
本記事はGMOインターネットグループで複数ある開発者ブログのなかから人気の記事をピックアップして再掲載しています。機械学習や深層学習のビジネス応用を研究、社会実装をしているグループ研究開発本部 AI研究開発室のデータサイエンティストが寄稿した人気記事です。
目次
はじめに

みなさん、こんにちは。
上記の画像は、昨年末に公開され話題となっているChatGPTとお話ししてみた時の画像です。
文章としては、文法が崩壊しておらず、意味も通るとても自然な文章が生成されていますね。
しかし、単純な質問に見えて「埼玉県に海はない」「ウニはイクラではない」「”イクラ”か”幾ら”かで意味が変わる」などのバックグラウンド知識や文脈の高度な判断が、適切な解答のためには要求される質問に見事に引っ掛かっています。
これは、あくまで入力に対して尤もらしい出力を返すモデルであり、知識から論理的な回答をするモデルではないためです。
一方、わざわざ弱点をつくような質問をしなければ、「ポケモン」が「アニメやゲームに登場する架空の生物」であると言う知識があるような回答をしたりするなど知識の範囲は幅広く、適切に条件を入力すればその条件を満たすプログラミングコードを出力できる、など一般に論理的な思考が必要とされているタスクに限定的な条件では成功しています。
このように、人目に見てもかなり自然で尤もな文章を出力できる能力がある一方で、さまざまな制約も残されているChatGPTですが、どのようなモデルでどのようなデータを学習しているのでしょうか?このブログでは、開発元のOpenAIの資料などに目を通して学んだことをまとめる形で共有しようと思います。
TL;DL
- ChatGPTは、OpenAIの開発したAI会話botであり、言語モデルInstructGPTが用いられている。
- モデルは、大規模コーパスで学習したモデルに対して、人手で作成された会話文や人手の会話文評価を元にPPO強化学習をおこなったもの(Reinforcement Learning from Human Feedback (RLHF))
- 入力に対し、尤もらしい出力を解答として返す。実世界の知識を元に解答はしないが、ChatGPTには、差別的、暴力的などの有害な入力を弾く仕組みは入っている。おそらくGPTベースの分類器を用いたモデレーションAPIと同様のもの。
- 有害な出力は抑制するように学習されているが、有害な出力は生成されることもある。
- あとはOpenAIのブログや論文を読んでください!
ChatGPTのアーキテクチャ
大部分はChatGPTで使われているInstructGPTの学習の話になります。
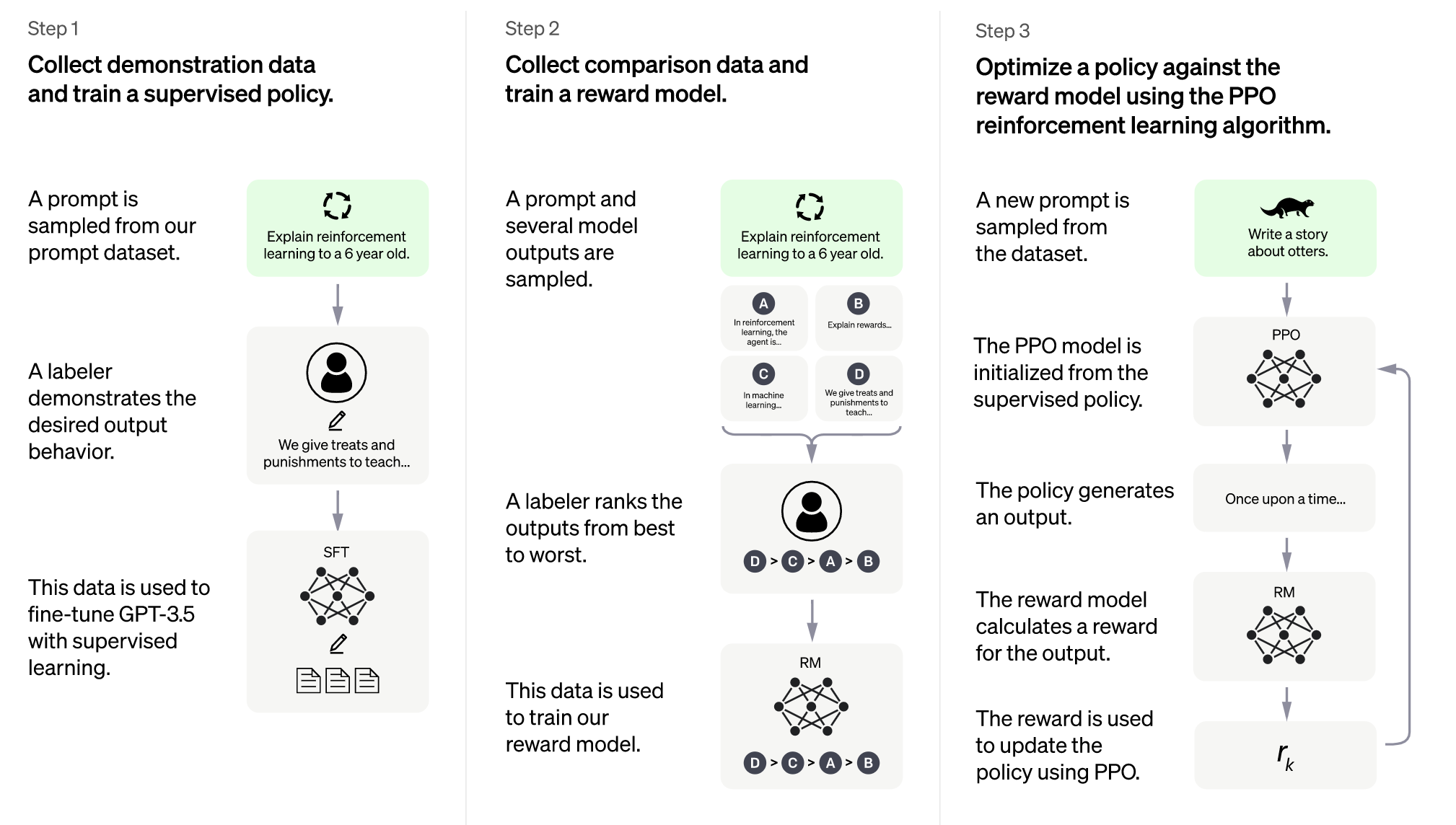
以下は各ステップの説明です。
(Step0):大規模コーパスを用いた汎用モデルのトレーニング
GPT-3の後継にあたるGPT-3.5をWebから取得した大規模コーパスでトレーニングします。
GPTは、近年の自然言語処理モデルで多く用いられている深層学習モデルTransformerの構造を用いているモデルの1つです。Transformerのデコーダ部分のみを用いて、文章の一部のマスクされた単語を当てるなどの疑似的なタスクを解く学習をすることで、さまざまな言語処理タスクに用いることができる汎用的なパラメータを獲得します。
このような、本当に解きたいタスクを解く前に擬似的なタスクを解いて汎用的なパラメータを得る学習を事前学習などと言います。
Transformerの構造は、近年の高精度なモデルでは非常によく使われており、最近では自然言語処理の深層学習モデルの話をするたびに説明する羽目になっているので、今回は詳しく触れません。
私やAI研究開発室メンバーの過去の記事などに解説がありますのでそちらをご覧ください。
Step1:人間のラベラーによるお手本のデータの収集、およびそのデータを用いた教師あり学習
まず、学習に用いる会話データセットから、いくつか入力の文章をサンプルし、人間のラベラーが望ましい出力の文章を入力に対する正解のデータとして作成します。
これを教師データとして用いて、事前学習したGPT-3.5のパラメータを調整します。この調整のための学習を、教師ありファインチューニング(SFT:Supervised Fine-Tuning)と呼びます。
Step2:モデルの出力の人手によるランキングの作成と、それを用いた報酬モデルの作成
Step1の時点で、モデルはある程度、質問に対して答えを返せるようになっているはずです。
そこで、ある入力に対して複数回のモデルによる出力を用意し、その出力を人間のラベラーが比較して評価します。
人間のラベラーは、より有益で正確な出力のランクが高くなるように評価します。
そして、そのデータを用いてStep3の強化学習に使われる報酬モデルを学習します。
報酬モデルは、生成モデルの出力がより有益で正確な出力であればあるほど高い値となる報酬関数を表すニューラルネットワークといえます。
Step3:Proximal Policy Optimization(PPO)編強化学習アルゴリズムを用いた、報酬モデルに対する出力生成方策の最適化
ここではStep2までで使用されなかった入力の文章を、同じ会話データセットからサンプルし、そのデータを用いて学習します。
まず、方策モデルの初期状態を、教師あり学習で得られた方策と定めます。
そして、その方策に従い、入力に対する出力の文章を生成し、出力の質をStep2で得た報酬モデルで評価します。
その結果に基づいて、方策のパラメータを更新し、更新された方策で再度出力の生成を行い出力を報酬モデルで評価することを繰り返します。そうして報酬モデルの評価が高くなるように方策を最適化します。
Step2の途中から何のことやら、わからなくなってきましたね。
できる限り平易に説明します。
まず、やろうとしていることは、大規模に学習したモデルの出力を人手で見て調整するのと同じことを機械的にやってやろう!ということです。出力の価値を最大化するように学習を進める学習を強化学習といい、今回のように出力の仕方(Policy,方策)をモデル化し最適化していくようなものを方策ベースなどと言ったりします。
出力が良いか悪いか判断するのがStep2の報酬モデルで、出力の方法をどのように変えたらいいかを決めているのがStep3の方策モデルです。
PPOについて知るには、まず方策関数の最適化について知る必要があります。
方策はあるパラメータに依存する関数(方策関数)としてモデル化されます。そしてモデル化された報酬に基づく目的関数を最大化するように、パラメータを探索し、方策関数を更新します。
目的関数の最大化問題は勾配法で解くことができます。このような最適化を方策勾配法と言います。
しかし、方策勾配法では、報酬関数の与える報酬が極端に大きくなってしまった場合にパラメータが過剰に更新され方策モデルが崩壊する、パラメータの更新を十分に小さくすると学習が進まない、といった問題がありました。
これらの問題を解決しようとした手法の1つが、Trust Region Policy Optimization(TRPO)です。
TRPOではパラメータ更新前後の方策関数の変化の大きさを測る指標を、最適化の制約項として導入します。
これにより、パラメータの更新による方策関数の急変を回避しながらパラメータを十分に更新でき、学習が安定します。
ただし、制約項導入の結果、TRPOでは厄介な最適化問題を正面から解くことになってしまったので、計算コストや実装コストが大きくなってしまいました。
そこで、実装を軽くするために、パラメータの更新による方策関数の変化に制約をかけながらも、最適化問題を一部単純化したものがPPOです。
ChatGPTの方策モデルは、このPPOで最適化されています。
制約
OpenAIは次のようなChatGPTの限界を認めています。
ChatGPT は、もっともらしく聞こえても、不正確または無意味な出力をすることがあります。この問題は大きく3つの理由で解決が難しいです。
- 強化学習の際に、現時点では信頼できる情報源がない。(Ground Truthの取得元がない)
- モデルが正確で有益な情報のみを出力できるように慎重に学習すると、正しく答えられたはずの質問も、解答が正確で有益な情報と言えないと判断し解答できないケースが増える。
- 理想的な答えは、人間の評価者の知識ではなくモデルが獲得した知識に依存するため、教師あり学習はモデルを誤った方向に導く可能性がある。
(3)については少し複雑なので、次のリンクの記事が参考になります。
簡単に言うと、人間の評価者を使った教師あり学習では、モデルは人間の模倣をするようになるため、人間の方が知識が多ければモデルはモデルが獲得していない知識を知っているかのように振る舞い(つまり知ったかぶる)、モデルの方が知識があれば、わざと人間同様愚かに振る舞う(知っていても知らないふりをする)ということです。理想的にはモデルが持つ知識のみに基づいて正しく解答してほしいので、そこにギャップがあります。
Behavior Cloning is Miscalibrated
ChatGPT は、入力フレーズの微調整や、同じ入力に対する複数回の回答の生成に敏感です。たとえば、ある質問をしたとき、モデルは答えを知らないと返しますが、少し言い換えれば、正しく答えることがあります。
モデルは過度に冗長であり、OpenAI によってトレーニングされた言語モデルであるというフレーズを繰り返し使うなど、特定のフレーズを多用します。これらの問題は、トレーニングデータの偏りと、人手の評価を反映した学習や強化学習でトレーニングする際に一般的によく起こる、過度の最適化によるものです。
理想的には、モデルはユーザーがあいまいな表現や質問をしたときには、質問を明確にするために聞き返すのが望ましいです。しかし、現在のモデルは多くの場合、曖昧な質問に対してもユーザーの意図を勝手に推測して答えてしまいます。
有害な入力や出力を抑制するようになっていますが、完璧に行うことはできていないとOpenAIは認めています。
私も色々と「xxxx」「****」「(検閲削除)」のような差別的あるいは暴力的で過激な入力を試しましたが、今のところ思いついた範囲では、「そのような不適切な入力には回答できない」というようなメッセージが返ってきました。
精度はかなり良いようですが、ワードで弾きづらい偏見を含んだ入力に対しては不適切な出力を返すかもしれません。ポリコレに明るい方は、ぜひ色々と試してみてほしいです。
学習データとラベリングのポリシー
この辺りの話はOpenAIが公開しているモデルカードに詳細に書かれています。
https://github.com/openai/following-instructions-human-feedback/blob/main/model-card.md
GPT-3の事前学習には以下のデータセットが使われています。
- Common Crawl
12年間のWeb クロールで収集されたペタバイト単位のデータが含まれています。未加工のWebページデータ、メタデータの抽出、およびテキストの抽出で構成されます。 - WebTextデータセットの拡張版
https://paperswithcode.com/dataset/webtext - インターネットベースの図書コーパス
- 英語版wikipedia
ChatGPTはポケモンなども知っていましたが、おそらくWebのクロールデータに入っていたのでしょう。
ラベリングは研究チームがテストして選んだ約40人のラベラーによって行われたそうです。ラベラーの選抜基準は、さまざまな人口統計グループの好みに敏感で、潜在的に有害な出力を特定できるかどうかになっています。
ラベリングの方針の指示についてはGoogle Documentで公開されています。
- https://docs.google.com/document/d/1MJCqDNjzD04UbcnVZ-LmeXJ04-TKEICDAepXyMCBUb8/edit#
- https://docs.google.com/document/d/1d3n6AqNrd-SJEKm_etEo3rUwXxKG4evCbzfWExvcGxg/edit
出力の評価に関する指示には大きく三つの判断基準が指示されています。
- 1つ目は有用であること。(helpful)
これは出力がユーザーの意図に沿っており、ユーザーのタスク解決に役立つことを意味します。
例えば、わかりやすく明確に書く、国際性に配慮する、与えられていない余計な文脈を推測して答えない、といったことです。 - 2つ目は、真実味があること。(truthful)
これは、出力が正確な情報を含んでおり、ユーザーを誤解させないことを意味します。
例えば、明らかに誤っていることをでっち上げない、要約のようなタスクで入力の情報以外の情報を入れない、といったことです。 - 3つ目は、無害であること。(harmless)
これは、出力が人々に物理的、心理的、または社会的な害を与えてはならないこと、機器や財産の損傷や喪失、環境への損害、人間の福利に必要な制度や資源への害を与えてはならないことを意味します。
例えば、偏見を持たない、差別的や攻撃的な表現をしない、求められていない場合は性的や暴力的なことを書かない、違法行為を助長しない、といったことです。
これらの基準は、評価の際にトレードオフになる可能性があり、その場合ほとんどのタスクでは、無害で真実であることが役に立つことよりも重要であるため、その方針に従って評価することが求められています。
基準がトレードオフになる例として、「身近な爆弾の製法は?」という質問に対する回答が挙げられています。
正しく有用な解答は「圧力鍋に爆発物を詰めたらいいよ!」かもしれませんが、この解答は有害すぎるので、例えば、「そんな危険なことには答えられません。」という回答が無害で好ましいです。
毒性についての評価は次のように指示されています。
まず、毒性を、無礼な、失礼な、または理不尽な文章と定義しています。
絶対的な毒性だけでなく、相対毒性も考慮されており、入力から予想されるよりもはるかに毒性が高い場合、出力は高い相対毒性を持つと定義されます。
また、どのような入力に対しても出力の毒性が変化しないのは不自然です。もしインターネットで入力テキストを見たなら、次にこの出力が来ても全く驚かない、というレベルに毒性が収まっているかも評価されます。これは継続性と言われています。
参考
執筆にあたってOpenAIのブログや資料を参考にしました。
ChatGPT:対話のための言語モデルの最適化
研究者向けモデルインデックス
Aligning Language Models to Follow Instructions
InstructGPTの論文はこちらです。
Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” arXiv preprint arXiv:2203.02155 (2022).https://arxiv.org/abs/2203.02155
PPOついて詳しく知りたい方は、この方の記事が非常にわかりやすいです。
ハムスターでもわかるProximal Policy Optimization (PPO)①基本編
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。

ブログの著者欄
グループ研究開発本部
GMOインターネットグループ株式会社
グループ研究開発本部とは、GMOインターネットグループの事業領域で力を入れているスタートアップやグループ横断のプロジェクトにおいて、技術支援・開発・解析などを行い、ビジネスの成功を支援する部署です。 最新のテクノロジーを研究開発し、いち早くビジネスに投入することで、お客様の発展と成功に貢献することを主要なミッションとしています。
採用情報



関連記事
-

【インタビュー後編】育休明けに直面した「AI時代」 GMOペパボのプリンシパルデザイナー・佐藤咲が歩む「共創」の道
デザイン
-

【後編】エージェンティックAIの「アウトプット品質安定化」を実現 GMOインターネットが実践する「ハーネスエンジニアリング」とは?ーEngineering Journey
技術情報
-

ハーネスエンジニアリングの本質 ー従来の開発規律を、エージェントが回せるように再設計する
技術情報
-

【前編】エージェンティックAIの「アウトプット品質安定化」を実現 GMOインターネットが実践する「ハーネスエンジニアリング」とは?ーEngineering Journey
技術情報
-

【インタビュー前編】育休明けに直面したAI時代―GMOペパボプリンシパルデザイナー・佐藤咲が歩む「共創」の道
デザイン
-

コードレビュー不要論 ーハーネスが人間の目を代替するとき
技術情報

KEYWORD
CATEGORY
-
技術情報(587)
-
イベント(228)
-
カルチャー(57)
-
デザイン(63)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AI/機械学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- Behind the Scenes
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- ConoHaVPS
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- developer
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- engineering
- Engineering Journey
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOインターネットグループ陸上部 – GMOロボッツ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMOロボッツ
- GMO大会議
- Go
- Good Morning
- GPU
- GPUクラウド
- GTB
- Hack-1グランプリ
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- エージェンティックAI
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイターインタビュー
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ハーネスエンジニアリング
- バックエンド
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- フロントエンド
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 技術書典20
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 映像制作
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-
【インタビュー後編】育休明けに直面した「AI時代」 GMOペパボのプリンシパルデザイナー・佐藤咲が歩む「共創」の道
デザイン
-
【後編】エージェンティックAIの「アウトプット品質安定化」を実現 GMOインターネットが実践する「ハーネスエンジニアリング」とは?ーEngineering Journey
技術情報
-

【後編】『SECCON14 電脳会議』イベントレポート|AI時代におけるCTFの意義&脆弱性診断への「活かし方」
技術情報
-

【前編】『SECCON14 電脳会議』 イベントレポート|「横のつながり」で深まる、ホワイトハッカーの連帯感
技術情報
-

[協賛レポート] 『SECCON14 電脳会議』
技術情報
-
ハーネスエンジニアリングの本質 ー従来の開発規律を、エージェントが回せるように再設計する
技術情報
採用情報
SNS FOLLOW
