
2022年9月24日(土)~25日(日)に「PHPカンファレンス2022」が大田区産業プラザにて開催されました。
GMOインターネットグループはスペシャルスポンサーとして協賛・登壇しました!
今回は、スポンサーセッション「17年続くWebサービスを改善する ~新卒2年目からみるカラーミーショップ~」の書き起こし記事となります。ぜひご覧ください。
イベント告知:https://developers.gmo.jp/23482/
目次
登壇者(敬称略)
- GMOペパボ株式会社 EC事業部ECグループCCXチーム
中山 慶祐(やんまー) - GMOペパボ株式会社 技術部プラットフォームグループ
新宮 隆太(ほみるん)
前半「切り取り方を工夫してアプリケーションを漸進的に改善する」
後半「カラーミーショップの改善におけるSRE活動について」
GMOペパボ株式会社技術部プラットフォームグループでサイトリライアビリティエンジニアをやっております、新宮隆太と申します。弊社ではあだ名で呼び合う文化があり、社内では”ほみるん”と呼ばれています。このあだ名は、むかし乱数で生成したものを使っています。
社内では、写真のようなサーバーを担ぐSlackアイコンを使っていることから、他のチームからはとりあえず「サーバーを担ぐやつ」として認知され始めました。最近のトピックは、曲がりなりにもサイトリライアビリティエンジニアをやっているわけですが、自宅サーバーで運用しているブログを落としてしまいました。非常に反省しております。Twitterは @h0mirun_deux のIDでやっておりますのでよければフォローよろしくお願いいたします。
本日のアジェンダです。
まず、一般的なSREについてのお話をさせていただき、その後カラーミーショップのSREチームの紹介をさせていただきます。そして、SREチームが行っているSRE活動と、その改善活動について実例を踏まえつつお話しさせていただければと思います。
SREとは
まずSREとは何なのかという話をします。SREとはSite Reliability Engineeringの略です。日本語にするとサイト信頼性エンジニアリングですね。実はですね、このSREという略はもうひとつの意味でも使われています。それはSite Reliability Engineerです。先ほどはエンジニアリング、今回はエンジニア、どっちもSREなので困りましたね…。スライドや口頭とかでもSREというとエンジニアリングかエンジニアどっちを指すのか分からなくなりそうです。でも、リライアビリティという言葉はもうさっきからずっと言っているのですけどめちゃくちゃ言いにくいですよね。なので、できればSREと略して喋りたいわけです。
そういうことで今回はSREという略語に関しては、Site Reliability Engineering、つまり手法を指すということにしたいと思います。エンジニアの方は略さずサイトリライアビリティエンジニアと書いたり言ったりしたいと思います。
ということで、本題に戻りまして、SREの話をしていきたいと思います。
SREとは、サービスの信頼性を維持向上することを目的としたアプローチのひとつで、信頼性に関する指標などをもとにファクトベースで意思決定を行います。
今度はエンジニアの方、サイトリライアビリティエンジニアは、その名の通りサイトリライアビリティエンジニアリングを実践する人たちのことを指しています。この人たちはサービスの信頼性に関するすべてのことに関わります。
さて、SREの簡単な説明が終わったところで、先ほどから信頼性、信頼性と言っていたわけですが、信頼性とは何なんだという話について軽く触れていきたいと思います。
信頼性は、サービスがどれだけユーザーの期待どおりに利用できる状態かどうかを示す言葉です。よく信頼性が高いという言葉を耳にすると思います。これは、ユーザーが期待どおりに利用できる時間が長いということになります。例えば満足な速度でレスポンスが返ってくるだとか、サービスが障害で止まって使えなくなることが少ないだとか、そういうことが組み合わさって信頼性が高くなるわけです。
さて、ではその信頼性を維持向上することで何が嬉しいのか見ていきたいと思います。
一番大きいのは、ユーザー体験の維持・向上だと思います。極端な例ですが、リリースのためにサービスが不安定になったり、レイテンシが悪化するといった状態だったとします。するとユーザーはより快適な別のサービスに乗り換えてしまうなど、ユーザーが離れていってしまい、せっかく素晴らしい機能をリリースしたのにそもそも使ってくれるユーザーがいなくなってしまうわけです。こういった機会損失を防ぐことができるのが信頼性の維持・向上です。
信頼性の維持・向上のためには、まず現状のサービスの状態を知ることと、目標の設定が不可欠です。ということで、次は信頼性の指標となるSLI/SLOについて簡単に説明していこうと思います。
まずSLIから。SLIは、Service Level Indicatorの略で、サービスの稼働状況を示したものです。具体例を出すと、可用性であればリクエストの成功と失敗の割合であるエラーレートであったり、決済の成功率、レスポンスの応答速度であればn秒以内に処理を完了したリクエストの割合とかがSLIとして設定できます。
SLOは、Service Level Objectiveの略で、サービスの稼働目標を数値化したものです。先ほど説明したSLIがどのような状態になっているとよいのかを定義します。先ほどと同じような例を出していくと、可用性では30日間で正常に処理されたリクエストが99.9%だとか、30日間で決済成功率が99.99%、いわゆるフォーナインといわれるものですね、レスポンスの速度では、30日間でn秒以内に処理が完了したリクエストが99.95%というものがSLOとして設定できます。
では、具体的に信頼性の維持向上のためにサイトリライアビリティエンジニアは何をやるのでしょうか。
実際には、以下のようなことをやっております。先ほど話したSLI/SLOの運用であったり、メトリクスをもとにしたパフォーマンスチューニング、運用の手順化・構造化、構造化したものをソフトウェア・エンジニアリングを用いて自動化し効率を図る、など様々なことをやっております。
今回の発表では、上記の2つについて、より焦点を当てて話しさせていただければなと思っています。
カラーミーショップのSREチーム
カラーミーショップでSRE活動を行っているチームについて簡単にお話しさせていただきます。
GMOペパボでは、サービスごとに事業部という形で分かれています。カラーミーショップは赤枠で囲んだEC事業部というところで開発されています。ですが、カラーミーショップのSREチームはEC事業部ではなく、サービス横断の横串組織である技術部の中にあるプラットフォームグループというところで主に担当しています。
カラーミーショップのSREチームを担当しているプラットフォームグループは、サービスから独立したSREチームとなっており、以下のようなことを行っております。SLI/SLOの運用、ソフトウェア・エンジニアリングを用いたサービス運用効率化、メトリクスをもとにしたパフォーマンスチューニング、といった先ほどのサイトリライアビリティエンジニアのやることで紹介したことはもちろん、インフラまわりの整備、オンコール対応なども行っています。
カラーミーショップにおけるSRE活動
ではここから、本題である実際にカラーミーショップで行っているSRE活動について説明していきたいと思います。
先ほど説明したSLI/SLOは、設定するだけでは意味をなしません。SLI/SLOを観測することが信頼性維持・向上に向けての第一歩となります。カラーミーショップではSLI/SLOを観測するために、以下のような取り組みを実施しています。
ではひとつずつ説明していきたいと思います。
まず1つ目がSLIの監視と通知です。
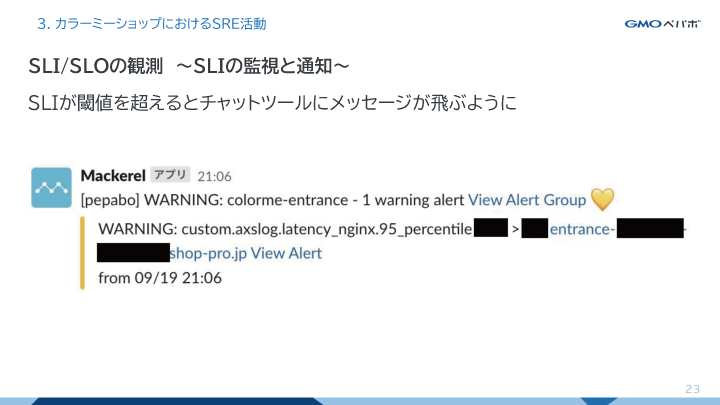
カラーミーショップではエンドポイントのレイテンシをSLIの1つとして設定しています。そこで我々はSLIを監視ツールで監視をし、直近の数分のレイテンシが閾値を超えていたことを通知できるようにしました。これにより、いま自分たちのサービスの信頼性が低下しているかもしれないということに即刻気が付くことができるようになります。
次にダッシュボードについてです。
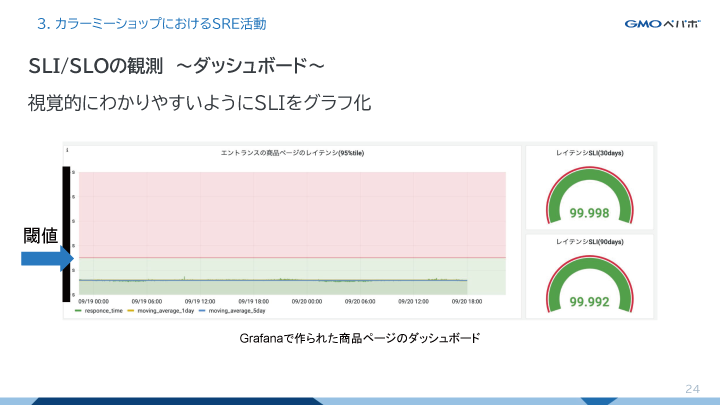
ダッシュボードはグラフ化されることで視覚的に分かりやすくなり、SLIの傾向をつかむのに最適です。全体的に少しずつSLIが悪化もしくは改善している傾向が分かったり、特定のタイミング、特定の時刻にSLIが悪化していることが分かったりします。この下に貼ってある画像の緑と赤の境界線が設定されている閾値で、ここを超えないように日々SRE活動を実施しています。
SLI/SLOレビュー会では、カラーミーショップ担当エンジニアとSREチームが参加し、現在のサービスの状態の認識共有を行う場として設定されています。具体的にこの会では、次のようなことをします。まず直近1週間のSLIを確認し、SREチームとカラーミーショップ担当エンジニアとの間で、現状のサービスの信頼性の状態を確認します。その後、SREチームが事前にこのままではSLIを違反してしまいそうな項目について調査をしておき、この場で共有します。最後に、次のSLI/SLOレビュー会までに実施する改善策、いわゆるアクションアイテムを設定します。この会を毎週毎週繰り返すことで、サービスの信頼性をより向上させていっています。
次に、エラーバジェットについてお話しします。

エラーバジェットは、サービスの信頼性がどの程度損なわれていても許容されるかを示す値です。例えば、SLOで30日間に来るリクエストのうち、99.99%は正しいリクエストを返すというものを設定した場合、30日間で約4.3分間はエラーを返してもよいということになります。
さて、エラーバジェットがだいたいどんなものか分かったところで、これをどう信頼性の維持・向上の活動に含めていくかです。カラーミーショップでは、エラーバジェットをすべて使い切った時に、カラーミーショップ担当エンジニアと、サイトリライアビリティエンジニアがとる行動についてルールを定めています。それが、エラーバジェットポリシーです。カラーミーショップでは、ちょうど運用を始める段階です。エラーバジェットポリシーは、サービスの機能開発と信頼性のバランスをとるという目的で設定されています。また、ここにはエラーバジェットポリシーはSLOの未達に対する罰としては運用しないということも明記されています。これは、このポリシーが信頼性回復を目的としてカラーミーショップ担当エンジニアとサイトリライアビリティエンジニアが協力するために設定されているのであって、対立するためには設定されていないことを重要視しているからです。
もう少し具体的にカラーミーショップのエラーバジェットポリシーについて見ていきます。
もし、エラーバジェットを使い切ってしまったら、まず信頼性回復のためのタスクが最優先になります。そのうえで、もしアプリケーションが起因でエラーバジェットを使い切ってしまった場合は、SREチームとカラーミーショップ担当エンジニアそれぞれ1人ずつ、信頼性回復のためのタスクに専任でアサインします。もしインフラ起因でエラーバジェットを使い切ってしまった場合は、SREチームから1人を専任でアサインします。
次に改善もくもく会についてお話しします。

改善もくもく会は、カラーミーショップ担当エンジニアとSREチーム合同で一緒にサービス改善を実施する会です。
もう少し具体的に話すと、この会では主に3つのことを行っています。まず、SREチームが改善できそうなエンドポイントの洗い出しを実施してカラーミーショップ担当エンジニアに共有します。カラーミーショップ担当エンジニアはSREチームが洗い出したエンドポイントに関する実装についてSREチームに説明をします。ここまでで出た情報をもとに、実際に手を動かしてサービス改善を実施していきます。
ここまでSLI/SLOの観測や改善もくもく会などのお話をしてきました。それらから生まれた改善活動として、実際に次のようなことを実施しています。
インフラの最適化としては、需要の予測とキャパシティプランニングや、Webサーバーの設定値の変更などのチューニング等、アプリケーションの改修としては、クエリチューニング等を実施しています。
SLI/SLOを用いた改善活動の事例紹介
それでは、先ほどの話を踏まえて実際に行った改善活動の事例を紹介します。
具体的な例の前に、アーキテクチャの話を少しだけ前提知識としてさせてください。
カラーミーショップの一部はGMOペパボのプライベートクラウド基盤であるNyah上でVMとして稼働しています。もちろんコンテナ化されている部分もあります。また先ほど言ったNyahにはGMOペパボが提供している別のサービスも含めて共存しています。これらを頭の片隅に置いた状態でこれから話す事例を聞いていただければと思います。
はじめに、インフラ最適化による改善活動を2例紹介します。
インフラの最適化による改善活動の例 ~その1~
1つ目は、エンドポイントレイテンシが悪化して閾値を超えてしまった例についてお話しします。
我々SREチームは、以下のような手順でこの問題を改善しました。
まず1つ目、まず我々はSLIダッシュボードから何か問題がありそうだぞとなったあと、もともと収集しているメトリクスを確認し、一部のインスタンスのみのレスポンスが悪化していることが分かりました。さらに、別のメトリクスを見ていくと、CPUstealの値が増加していることが判明しました。ここで出てきたCPUstealとは、ハイパーバイザー型VMにおいて仮想CPUが実CPUを待っている時間のことで、同じホストにいる別VMと実CPUのCPU 時間を奪い合うことで発生します。カラーミーショップは先ほど説明した通りVM上で動いているため、このような問題が発生していました。
さて、CPUstealの値が増えていることから我々はノイジーネイバー問題を疑い、インスタンスのライブマイグレーションを実施しました。ノイジーネイバーとは、日本語だと「うるさい隣人」という意味です。同じホストに存在する他のVMがホストのマシンリソースを大量に利用することで十分なリソースが利用できない状態のことです。なので、うるさい隣人のいないホストへ移動すべく、ライブマイグレーションという、仮想マシンを別のホストに移動するという対応をとりました。さらに、再度同じような問題が起こった時に、毎回手動で同じような対応をするのは大変なので、それらを自動化する仕組みを用意しました。こちらに関しては、テックブログに詳しく書いておりますのでぜひ見てみてください。
Pepabo Tech Portal「クラウドのノイジーネイバー問題を解決する動的スケジューラー」
https://tech.pepabo.com/2022/04/18/instance-migrator/
インフラの最適化による改善活動の例 ~その2~
2つ目はアプリケーションのデプロイを行うためにエラーレートが上がっていた例を紹介します。
この例では、以下のような手順でこの問題を改善しました。まずAPMやログを調査したところ、デプロイ時のフローとして実施されているPHP-FPMのリスタートのタイミングで502エラーが頻発していることが判明しました。その後、開発環境で確認したところ、PHP-FPMはデフォルトでGraceful Restartをするのを期待していましたが、実はそうではないことが判明しました。
ここで、期待していた動作であるGraceful Restartについて軽く説明します。Graceful Restartとは、プロセスを再起動する際に古い子プロセスへ新しいリクエストを受け付けない状態にして、すでに受け付けているリクエストを処理し、新しい子プロセスと入れ替わる動作のことをいいます。もしGracefulでないRestartをすると、すでに受け付けているリクエストの処理は終わらせずに、そのままバツンと切ってしまって新しい子プロセスと入れ替わります。そうすると今回のようにプロセス再起動のタイミングでエラーが出るようになってしまいます。我々はGraceful Restartを実現するために、PHP-FPMの設定のprocess _control_timeoutの値を、デフォルト値である0から直近のレスポンスタイムの95%タイルをもとに設定しました。このprocess_control_timeoutという値は、子プロセスがマスターからのシグナルを待つ最大時間を設定する値で、これを変更することによりGraceful Restartのようなことを実現することができました。これによって、デプロイのタイミングでエラーレートが上昇することがなくなりました。
先ほどまでの例は、インフラの最適化による改善活動のお話でしたが、次はアプリケーション開発による改善の例を紹介しようと思います。
アプリケーション改修による改善活動の例
この例ではSLO違反の調査から特定エンドポイントの処理が意図したよりも長かったことが判明した例を紹介します。
まずメトリクスより複数のインスタンスにおいてレイテンシが悪化していることが分かりました。複数のインスタンスで出ていることから、先ほどの例で出てきたノイジーネイバーが原因である線は薄くなりました。APMから特定エンドポイントの処理の中で投げられているクエリを確認したところ、N+1クエリが存在していることが分かりました。こちらはアプリケーション側の修正であることから、変更した部分の影響範囲の確認も含めて、カラーミーショップ担当エンジニアにレビューをもらったうえでクエリを修正しました。
これらの行動により、該当エンドポイントのレイテンシが改善されたことが確認されました。
おわりに
まとめに入ると思いきや、タイトルにも「新卒2年目から見る」という言葉が付いているので、SREチームに配属されて丸1年経った今と配属当初で自分の中で変わったことを少しだけ喋らせていただこうかなと思います。
まず1つ目が、SLI/SLOをベースとして物事を考えられるようになりました。
自分はそもそも配属時はSREのことをよく理解していなかったので、最初はできなかった行動でした。今はSREの先にお客様がいるということを考えながら行動することで、すべての行動やタスクの優先順位付けに良い影響を及ぼしているのではないかというふうに考えています。
2つ目に、何事も手順化するようになりました。タスクをこなしていくうちによく分からないことが出てくると、とりあえずチャットツールの検索を使って過去に同じようなはまり方をしている人を探したり、GitHubで似たようなことを調べたりします。ただ何度も同じような検索、調べたりする行動をすると時間がもったいないので、二度とイチから調べなくてもよいように、ドキュメント化するようになりました。
自分で言うのもなんですが、1年前に比べるとできることが広がったなと感じています。
というわけで、自分の感想はここまでにしたいと思います。
最後に、今回お話ししたことは以下の通りです。
一般的なSREに関する話として、SREとはサービスの信頼性を維持・向上することを目的としたアプローチのことを指す、というお話をしました。
次に、カラーミーショップのSRE活動について、SLI/SLOの観測を監視ダッシュボード、レビュー会などの手段を用いて実施しているということ、またエラーバジェット運用を開始したことなどをお話ししました。
最後にカラーミーショップにおけるSLI/SLOを用いた改善活動についてインフラからのアプローチとアプリケーションからのアプローチ、合計3例をお話しさせていただきました。
以上で発表を終わらせていただきます。ご清聴ありがとうございました。
アーカイブ映像
PHP Conference Japan 2022: 17年続くWebサービ… / やんまー、ほみるん | GMOペパボ – YouTube
ブログの著者欄
技術広報チーム
GMOインターネットグループ株式会社
イベント活動やSNSを通じ、開発者向けにGMOインターネットグループの製品・サービス情報を発信中
採用情報

GMOインターネットグループ採用情報

関連記事
-

【第1回・AI TALK】SUZURI・minne事業部CTO 黒瀧さんに聞く、AI活用の現在地と未来
技術情報
-

【インタビュー後編】育休明けに直面した「AI時代」 GMOペパボのプリンシパルデザイナー・佐藤咲が歩む「共創」の道
デザイン
-

【インタビュー前編】育休明けに直面したAI時代―GMOペパボプリンシパルデザイナー・佐藤咲が歩む「共創」の道
デザイン
-

Google Workspace カードが店頭販売の棚に並ぶ!~リリースを支えるSagaパターンの分散トレーシングとコンテキスト管理~
技術情報
-

配信コメントのストリーミング処理における、WebSocketとSSEの両立と設計について
技術情報
-

Dify × GASで実現する実用的なAIシステム – Gmail自動返信の事例 –
技術情報

KEYWORD
CATEGORY
-
技術情報(596)
-
イベント(237)
-
カルチャー(60)
-
デザイン(70)
TAG
- 5G
- AI
- AI TALK
- AI 機械学習強化学習
- AI/機械学習
- AIエージェント
- AIコーディング
- AI人財
- AI駆動
- Behind the Scenes
- BIT VALLEY
- blockchain
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CNDO
- CNDT
- CODE BLUE
- ConoHa
- ConoHa VPS
- CSS
- CTF
- Designship
- developer
- DevRel
- DevSecOpsThon
- Docker
- DTF
- Engineering Journey
- expert
- EXPERT CROSS
- GMO AI&ロボティクス商事
- GMO AIR
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティ byイエラエ
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMO大会議
- GMO天秤AI
- Go
- GPUクラウド
- GTB
- Hack-1グランプリ
- IETF
- iOS
- IoT
- ISUCON
- Japan Drone
- JapanDrone
- Java
- JJUG
- K8s
- Kaigi on Rails
- Kids VALLEY
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- OpenStack
- Perl
- PHP
- PHPcon
- PHPerKaigi
- Python
- RFC
- RPA
- Ruby
- SECCON
- Selenium
- Spectrum Tokyo Meetup
- splunk
- SRE
- Takumi byGMO
- Terraform
- TypeScript
- UI/UX
- vibe
- VPN
- VS Code
- XSS
- ZTNA
- アドベントカレンダー
- インターンシップ
- インハウス
- お名前.com
- クリエイターインタビュー
- クリエイティブ
- コンテナ
- サイバーセキュリティ
- サマーインターン
- スクラム
- スペシャリスト
- セキュリティ
- ソフトウェアサプライチェーン
- チームビルディング
- デザイン
- ネットのセキュリティもGMO
- ハーネスエンジニアリング
- バックエンド
- ヒューマノイド
- ヒューマノイドロボット
- プログラミング教育
- ブロックチェーン
- フロントエンド
- ペアリング暗号
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 国際ロボット展
- 国際標準化
- 基礎
- 多拠点開発
- 宮崎オフィス
- 応用
- 技育プロジェクト
- 技術広報
- 技術書典
- 新卒
- 新卒研修
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 機械学習
- 決済
- 生成AI
- 耐量子暗号
- 脆弱性診断
- 開発者
PICKUP
-

【EXPERT CROSS #2】暗号技術の可能性を未来につなぐ、「暗号のおねぇさん」の歩み(後編)
技術情報
-

【EXPERT CROSS #2】「暗号のおねぇさん」が国際標準化の場で残していく、インターネットへの「爪痕」(前編)
技術情報
-

デザインカンファレンス「Yoitoi Summit 2026」をGMOYours・フクラスにて開催!
デザイン
-

攻撃者優位の時代に問われる「使命感」 GMO Flatt Security&GMOサイバーセキュリティ byイエラエが描く、AI時代のセキュリティ構想(後編)ーEngineering Journey
技術情報
-

頂上と裾野の両方から「底上げ」 GMO Flatt Security&GMO サイバーセキュリティ byイエラエが支える、日本のサイバーセキュリティ(前編)ーEngineering Journey
技術情報
-

【開催レポート】八幡小学校 社会科見学 at GMO kitaQ
カルチャー
採用情報

SNS FOLLOW
