
本記事はGMOインターネットグループで複数ある開発者ブログのなかから人気の記事をピックアップして再掲載しています。機械学習や深層学習のビジネス応用を研究、社会実装をしているグループ研究開発本部 AI研究開発室のデータサイエンティストが寄稿した人気記事です。
目次
結論ファースト
A. ベクターストアに入れる元ネタドキュメントの抽出
⇒ unstructured が使えるかも
B. ベクターストアに入れる元ネタドキュメントのチャンク分け
⇒ タイトル。キーワードをメタデータで付加
C. ベクターストアに投げる質問プロンプトの最適化
⇒ 形態素またはキーワード抽出でプロンプトを精査
D. ベクターストア検索結果の精査
⇒ ContextualCompressionRetriever による検索結果要約とDocumentCompressorPipeline による検索結果絞り込みがよさげ
「検索結果が質問に沿ったものか精査させる」タスクをChatGPTに担当してもらうことが私の業務課題には適しているのではという気付きがありました。
E. (おまけ)ベクターストアの選定
⇒ 1位はFaiss。マネージドも多々あり。Chromaがこれから来るかも。
ChatGPT 活用に関する問題意識
プロジェクト管理者にとっての ChatGPT 活用
ChatGPT はシステム開発の現場でも非常に役に立っていますが、現在の利用範囲は「個別のコードの生成」や「レビュー」など、どちらかというと小さく限定されたタスクが多いと思います。
私はプロジェクト管理をしている立場なので、自分自身の業務で ChatGPT を活かすにはもっと広い視点でアイディアを出す必要性を感じています。
最終的には以下のような業務に ChatGPT を活用できないかと日々妄想し、勉強会や Web 検索に勤しんでいます。
- 指定した仕様でプロジェクトのコードを実装してもらう。
- ソースコードを読み込んで仕様に関するQAを回答する。
- 仕様に関するドキュメントを読み込んでソースレビューをする。
- 既存ソースコードを読み込んでソースレビューをする。
- ソースコードや仕様ドキュメントを読み込んで該当機能の影響範囲を特定する。
今回は「影響範囲の調査」にフォーカスして考えてみようと思います。
まだ道半ばですが、現在わかっている手法のいくつかをご紹介していきます。
In-Context Learning を突き詰める必要性
2023年7月の公式発表で ChatGPT 3.5 Turbo と 4 の Fine Tuning が2023年後半に利用可能になるかもという情報が公表されました。
“We are working on safely enabling fine-tuning for GPT-4 and GPT-3.5 Turbo and expect this feature to be available later this year.”
「私たちは GPT-4 および GPT-3.5 Turbo の微調整を安全に有効にすることに取り組んでおり、この機能は今年後半に利用可能になる予定です。」
https://openai.com/blog/gpt-4-api-general-availability
Fine Tuning は ChatGPT に特定の知識を身に着けさせる「追加学習」です。
こちらに関してまだ古いモデルである GPT3 でしか提供されておらず事例も少なくなっており、わかっていないことがたくさんあります。
1つの疑念として、 ChatGPT は少しの情報を与えた程度では専門的な知識を覚えてくれないのではというのがあります。例えば、自社のシステム仕様情報を Fine Tuning で覚えさせても、そもそもの元の学習データには似たような情報が膨大に入っており、そちらに引っ張られて結局一般的なことを回答してしまう、もっと言うとありもしない幻覚を回答するリスクはどこまでいっても残り続ける可能性があるのではという話を聞きました。
Fine Tuning とは別のアプローチとして、「都度学習」 としての In-Context Learning があります。これはプロンプトに都度必要な情報を全部含めてしまうことでChatGPTが正確な回答を生成しやすくするという手法です。
現状は Fine Tuning の可能性が不透明なことから、In-Context Learning を突き詰めて精度を向上していく必要性が当面は継続するという見方もできると考えています。
In-Context Learning の事例は巷に溢れており(現実的に2023年7月現在はこれしか有効な手法がないというのがある)、特に Python では LangChain や Llamaindex などのフレームワークがありますが、結局は「 ChatGPT のプロンプトの中に別のデータソースから得た情報を埋め込んでいく」という手法に集約されます。
私のプロジェクト管理業務の改善に大きく関連する話では Pinecone 社が出している以下の事例が興味深いです。
GPT4にLangChainのソースコードに関する質問を回答させる
https://github.com/pinecone-io/examples/blob/master/generation/gpt4-retrieval-augmentation/gpt-4-langchain-docs.ipynb
本質的にはこれに近いことを自社のプロジェクトの仕様ドキュメント+ソースコードで実現したい、というのが現在の私の目指すゴールになると思います。
In-Context Learning で利用するベクターストアの現実的な課題
LangChain でも Llamaindex でも内部的に外部データソースで情報検索をすることで In-Context Learning を実現しています。このデータソースの実現方法はいくつかあるのですが、特に特定のプロジェクトの情報を格納する目的では自前でのベクターストア構築が本命になると思います。
ベクターストアは文書をベクトル化して保存し検索された単語との関連度を高速に判定することで精度の高い検索ができる検索エンジンです。(種類はいくつかあるので終盤で少し紹介します)
ただ、ベクターストアは検索エンジンのため、その活用にあたり以下のような初期的な課題に直面します。(今回のメインコンテンツです)
A. ベクターストアに入れる元ネタドキュメントの抽出
B. ベクターストアに入れる元ネタドキュメントのチャンク分け
C. ベクターストアに投げる質問プロンプトの最適化
D. ベクターストアからのレスポンス精査
E. (おまけ)ベクターストアの選定
ここからこれらひとつひとつをどのように解決できるか、調査・検証した内容をご紹介していきます。
A. ベクターストアに入れる元ネタドキュメントの抽出
ここでいう元ネタドキュメントは、仕様情報やソースコードなど ChatGPT が few shot の In-Context Learning のためにプロンプトに入れて送る情報です。
まずはベクターストアに登録する事前準備として、この元ネタドキュメント情報をプログラムから扱いやすいように抽出・整形する必要があります。
unstructured ライブラリ
私の担当には Atlassian の Confluence を使って仕様ドキュメントを管理しているプロジェクトがあり、こちらはページ全体を HTML または PDF で出力できます。
HTMLまたはPDFのドキュメントをどうやってパースしてテキストドキュメント化するのかという課題がありますが、 unstructured という Python ライブラリがありました。
公式ページ
https://www.unstructured.io/
こちらを使うと PDF、HTML だけでなく Excel や md からのドキュメントからでも個別のプレーンなテキストを生成できます。
対応しているドキュメント種別は公式に記載があります。
https://unstructured-io.github.io/unstructured/bricks.html#partitioning
具体例として、弊社 VPS サービスの Conoha API ドキュメントをHTMLとPDFにして練習してみます。
トークン取得API
https://www.conoha.jp/docs/identity-post_tokens.php
コードは至ってシンプルです。
from unstructured.partition.html import partition_html
elements = partition_html("conoha_api_token.html")
print("\n\n".join([str(el) for el in elements]))HTMLからドキュメントを抽出した結果(長いので折りたたまれています)
MENU
TOP
Identity API v2.0
バージョン情報取得
バージョン情報詳細取得
トークン発行
Account(Billing) API v1
バージョン情報取得
バージョン情報詳細取得
アイテム一覧の取得
アイテム詳細取得(アイテム指定)
入金履歴取得
入金サマリー取得
請求データ一覧取得
請求データ明細取得(アイテム指定)
告知一覧取得
告知詳細取得(アイテム指定)
告知既読・未読変更
Object Storage 利用状況グラフ(リクエスト数)
Object Storage 利用状況グラフ(使用容量数)
Compute API v2
バージョン情報取得
バージョン情報詳細取得
VMプラン一覧取得
VMプラン詳細取得
VMプラン詳細取得(アイテム指定)
VM一覧取得
VM一覧詳細取得
VM詳細取得(アイテム指定)
VM追加
VM削除
VM起動
VM再起動
VM強制停止
VM通常停止
OS再インストール
VMリサイズ
VMリサイズ(confirm)
VMリサイズ(revert)
VNCコンソール
ローカルディスクのイメージ保存
ストレージコントローラー変更
ネットワークアダプタ変更
ビデオデバイスの変更
コンソールのキーマップ変更
WebSocket(novaconsole)用のAPI
WebSocket(httpconsole)用のAPI
ISOイメージの挿入(mount)
ISOイメージの排出(unmount)
セキュリティグループのサーバへの割り当て状態表示
キーペア一覧取得
キーペア詳細取得(アイテム指定)
キーペア追加
キーペア削除
イメージ一覧取得(nova)
イメージ詳細取得
イメージ詳細取得(アイテム指定)(nova)
アタッチ済みボリューム一覧
アタッチ済みボリューム取得(アイテム指定)
ボリュームアタッチ
ボリュームデタッチ
アタッチ済みポート一覧取得
アタッチ済みポート取得(アイテム指定)
ポートアタッチ
ポートデタッチ
VMメタデータの更新(ネームタグの変更)
VMメタデータ取得
VMに紐づくアドレス一覧
VMに紐づくアドレス一覧(ネットワーク指定)
VPS利用状況グラフ(CPU使用時間)
VPS利用状況グラフ(インターフェイストラフィック)
VPS利用状況グラフ(ディスクIO)
バックアップ一覧取得
バックアップ一覧取得(backup id 指定)
バックアップの申し込み
バックアップの解約
ブートディスクバックアップのリストア
ブート・追加ディスクバックアップのイメージ保存
ISOイメージの一覧
ISOイメージダウンロード
Block Storage API v2
バージョン情報取得
バージョン情報詳細取得
ボリュームタイプ一覧取得
ボリュームタイプ取得(アイテム指定)
ボリューム一覧取得
ボリューム詳細取得
ボリューム詳細取得(アイテム指定)
ボリューム作成
ボリューム作成(ソースボリューム指定)
ボリューム削除
ブロックディスクのイメージ保存
Image API v2
バージョン情報取得
イメージ一覧取得(Glance)
イメージ詳細取得(アイテム指定)(glance)
イメージコンテナのスキーマ情報取得
イメージのスキーマ情報取得
イメージメンバーコンテナのスキーマ情報取得
イメージメンバーのスキーマ情報取得
イメージメンバー一覧取得
イメージ削除
イメージ保存容量制限
イメージ保存容量制限情報取得
Network API v2.0
バージョン情報取得
バージョン情報詳細取得
ネットワーク一覧取得
ネットワーク詳細取得
ネットワーク追加(ローカルネット用)
ネットワーク削除
ポート一覧取得
ポート詳細取得
ポート追加
ポート更新
ポート削除
サブネット一覧取得
サブネット詳細取得
サブネットの払い出し(ローカルネット用)
サブネットの払い出し(追加IP用)
サブネットの払い出し(LB用)
サブネットの削除
POOL一覧取得
POOL詳細取得
POOL追加(バランシング指定)
POOL更新(バランシング方式の変更)
POOL削除
VIP一覧取得
VIP詳細取得
VIP作成
VIP削除
REAL(member)一覧取得
REAL(member)詳細取得
REAL(member)追加
REAL(member)更新
REAL(member)削除
ヘルスモニタ一覧取得
ヘルスモニタ詳細取得
ヘルスモニタ作成
ヘルスモニタ変更
ヘルスモニタ削除
ヘルスモニタの関連付け
ヘルスモニタの関連付け解除
セキュリティグループ一覧取得
セキュリティグループ詳細取得
セキュリティグループ作成
セキュリティグループ更新
セキュリティグループ削除
セキュリティグループ ルール一覧取得
セキュリティグループ ルール詳細取得
セキュリティグループ ルール作成
セキュリティグループ ルール削除
ObjectStorage API v1
アカウント情報取得
アカウントクォータ設定
コンテナ情報取得
コンテナ作成
コンテナ削除
オブジェクト情報取得
オブジェクトアップロード
オブジェクトダウンロード
オブジェクト複製
オブジェクト削除
dynamic large objects
static Large Object
object versioning
schedule objects for deletion
temporary url middleware
web publishing
Database API v1
バージョン情報取得
バージョン情報詳細取得
サービス作成
サービス一覧取得
サービス情報取得
サービス更新
サービス削除
サービスメタデータ更新
データベース上限値取得
データベース上限値変更
バックアップ有効無効
データベース作成
データベース一覧取得
データベース情報取得
データベース更新
データベース削除
データベース権限作成
データベース権限一覧取得
データベース権限削除
バックアップ一覧
リストア
アカウント作成
アカウント一覧取得
アカウント情報取得
アカウント更新
アカウント削除
DNS API v1.0
バージョン情報取得
ドメインホスティング情報表示
ドメイン一覧表示
ドメイン作成
ドメイン削除
ドメイン情報表示
ドメイン更新
レコード一覧取得
レコード作成
レコード削除
レコード情報表示
レコード更新
ゾーンファイルインポート
ゾーンファイルエクスポート
ConoHa API Documantation
トークン発行 – Identity API v2.0
トークン発行 – Identity API v2.0
TOP
Identity API v2.0
バージョン情報取得
バージョン情報詳細取得
トークン発行
Account(Billing) API v1
バージョン情報取得
バージョン情報詳細取得
アイテム一覧の取得
アイテム詳細取得(アイテム指定)
入金履歴取得
入金サマリー取得
請求データ一覧取得
請求データ明細取得(アイテム指定)
告知一覧取得
告知詳細取得(アイテム指定)
告知既読・未読変更
Object Storage 利用状況グラフ(リクエスト数)
Object Storage 利用状況グラフ(使用容量数)
Compute API v2
バージョン情報取得
バージョン情報詳細取得
VMプラン一覧取得
VMプラン詳細取得
VMプラン詳細取得(アイテム指定)
VM一覧取得
VM一覧詳細取得
VM詳細取得(アイテム指定)
VM追加
VM削除
VM起動
VM再起動
VM強制停止
VM通常停止
OS再インストール
VMリサイズ
VMリサイズ(confirm)
VMリサイズ(revert)
VNCコンソール
ローカルディスクのイメージ保存
ストレージコントローラー変更
ネットワークアダプタ変更
ビデオデバイスの変更
コンソールのキーマップ変更
WebSocket(novaconsole)用のAPI
WebSocket(httpconsole)用のAPI
ISOイメージの挿入(mount)
ISOイメージの排出(unmount)
セキュリティグループのサーバへの割り当て状態表示
キーペア一覧取得
キーペア詳細取得(アイテム指定)
キーペア追加
キーペア削除
イメージ一覧取得(nova)
イメージ詳細取得
イメージ詳細取得(アイテム指定)(nova)
アタッチ済みボリューム一覧
アタッチ済みボリューム取得(アイテム指定)
ボリュームアタッチ
ボリュームデタッチ
アタッチ済みポート一覧取得
アタッチ済みポート取得(アイテム指定)
ポートアタッチ
ポートデタッチ
VMメタデータの更新(ネームタグの変更)
VMメタデータ取得
VMに紐づくアドレス一覧
VMに紐づくアドレス一覧(ネットワーク指定)
VPS利用状況グラフ(CPU使用時間)
VPS利用状況グラフ(インターフェイストラフィック)
VPS利用状況グラフ(ディスクIO)
バックアップ一覧取得
バックアップ一覧取得(backup id 指定)
バックアップの申し込み
バックアップの解約
ブートディスクバックアップのリストア
ブート・追加ディスクバックアップのイメージ保存
ISOイメージの一覧
ISOイメージダウンロード
Block Storage API v2
バージョン情報取得
バージョン情報詳細取得
ボリュームタイプ一覧取得
ボリュームタイプ取得(アイテム指定)
ボリューム一覧取得
ボリューム詳細取得
ボリューム詳細取得(アイテム指定)
ボリューム作成
ボリューム作成(ソースボリューム指定)
ボリューム削除
ブロックディスクのイメージ保存
Image API v2
バージョン情報取得
イメージ一覧取得(Glance)
イメージ詳細取得(アイテム指定)(glance)
イメージコンテナのスキーマ情報取得
イメージのスキーマ情報取得
イメージメンバーコンテナのスキーマ情報取得
イメージメンバーのスキーマ情報取得
イメージメンバー一覧取得
イメージ削除
イメージ保存容量制限
イメージ保存容量制限情報取得
Network API v2.0
バージョン情報取得
バージョン情報詳細取得
ネットワーク一覧取得
ネットワーク詳細取得
ネットワーク追加(ローカルネット用)
ネットワーク削除
ポート一覧取得
ポート詳細取得
ポート追加
ポート更新
ポート削除
サブネット一覧取得
サブネット詳細取得
サブネットの払い出し(ローカルネット用)
サブネットの払い出し(追加IP用)
サブネットの払い出し(LB用)
サブネットの削除
POOL一覧取得
POOL詳細取得
POOL追加(バランシング指定)
POOL更新(バランシング方式の変更)
POOL削除
VIP一覧取得
VIP詳細取得
VIP作成
VIP削除
REAL(member)一覧取得
REAL(member)詳細取得
REAL(member)追加
REAL(member)更新
REAL(member)削除
ヘルスモニタ一覧取得
ヘルスモニタ詳細取得
ヘルスモニタ作成
ヘルスモニタ変更
ヘルスモニタ削除
ヘルスモニタの関連付け
ヘルスモニタの関連付け解除
セキュリティグループ一覧取得
セキュリティグループ詳細取得
セキュリティグループ作成
セキュリティグループ更新
セキュリティグループ削除
セキュリティグループ ルール一覧取得
セキュリティグループ ルール詳細取得
セキュリティグループ ルール作成
セキュリティグループ ルール削除
ObjectStorage API v1
アカウント情報取得
アカウントクォータ設定
コンテナ情報取得
コンテナ作成
コンテナ削除
オブジェクト情報取得
オブジェクトアップロード
オブジェクトダウンロード
オブジェクト複製
オブジェクト削除
dynamic large objects
static Large Object
object versioning
schedule objects for deletion
temporary url middleware
web publishing
Database API v1
バージョン情報取得
バージョン情報詳細取得
サービス作成
サービス一覧取得
サービス情報取得
サービス更新
サービス削除
サービスメタデータ更新
データベース上限値取得
データベース上限値変更
バックアップ有効無効
データベース作成
データベース一覧取得
データベース情報取得
データベース更新
データベース削除
データベース権限作成
データベース権限一覧取得
データベース権限削除
バックアップ一覧
リストア
アカウント作成
アカウント一覧取得
アカウント情報取得
アカウント更新
アカウント削除
DNS API v1.0
バージョン情報取得
ドメインホスティング情報表示
ドメイン一覧表示
ドメイン作成
ドメイン削除
ドメイン情報表示
ドメイン更新
レコード一覧取得
レコード作成
レコード削除
レコード情報表示
レコード更新
ゾーンファイルインポート
ゾーンファイルエクスポート
Description
有効なトークン情報を取得する
Request URL
Request Paramters
username
ユーザー名
plain
ユーザ名
password
ユーザーパスワード
plain
ユーザパスワード
tenantId (Optional)
Tenant ID
plain
テナントID
Request Json
Normal response codes
200 OK
Example
※エンドポイントURLにつきましては、お客様環境によって異なりますので、コントロールパネルにてご確認の上ご利用ください。
REQ
RES
ConoHa WING
トップ
料金・仕様
特長
機能
ドメイン
ご利用の流れ
導入事例
お申し込み
ConoHa VPS
トップ
料金・仕様
特長
機能
ご利用の流れ
導入事例
お申し込み
ConoHa for Windows Server
トップ
料金・仕様
特長
ご利用の流れ
お申し込み
ConoHa for GAME
トップ
料金・仕様
特長
ご利用の流れ
お申し込み
おすすめ情報
ConoHa Mobile
ConoHaカード
ConoHa学割
ConoHaデビュー割
採用情報
美雲このはオフィシャルサイト
ワプ活
マイクラゼミ
美雲このは徹底ガイド
サポート
トップ
ConoHa WINGサポート
ConoHa VPSサポート
ConoHa for Windows Serverサポート
用語集
会員規約
ConoHaドメイン登録規約
ConoHaチャージ利用規約
ConoHaクーポン利用規約
特定商取引法に基づく表記
資金決済法に基づく表示
サービス品質保証制度(SLA)
お問い合わせ
プライバシーポリシー
Cookieポリシー
会社概要
Copyright © 2023 GMO Internet Group, Inc. All Rights Reserved.
from unstructured.partition.pdf import partition_pdf
elements = partition_pdf("conoha_api_token.pdf")
print("\n\n".join([str(el) for el in elements]))PDFからドキュメント抽出結果(長いので折りたたまれています)
トークン発⾏ – Identity API v2.0|ConoHa API
法⼈⼝座即⽇ > GMOあおぞらネット銀⾏ CFD国内1位 > GMOクリック証券 国内1位 > 電⼦印鑑GMOサイン 夢を応援 > 起業の窓⼝ byGMO
ConoHa API Documantation
トークン発行 – Identity API v2.0
トークン発行 – Identity API v2.0
Description
TOP
有効なトークン情報を取得する
Identity API v2.0
バージョン情報取得
バージョン情報詳細取得
Request URL
トークン発行
Account(Billing) API v1
identity API v2.0
Compute API v2
POST /v2.0/tokens
Block Storage API v2
Image API v2
Network API v2.0
Request Paramters
ObjectStorage API v1
Parameter
Value
Style
Description
Database API v1
username
ユーザー名
plain
ユーザ名
DNS API v1.0
password
ユーザーパスワード
plain
ユーザパスワード
tenantId (Optional)
Tenant ID
plain
テナントID
Request Json
{
“auth”: {
“passwordCredentials”: {
“username”: “ConoHa”,
“password”: “paSSword123456#$%”
},
“tenantId”: “487727e3921d44e3bfe7ebb337bf085e”
}
}
Normal response codes
200 OK
Example
※エンドポイントURLにつきましては、お客様環境によって異なりますので、コン
トロールパネルにてご確認の上ご利用ください。
REQ
curl -i -X POST \
H “Accept: application/json” \
d ‘{“auth”:{“passwordCredentials”:{“username”:”ConoHa”,”password”:”paSSword123456#$%”},”
https://identity.tyo1.conoha.io/v2.0/tokens
RES
HTTP/1.1 200 OK
Date: Mon, 08 Dec 2014 02:40:56 GMT
Server: Apache
Content-Length: 4572
Content-Type: application/json
{
“access”: {
“token”: {
“issued_at”: “2015-05-19T07:08:21.927295”,
“expires”: “2015-05-20T07:08:21Z”,
“id”: “sample00d88246078f2bexample788f7”,
“tenant”: {
“name”: “example00000000”,
“enabled”: true,
“tyo1_image_size”: “550GB”,
}
],
“endpoints_links”: [],
“type”: “mailhosting”,
“name”: “Mail Hosting Service”
},
{
“endpoints”: [
{
“region”: “tyo1”,
“publicURL”: “https://dns-service.tyo1.conoha.io”
}
],
“endpoints_links”: [],
“type”: “dns”,
“name”: “DNS Service”
},
{
“endpoints”: [
{
“region”: “tyo1”,
“publicURL”: “https://object-storage.tyo1.conoha.io/v1/nc_a4392c0ccba74485abd
}
],
“endpoints_links”: [],
“type”: “object-store”,
“name”: “Object Storage Service”
},
{
“endpoints”: [
{
“region”: “sjc1”,
“publicURL”: “https://identity.sjc1.conoha.io/v2.0”
},
{
“region”: “tyo1”,
“publicURL”: “https://identity.tyo1.conoha.io/v2.0”
},
{
“region”: “sin1”,
“publicURL”: “https://identity.sin1.conoha.io/v2.0”
}
],
“endpoints_links”: [],
“type”: “identity”,
“name”: “Identity Service”
}
],
“user”: {
“username”: “example00000000”,
“roles_links”: [],
“id”: “examplea6963c074d7csample12a886ee”,
“roles”: [
{
“name”: “SwiftOperator”
},
{
“name”: “_member_”
}
],
“name”: “example00000000”
},
“metadata”: {
“is_admin”: 0,
“roles”: [
“0000000000000000000000000000000e”,
“11111111111111111111111111111113”
]
}
}
}
ConoHa for Windows Server
ConoHa WING
ConoHa VPS
ConoHa for GAME
おすすめ情報
サポート
トップ
トップ
トップ
トップ
ConoHa Mobile
トップ
料金・仕様
料金・仕様
料金・仕様
料金・仕様
ConoHaカード
ConoHa WINGサポー
ト
特長
特長
特長
特長
ConoHa学割
ConoHa VPSサポート
機能
機能
ご利用の流れ
ご利用の流れ
ConoHaデビュー割
ConoHa for Windows
ドメイン
ご利用の流れ
お申し込み
お申し込み
採用情報
Serverサポート
ご利用の流れ
導入事例
美雲このはオフィシャ
用語集
ルサイト
導入事例
お申し込み
ワプ活
お申し込み
マイクラゼミ
美雲このは徹底ガイド
会員規約 | ConoHaドメイン登録規約 | ConoHaチャージ利用規約 | ConoHaクーポン利用規約 | 特定商取引法に基づく表記 | 資金決済法に基づく表示 | サービス品質保証制度(SLA) | お問い合わせ | プライバシーポリシー | Cookieポリシー | 会社概要
Copyright © 2023 GMO Internet Group, Inc. All Rights Reserved.
https://www.conoha.jp/docs/identity-post_tokens.php
1/1
上記の2つとも何とか取れていますが、パッと見、ちゃんとできているのかよくわからないw
以下、結果をしっかり読んだ考察です。
[HTML 取込結果]
・必要のない MENU ががっつり入っている。そのせいか、本題以外の文章がとても多い。
・重要な curl や JSON の情報なし。
[PDF 取込結果]
・MENU なし。
・curl や JSON あり。
これだけ見ると PDF 一択のようにも見えます。
HTML 側の問題回避のアプローチとして以下のような方法がある思います。
・MENU など不要な文書をカットするために別のスクリプトを書いてノイズを除去する
・ノイズ除去自体を ChatGPT にやってもらう
具体的なチューニングまで踏み込めていないのですが、より効率的なデータ抽出のためさらなる検証を継続していこうと思います。
ひとまず元ネタのドキュメントから「文字」データは取れますよねというところができるようになりました。
B. ベクターストアに入れる元ネタドキュメントのチャンク分け
元ネタドキュメントは分割して、 ChatGPT のプロンプトに In-Context として入れやすい小さな塊(=チャンク)にしておく必要があります。
この分割は人間が作る、が当然確実なのですが、現実的課題として100だの1000だのというレベルの大量の既存文書を機械的にチャンク化せざるを得ない状況が発生すると思います。
手法としては以下の2点が重要なポイントになります。
・元ネタドキュメントの章やページなどの単位でチャンクを分けて、なるべく意味の塊をキープする。
・タイトルやキーワードといった文章のメタデータを先頭に付加する。
1回に Embbeding 可能な文章量
ベクターストアに入れるデータは OpenAI の text-embedding-ada-002 でベクトル化を行いますが、こちらは1回に8191トークンが上限です。
目安としては5000文字が1回の Embbeding でベクトル化できます。
(トークンのカウントは漢字が入ると増えてしまうため TikToken ライブラリで行ったほうが確実です。)
ChatGPT への質問プロンプトで送ることができるトークン数と文字数の目安は以下の通りです。
gpt-4-0613 : 8,192 tokens (5000文字)
gpt-4-32k-0613 : 32,768 tokens (20000文字)
gpt-3.5-turbo-0613 : 4,096 tokens (2500文字)
gpt-3.5-turbo-16k : 16,384 tokens (10000文字)
チャンクサイズとRefine
どのぐらいの文章の塊をプロンプトとして ChatGPT に送るべきなのか、という重要な問いを考える上で、私は Refine を前提とした1チャンクの大きさは300文字から1000文字程度のある程度意味のまとまった文章の塊にするといいのではという仮説で進めています。
Refine とは異なるデータを乗せたプロンプトで会話を複数回繰り返し、回答を少しずつ洗練する手法です。
Refine に関連する回答生成の手法としては以下のような選択肢があります。
・1つの大きなチャンクに全部を入れ込む。
・1つの大きなチャンクを複数回送る。(Refine)
・複数の小さなチャンクをマージして送る。
・複数の小さなチャンクをマージしたものを複数回送る。(Refine)
Refine は繰り返し処理のためコスト+処理時間がかかってしまうのがマイナス点なのですが、精度を上げる手法としては一定の効果があると今のところは感じています。最適なチャンクサイズを見つけるには、自分の扱うドキュメントと質問の特性に応じたサイズ検証を設計して、試しながらチューニングしていく他ないと思います。
unstructured でメタデータを入れ込む
unstructured で自動的にチャンクを作る方法もあります。
こちらは元ネタドキュメントを Elements という文節ごとに区切ってリスト化してくれるので、 1 Element = 1 Chunk として利用する事例もありました。
ただ、私は元ネタドキュメントのほうがこの手法と相性が合わなかったようでどうもうまくいきませんでした。先ほどの PDF と HTML の例では文節の Element がいずれもほぼ単語レベルの小さすぎる分割になってしまいました。ここまで小さくなると意味の塊としては用をなしえません。
JSON の塊もバラされて1つ1つの項目が別の Elements になってしまったりしたので、このままでは 1 Element = 1 Chunk のような形式にはできないなと。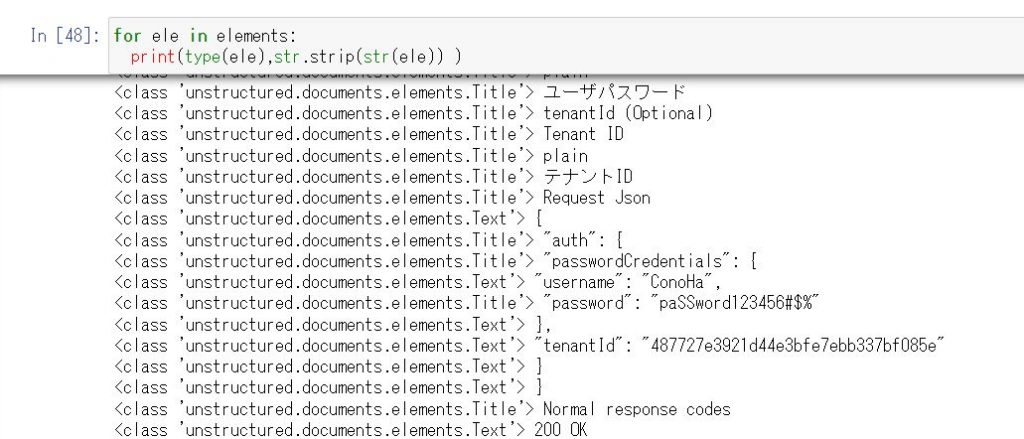
元ネタドキュメントは1ページ全体が小さいので Elements 全体まとめて 1 chunk するのが丁度よいと感じでした。
(最大で gpt-3.5-turbo でも 2500 文字、 gpt-4-32k-0613 なら 20000 文字はいけるので、金額をかけてもいいから正確さが欲しいという場合はアリかもしれません。要検証)
そうなると登録できる長さを計算し、機械的に一定の長さでループ処理するというのはあながち悪いとも言い切れません。
いい感じに2500文字ぐらいのチャンクを作る事例(PDFから情報をとっている)
https://qiita.com/sakasegawa/items/16714fa132e874cab069
さらに、メタデータのアイディアがあります。
ここでいうメタデータは、タイトルやトピックのキーワードのことです。つまり文章がどんな内容なのかをチャンクの先頭で示し、検索精度を上げようという試みです。
以下で、機械的に文章を分割しながら小見出し的なタイトルをチャンクに入れ込む方法が以下に紹介されています。
https://note.com/mahlab/n/n0a8fa0e1d586#6a22a272-b37f-4153-80cc-ca130bb11597
こちらはチャンクの先頭にタイトルとサブタイトルに相当する情報を文章に付加しています。
このケースでは unstructured でマークダウン(.md)のドキュメントをパースした際に、 title 要素を unstructured の element として取得できる点を活用しています。
私の要件のように HTML が元ネタの場合は、ページの title タグや h1 タグをキーワードとして抽出し、それを先頭に記載するという方法が取れると思います。
(HTML を unstructured でやってみたら本来 titleでないものがたくさんtitle扱いされてしまい結局使えず)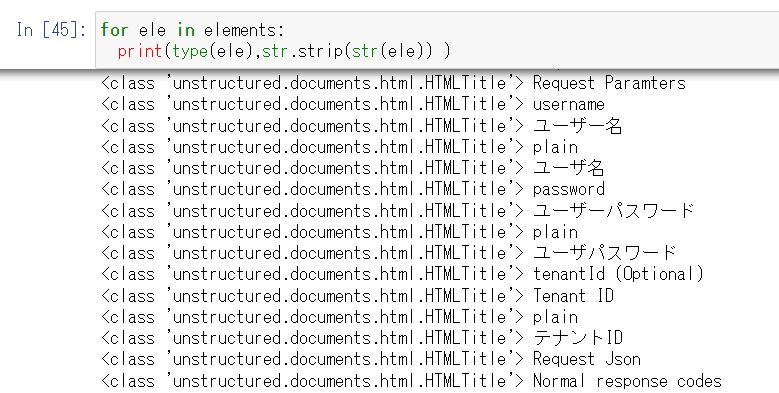
こちらも1つのチャンクには複数のトピックが混ざらないようなもともときれいな内容の分割がされていることがやはり望ましいと言えます。
もう1点、1つ1つのドキュメントの要約を ChatGPT に生成させ、それをチャンクに入れて文章をわかりやすくするというのもアリなのではと思いました。文章が長くはなってしまいますが、より意味の関連度が強められる可能性があります。(検索に効果があるかは未検証)
C. ベクターストアに投げる質問プロンプトの最適化
LangChain でも Llamaindex でも質問文は検索前に Embbedings API でベクター化されてから実行されます。
ただこの質問文は冗長だったり関係ないものを含むと検索結果もブレが生じるので、質問文自体を形態素解析またはキーワード抽出してからベクター検索をするという方法があります。
形態素解析の場合、ライブラリで処理すれば一発です。
from sudachipy import tokenizer
from sudachipy import dictionary
# 人間が入力したプロンプト
question = "トークン取得APIのパラメータを教えてください。"
# 形態素解析モデルの構築
tokenizer_obj = dictionary.Dictionary().create()
mode = tokenizer.Tokenizer.SplitMode.C
# 形態素解析の実行
tokens = tokenizer_obj.tokenize(question, mode)
keywords = []
# keywords
for token in tokens:
# 名詞だけを抽出して格納
if token.part_of_speech()[0] == "名詞":
print(token.surface(), token.part_of_speech()[0])
keywords.append(token.surface())結果以下のようにキーワードを抽出できます。
トークン 名詞 取得 名詞 API 名詞 パラメータ 名詞
また、 pke を使えば重要キーワードを機械的に抽出ができます。
!pip install git+https://github.com/boudinfl/pke.git
!python -m spacy download ja_core_news_sm
import pke
import spacy
text = "トークン取得APIのURLとパラメータを教えてください。"
spacy_model = spacy.load("ja_core_news_sm")
extractor = pke.unsupervised.MultipartiteRank()
extractor.load_document(input=text, language='ja', normalization=None, spacy_model=spacy_model)
extractor.candidate_selection(pos={'NOUN', 'PROPN', 'ADJ', 'NUM'})
extractor.candidate_weighting(threshold=0.76, method='average', alpha=1.1)
print(extractor.get_n_best(5))最終的にスコアの上位5件を絞り込んでいます。
[('url', 0.39361741945785217),
('トークン 取得 api', 0.30319129027107367),
('パラメータ', 0.30319129027107367)]「キーワード抽出」はChatGPTに任せるのもありますが、質問するごとに毎回リクエストすることになる点が気になる点です。
私の想定するユースケースでは簡単な質問文が使われるので、上記の例だけでも充分ではと思います。
D. 検索結果の精査
検索全般の課題として、以下のような点があると思います。
・質問と関係ないドキュメントが検索にヒットしてしまう
・ドキュメントが長いと LLM に In-Context Learning で付与できる文字数を超えてしまう
こうした課題を LangChain ではどのようにアプローチできるでしょうか。
LangChain の Contextual Compression Retriever を使って部分要約をつくる
これは「回答の生成」ではなく「検索結果の精査」のタスクを ChatGPT に担当してもらう方法です。
当初の目的であった、ChatGPT に「検索結果から正確な回答を生成させる」ことは実際結構なチューニングが必要でハードルが高いのですが、「検索結果の精査をする」だけに特化すればある程度は機械的に行える可能性があります。
参考にした情報です。
https://zenn.dev/laiso/articles/f5e5c616e128a7
ここから検証のため、ベクターストア Faiss をセットアップしていきます。
上述の Conoha API ドキュメントから、検索対象となる API の情報を 7 件追加しています。
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import FAISS
def print_docs(docs):
print(f"\n{'-' * 10}\n".join([f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]))
loader = DirectoryLoader('./data_conoha_api', glob="*.txt")
docs = loader.load()
len(docs)7つの API ドキュメントがロードされます。
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
### 初回だけ Embbeding してファイルに保存
## db = FAISS.from_documents(docs, embeddings)
## db.save_local("faiss_index")
# ファイルからFAISSを生成
retriever=FAISS.load_local("faiss_index", embeddings).as_retriever()素の状態でドキュメントを検索した結果です。
# 「トークン取得APIのパラメータをおしえてください。」のプロンプトを形態素解析した結果のキーワードで検索します
# 名詞4つ "トークン 取得 API パラメータ"
q=" ".join(keywords)
docs = retriever.get_relevant_documents(q))
pretty_print_docs(docs)
ベクターストアの検索結果(めちゃくちゃ長いので折りたたまれています)
Document 1:
Conoha API
トークン発行
Identity API v2.0
Description
有効なトークン情報を取得する
Request URL
identity API v2.0
POST /v2.0/tokens
Request Paramters
Parameter Value Style Description
username ユーザー名 plain ユーザ名
password ユーザーパスワード plain ユーザパスワード
tenantId (Optional) Tenant ID plain テナントID
Request Json
{
“auth”: {
“passwordCredentials”: {
“username”: “ConoHa”,
“password”: “paSSword123456#$%”
},
“tenantId”: “487727e3921d44e3bfe7ebb337bf085e”
}
}
Normal response codes
200 OK
Example
※エンドポイントURLにつきましては、お客様環境によって異なりますので、コントロールパネルにてご確認の上ご利用ください。
REQUEST
curl
i
X POST \
H “Accept: application/json” \
d ‘{“auth”:{“passwordCredentials”:{“username”:”ConoHa”,”password”:”paSSword123456#$%”},”tenantId”:”487727e3921d44e3bfe7ebb337bf085e”}}’ \
https://identity.tyo1.conoha.io/v2.0/tokens
RESPONSE HTTP/1.1 200 OK Date: Mon, 08 Dec 2014 02:40:56 GMT Server: Apache Content-Length: 4572 Content-Type: application/json
{
“access”: {
“token”: {
“issued_at”: “2015
05
19T07:08:21.927295″,
“expires”: “2015
05
20T07:08:21Z”,
“id”: “sample00d88246078f2bexample788f7”,
“tenant”: {
“name”: “example00000000”,
“enabled”: true,
“tyo1_image_size”: “550GB”,
}
],
“endpoints_links”: [],
“type”: “mailhosting”,
“name”: “Mail Hosting Service”
},
{
“endpoints”: [
{
“region”: “tyo1”,
“publicURL”: “https://dns
service.tyo1.conoha.io”
}
],
“endpoints_links”: [],
“type”: “dns”,
“name”: “DNS Service”
},
{
“endpoints”: [
{
“region”: “tyo1”,
“publicURL”: “https://object
storage.tyo1.conoha.io/v1/nc_a4392c0ccba74485abd58ec123eca824″
}
],
“endpoints_links”: [],
“type”: “object
store”,
“name”: “Object Storage Service”
},
{
“endpoints”: [
{
“region”: “sjc1”,
“publicURL”: “https://identity.sjc1.conoha.io/v2.0”
},
{
“region”: “tyo1”,
“publicURL”: “https://identity.tyo1.conoha.io/v2.0”
},
{
“region”: “sin1”,
“publicURL”: “https://identity.sin1.conoha.io/v2.0”
}
],
“endpoints_links”: [],
“type”: “identity”,
“name”: “Identity Service”
}
],
“user”: {
“username”: “example00000000”,
“roles_links”: [],
“id”: “examplea6963c074d7csample12a886ee”,
“roles”: [
{
“name”: “SwiftOperator”
},
{
“name”: “_member_”
}
],
“name”: “example00000000”
},
“metadata”: {
“is_admin”: 0,
“roles”: [
“0000000000000000000000000000000e”,
“11111111111111111111111111111113”
]
}
}
}
サービス一覧取得
Database API v1
Description
データベースサービスの一覧を取得します。
Request URL
Database API v1.0
GET /v1/services
Request Paramters
Parameter Value Style Type Description
X
Auth
Token
header string Userトークン
offset(Optional)
query int 取得開始位置 Default:0
limit(Optional)
query int 取得数 Default:1000
sort_key(Optional) service_name/status/create_date query string ソートキー Default:create_date
sort_type(Optional) asc/desc query string ソート順 Default:asc
Response Paramters
Parameter Value Style Type Description
services
list
service_id
plain UUID サービスID
service_name
plain string サービス名
create_date
plain string 作成日時
quota
plain int 使用容量上限値(単位GB)
total_usage
plain float 使用容量合算値(単位GB)、小数点第二位まで表示
status active/suspended/pending/creating/deleting/error plain string ステータス
backup enable/disable plain string バックアップ有効フラグ
prefix
plain string プレフィックス
metadata
plain dict メタデータ キーと値の辞書オブジェクト
total_count
plain int 総件数
current_count
plain int 現在の取得件数
Request Json This operation does not accept a request body.
Normal response codes
200
Success
Error response codes
400
Bad Request
401
Access Denied
Repeatable
Yes
Example
※エンドポイントURLにつきましては、お客様環境によって異なりますので、コントロールパネルにてご確認の上ご利用ください。
REQ
curl
i
X GET \
H “Accept: application/json” \
H “Content
Type: application/json” \
H “X
Auth
Token: 39be9f8d53044388b7f2e867eba8b140″ \
https://database
hosting.tyo1.conoha.io/v1/services
RES HTTP/1.1 200 Success Date: Tue, 09 Dec 2014 01:46:58 GMT Server: Apache Content-Length: 1003 Content-Type: application/json
{
“services” : [
{
“service_id”: “9d6441f6
c5a0
4dcf
a1a9
1a4d724e51fd”,
“service_name”: “dbservice01”,
“create_date”: “2012
11
02T19:56:26Z”,
“quota”: 10,
“total_usage”: 2.25,
“status”: “active”,
“backup”: “disable”,
“prefix” : “02p8y”,
“metadata” : {
“key” : “value”
}
},
{
“service_id”: “ff164ba8
42d1
49d3
a597
a98503f6fd45″,
“service_name”: “dbservice02”,
“create_date”: “2012
11
02T19:56:26Z”,
“quota”: 30,
“total_usage”: 14,
“status”: “active”,
“backup”: “enable”,
“prefix” : “8ypg0”
“metadata” : {
“key” : “value”
}
}
],
“total_count”:100,
“current_count”:10
}
———-
Document 2:
請求データ一覧取得
Account(Billing) API v1
Description
課金アイテムへの請求データ一覧を取得します。
Request URL
billing API v1
GET /v1/{tenant_id}/billing
invoices
Request Paramters
Parameter Value Style Description
X
Auth
Token Userトークン header トークンID
tenant_id Tenant ID URI テナントID
offset(Optional) 取得開始位置 query Default:0
limit(Optional) 取得数 query Default:1000
Example
※エンドポイントURLにつきましては、お客様環境によって異なりますので、コントロールパネルにてご確認の上ご利用ください。
REQ curl -X GET \ -H “Accept: application/json” \ -H “X-Auth-Token: 35941e7df872405d84e5b026dba8323c” \ https://account.tyo1.conoha.io/v1/487727e3921d44e3bfe7ebb337bf085e/billing-invoices?limit=3 RES HTTP/1.1 200 OK Server: openresty/1.7.10.1 Date: Fri, 08 May 2015 12:52:02 GMT Content-Type: application/json Content-Length: 230 Connection: keep-alive
{
“billing_invoices”: [
{
“invoice_id”: 00001,
“payment_method_type”: “Charge”,
“invoice_date”: “2014
08
01T00:00:00″,
“bill_plas_tax”: 500,
“due_date”: “2014
08
01T00:00:00″
},
{
“invoice_id”: 00002,
“payment_method_type”: “Charge”,
“invoice_date”: “2014
07
01T00:00:00″,
“bill_plas_tax”: 500,
“due_date”: “2014
07
01T00:00:00″
},
{
“invoice_id”: 00003,
“payment_method_type”: “Charge”,
“invoice_date”: “2014
06
01T00:00:00″,
“bill_plas_tax”: 500,
“due_date”: “2014
06
01T00:00:00″
}
]
}
}
———-
Document 3:
入金サマリー取得
Account(Billing) API v1
Description
入金のサマリーを取得します。
Request URL
billing API v1
GET /v1/{tenant_id}/payment
summary
Request Paramters
Parameter Value Style Description
X
Auth
Token Userトークン header トークンID
tenant_id Tenant ID URI テナントID
Example
※エンドポイントURLにつきましては、お客様環境によって異なりますので、コントロールパネルにてご確認の上ご利用ください。
REQ curl -i -X GET \ -H “Accept: application/json” \ -H “X-Auth-Token: 35941e7df872405d84e5b026dba8323c” \ https://account.tyo1.conoha.io/v1/487727e3921d44e3bfe7ebb337bf085e/payment-summary RES HTTP/1.1 200 OK Date: Wed, 24 Dec 2014 04:36:31 GMT Server: Apache Content-Length: 141 Content-Type: application/json
{
“payment_summary”: {
“total_deposit_amount”: 1000
}
}
———-
Document 4:
イメージ一覧取得(Glance)
Image API v2
Description
イメージ一覧を取得
Request URL
Image 一覧API v2
GET /v2/images Request Paramters Parameter Value Style Description X-Auth-Token Userトークン header トークンID name (Optional) query イメージ名 visibility (Optional) query 公開(public) または、非公開(private) を指定 member_status (Optional) query イメージメンバーの状態でフィルター owner (Optional) query イメージ所有者(テナントID指定) status (Optional) query イメージの状態 size_min (Optional) query イメージの最小サイズ。単位は bytes size_max (Optional) query イメージの最大サイズ。単位は bytes sort_key (Optional) query ソート対象となる項目。Deault:created_at sort_dir (Optional) query ソートする方向性
Example
※エンドポイントURLにつきましては、お客様環境によって異なりますので、コントロールパネルにてご確認の上ご利用ください。
REQ
curl
i
X GET \
H “Accept: application/json” \
H “X
Auth
Token: 35941e7df872405d84e5b026dba8323c” \
https://image
service.tyo1.conoha.io/v2/images
RES HTTP/1.1 200 OK Date: Tue, 09 Dec 2014 10:17:20 GMT Server: Apache Content-Length: 6102 Content-Type: application/json
{
“images”: [
{
“status”: “active”,
“name”: “testsnap”,
“tags”: [],
“container_format”: “ovf”,
“created_at”: “2014
12
05T13:16:57Z”,
“size”: 3134390272,
“disk_format”: “qcow2”,
“updated_at”: “2014
12
05T13:17:14Z”,
“visibility”: “private”,
“id”: “e9a36da8
5c2e
4d8c
a7a4
db32e7054d34″,
“self”: “/v2/images/e9a36da8
5c2e
4d8c
a7a4
db32e7054d34″,
“min_disk”: 0,
“protected”: false,
“min_ram”: 0,
“file”: “/v2/images/e9a36da8
5c2e
4d8c
a7a4
db32e7054d34/file”,
“checksum”: “238c596d2aa5c4c1daa101c4eb3682ff”,
“owner”: “65a85d8e02e7470da8f72ed31effaf4e”,
“direct_url”: “file:///var/lib/glance/images/e9a36da8
5c2e
4d8c
a7a4
db32e7054d34″,
“hw_qemu_guest_agent”: “yes”,
“schema”: “/v2/schemas/image”
},
{
“status”: “active”,
“name”: “okvm
centos65_ga_fio”,
“tags”: [],
“container_format”: “ovf”,
“created_at”: “2014
12
05T13:09:24Z”,
“size”: 3135963136,
“disk_format”: “qcow2”,
“updated_at”: “2014
12
05T13:09:41Z”,
“visibility”: “private”,
“id”: “7e8ef227
9000
46f2
82b4
c7d68f1bcf96″,
“self”: “/v2/images/7e8ef227
9000
46f2
82b4
c7d68f1bcf96″,
“min_disk”: 0,
“protected”: false,
“min_ram”: 0,
“file”: “/v2/images/7e8ef227
9000
46f2
82b4
c7d68f1bcf96/file”,
“checksum”: “5331449d33377d47459628542f542d4d”,
“owner”: “65a85d8e02e7470da8f72ed31effaf4e”,
“direct_url”: “file:///var/lib/glance/images/7e8ef227
9000
46f2
82b4
c7d68f1bcf96″,
“hw_qemu_guest_agent”: “yes”,
“schema”: “/v2/schemas/image”
},
{
“status”: “active”,
“name”: “okvm
centos65″,
“tags”: [],
“container_format”: “ovf”,
“created_at”: “2014
12
05T12:33:00Z”,
“size”: 2967273472,
“disk_format”: “qcow2”,
“updated_at”: “2014
12
05T12:33:18Z”,
“visibility”: “private”,
“self”: “/v2/images/7b85762c
23d0
4ed0
805b
b5a0604049a2″,
“min_disk”: 0,
“protected”: false,
“id”: “7b85762c
23d0
4ed0
805b
b5a0604049a2″,
“file”: “/v2/images/7b85762c
23d0
4ed0
805b
b5a0604049a2/file”,
“checksum”: “765f4a4670240bcd1e7f40fe5e655c90”,
“owner”: “4a9f0a43587e46258d6b0feb45b58b31”,
“direct_url”: “file:///var/lib/glance/images/7b85762c
23d0
4ed0
805b
b5a0604049a2″,
“min_ram”: 0,
“schema”: “/v2/schemas/image”
},
{
“status”: “active”,
“name”: “okvm
centos65_ga”,
“tags”: [],
“container_format”: “ovf”,
“created_at”: “2014
12
05T12:32:10Z”,
“size”: 2967273472,
“disk_format”: “qcow2”,
“updated_at”: “2014
12
05T12:32:26Z”,
“visibility”: “public”,
“id”: “0481cc6f
5cee
474c
bdf3
b46c793a94ec”,
“self”: “/v2/images/0481cc6f
5cee
474c
bdf3
b46c793a94ec”,
“min_disk”: 0,
“protected”: false,
“min_ram”: 0,
“file”: “/v2/images/0481cc6f
5cee
474c
bdf3
b46c793a94ec/file”,
“checksum”: “5ada4a66c2598d39fb6aacc6731aeae4”,
“owner”: “4a9f0a43587e46258d6b0feb45b58b31”,
“direct_url”: “file:///var/lib/glance/images/0481cc6f
5cee
474c
bdf3
b46c793a94ec”,
“hw_qemu_guest_agent”: “yes”,
“schema”: “/v2/schemas/image”
},
{
“status”: “active”,
“name”: “okvm
centos65″,
“tags”: [],
“container_format”: “ovf”,
“created_at”: “2014
12
03T08:22:44Z”,
“size”: 2967273472,
“disk_format”: “qcow2”,
“updated_at”: “2014
12
03T08:23:02Z”,
“visibility”: “public”,
“self”: “/v2/images/765acb4f
e4df
4f9f
a37c
e062df376504″,
“protected”: false,
“id”: “765acb4f
e4df
4f9f
a37c
e062df376504″,
“file”: “/v2/images/765acb4f
e4df
4f9f
a37c
e062df376504/file”,
“checksum”: “765f4a4670240bcd1e7f40fe5e655c90”,
“min_disk”: 0,
“direct_url”: “file:///var/lib/glance/images/765acb4f
e4df
4f9f
a37c
e062df376504″,
“min_ram”: 0,
“schema”: “/v2/schemas/image”
},
{
“status”: “active”,
“name”: “cirros
0.3.3
x86_64″,
“tags”: [],
“container_format”: “bare”,
“created_at”: “2014
12
03T07:48:41Z”,
“size”: 13200896,
“disk_format”: “qcow2”,
“updated_at”: “2014
12
03T07:48:42Z”,
“visibility”: “public”,
“self”: “/v2/images/3cab9d0f
29b1
45e3
b5fd
76e8d746b289″,
“protected”: false,
“id”: “3cab9d0f
29b1
45e3
b5fd
76e8d746b289″,
“file”: “/v2/images/3cab9d0f
29b1
45e3
b5fd
76e8d746b289/file”,
“checksum”: “133eae9fb1c98f45894a4e60d8736619”,
“min_disk”: 0,
“direct_url”: “file:///var/lib/glance/images/3cab9d0f
29b1
45e3
b5fd
76e8d746b289″,
“min_ram”: 0,
“schema”: “/v2/schemas/image”
},
{
“status”: “active”,
“name”: “cirros
0.3.3
x86_64″,
“tags”: [],
“container_format”: “bare”,
“created_at”: “2014
12
03T07:48:38Z”,
“size”: 13200896,
“disk_format”: “qcow2”,
“updated_at”: “2014
12
03T07:48:39Z”,
“visibility”: “public”,
“self”: “/v2/images/fd2cbdb5
b4dd
4afe
8409
fb2998ca50ef”,
“protected”: false,
“id”: “fd2cbdb5
b4dd
4afe
8409
fb2998ca50ef”,
“file”: “/v2/images/fd2cbdb5
b4dd
4afe
8409
fb2998ca50ef/file”,
“checksum”: “133eae9fb1c98f45894a4e60d8736619”,
“min_disk”: 0,
“direct_url”: “file:///var/lib/glance/images/fd2cbdb5
b4dd
4afe
8409
fb2998ca50ef”,
“min_ram”: 0,
“schema”: “/v2/schemas/image”
},
{
“status”: “active”,
“name”: “cirros
0.3.3
x86_64″,
“tags”: [],
“container_format”: “bare”,
“created_at”: “2014
12
03T07:42:58Z”,
“size”: 13200896,
“disk_format”: “qcow2”,
“updated_at”: “2014
12
03T07:42:59Z”,
“visibility”: “public”,
“self”: “/v2/images/a6f3a56f
0e21
4dfc
b267
9df611034a5d”,
“protected”: false,
“id”: “a6f3a56f
0e21
4dfc
b267
9df611034a5d”,
“file”: “/v2/images/a6f3a56f
0e21
4dfc
b267
9df611034a5d/file”,
“checksum”: “133eae9fb1c98f45894a4e60d8736619”,
“min_disk”: 0,
“direct_url”: “file:///var/lib/glance/images/a6f3a56f
0e21
4dfc
b267
9df611034a5d”,
“min_ram”: 0,
“schema”: “/v2/schemas/image”
},
{
“status”: “active”,
“name”: “cirros
0.3.3
x86_64″,
“tags”: [],
“container_format”: “bare”,
“created_at”: “2014
12
03T07:41:52Z”,
“size”: 13200896,
“disk_format”: “qcow
以下は ContextualCompressionRetriever で検索結果を ChatGPT で要約してから表示しています。(そのため検索するたびにリクエストはガンガン発生します。)
from langchain.chat_models import ChatOpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain.document_transformers import EmbeddingsRedundantFilter
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain.text_splitter import CharacterTextSplitter
llm = ChatOpenAI(temperature=0, verbose=True)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor,
base_retriever=retriever,
verbose=True
)
compressed_docs = compression_retriever.get_relevant_documents(q)
print_docs(compressed_docs)
要約版のベクターストアのドキュメント検索結果。
取得してからChatGPTが要約しています。最初の素のベクター検索結果に比べてだいぶ簡素です。結構情報が抜けているとも言えます。
Document 1:
トークン発行
有効なトークン情報を取得する
POST /v2.0/tokens
{
"auth": {
"passwordCredentials": {
"username": "ConoHa",
"password": "paSSword123456#$%"
},
"tenantId": "487727e3921d44e3bfe7ebb337bf085e"
}
}
200 OK
サービス一覧取得
GET /v1/services
X-Auth-Token: 39be9f8d53044388b7f2e867eba8b140
{
"services" : [
{
"service_id": "9d6441f6c5a04dcfa1a91a4d724e51fd",
"service_name": "dbservice01",
"create_date": "2012-11-02T19:56:26Z",
"quota": 10,
"total_usage": 2.25,
"status": "active",
"backup": "disable",
"prefix" : "02p8y",
"metadata" : {
"key" : "value"
}
},
{
"service_id": "ff164ba842d149d3a597a98503f6fd45",
"service_name": "dbservice02",
"create_date": "2012-11-02T19:56:26Z",
"quota": 30,
"total_usage": 14,
"status": "active",
"backup": "enable",
"prefix" : "8ypg0"
"metadata" : {
"key" : "value"
}
}
],
"total_count":100,
"current_count":10
}
----------
Document 2:
"Userトークン"
----------
Document 3:
入金のサマリーを取得します。
トークンID
----------
Document 4:
GET /v2/images Request Paramters Parameter Value Style Description X-Auth-Token Userトークン header トークンID
最後に ContextualCompressionRetriever とは少し違うアプローチで使える検索結果のフィルター処理を紹介します。
DocumentCompressorPipeline で複数の処理を実行し、検索結果に処理を入れて減らしていきます。
実はこれが一番役に立つかも。
from langchain.chat_models import ChatOpenAI
from langchain.text_splitter import CharacterTextSplitter
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain.document_transformers import EmbeddingsRedundantFilter
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
# この例ではまずはじめに普通にベクターストアを検索する
docs = retriever.get_relevant_documents(question)
### フィルター処理の設定
# 1 検索結果ドキュメントをさらに分割。小分けにして増やす。
# 1つのチャンクが長い場合、重要なところにフォーカスを上げる
splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0, separator="\n")
# 2 質問プロンプト文と類似しすぎている検索結果を排除する。
redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings)
# 3 小さくしたドキュメントのEmbeddingsを改めて作成し、質問プロンプト文との類似性を比較。しきい値以下を排除
relevant_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.80)
# 各フィルターをDocumentCompressorPipelineでつないで、検索結果を減らす処理を行う
pipeline_compressor = DocumentCompressorPipeline(
transformers=[splitter, redundant_filter, relevant_filter]
)
filterd_docs = pipeline_compressor.compress_documents(docs, question)
print_docs(filterd_docs)
結果、いいかんじになっています。
Document 1:
Conoha API
トークン発行
Identity API v2.0
Description
有効なトークン情報を取得する
Request URL
identity API v2.0
POST /v2.0/tokens
Request Paramters
Parameter Value Style Description
username ユーザー名 plain ユーザ名
password ユーザーパスワード plain ユーザパスワード
tenantId (Optional) Tenant ID plain テナントID
Request Json
{
"auth": {
"passwordCredentials": {
"username": "ConoHa",
"password": "paSSword123456#$%"
},
"tenantId": "487727e3921d44e3bfe7ebb337bf085e"
}
}
Normal response codes
200 OK
Example
----------
Document 2:
※エンドポイントURLにつきましては、お客様環境によって異なりますので、コントロールパネルにてご確認の上ご利用ください。
REQUEST
curl
i
X POST \
H "Accept: application/json" \
d '{"auth":{"passwordCredentials":{"username":"ConoHa","password":"paSSword123456#$%"},"tenantId":"487727e3921d44e3bfe7ebb337bf085e"}}' \
https://identity.tyo1.conoha.io/v2.0/tokens
RESPONSE HTTP/1.1 200 OK Date: Mon, 08 Dec 2014 02:40:56 GMT Server: Apache Content-Length: 4572 Content-Type: application/json
{
"access": {
"token": {
"issued_at": "2015
05
19T07:08:21.927295",
----------
Document 3:
header string Userトークン
offset(Optional)
...
(20まで続く)
refine の中でChatGPT回答が複数得られるので回答同士の類似度を判定する
上記の例では、関係のない文書も含めて要約したりEmbbedingしたりするのでOpenAI API実行回数がだいぶ多いです。
別のアプローチとして、LangChainやLlamaindexで用いられる refine の処理の途中で、回答同士の変化度の判定を行います。
例えば、回答1から回答2に変更があった場合に回答2に価値があるとみなすことができます。
類似度・関連度を活用するのとは逆のアプローチになると思います。
そもそも人間でも精査が難しいということもあると思っていて、全部の検索結果を表示してしまうのも別にいいのではと思ったりします。
E. ベクターストアの選定
ベクトルDB、ベクター検索エンジンなど様々な呼ばれ方をしていますが、類似した文書を高速に検索することができます。
結論として私はまだ選定の最適解に到達していません。なのでここはおまけです。
Githubのスター数でランキングを作っているサイトがありました。こちらは非常に参考になります。
https://byby.dev/vector-databases
Faiss がスター数でも知名度でも一番です。
ユースケース別に考えると、以下のような視点があります。
1)既存のDB運用があるのでそこに混ぜていきたい
pgvector
2)マネージドで他のシステムに影響なく独立して運用したい
+大きなデータセットになった場合のスケーラビリティがある
ElasticSearch
milvus
pinecone
こちらに出ていないものとして最近の注目株は Chroma があります。
https://www.trychroma.com/
個人的に Chroma の強みと感じているのは metadata を付与できる部分です。
こちらは検索フィルタとして利用できるので、検索精度を上げることができます。
公式の例では { status: [read/unread] } というステータス値を管理させています。
https://github.com/chroma-core/chroma/blob/main/examples/basic_functionality/where_filtering.ipynb
ドキュメントの種類が広範囲にわたる場合はこの metadata にカテゴリ名などタグ付けをしていくことで検索精度を改善できると思います。
LangChain, LlamaIndex と連携できる API があり、実装上は簡単にいける点も魅力的です。
まとめ
A. ベクターストアに入れる元ネタドキュメントの抽出
⇒ unstructured が使えるかも
B. ベクターストアに入れる元ネタドキュメントのチャンク分け
⇒ タイトル。キーワードをメタデータで付加
C. ベクターストアに投げる質問プロンプトの最適化
⇒ 形態素またはキーワード抽出でプロンプトを精査
D. ベクターストア検索結果の精査
⇒ ContextualCompressionRetrieverによる検索結果要約とDocumentCompressorPipelineによる検索結果精査がよさげ
E. (おまけ)ベクターストアの選定
⇒ 1位はFaiss。マネージドも多々あり。Chromaがこれから来るかも。
まだ全体としては不十分な点が多々ありますが、「検索結果が質問に沿ったものか精査させる」タスクをChatGPTに担当してもらうことが私の業務課題には適しているのでは。。という気づきがありました。
これは大いなる前進です。
元の目的は「検索結果の精度を上げてChatGPTが正確な回答ができるようにする」という点がありましたが、そこにこだわるのではなく、検索精度の向上自体をChatGPTに手伝ってもらうことが業務効率化につながる道が見えてきたので、この点をさらに研ぎ澄ましていこうと思います。
現在公開可能な情報は以上です。
最後に宣伝
次世代システム研究室では、最新のテクノロジーを調査・検証しながらインターネットのいろんなアプリケーションの開発を行うアーキテクトを募集しています。募集職種一覧 からご応募をお待ちしています。

ブログの著者欄
グループ研究開発本部
GMOインターネットグループ株式会社
グループ研究開発本部とは、GMOインターネットグループの事業領域で力を入れているスタートアップやグループ横断のプロジェクトにおいて、技術支援・開発・解析などを行い、ビジネスの成功を支援する部署です。 最新のテクノロジーを研究開発し、いち早くビジネスに投入することで、お客様の発展と成功に貢献することを主要なミッションとしています。
採用情報


関連記事
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート後編】
イベント
-

【2025国際ロボット展 出展レポート】AI ❤ ROBOTs で描く、人とロボットが共存する社会
技術情報
-

【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-

ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

【イベントレポート・後編】GMO Developers Day 2025 -Creators Night-|共創するデザイン組織と次世代クリエイターの可能性
デザイン
-

【イベントレポート・中編】GMO Developers Day 2025 -Creators Night-|変化に挑むクリエイターのキャリアと成長
デザイン

KEYWORD
CATEGORY
-
技術情報(575)
-
イベント(220)
-
カルチャー(55)
-
デザイン(58)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- GPU
- GPUクラウド
- GTB
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-

クレジットカード不正利用と戦う!秘密計算×AIの挑戦 — IPSJ-ONE 2026 登壇レポート
技術情報
-
第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート後編】
イベント
-
【2025国際ロボット展 出展レポート】AI ❤ ROBOTs で描く、人とロボットが共存する社会
技術情報
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート前編】
イベント
-
【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-
ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
採用情報
SNS FOLLOW
