
普段はインフラエンジニアをやっている柳です。
前回の記事「オープンソースで作成する顔認証Web Server / vol.01」と共通する部分も多いため参照ください。
音声認識とは人間の声をコンピューターに認識させることです。音声認識にはWeb Speech APIという無料で使えるAPIがありhtmlとJavaScriptで実装可能です。しかしそれでは面白くない為、機械学習部分も含めサーバーを構築していきたいと思います。言語はフロントにhtml、JavaScript、バックにPythonを用います。
目次
1.完成イメージ
Web Speech APIと同じ動作をすることを目標とします。ブラウザ上でリアルタイムに音声認識し短文としてウェブページ上に表示します。

Web Speech APIでの実装は下記となります。htmlファイルとして保存しブラウザで起動すれば動作可能です。
※インターネット環境が必要です。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Web Speech API</title>
</head>
<body>
<h2>Web Speech API</h2>
<button id="start_btn">start</button>
<button id="stop_btn">stop</button>
<small id="status"></small>
<h3>Recognition Result</h3>
<textarea id="show_progress" cols="100" rows="1"></textarea>
<div id="show_result"></div>
</body>
<script>
// Declare webkitSpeechRecognition
window.SpeechRecognition = window.SpeechRecognition || webkitSpeechRecognition;
var recognition = new webkitSpeechRecognition();
// Web Speech API Configuration
// Language
recognition.lang = 'ja';
// Show Progress
recognition.interimResults = true;
// Continuous recognition
recognition.continuous = true;
// Const
const start_btn = document.getElementById('start_btn');
const stop_btn = document.getElementById('stop_btn');
const show_progress = document.getElementById('show_progress')
const show_result = document.getElementById('show_result');
recognition.onsoundstart = function(){
document.getElementById('status').innerHTML = "Recognizing";
};
recognition.onnomatch = function(){
document.getElementById('status').innerHTML = "Try again";
};
recognition.onerror= function(){
document.getElementById('status').innerHTML = "ERROR";
};
recognition.onsoundend = function(){
document.getElementById('status').innerHTML = "Stopped";
};
start_btn.addEventListener('click' , function() {
// Start recognition
recognition.start();
this.disabled = true;
stop_btn.disabled = false;
});
stop_btn.addEventListener('click' , function() {
// Stop recognition
recognition.stop();
this.disabled = true;
start_btn.disabled = false;
show_progress.innerHTML = '';
});
recognition.onresult = function(event){
var results = event.results;
for (var i = event.resultIndex; i<results.length; i++){
if(results[i].isFinal)
show_result.innerHTML += '<div>'+ results[i][0].transcript +'</div>';
else
show_progress.innerHTML = "[Progress] "+ results[i][0].transcript;
}
}
</script>
</html>
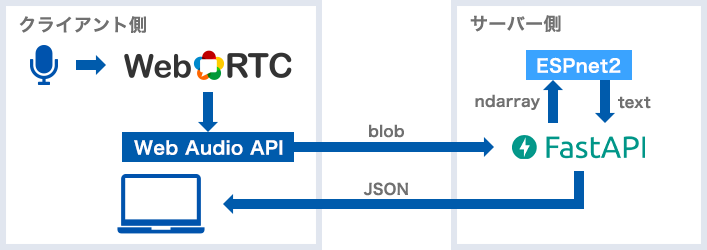
2.サーバー構成
フロント(HTML, API)のウェブアプリケーションフレームワークはFastAPI、バックエンドにはEnd-to-End音声処理のESPnet2を利用します。(FastAPIのアプリケーションは前回同様Gunicornで起動しリバプロにnginxを挟んでいます。)
クライアント側のマイク起動はWebRTCのAPIで行い、音声データの前処理はWeb Audio APIを利用します。
3.Web Audio API
クライアント側での音声処理ワークフローです。マイクで入力された音声をHTTPS(Port441)でサーバーにポストする処理を担当しています。
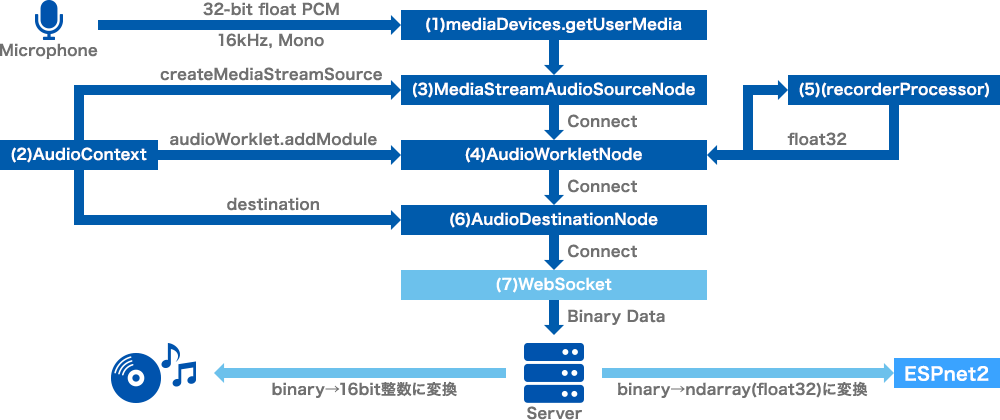
(1)WebRTCのgetUserMediaでマイク起動
16bit、16kHz、モノラルを指定しマイクのアナログ入力を32ビット浮動小数点数(-1.0~1.0)でAD変換し入力します。
(2)AudioContextを定義
ESPnet2で利用する16kHzのサンプルレートを指定しAudioContextを定義します。
(3)MediaStreamAudioSourceNode
createMediaStreamSourceでストリーム(WebRTC)からの入力ノードを作成します。
(4)AudioWorkletNode
AudioWorkletNodeはScriptProcessorNodeの後継となります。音声録音用のレコーダーを作成します。AudioWorkletNodeではbufferSizeを指定できませんが内部では128サンプルで処理されています。
(5)recorderProcessor
入力データを処理する場合はここで定義します。今回は入力データを処理する必要がない為中身は空となります。
(6)AudioDestinationNode
レコーダーを出力先に接続します。
(7)WebSocket
WebSocketを定義しサーバーへ音声データをPostできるようにします。port.onmessageで入力データを随時サーバーへBinary Dataとしてポストします。
//(2) Declare audio context
const context = new AudioContext({ sampleRate: sampleRate });
//(3) Create MediaStreamAudioSourceNode
const source = context.createMediaStreamSource(stream);
//(4&5) Create AudioWorkletNode
await context.audioWorklet.addModule('static/js/recorderProcessor.js');
const recorder = new AudioWorkletNode(context, 'recorder');
// Connect MediaStreamAudioSourceNode and AudioWorkletNode
source.connect(recorder);
//(6) Connect AudioWorkletNode and AudioDestinationNode
recorder.connect(context.destination);
//(7) WebSocket
let connection = new WebSocket(websocketUrl);
// Send audio data
connection.onopen = function(event) {
show_status.textContent = "Recognizing";
// Send stream to websocket
recorder.port.onmessage = msg => {
connection.send(msg.data.buffer);
};
};サーバー側で受け取ったデータを出力先が処理可能なデータに整形し渡します。
■ESPnet2解析時
websocketのreceive_bytes でデータを受取後ndarray(float32)へ変換します。
# Recieve binary data
data = await websocket.receive_bytes()
# Convert bibary to numpy ndarray(float32)
np_data = np.frombuffer(data, dtype='float32')■音声ファイル保存
32ビット浮動小数点からリニアPCM(16bit符号付整数)に変換します。
※215-1を掛けることで変換できます。
# Change float32(-1.0 ~ 1.0) to 16bit signed integer(-32,768 ~ 32767)
int_size = 2**(SAMPLE_SIZE - 1) – 1
np_data = (np_data * int_size).astype(np.int16)下記ページを参考にさせて頂きました。
https://qiita.com/ryoyakawai/items/1160586653330ccbf4a4
https://developer.mozilla.org/ja/docs/Web/API/Web_Audio_API
4.Websocket 双方向通信
リアルタイム音声認識を実現するため、WebSocketでサーバークライアント間の双方向通信を実装する必要があります。また音声データは途切れることなくクライアントからサーバーへ送付されるため、音声データの受信処理(websocket.receive_bytes)と解析結果の送信処理(websocket.send_text)が同時にサーバー側で行えるよう非同期処理で実装します。
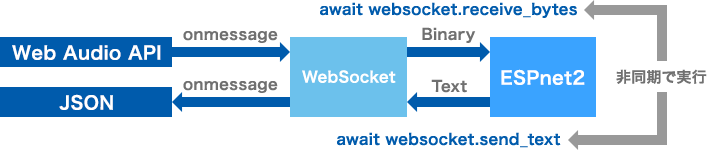
5.音声認識
ここからはサーバー側の処理を説明します。音声認識はespnet_model_zooをインストールしESPnetの学習済みモデルを利用します。
下記ページを参考にさせて頂きました。
https://tech.retrieva.jp/entry/2020/12/23/170645
# ASRモデルを指定しSpeech2Textを定義
speech2text = Speech2Text(asr_config, asr_pth, device=device)
# 32bit floatの音声データ(np_data)を入力
nbests = speech2text(np_data)
# 解析結果(text)を取り出し
text, *_ = nbests[0]■ESPnet2について
音声認(ASR)、テキスト音声合成(TTS)、音声強調(SE)がサポートされている音声処理ツールキットです。機械学習部分にはPyTorchが採用されています。レシピと呼ばれるシェルスクリプトがありモデルの構築も可能です。
詳しくは下記ページを参照ください。
今回は学習済モデルを利用するためモデルの構築は必要ありません。
https://kan-bayashi.github.io/asj-espnet2-tutorial/
■End To End音声認識について
従来の音声認識技術では、音響モデル、言語モデル、発音辞書を組み合わせ、音声認識システムを構築していました。End To Endモデルでは特徴量からダイレクトに文字や単語をニューラルネットワークから予測し出力します。
https://techblog.yahoo.co.jp/entry/2020062930010545/
■ ESPnet2でのASR(音声認識)フローについて
https://tech.fusic.co.jp/posts/2021-08-03-espnet/
6.音声区間検出(Voice Activity Detector)
リアルタイム音声認識に必要となる音声区間検出についてです。会話の区切り(息継ぎ)を見つけることで短い文、単語として音声を解析させます。End To Endモデルでは長い文章で解析するより短い文に区切り解析した方が高速となります。
例:「今日の天気は晴れ後曇り。/最高気温は三十度です。/夕方から雨が降る可能性があるので/傘を持っていくと安心です」(音声11秒)
(A)1音声ファイルで入力した場合
解析時間:33秒(CPU)、2.97秒(GPU)
(B)4音声ファイル(/で分割)で入力した場合
解析時間:14秒(CPU)、2.11秒 (GPU)
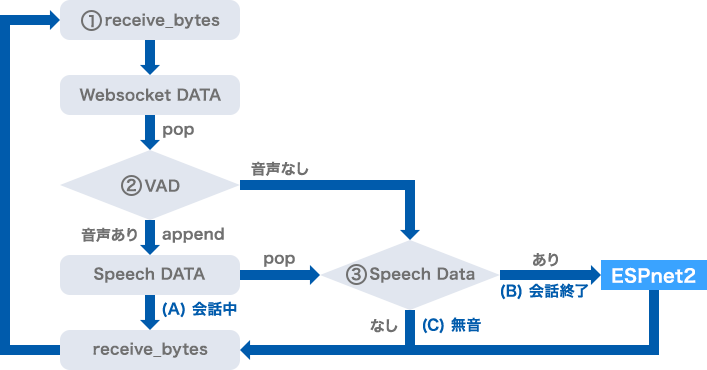
会話中、会話終了、無音は下記で判断します。
(A)会話中 :音声区間検出あり
(B)会話終了:音声区間検出なし、Speech DATAあり
(C)無 音 :音声区間検出なし、Speech DATAなし
① WebSocketからデータを受信しWebsocket DATAに格納します。
② Websocket DATA[リスト型]から音声をPOP(Websocket DATAリストは空となる)
後、音声区間検出(VAD)を行います。
└音声あり:データをSpeech DATAへappend(追加)し①へ
└音声なし:③へ
③ Speech DATA[リスト型]から音声をPOP(Speech DATAリストは空となる)
後、データありなしを判別します。
└データあり:会話終了、解析処理を行います
└データなし:無音区間、①へ戻ります
※データをPOPしリストを空にすることが重要です。
音声区間検出実行のインターバルは1~2秒が最適と思います。
└短いインターバル:音声途中で解析を行う(息継ぎ等)の可能性が高くなります
└長いインターバル:会話と会話が繋がり解析する可能性が高くなります
このフローであれば長い文章でも単語でも息継ぎを見つけることでリアルタイム(1-2秒後)に結果を表示可能となります。
7.WebRTC マイク入力切り替え
音声認識で重要な要素の1つがマイクの性能です。ノートPC内蔵マイクでも認識可能ですが雑音が多く認識率が下がります。専用の指向性マイクを利用すると雑音が少なく認識率が良くなります。クライアント別にマイクが選択できるようWebRTCで実装しました。
実装イメージは下記となります。

navigator.mediaDevices.enumerateDevicesでデバイスリストを取得し必要な部分のみ加工しHTMLへ表示させる形です。コードは下記となります。
<select id="audioSource"></select>const audioInputSelect = document.querySelector('select#audioSource');
const selectors = [audioInputSelect];
// Get device list and show list on select button
function gotDevices(deviceInfos) {
// Handles being called several times to update labels. Preserve values.
const values = selectors.map(select => select.value);
selectors.forEach(select => {
while (select.firstChild) {
select.removeChild(select.firstChild);
}
});
for (let i = 0; i !== deviceInfos.length; ++i) {
const deviceInfo = deviceInfos[i];
const option = document.createElement('option');
option.value = deviceInfo.deviceId;
if (deviceInfo.kind === 'audioinput') {
option.text = deviceInfo.label || `microphone ${audioInputSelect.length + 1}`;
audioInputSelect.appendChild(option);
}
}
selectors.forEach((select, selectorIndex) => {
if (Array.prototype.slice.call(select.childNodes).some(n => n.value === values[selectorIndex])) {
select.value = values[selectorIndex];
}
});
}
// Create device list
navigator.mediaDevices.enumerateDevices().then(gotDevices);下記ページを参考にさせて頂きました。
https://webrtc.github.io/samples/src/content/devices/input-output/
8.各種比較結果
ESPnet2 学習済みモデル
(1)kan-bayashi/csj_asr_train_asr_transformer_raw_char_sp_valid.acc.ave
コーパス:CSJ、言語:日本語、容量:411MB、周波数:16kHz、訓練時間:45時間、必要GPUメモリ:1.7GB
【結果】日本語認識率○、特定の不得意な単語あり
(2)Shinji Watanabe/laborotv_asr_train_asr_conformer2_latest33_raw_char_sp_valid.acc.ave
Watanabe/laborotv_asr_train_asr_conformer2_latest33_raw_char_sp_valid.acc.ave
コーパス:LaboroTV、言語:日本語、容量:611MB、周波数:16kHz、訓練時間:2,049 時間、必要GPUメモリ:1.7GB
【結果】日本語認識率◎、全く異なる文章に変換する場合あり
(3)Hoon Chung/jsut_asr_train_asr_conformer8_raw_char_sp_valid.acc.ave
コーパス:JSUT、言語:日本語、容量:212MB、周波数:16kHz、訓練時間:10時間
【結果】認識率✕、学習データが少ないと思います
→(1)または(2)を利用するのが良いと思います。
その他学習済モデル
https://github.com/espnet/espnet_model_zoo/blob/master/espnet_model_zoo/table.csv
taskはASR、lnagはjpを選びます。※fs(周波数)に注意ください。
音声区間検出(Voice Activity Detector)
(1)inaSpeechSegmenter
ffmpegのインストールが必要となります。wav audio形式の入力はできますがnumpy形式は不可。別途Numpy形式を入力できるよう改修が必要となります。またnumpy, typing-extensionsがデグレードするためお勧めできません。
参考:https://www.ai-shift.co.jp/techblog/1686
(2)silero-vad
PyTorchとの相性がよく実装が容易です。子音部分をはっきり検知するため誤認識が少なく不要な単語別れもない為まとまった文で区切られます。
参考:https://pytorch.org/hub/snakers4_silero-vad_vad/
(3)pyannote-audio
話者ダイアリゼーションを得意としています。複数の話者が話している音声データを解析し話者を識別することが可能です。ただしその分解析処理に時間を要します。リアルタイム性に課題はありますが議事録作成に非常に有用と思います。
参考:https://github.com/pyannote/pyannote-audio
→今回は(2)silero-vadを利用し音声区間検出を実装しました。
9.開発環境準備
開発はWindows 10がインストールされたノートPC1台(+Bluetoothマイク)で進めます。全てを1台で完結させるためCPUパワーを必要としますが高速にデバッグ可能です。
(1)Anacondaインストール
下記ページを参考にインストールします。
https://www.javadrive.jp/python/install/index5.html#section1
(2)必要なパッケージインストール
Anacondaプロンプトを起動し必要なパッケージをインストールします。

conda install pytorch torchaudio cpuonly -c pytorch
conda install -c conda-forge fastapi python-multipart
conda install -c conda-forge uvicorn[standard]
conda install aiofiles jinja2
pip3 install espnet_model_zoo
pip3 install SoundFile(3)仮想環境作成
base環境をコピーし開発用の環境を作成します。
conda create -n poc --clone base
conda activate poc(4)アプリケーションダウンロード
conda install -c anaconda git
git clone https://github.com/masayay/maispeech.git(5)Config編集
[1] maifaceへ移動リネーム
conf_sample_win.pyをconf.pyへリネーム
[2] フォルダ作成&必要に応じてconf修正
C:\User\Music\wav
C:\User\Music\models(6)Uvicornでアプリケーション起動
[1] アプリケーションディレクトリへ移動
cd maispeech
[2] アプリケーション起動
uvicorn speech_api:app下記メッセージが表示されれば起動成功です。
SpeechRecognition started on device: cpu
Using legacy_rel_pos and it will be deprecated in the future.
Started server process
Waiting for application startup.
Application startup complete.
Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)マイクに向かって話すと下記のようにログが流れます。
DEBUG:uvicorn:Speech Recognition: テスト
DEBUG:uvicorn:Speech Recognition: YouTube(7)接続テスト
ブラウザでhttp://127.0.0.1:8000/を開きます。
※http://127.0.0.1:8000/は手順(1)~(6)実施後アクセス可能です。
※ブラウザよりマイクのアクセス許可を求めらますので「許可」します。
(8)認識結果比較
左が今回作成した音声認識ウェブサーバーで右側がWeb Speech APIを利用した結果となります。かなり等しい結果が出力されるよう作成できたと思います。

10.所感
顔認証、音声認識を提供するWebサーバーを構築し、バックエンドの機械学習部分は異なる知識が必要だと感じました。顔認証では画像から特徴を見つけ、音声認識では波形から特徴を見つけ学習します。しかしこの異なる分野も機械学習の登場により共通部分が増えて来ていると感じました。
関連記事はこちら
ブログの著者欄
柳 匡哉
GMOインターネット株式会社
GPUを活用したホスティングサービスの基盤設計および開発を担当しています。オンプレミスとパブリッククラウドを組み合わせたハイブリッドインフラの設計・構築に携わっており、コンテナ技術やTerraform、Ansibleを活用した自動化・スケーラビリティの高い環境構築を得意としています。
採用情報


関連記事
-

コードレビュー不要論 ーハーネスが人間の目を代替するとき
技術情報
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート後編】
イベント
-

【2025国際ロボット展 出展レポート】AI ❤ ROBOTs で描く、人とロボットが共存する社会
技術情報
-

【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-

ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

【イベントレポート・後編】GMO Developers Day 2025 -Creators Night-|共創するデザイン組織と次世代クリエイターの可能性
デザイン

KEYWORD
CATEGORY
-
技術情報(579)
-
イベント(224)
-
カルチャー(57)
-
デザイン(60)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- Behind the Scenes
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOインターネットグループ陸上部 – GMOロボッツ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMOロボッツ
- GMO大会議
- Go
- Good Morning
- GPU
- GPUクラウド
- GTB
- Hack-1グランプリ
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 技術書典20
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 映像制作
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP






採用情報
SNS FOLLOW
