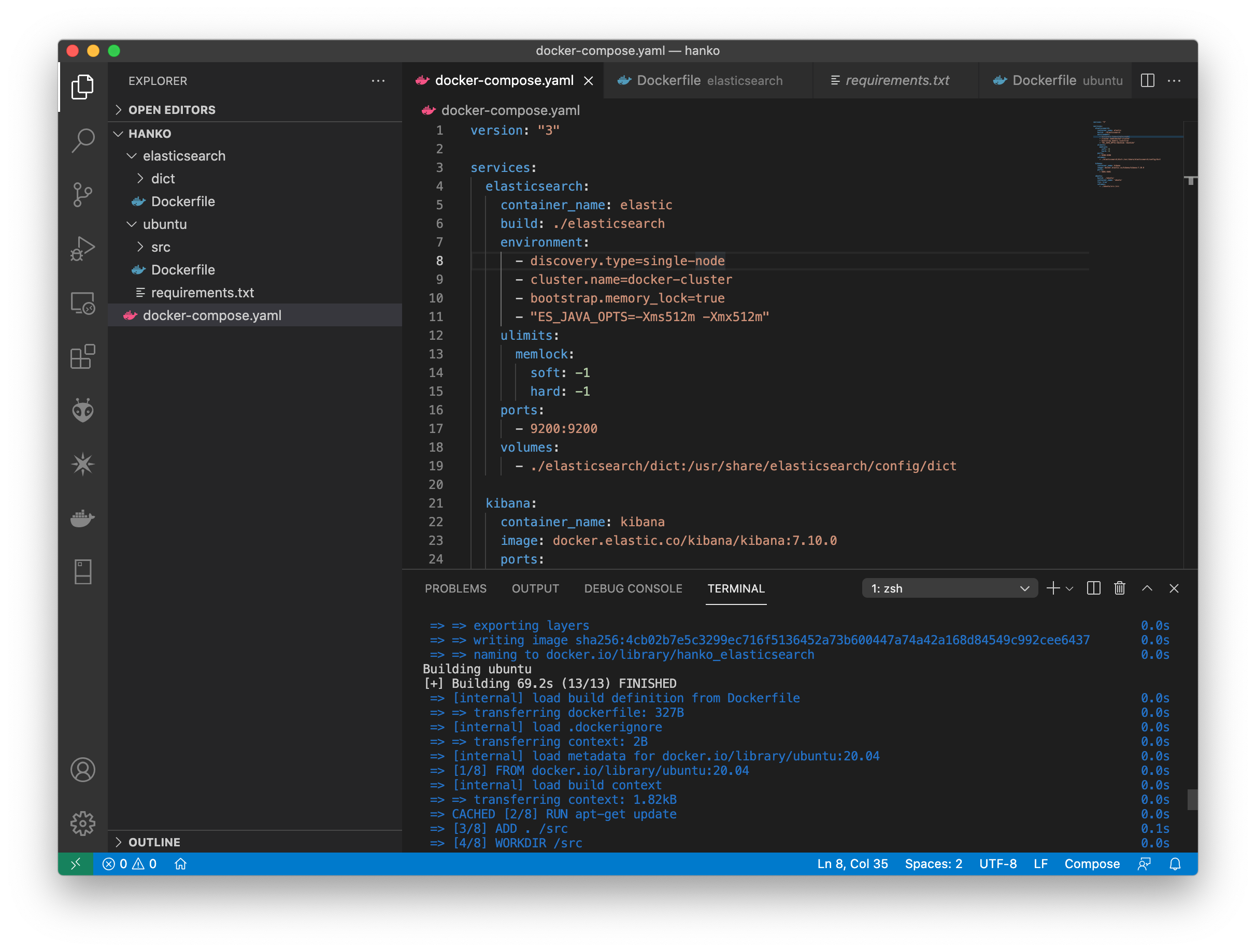
elastic/kibanaと制御するサーバー(ここではUbuntu)は利用する事も多いので、docker-composeにしてまとめています。基本的な部分だけ記載しておきます。ディレクトリ構成は上のVScodeのスクショの通りです。kibanaは立ち上げるだけで、Dockerfileは用意しなくてもOKという事にしてあります。
version: "3"
services:
elasticsearch:
container_name: elastic
build: ./elasticsearch
environment:
- discovery.type=single-node
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 9200:9200
volumes:
- ./elasticsearch/dict:/usr/share/elasticsearch/config/dict
kibana:
container_name: kibana
image: docker.elastic.co/kibana/kibana:7.10.0
ports:
- 5601:5601
ubuntu:
build: ./ubuntu/
container_name: 'ubuntu'
tty: true
volumes:
- ./ubuntu/src:/srcFROM docker.elastic.co/elasticsearch/elasticsearch:7.10.0
RUN elasticsearch-plugin install analysis-kuromojiFROM ubuntu:20.04
RUN apt-get update
ADD . /src
WORKDIR /src
RUN apt-get update
RUN apt install -y python3 python3-pip curl
RUN pip install --upgrade setuptools
RUN pip install -r requirements.txtelasticsearchこんな感じで基本部分を用意しておけば”docker-compose build”でOKですね。
kibanaについてはとくに何も用意しないで、コンテナを起動して繋げられるようにしてあるだけです。サクッと使う時にPythonをよく利用するので、requirements.txt でpip経由で入れておきます。
あと、elasticsearchはdictを用意しています。これはシノニムや辞書を登録する時に利用しておけるようにしています。
たとえば、カスタム辞書やシノニムを置いておくときに、ホスト側からもサクサク編集・配布できるようにしてあります。
{
"settings": {
"analysis": {
"tokenizer": {
"kuromoji_tokenizer_search": {
"type": "kuromoji_tokenizer",
"mode": "search",
"discard_punctuation" : "true",
"user_dictionary" : "dict/userdict_ja.txt"
},
},
"analyzer": {
"kuromoji_analyzer": {
"type": "custom",
"tokenizer": "kuromoji_tokenizer_search"
},
},
"filter": {
"custom_synonym": {
"type": "synonym",
"synonyms_path" : "dict/user_synonyms.txt"
}
}
}
}
}これに横付けしてDBがあったりデータ連携ができれば一瞬ですね。適当にmappingを用意してデータ連携・投入をすれば、すぐKibana経由で集計・分析が出来るでしょう。アプリで何か制御が必要な時はUbuntu上で処理をサクッとやっておけばOKですね。
何も集計・分析したり可視化・レポートする環境が無いとき、サクッとdockerで環境構築、elasticsearch/kibanaの構成はかなりオススメですね。
ブログの著者欄
新里 祐教
GMOインターネットグループ株式会社
プログラマー。GMOインターネットグループにて開発案件・新規事業開発に携わる。またオープンソースの開発や色々なアイデアを形にして展示をするなどの活動を行っている。
採用情報



関連記事







KEYWORD
CATEGORY
-
技術情報(594)
-
イベント(237)
-
カルチャー(60)
-
デザイン(70)
TAG
- 5G
- AI
- AI TALK
- AI 機械学習強化学習
- AI/機械学習
- AIエージェント
- AIコーディング
- AI人財
- AI駆動
- Behind the Scenes
- BIT VALLEY
- blockchain
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CNDO
- CNDT
- CODE BLUE
- ConoHa
- ConoHa VPS
- CSS
- CTF
- Designship
- developer
- DevRel
- DevSecOpsThon
- Docker
- DTF
- Engineering Journey
- expert
- EXPERT CROSS
- GMO AI&ロボティクス商事
- GMO AIR
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティ byイエラエ
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMO大会議
- GMO天秤AI
- Go
- Good Morning
- GPUクラウド
- GTB
- Hack-1グランプリ
- iOS
- IoT
- ISUCON
- Japan Drone
- JapanDrone
- Java
- JJUG
- K8s
- Kaigi on Rails
- Kids VALLEY
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- OpenStack
- Perl
- PHP
- PHPcon
- PHPerKaigi
- Python
- RPA
- Ruby
- SECCON
- Selenium
- Spectrum Tokyo Meetup
- splunk
- SRE
- Takumi byGMO
- Terraform
- TypeScript
- UI/UX
- vibe
- VPN
- VS Code
- XSS
- ZTNA
- アドベントカレンダー
- インターンシップ
- インハウス
- お名前.com
- クリエイターインタビュー
- クリエイティブ
- コンテナ
- サイバーセキュリティ
- サマーインターン
- スクラム
- スペシャリスト
- セキュリティ
- ソフトウェアサプライチェーン
- チームビルディング
- デザイン
- ネットのセキュリティもGMO
- ハーネスエンジニアリング
- バックエンド
- ヒューマノイド
- ヒューマノイドロボット
- プログラミング教育
- ブロックチェーン
- フロントエンド
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 国際ロボット展
- 基礎
- 多拠点開発
- 宮崎オフィス
- 応用
- 技育プロジェクト
- 技術広報
- 技術書典
- 新卒
- 新卒研修
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 機械学習
- 決済
- 生成AI
- 脆弱性診断
- 開発者
PICKUP
-

デザインカンファレンス「Yoitoi Summit 2026」をGMOYours・フクラスにて開催!
デザイン
-

攻撃者優位の時代に問われる「使命感」 GMO Flatt Security&GMOサイバーセキュリティ byイエラエが描く、AI時代のセキュリティ構想(後編)ーEngineering Journey
技術情報
-

頂上と裾野の両方から「底上げ」 GMO Flatt Security&GMO サイバーセキュリティ byイエラエが支える、日本のサイバーセキュリティ(前編)ーEngineering Journey
技術情報
-

【開催レポート】八幡小学校 社会科見学 at GMO kitaQ
カルチャー
-

デザインコンテスト「GMO DESIGN AWARD 2026」開催決定!3年目のテーマは「トキメキ」
デザイン
-

ソフトウェアサプライチェーン攻撃から「エンジニアの背中」を守る。Takumi byGMO・「Guard」機能「Runner」機能 開発の舞台裏ーEngineering Journey
技術情報
採用情報

SNS FOLLOW
