
こんにちは、今年もブログを更新することになりました、GMOインターネットの岡村です。
ConoHa で提供されている NVIDIA L4 で最新の Ubuntu 24.04 のサーバーを 200GB に増量されたブートボリュームで構築し、その上で動作する Ollama を VS Code の Continue 拡張機能で利用できるようにし、Vibe Coding の環境を整えてみます。
目次
やりたいこと
昨今 GitHub Copilot などの AI によるコーディング支援、さらにはバイブコーディングなども知られるようになってきました。
これらの活用は OSS の開発や個人的なものでは問題なくとも、用途によっては外部に情報を送信するのはためらわれる場合もあるかもしれません。
その場合、ローカルで実行可能な LLM や、ConoHa のようなサーバー上で LLM を実行させる、といった方法があります。
GitHub Copilot 自体はローカル等では実行できませんが、Visual Studio Code の拡張機能である Continue を使うと、Ollama などを使用してローカルやサーバー上で実行することができます。
ConoHa のご紹介
NVIDIA L4 サーバー
ConoHa では NVIDIA の H100 と L4 のサーバーを提供しています。
プラン、利用開始の方法については、2024年7月に投稿した下記の記事でも紹介しています。
今回も NVIDIA L4 を使用します。
公開 API
ConoHa では OpenStack 準拠の公開 API が利用可能です。
今回は、直接公開 API を利用するのではなく、OpenStack CLI を使用します。
下記ページを元に環境を準備し、openstack token issue によるトークン発行ができることを前提とします。
ブートストレージ容量追加
これまで 512MB プラン以外は 100GB のブートストレージが標準提供されていましたが、
2025年6月より公開 API からの利用限定となりますが、「200GB」「500GB」も利用できるようになりました。
料金についてはこちらをご確認ください。
標準の 100GB のボリュームは、VM からデタッチされた状態が長時間続くと自動的に削除されてしまいますが、
有料オプションの 200GB, 500GB であればデタッチ状態が長く続いてもボリュームは残ります。
したがって、高価な GPU インスタンスは使用しないときは削除し、必要なときボリュームから作るといった利用も可能です。
テンプレート
記事執筆時点で、コンパネからは GPU のイメージテンプレートとして下記が利用可能です。
- OS:Ubuntu 22.04
- アプリケーション:NVIDIA Container Toolkit、Automatic1111、 InvokeAI
昨年リリースされた「Ubuntu 24.04」について、昨年記事の時点では一部サポートしていないアプリケーションもあり 22.04 を採用していましたが、現在はサポートが進んでいます。
公開 API であれば、VPS で提供されているテンプレートも利用可能になるため、「Ubuntu 24.04」を使用します。
VM 作成
セキュリティグループ作成
公開 API や OpenStack CLI からでも作成可能ですが、コンパネから作成するのが簡単です。
今回はトークン認証は設定しないため、利用したい IP アドレス指定でセキュリティグループを作成します。
必要なポートは下記です。
- SSH 用:22/tcp
- Ollama 用:11434/tcp
ブートストレージ作成
openstack volume create --size 200 --bootable \
--image vmi-ubuntu-24.04-amd64 gmo-developer-blog-demoエラーが出る場合、イメージ一覧取得コマンドで存在しているか確認してください。
openstack image list --publicNVIDIA Container Toolkit 用 cloud-init user-data 作成
今回は素の Ubuntu テンプレートのため、cloud-init の user-data で NVIDIA Container Toolkit テンプレート相当までパッケージをインストールします。
NVIDIA Container Toolkit・CUDA の導入後、GPU を認識するには再起動が必要であるため、ollama などのインストールは別途行うことにします。
出来上がったスクリプトは下記となります。
#cloud-config
merge_how:
- name: list
settings: [append]
- name: dict
settings: [no_replace, recurse_list]
runcmd:
- echo --- Install and Upgrade apt package ---
- echo
- apt-get update
- apt-get upgrade -y
- apt-get -y install docker.io nvtop
- echo
- echo --- Install NVIDIA Container Toolkit ---
- echo
- wget -O /root/cuda-keyring_1.1-1_all.deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
- dpkg -i /root/cuda-keyring_1.1-1_all.deb
- apt-get update
- apt-get install -y nvidia-container-toolkit cuda
- echo
- echo --- Reboot ---
- echo
- shutdown -r +1VM 作成
先ほど作成した user-data を読み込ませて VM を作成します。
一度セットアップした VM をボリュームだけ残して再作成する場合、user-data は不要です。
openstack server create --flavor g2l-t-c20m128g1-l4 \
--volume gmo-developer-blog-demo \
--property "instance_name_tag=gmo-developer-blog-demo" \
--security-group allow_from_myip --password {パスワード} \
--user-data user-data.yaml ""このタイミングでエラーが発生する場合、GPU サーバーの利用申請が完了していない可能性があります。
コントロールパネルから GPU サーバーの作成画面が表示されることを確認してください。
Ollama 準備
Ollama を直接インストールする方法もありますが、
今後 TLS 暗号化、トークン認証を haproxy 等を経由し実装できるようにコンテナにて起動します。
docker run -d --gpus=all --restart=always -v /usr/share/ollama/.ollama:/root/.ollama --name ollama ollama/ollama:latest
ufw allow 11434/tcp comment 'ollama'今回使用するモデルをダウンロードします。
docker exec ollama ollama pull gemma3n:latest
docker exec ollama ollama pull qwen2.5-coder:7bダウンロード済みのモデルは下記で確認できます。
docker exec ollama ollama lsVSCode 準備
まずは、ローカルから Ollama への疎通が可能か確認します。
curl http://{VM の IP アドレス}:11434
Ollama is running次に Visual Studio Code で下記の拡張機能を導入します。
画面の指示通り設定すると、モデルは自動選択(Autodetect)となりますので、apiBase, role の行だけ追記します。
name: Local Assistant
version: 1.0.0
schema: v1
models:
- name: Autodetect
provider: ollama
model: AUTODETECT
apiBase: http://{VM の IP アドレス}:11434
roles:
- chat
- edit
- apply
- autocomplete
context:
- provider: code
- provider: docs
- provider: diff
- provider: terminal
- provider: problems
- provider: folder
- provider: codebase初期設定は上記のmodel の部分が空になるものです。
使ってみる
架空の「Go言語でじゃんけんに勝ったらハンバーガーを食べられるゲーム」を作成します。
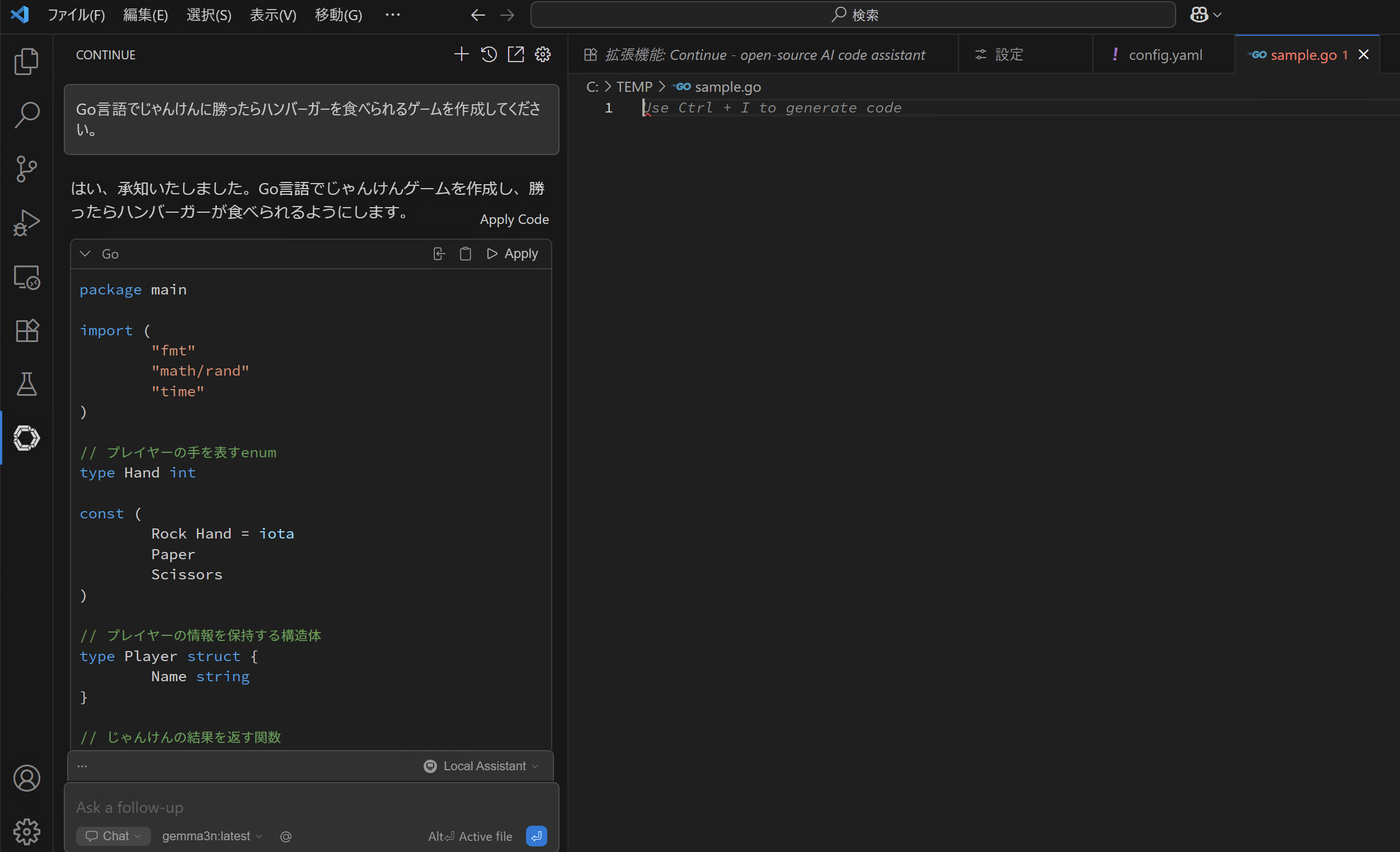
出力されたコードを「Apply」すると反映されます。
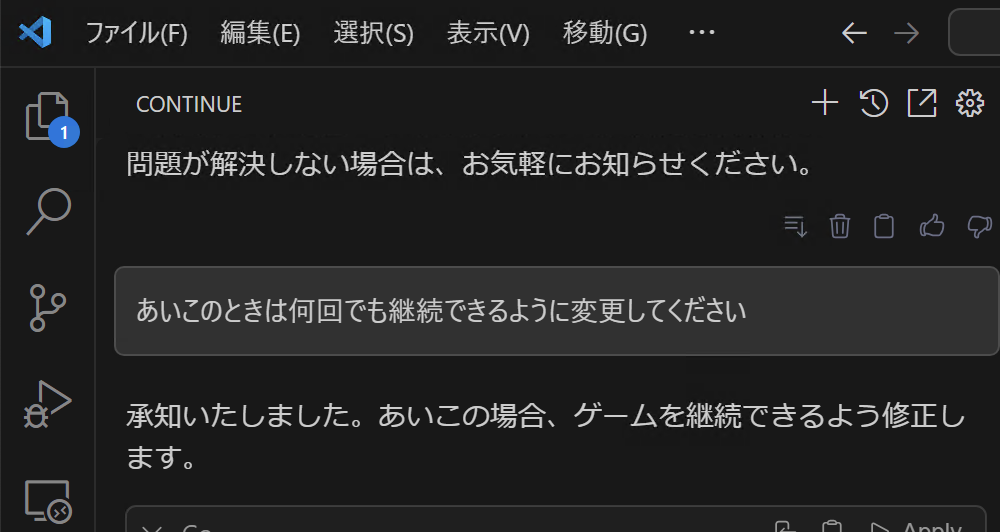
ただ、実際に実行すると、あいこ3連続の場合、どちらもハンバーガーが食べられないままゲームが終了してしまいます。
プログラムの改修を指示すると、修正後のソースを提示してくれます。
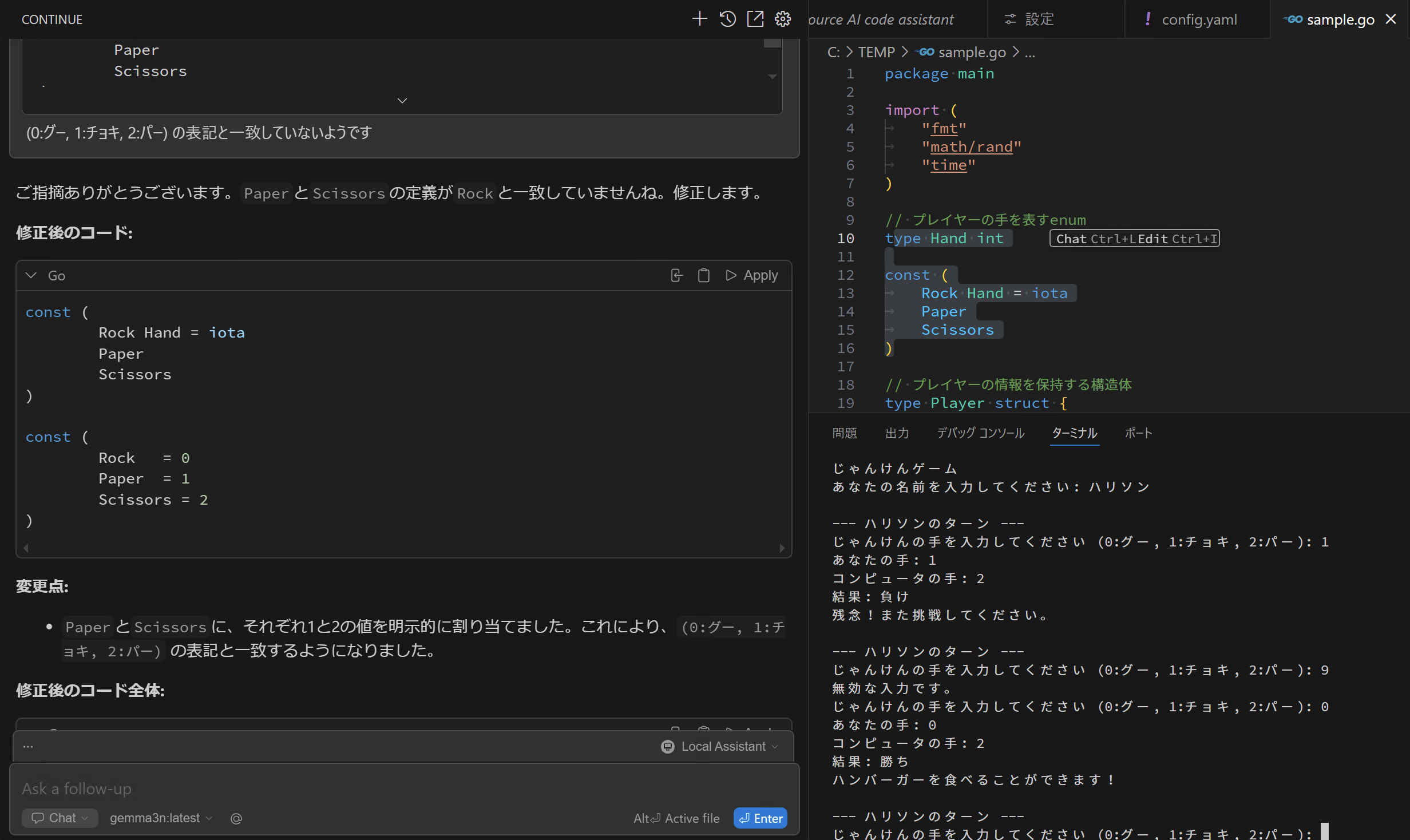
さらに試してみると、勝ち負けの判定がおかしいことに気づきましたが、修正されず・・・このモデルにおいてはうまくいかない例もあるようです。
最後に
Visual Studio Code + Continue + Ollama + ConoHa L4 の組み合わせで、AI によるコーディング支援環境が整えられました。
ブートストレージの容量追加機能により、200GB 以上のブートストレージだけ残して、高価な GPU インスタンスは都度作成というお財布に優しい使い方もできるようになりました。
記事を書き始めると内容が増えてきたので、下記については本記事では触れていませんので、実際にこの構成を参考にする際はご注意ください。
- 通信の暗号化:間に haproxy 等を挟み自己署名証明書を用いるか、Cloudflare Zero Trust や VPN 等で経路ごと暗号化するなどが考えられます
- IP 制限以外のトークン等の認証:自己署名証明書を用いる場合、haproxy 等で擬似的にトークン認証の仕組みを入れることも考えられます
- 最適なモデル選択:NVIDIA L4 で動作する範囲の高性能なモデルの選択も重要ですので、いろいろ試してみるのが大事です
ブログの著者欄
岡村 康行
GMOインターネット株式会社
GMOインターネット株式会社 2016年入社、ConoHa や Z.com Cloud など、OpenStack インフラの開発・運用に従事。2023年よりアーキテクトとして活動中。写真は採用サイトでインタビューを受けた時の写真です。
採用情報


関連記事
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート後編】
イベント
-

【2025国際ロボット展 出展レポート】AI ❤ ROBOTs で描く、人とロボットが共存する社会
技術情報
-

【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-

ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

【イベントレポート・後編】GMO Developers Day 2025 -Creators Night-|共創するデザイン組織と次世代クリエイターの可能性
デザイン
-

【イベントレポート・中編】GMO Developers Day 2025 -Creators Night-|変化に挑むクリエイターのキャリアと成長
デザイン

KEYWORD
CATEGORY
-
技術情報(574)
-
イベント(220)
-
カルチャー(55)
-
デザイン(58)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- GPU
- GPUクラウド
- GTB
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-
第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート後編】
イベント
-
【2025国際ロボット展 出展レポート】AI ❤ ROBOTs で描く、人とロボットが共存する社会
技術情報
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート前編】
イベント
-
【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-
ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

コールセンターでSpeech2Speech AIを繋ぐときに知っておきたい3つの接続方式
技術情報
採用情報
SNS FOLLOW
