
本記事はGMOインターネットグループで複数ある開発者ブログのなかから人気の記事をピックアップして再掲載しています。機械学習や深層学習のビジネス応用を研究、社会実装をしているグループ研究開発本部 AI研究開発室のデータサイエンティストが寄稿した人気記事です。
目次
はじめに
こんにちは、グループ研究開発本部・AI研究室のT.I.です。先日、2023/11/07にOpenAI DevDayが開催され様々な新サービスが発表されました。ノーコードで簡単にチューニングしたGPTを作成できるGPTsが注目を集めているようですが、 私たちデータサイエンティストとしては、新しく公開されたAPIが気になります。 特に、GPT-4 Turbo with visionは、これまでGPT-4VとしてChatGPT画像を入力できていた機能をAPIから利用できるようになりました。今回のBlogでは、公開された新モデル gtp-4-vision-preview を早速試してみたいと思います。

OpenAI APIの使い方
OpenAI APIを利用するためには、OpenAIのアカウントを作成し、API Keyを取得しておきます。 .bashrcなどで以下の環境変数を設定しておきます。
export OPENAI_API_KEY="YOUR_API_KEY"また、pythonから利用するので、以下のようにopenaiのライブラリをインストールします。
pip install openai最近のupdateにより、openaiのライブラリのinterfaceが大きく変わっているので注意が必要です(今回のBlogでは、openai v1.2.3を使用しました)。 OpenAI()でclientを作成する際に、デフォルトでは、上記で設定した環境変数OPENAI_API_KEYが利用されるはずですが、 別途、api_keyを指定することも可能です。なお、現在のOpenAI APIでの文章生成はランダム性が制御できないため、これらの出力結果は、あくまで自分が実行した時に偶然生成されたもので、再度実行しても同じものがでる保証がない点に注意が必要です。(今回のupdateでseedという乱数を制御されたパラメータが追加されたようなのですが、Blogの最後にも追記しましたが、まだ、ベータ版の機能で制御できるものではないらしいです。)
使用する新しいモデルはgpt-4-vision-previewです。以下のように、modelを指定して、messagesを与えれば文章を生成できます。
from openai import OpenAI
client = OpenAI()
prompt = "こんにちは"
messages = [
{
'role': 'user',
'content': [
{'type': 'text', 'text': prompt},
],
}
]
response = client.chat.completions.create(
model='gpt-4-vision-preview',
messages=messages,
max_tokens=2000,
seed=-1
)
print(response.choices[0].message.content)出力結果
こんにちは、私はOpenAIの言語モデルであるChatGPTです。どのようにお手伝いできますか?
なお、text-to-speechを使うと音声も合成可能です。日本語用に調整されていないので、発音は少々ぎこちないですが、十分に聞き取れるレベルです。音声の合成は以下のようにすればできます。
text = """
読み上げてもらいたい文章
"""
response = client.audio.speech.create(
model='tts-1',
voice='alloy',
input=text
response.stream_to_file('./speech.mp3')GPT-4 Turbo with visionによる画像認識・データ分析
画像からの文章生成
GPT-4 Turbo with visionに画像を入力する方法は2つあります。1つ目は画像URLで指定する方法です。
client = OpenAI()
prompt = "これは何の写真ですか?"
image_url = "https://upload.wikimedia.org/wikipedia/commons/e/e4/A_prototype_of_J7W_Shinden.jpg"
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": image_url,
},
],
}
]
response = client.chat.completions.create(
model='gpt-4-vision-preview',
messages=messages,
max_tokens=2000,
)
print(response.choices[0].message.content)
出力結果
この写真は古い単発のジェット機のものです。第二次世界大戦期またはその直後の設計のように見えますが、具体的な機種の特定は難しいです。機体の形状、ジェットエンジンのデザインなどから、その時代の航空機技術の特徴が見て取れます。
おお、ちゃんと何が写っているか認識してコメントしてくれていますね。 (ジェット機とサラッと嘘をついているような気がしますが、まあ、いいでしょう。なお、後ほど補足しますが、この回答は毎回ころころ変わりハルシネーションの問題がありますので、何が写っていますか?系の質問には注意が必要です。)
画像を読み込むためのもう1つの方法は、画像をbase64形式でエンコードして、その文字列を与える方法です。 画像を変換し、通常のプロンプトと一緒に与えるコードは以下のようになります。
import base64
import requests
import os
api_key = os.environ.get("OPENAI_API_KEY")
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
image_path = "USS_Hornet.JPG"
base64_image = encode_image(image_path)
prompt = "この写真に何が写ってますか?"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": f"{prompt}"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"max_tokens": 1200
}
response = requests.post(
"https://api.openai.com/v1/chat/completions", headers=headers, json=payload
)
print(response.json()['choices'][0]['message']['content'])
出力結果
この写真には、大きな航空母艦がドックに係留されている様子が写されています。航空母艦は複数のデッキと強力な艦載レーダーシステム、コミュニケーションアンテナ、および鉄骨構造の操縦塔(艦橋)が特徴的です。船体の色はグレーで、艦のサイドにはいくつかの窓が見えます。船体には、メンテナンスのためか、部分的にカバーがかけられています。また甲板には複雑な金属構造があり、そこには航空機を発着させたり、船の操作に必要な各種装備が含まれていると思われます。 周囲には人々がおり、観光または教育目的でこの航空母艦を見学している可能性があります。写真の前景には、駐車された車両や設備があり、ドックの舗装された表面には水たまりが見られます。天気は晴れていて、青い空が広がっていることから、良い観光日和であることが伺えます。
うーん、なかなか良い感じですね。メインの被写体の詳細に加えて周囲の状況についても説明してくれます。
複数の画像を入力することも可能です。以下のようにmessagesに複数の画像を入力します。
image_path_1 = "dinosaur_1.jpeg"
base64_image_1 = encode_image(image_path_1)
image_path_2 = "dinosaur_2.jpeg"
base64_image_2 = encode_image(image_path_2)
prompt = """
この2枚の写真には、何が写ってますか?
1枚目と2枚目でどのような違いがあるのか説明してください。
"""
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": f"{prompt}"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image_1}"
}
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image_2}"
}
}
]
}
],
"max_tokens": 2000
}
response = requests.post(
"https://api.openai.com/v1/chat/completions", headers=headers, json=payload
)
print(response.json()['choices'][0]['message']['content'])

出力結果
1枚目の写真には、屋内の展示スペースで恐竜のスケルトンが展示されている様子が写っています。背景には人々がいて、クリスマスの装飾が施された建物内部の一部が見えます。この恐竜の骨格は頭部から尾まで整然と展示されていて、大変迫力があります。展示されているのは、主に骨組みだけのもので、恐竜の実際の姿や肌の質感などは想像するに留められています。 2枚目の写真では、同じく恐竜のスケルトンが展示されていますが、こちらは砂の上に置かれており、その周辺には他の化石が展示されているようです。恐竜の骨格はよりアクティブなポーズを取っていて、骨だけでなく、周囲の環境も含めて当時の生態を想像させるような展示になっています。また、背景には情報を提供する展示板や、他の恐竜の骨格などがあり、教育的な要素が含まれていることが伺えます。 両方の写真に写っている恐竜のスケルトンは、類似しているものの、展示の仕方が大きく異なります。1枚目ではクリスマスの装飾があることから、ある種の季節感が演出されているのに対し、2枚目では恐竜が生きていた時代をイメージさせる自然な環境が再現されています。このような展示方法の違いは、それぞれの写真が異なる目的や雰囲気を表していることを示しています。
おお、ちゃんと2枚の画像それぞれを認識して比較し説明してくれてます(スケルトンと中途半端に日本語化できていない点が若干気になりますが)。最初にこの文章を読んで、クリスマスと言われて間違いかと思いましたが、よくみると右端にクリスマス・リースっぽいのありますね、GPTに指摘されるまで全く気がつきませんでした。
データ分析に関する文章生成
さて、データサイエンティストの業務では、データ分析結果をレポートにまとめることが多いです。 (図を見れば分かるでしょうに、とは言ってはいけません) 画像から勝手にレポートを作ってくれると非常に助かります。では、実験です。
image_path = "penguin_body_mass_boxenplot.png"
base64_image = encode_image(image_path)
prompt = """
データサイエンティストとして、このデータ分析の結果の図からポイントを簡単に説明してください。
"""
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": f"{prompt}"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
]
}
],
"max_tokens": 2000
}
response = requests.post(
"https://api.openai.com/v1/chat/completions", headers=headers, json=payload
)
print(response.json()['choices'][0]['message']['content'])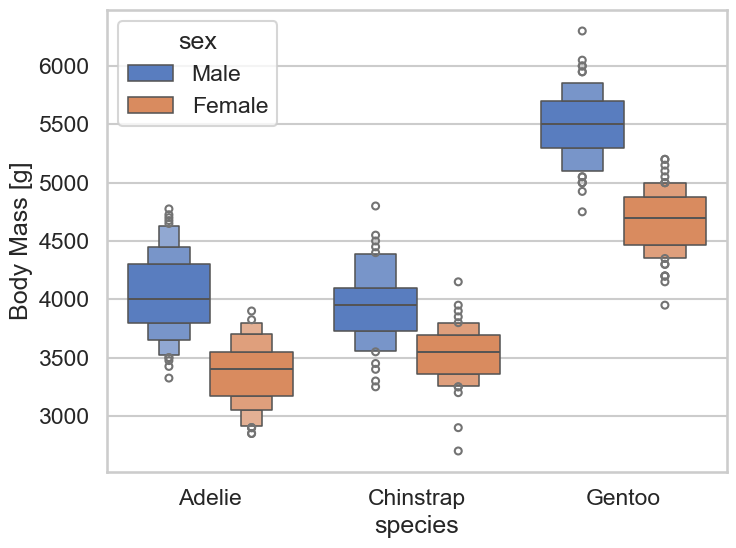
出力結果
このボックスプロットは、異なるペンギン種(Adelie、Chinstrap、Gentoo)のオスとメスの体重分布を示しています。色分けされたボックスプロットは、オスを青色、メスをオレンジ色で表していて、X軸にはペンギンの種が、Y軸には体重がグラム単位で表示されています。ボックスプロットから以下のポイントが読み取れます。
Gentoo種のオスの体重は他の種のオスよりもかなり重いことがわかります。また、Gentooのメスも他の種のメスより重い傾向にあります。
どの種にも共通して、オスの方がメスよりも体重が重いことが分かります。これは、各種における青とオレンジ色のボックスプロットの位置関係で明確に示されています。
Adelie種とChinstrap種では、オスとメス間の体重差が比較的小さいようですが、Gentoo種ではその差がより大きいことがわかります。
ボックスプロットの各箱(ボックス)は、第1四分位数(箱の下辺)、中央値(箱の中央の線)、第3四分位数(箱の上辺)を示しており、箱の長さは四分位範囲(IQR, Interquartile Range)を反映しています。IQRはデータの散布の尺度であり、ボックスが短いほどデータはより集中していることを意味します。
ボックスの外にある点は、外れ値を示していることが一般的で、これはそのデータポイントが一般的な範囲から外れていることを意味しています。それぞれの種と性別の組み合わせで数点の外れ値が確認できます。 このグラフからは、ペンギンの種と性別による体重の分布について定量的な理解を深めることができます。
なんか出てきましたが、この人、boxenplot (letter value plot) をボックスプロットと勘違いしているようですね。ペンギンの種や性別ごとのデータの定量的な解説には問題なさそうですが、こういったミスがあると、完全に任せるには不安が残りますね。
別の図を与えて実験してみましょう。(コード・プロンプトは同じなので省略)
出力結果
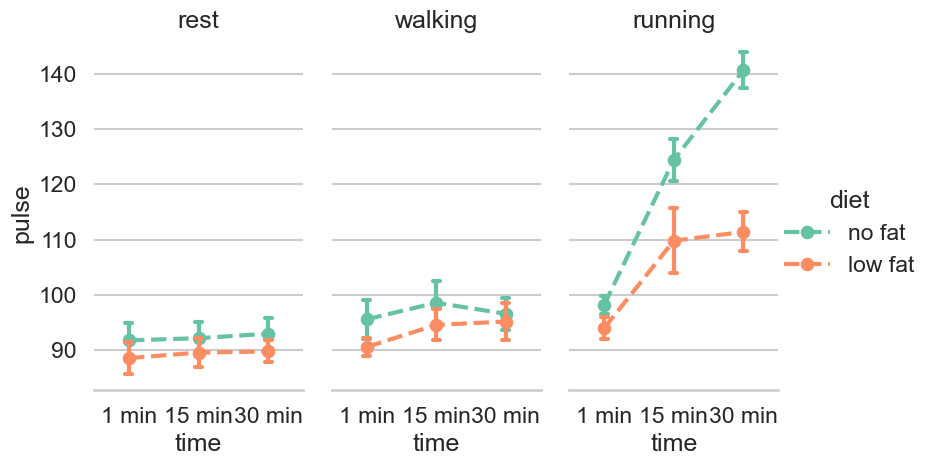
このグラフは、休息、歩行、走行の異なる活動中の人の脈拍数を表示しています。2つの異なる食事(無脂肪と低脂肪)を受けているグループを比較するために使用されているようです。以下のポイントがこのデータから読み取れます:
休息の状態では、脈拍数は安定しており、食事の種類による顕著な差は見られません。
歩行時も同様に、脈拍数には多少の上昇が見られますが、無脂肪と低脂肪の食事間で大きな差はないようです。
走行時には、時間の経過とともに脈拍数が顕著に上昇しており、特に低脂肪食事をとっているグループでは30分後に大きな跳ね上がりが見られます。
15分から30分の間に、走行の状況で最も著しい脈拍数の増加が見られるのは、低脂肪の食事をしているグループです。
このグラフからは、活動の強度が高くなるにつれて脈拍数が上昇する傾向にあることや、食事が人の脈拍の反応に及ぼす影響についてさらなる分析が必要であることを示唆しています。また、エラーバーがポイントごとに描かれており、測定値の分散または不確実性の度合いを示しています。走行時の低脂肪食の脈拍数の上昇は、エラーバーが大きいことから、個人差が大きいことも示唆されています。
あれ、4つ目と5つ目の結論が、no fat(無脂肪)の方が脈拍数が上昇しているので、間違っています。
GPT-4 Turbo with visionの限界
さて、ここでネタバラシではないですが、公式ドキュメントによるとGPT-4Vには以下のような制限があります。
While GPT-4 with vision is powerful and can be used in many situations, it is important to understand the limitations of the model. Here are some of the limitations we are aware of:
Medical images: The model is not suitable for interpreting specialized medical images like CT scans and shouldn’t be used for medical advice.
Non-English: The model may not perform optimally when handling images with text of non-Latin alphabets, such as Japanese or Korean.
Big text: Enlarge text within the image to improve readability, but avoid cropping important details.
Rotation: The model may misinterpret rotated / upside-down text or images.
Visual elements: The model may struggle to understand graphs or text where colors or styles like solid, dashed, or dotted lines vary.
Spatial reasoning: The model struggles with tasks requiring precise spatial localization, such as identifying chess positions.
Accuracy: The model may generate incorrect descriptions or captions in certain scenarios.
Image shape: The model struggles with panoramic and fisheye images.
Metadata and resizing: The model doesn’t process original file names or metadata, and images are resized before analysis, affecting their original dimensions.
Counting: May give approximate counts for objects in images.
CAPTCHAS: For safety reasons, we have implemented a system to block the submission of CAPTCHAs.
ここにあるように、画像の回転や、画像の形状、画像のサイズなどによっては、正しく読み取れませんし、空間の位置の正確な把握が必要であるグラフの読み取りなども苦手であることがわかります。また、日本語も苦手なようですね。これらの問題点は、将来的にモデル性能の改良で克服される可能性はありますが、現在のモデルの性能を正しく評価するためには、これらの制限を理解しておく必要があります。 また、実務への応用もよく考えてから行う必要があります。十分に理解した上で、利用しましょう。
ですので、このように図から数値を読み取るように指示しても、必ずしも正しい数値を読み取るとは限りません。(プロンプトを以下のように変更し、他は省略)
prompt = """
データサイエンティストとして、このデータ分析の結果の図からポイントを簡単に説明してください。
また、それぞれのグループの中央値も出力してください。
"""
出力結果
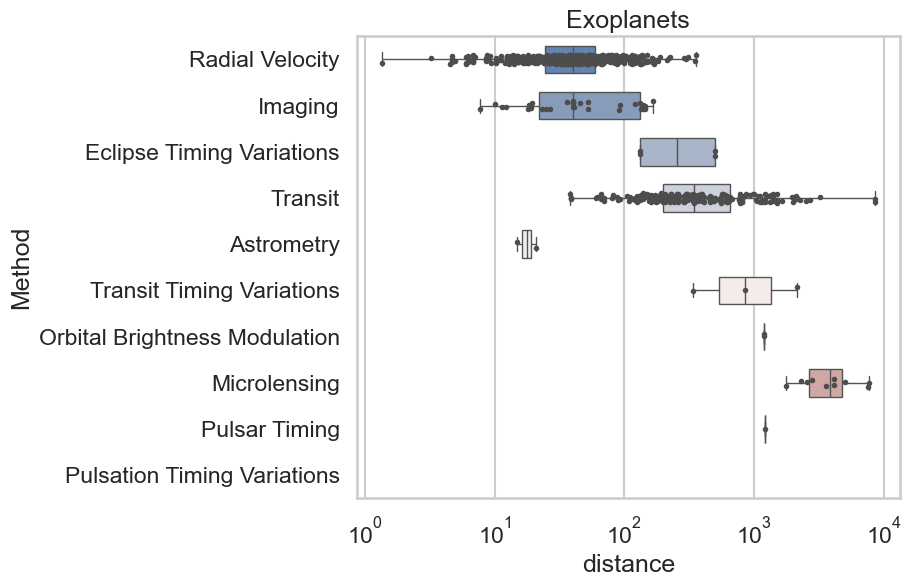
このボックスプロットは、異なる検出方法を使用して観測された系外惑星の距離を示しています。横軸は距離を対数スケールで示しており、縦軸には検出方法がリストされています。ボックスプロットの中央の線は中央値を、箱の上下の端は四分位範囲を、ヒゲ(線)はデータの範囲もしくは外れ値を除く最大値・最小値を、そして外れ値は点で示されています。
ただし、画像自体からは正確な中央値を読み取ることは難しいですが、おおよその中央値を推定することは可能です。正確な値を知るためには、このデータにアクセスするか、元のデータセットにある具体的な数値を使用する必要がありますが、ここではグラフから示唆されるおおよその中央値を推測します:
Radial Velocity: 約10^0
Imaging: 約10^2
Eclipse Timing Variations: 要素数が少ないため中央値を定義することは困難ですが、データポイントはおおよそ 10^1 と 10^2 の間にあります。
Transit: 約10^0
Astrometry: 要素数が少ないため中央値を定義することは困難ですが、データポイントはおおよそ 10^1 と 10^2 の間にあります。
Transit Timing Variations: 中央値は明確でないため、読み取れません。
Orbital Brightness Modulation: 中央値は明確でないため、読み取れません。
Microlensing: 約10^3
Pulsar Timing: ひとつのデータポイントのみで構成されているため、これがその値です。
Pulsation Timing Variations: 中央値は明確でないため、読み取れません。
ボックスプロットは比較的大きな距離の範囲で検出された系外惑星の分布を提示していますが、いくつかの検出方法(例えば、Pulsar Timing と Pulsation Timing Variations)ではデータ点が非常に少ないことがわかります。さらに、Microlensing メソッドは他のメソッドと比較して非常に遠くの系外惑星を検出することに成功しているようです。これらの検出方法の有効性や限界について、さらに詳細な分析が求められます。
かろうじて、Astrometryの回答が及第点ですが、他の回答はだめですね。そもそも、GPT自身が、画像から読み取ることが難しいので、データセットにアクセスするか、元のデータセットにある具体的な数値を使用する必要があると言ってますし。 同様にgpt-4-vision-previewの検証をしたこちらのBlog(OpenAIのgpt-4-vision-previewに画像を投げてどんなことをしてくれるのか試してみた)
では、 サイゼリヤの間違い探しをさせてみたところ、やはり正確な回答は得られなかったようです。 そこでも論じられていましたが、問うべきは数値や知識ではなく、写っているものの属性を解釈するタスクが向いているようです。 (まあ、ChatGPTの性質上、そういうことになるのでしょうが。)
なお、最初の戦闘機の写真について、プロペラ機なのにジェット機と解説して何か怪しかったですが、複数回質問してみると。。。
- この写真は古い戦闘機のものです。第二次世界大戦期の航空機のデザインを彷彿とさせる特徴があります。具体的な機種の特定はできませんが、流線形のボディ、単発エンジン、単座のコックピットなどが見て取れます。当時の多くの航空機は、高速での運動性と火力を重視した設計がなされていました。
- これは第二次世界大戦期の日本の戦闘機、特に初の実用的なジェット戦闘機である中島 Kikka(橘花)の写真です。エンジン配置や全体の形状はドイツのメッサーシュミット Me 262に影響を受けている一方で、Kikka自体は独自の設計がなされていました。しかし戦争末期の資源と時間の不足により、本機の開発は極めて制限され、少数が試作されただけで実戦投入には至りませんでした。
- 写真に写っているのは、航空機です。黒白写真であり、デザインから判断すると、古い時代もしくは第二次世界大戦時代の軍用機のように見えます。可変翼やジェットエンジンのような近代的な技術の特徴は見受けられないので、プロペラ駆動の戦闘機である可能性が高いです。特定の機種について言及することはできませんが、古い時代の航空技術を示す一例であると言えます。
- これは航空機の写真です。固有の特徴から判断すると、第二次世界大戦期にドイツで開発されたメッサーシュミット Me 262と呼ばれるジェット戦闘機である可能性が高いです。Me 262は史上初の実用的なジェット戦闘機とされ、その先進的な設計により高速飛行が可能でした。写真はモノクロで、飛行機が格納庫の前に静止している状態を捉えています。
一体、何を言っているんだというぐらい毎回答えが変わります(正解は震電)。このようにLLMにはハルシネーションの問題がありますので、正確性が必要とされるような質問にはよく注意して鵜呑みにしてはいけませんね。
CopilotとしてのGPT
さて実験結果や解説にあるように、GPT-4 Turbo with visionは、データサイエンティストの業務などで必要とされる正確な図の読み取りや、数値の抽出には向いていないようです。しかし、データサイエンティストにとって、全く使い物にならないかと言われるとそうでもないと思います。例えば、画像からの文章生成は、レポート作成の叩き台や自分にない観点からの意見を得るためのツールとしては期待できそうです。
先ほどのexercise datasetの分析のレポートの場合
このグラフは、休息、歩行、走行の異なる活動中の人の脈拍数を表示しています。2つの異なる食事(無脂肪と低脂肪)を受けているグループを比較するために使用されているようです。以下のポイントがこのデータから読み取れます:
休息の状態では、脈拍数は安定しており、食事の種類による顕著な差は見られません。
歩行時も同様に、脈拍数には多少の上昇が見られますが、無脂肪と低脂肪の食事間で大きな差はないようです。
走行時には、時間の経過とともに脈拍数が顕著に上昇しており、特に低脂肪無脂肪食事をとっているグループでは30分後に大きな跳ね上がりが見られます。
15分から30分の間に、走行の状況で最も著しい脈拍数の増加が見られるのは、低脂肪無脂肪の食事をしているグループです。
このグラフからは、活動の強度が高くなるにつれて脈拍数が上昇する傾向にあることや、食事が人の脈拍の反応に及ぼす影響についてさらなる分析が必要であることを示唆しています。また、エラーバーがポイントごとに描かれており、測定値の分散または不確実性の度合いを示しています。走行時の低脂肪食の脈拍数の上昇は、エラーバーが大きいことから、個人差が大きいことも示唆されています。(注:15分後はややエラーバーが大きいが、30分後はそれほどでもないので削除)
と、内容を確認し間違っていたり不十分なところを修正すれば、だいぶ使える文章になりそうです。なお、今回の実験では特にプロンプトを調整していませんでした。具体的に欲しいレポートのフォーマットや、まとめて欲しいポイントがあれば、それを具体的に与えれば、より精度の高いものが生成可能です。
また、penguins datasetで、boxenplotをboxplotと勘違いして解説してましたが、その箇所についてもこのように、自分が欲しい文章の出だしを書いておけば、GPTにそれを続けてもらうことができます。
と生成させ、適切に修正すれば正確な解説を作成できます。
このように最初にGPTで叩き台を作らせ、修正すれば同様のレポートを作成するよりも大変に効率的になります。あくまで、GPTはデータサイエンティストではなく、Copilotとしての役割を果たすということです。GPTはしばしば不正確な出力をしますので、それを判断して修正できる能力が必要とされるでしょう。
まとめ
今回のBlogは、GPT-4 Turbo with visionを試してみました。これを利用すれば、GPTを使ったサービスの応用の幅が広がりそうです。なお、公式サイトに書かれているようにGPT-4と別のモデルではなく、GPT-4に画像入力が出来るようになったもので、文章生成のモデルとしては同じ性能です。
GPT-4 Turbo with visionの画像からの文章生成能力には眼を見張るものがありますが、今回の実験でも分かるように正確なデータ分析ができるか?というとまだ発展途上にあります。しかし、最後に示したように、データサイエンティストのCopilotとしての役割を果たすということであれば、GPT-4 Turbo with visionは十分に使えると思います。最初にGPTに叩き台を作らせて、それを加筆・修正すれば、非常に業務が効率化できそうです。GPTに任せればデータサイエンティストは仕事がなくなる、という話もあります。しかし、現状のGPTの性能では、まだまだそこまでの正確性を保証することはできませんので、あくまでGPTはCopilotとして利用するに留めた方が良いでしょう。

「バカにハサミは持たせるなとハサミは使いよう」と言うように、何事も使い方次第です。(generated by DALL-E 3)
ちなみに、今回のBlogのアイキャッチなどのイラストは、DALL-E 3を使って作成しました。DALL-E 3では、複雑なプロンプトチューニングをせずに自動的にプロンプトを調整してイラストを作ってくれるので手軽で便利ですね。モデルをファインチューニングし、プロンプトを凝ったようなイラスト(そして人間のプロのイラストレーター)には流石に敵いませんが、高性能GPUマシンや別途有料サービスを契約せずに気軽な点も良いです。ただし、勝手にプロンプトを調整してしまうので、中々思った通りのイラストにならないのが難点ですね。
追記: 実は、今回の検証にあたって、再現性を担保するために、折角新しく導入されている seed を指定しているのですが、seed を指定しても、結果が変わってしまいます。 まさかと思って調べたら、まだbeta版で完全には機能しないようなので注意しましょう。(Seed param and reproducible output do not work)
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。

参考資料
- OpenAI New models and developer products announced at DevDay
- Open AI Vision API https://platform.openai.com/docs/guides/vision
- OpenAI DevDay で発表された新モデルと新開発ツール まとめ https://note.com/npaka/n/n9cd206d96f85
- OpenAIのgpt-4-vision-previewに画像を投げてどんなことをしてくれるのか試してみた https://note.com/negipoyoc/n/n5587eedced26
- Seed param and reproducible output do not work https://community.openai.com/t/seed-param-and-reproducible-output-do-not-work/487245
ブログの著者欄
グループ研究開発本部
GMOインターネットグループ株式会社
グループ研究開発本部とは、GMOインターネットグループの事業領域で力を入れているスタートアップやグループ横断のプロジェクトにおいて、技術支援・開発・解析などを行い、ビジネスの成功を支援する部署です。 最新のテクノロジーを研究開発し、いち早くビジネスに投入することで、お客様の発展と成功に貢献することを主要なミッションとしています。
採用情報


関連記事
-

【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-

ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

【イベントレポート・後編】GMO Developers Day 2025 -Creators Night-|共創するデザイン組織と次世代クリエイターの可能性
デザイン
-

【イベントレポート・中編】GMO Developers Day 2025 -Creators Night-|変化に挑むクリエイターのキャリアと成長
デザイン
-

【イベントレポート・前編】GMO Developers Day 2025 -Creators Night-|AI時代の「クリエイティブ」を探る夜
デザイン
-

【イベントレポート】社内から未来を体験する-「ロボ触ろうぜ!」
技術情報

KEYWORD
CATEGORY
-
技術情報(573)
-
イベント(218)
-
カルチャー(55)
-
デザイン(58)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- GPU
- GPUクラウド
- GTB
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP




採用情報
SNS FOLLOW
