
Perlを中心としたIT関連カンファレンス「YAPC::Kyoto 2023」が3月19日に京都市の京都リサーチパークで開催されました。Perlに限らないさまざまな技術情報が満載のイベントです。今回は「try/catch」をテーマにしたということで、初めて現地とオンラインというハイブリッドでの開催となりました。
GMOインターネットグループからは、GMOペパボの技術者が参加して講演を行いました。今回はその講演から『入門 障害対応 「サービス運用はTry::Catchの繰り返しだよ、ワソン君」』をお届けします。
目次
登壇者
- 渡部 龍一 @ryuichi_1208
GMOペパボ株式会社 技術部プラットフォームフォームグループ SRE
GMOペパボの古参サービスを支える技術部プラットフォームグループ
今回講演した渡部が主に担当しているサービスは、ネットショップ作成・運営のためのプラットフォームである「カラーミーショップ」です。2005年にサービス提供を開始した古参サービスで、流通総額は1兆円を超え、比較的大きなトラフィックを有するサービスです。
カラーミーショップのサービスの特徴やサービス構成は、「CI/CD Conference 2023 by CloudNative Days」(https://developers.gmo.jp/30849/)でもご紹介しているので、そちらも参考にしてください。
そんなカラーミーショップをはじめとしたGMOペパボのサービスにおいて、渡部が所属する技術部プラットフォームグループが担当しているのは、「サービスの多様性を確保し、サービスの成長に合わせて適切な環境を提供する」という点だと渡部は言います。具体的にはサーバーの調達、キッティング、SREによるサービスレベルの向上、クラウド環境の検証や選定、専門事業部門のアプリケーションの改善・開発など、事業の成長を支えることを目指しています。
障害対応における5つのフェーズ
そんなGMOペパボにおける障害対応フローが今回のテーマです。
渡部はまず、サービス障害の定義として「通常の運用状態から逸脱してユーザーに影響を与える事象」と位置づけます。これはシステムの異常動作やアプリケーションの問題などが該当します。
それに対する「障害対応」とは、「サービス障害が起こった状態から通常の運用状態に戻すための対応」ということになります。
この障害対応を、渡部は5つのフェーズに分類します。
(1)障害の影響範囲の特定と分類
まずは提供範囲の特定が重要になります。使えない機能は何か、例えば外形監視が落ちている場合はどこに影響があるかを評価し、分類します。その結果、問題解決に必要な情報を集めることができ、影響範囲が分かれば、原因特定の方針決定の根拠となる情報も得られると言います。
(2)関係者への連絡
続いて、ユーザーに対してどのような影響があるのかを、関係者に周知することが重要だと渡部は指摘します。障害発生時は技術的な話をしがちですが、最初にやるべきはユーザーへの影響がどの程度あるかを共有することで、「報告は結論ファーストを意識している」と渡部。
同時に、サービスに関わる様々なチームへの連絡も行います。渡部の所属するSREチーさまざまは障害アラートなどを出しますが、障害の復旧がすべてできるわけではありません。そのため、マネージャーやカスタマーサポートチームに連絡して協力を仰ぐこともあるそうです。エンドユーザーに対して影響がある障害であれば、SNSなどでのアナウンスも必要になるので担当者と共有をします。
障害を起こしたアプリケーションに精通しているメンバーが、常に障害のアラートを受け取れるわけではないため、その場合はアプリケーションエンジニアに、セキュリティインシデントならセキュリティエンジニアにエスカレーションすることもあるそうです。
(3)原因調査
3番目が「なぜ繋がらないのか」を調べるフェーズです。「外形監視になった」、「Webサービスに繋がらなくなった」というだけでは、「なぜ繋がらないのか」の原因は分かりません。
最も頻度が多いのは、サービスに何かしらの変更を加えた際に繋がらなくなるエラーが起きることだと言います。そのため、まずは変更したシステムを調べることになります。
例えば、アプリケーションをデプロイした場合はその内容を確認したり、GUIの設定画面からサーバーの設定を変更していたらそれを確認したりします。とはいえ、「何もしていないのに壊れるケースが”たまによくある”」と渡部は苦笑します。
他にはハードウェアが原因の場合や急激なトラフィックでソフトウェアが耐えきれない場合があるので、もう少し詳しく原因を探っていくそうです。サービスを構成するコンポーネントから、怪しい部分を探るわけです。
原因調査は、仮説確認を繰り返していくフェーズだと渡部は話します。どこが怪しいのか全くわからない状いであれば、例えば構成図を見てロードバランサーやWebアプリケーション、データベース、ネットワーク、外部連携サービスなど、何かおかしくなっていないかを見ていきます。
渡部が取る手法としては「挟み撃ち法」があるそうです。これは、例えばL3レイヤーを調べたらL7のWebアプリケーションを確認し、L4を見てL6を見る、というような順番で確認していく方法です。「OSI参照モデルをイメージしてもらえれば分かりやすい」と言います。
このフェーズではログ調査も行って、怪しいログをチェックすることもしています。
(4)復旧作業の実施
原因が判明したら復旧作業を実施します。これには2つのパターンがあり、一つ目が「根本対応」です。調査で原因が完全に判明すれば根本的な対応が行えます。ところが、原因は分からないけれども接続できないということもあります。
そうした場合に行うのが「止血対応」と呼ばれる作業です。過去の知見から、「もしかしたら復旧するかもしれない」という対応手段を試していくというものです。ここで大事なのが、「原因が分からなくてもユーザーが正常にサービスを利用できる」ことを最優先にするということです。そのため、まずは止血対応によってサービスを正しい状態にすることを意識しているそうです。
具体的な手法としては、OSやミドルウェアの再起動、アップデートをしていたら根本原因が分からなくてもロールバックするといった手段で復旧を試みます。急激なトラフィック増加等があればリソース不足の可能性もあるので、スケールアウトなどの対応をします。
(5)ポストモーテム
最後のフローがポストモーテムです。これは障害対応後に行われる反省と改善のための分析会議」で、障害の原因、障害対応の振り返りを行うことで、今後の改善点を見つけることを目的としています。
こうした会議でありがちなのが、失敗の要因を明確にすることだけになってしまい、成功の要因が明らかにならないという例があります。そこで渡部は「対応がなぜうまくいったのか」という要因を分析してドキュメント化も行っているそうです。
この会議のドキュメントは、会議に未参加のチームや、今後参画する新メンバーも学んでいけることを意識して執筆していると言います。具体的にはなぜこうした対応をしたのか、障害復旧後にアクションアイテムがあったらイシュー化して追跡しやすくする、といった記録を残していると言います。
1人に頼らずメンバー全員の能力向上を
こうした障害対応の能力をどのように向上させるか。渡部はまず「障害対応能力」について、前述の5フェーズを全て1人で担当できるという人物が能力値マックスと規定します。
そもそも障害をゼロにすることはできないという判断から、障害が発生したときに対応するメンバーの能力向上が必要というのが渡部の考えです。そのためには「何度でも障害に向き合っていく必要がある」と渡部は言います。
以前まで、GMOペパボでも障害発生時に一部の優秀なエンジニアが1人で原因特定から復旧までを短時間で対応してしまい、他のメンバーの知見が残らないということがあったそうです。
そういった優秀なエンジニアも24時間365日稼働できるわけではないので、そのエンジニアがいないときの障害対応の時間が長くなってしまい、サービスの信頼性低下にも繋がりかねません。
そのため、障害対応能力が高いメンバーがチーム内に多く存在するほど、サービスの信頼性向上に繋がる、というのが渡部の考えです。
そうしたメンバーを増やすためには、障害対応の教科書のような書籍を学習するだけで実践するのは難しいといいます。例えばサービスの再起動をするためのコマンドは学べても、どのタイミングで、どういった根拠で再起動をするのか、といった見極めは経験が必要だからです。もちろん、本番環境で学ぶのが一番なのですが、それが難しい場合もあります。
2つの施策で能力向上
渡部が採用した施策は2つ。Playbookの作成と障害対応訓練です。
Playbookとはアメリカンフットボールの用語で、戦略やプレイをまとめた資料です。渡部は「一定の知見や経験を持った人でなければ理解できない熟練者向けのドキュメント」と位置づけます。渡部のチームでは、障害対応能力の高いメンバーが行った作業内容と、その作業に至った思考の流れをドキュメント化しているそうです。

なぜそのコマンドを打ったのか、なぜその作業を行ったのか、結果として何が起きたのか、そういった部分を取りまとめることで、他のメンバーの障害対応能力向上に繋がると考えたと言います。
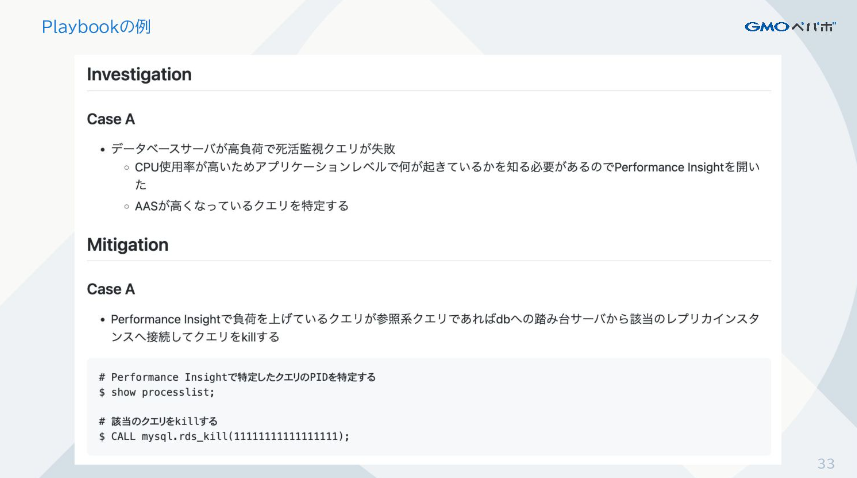
こうしてPlaybookに事例を積み上げて情報を共有し、メンバーのノウハウを蓄積していくことに加えて、障害対応経験を増やすための訓練も行います。
過去に発生した障害などをテスト環境に再現して、実際に調査から復旧までを実践してもらう内容ということで、さらに出題者と回答者に分かれて実施しているそうで、机上演習のようなものというイメージのようです。
Playbookと障害対応訓練という施策を実施した結果、「チーム全体の障害対応能力の向上に繋げることができた」と渡部は言います。調査から復旧までを単独で実施できるメンバーも増えているそうです。訓練で実施したトレーニングと同じ障害が、訓練の数時間後に実際に発生する、といったこともあったそうで、訓練を生かすこともできたと言います。
障害対応も一日にしてならず
「障害を完全になくすことはできない」。まとめとして渡部はそう伝えます。そのため、障害は起きるものとして対応に向き合う必要があります。優秀なメンバーだけが対応するような属人的な状況は危険で、障害対応できるメンバー数を可視化していく必要があるとしています。
障害対応できるメンバーを増やすためのPlaybookや障害訓練といった施策も、すぐに効果が出るような施策ではなく、渡部は「ローマは一日にしてならず、障害対応も一日にしてならず」として、継続的に続けることが必要だと強調しました。
質疑応答では、Playbookを作成するためのコストの問題について問われ、渡部は「コストはかかるけれど、最終的にメンバーが増えるというチームの状況だったので、それでペイできるという判断で未来への投資としてメンバーを説得しました」と回答。ちなみにPlaybookには「障害対応での思考の流れをドキュメント化する」という例を挙げた渡部ですが、これは作業中にSlackのスレに書き込んでいって、最後にまとめるそうです。
障害対応訓練に対して問われた渡部は、「簡単なものだと30分や1時間で障害環境を用意して、回答を受ける側も1時間程度で終わる」とのことで、極端に長時間化かかるような訓練はまだしていないということです。逆に言えば、それでも訓練としては意味があるということと言えそうです。
アーカイブ
映像はアーカイブ公開しておりますので、
まだ見ていない方、もう一度見たい方は 是非この機会にご視聴ください!
ブログの著者欄
技術広報チーム
GMOインターネットグループ株式会社
イベント活動やSNSを通じ、開発者向けにGMOインターネットグループの製品・サービス情報を発信中
採用情報

関連記事
-

【第1回・AI TALK】SUZURI・minne事業部CTO 黒瀧さんに聞く、AI活用の現在地と未来
技術情報
-

【インタビュー後編】育休明けに直面した「AI時代」 GMOペパボのプリンシパルデザイナー・佐藤咲が歩む「共創」の道
デザイン
-

【インタビュー前編】育休明けに直面したAI時代―GMOペパボプリンシパルデザイナー・佐藤咲が歩む「共創」の道
デザイン
-

Google Workspace カードが店頭販売の棚に並ぶ!~リリースを支えるSagaパターンの分散トレーシングとコンテキスト管理~
技術情報
-

配信コメントのストリーミング処理における、WebSocketとSSEの両立と設計について
技術情報
-

Dify × GASで実現する実用的なAIシステム – Gmail自動返信の事例 –
技術情報

KEYWORD
CATEGORY
-
技術情報(598)
-
イベント(237)
-
カルチャー(60)
-
デザイン(70)
TAG
- 5G
- AI
- AI TALK
- AI 機械学習強化学習
- AI/機械学習
- AIエージェント
- AIコーディング
- AI人財
- AI駆動
- Behind the Scenes
- BIT VALLEY
- blockchain
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CNDO
- CNDT
- CODE BLUE
- ConoHa
- ConoHa VPS
- CSS
- CTF
- Designship
- developer
- DevRel
- DevSecOpsThon
- Docker
- DTF
- Engineering Journey
- expert
- EXPERT CROSS
- GMO AI&ロボティクス商事
- GMO AIR
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティ byイエラエ
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMO大会議
- GMO天秤AI
- Go
- GPUクラウド
- GTB
- Hack-1グランプリ
- IETF
- iOS
- IoT
- ISUCON
- Japan Drone
- JapanDrone
- Java
- JJUG
- K8s
- Kaigi on Rails
- Kids VALLEY
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- OpenStack
- Perl
- PHP
- PHPcon
- PHPerKaigi
- Python
- RFC
- RPA
- Ruby
- SECCON
- Selenium
- Spectrum Tokyo Meetup
- splunk
- SRE
- Takumi byGMO
- Terraform
- TypeScript
- UI/UX
- vibe
- VPN
- VS Code
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- お名前.com
- クリエイターインタビュー
- クリエイティブ
- コンテナ
- サイバーセキュリティ
- サマーインターン
- スクラム
- スペシャリスト
- セキュリティ
- ソフトウェアサプライチェーン
- チームビルディング
- デザイン
- ネットのセキュリティもGMO
- ハーネスエンジニアリング
- バックエンド
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- フロントエンド
- ペアリング暗号
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 京都大学
- 国際ロボット展
- 国際標準化
- 基礎
- 多拠点開発
- 大阪公立大学
- 宮崎オフィス
- 強化学習
- 応用
- 技育プロジェクト
- 技術広報
- 技術書典
- 拡張知能
- 新卒
- 新卒研修
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 機械学習
- 決済
- 生成AI
- 産学連携
- 研究開発
- 耐量子暗号
- 脆弱性診断
- 開発者
PICKUP
-

【開催レポート・後編】第6回 京大ミートアップ|集合的予測符号化から見る人間とAIの共生
技術情報
-

【開催レポート・前編】第6回 京大ミートアップ|フィジカルAIとAI時代の知性
技術情報
-

【EXPERT CROSS #2】暗号技術の可能性を未来につなぐ、「暗号のおねぇさん」の歩み(後編)
技術情報
-

【EXPERT CROSS #2】「暗号のおねぇさん」が国際標準化の場で残していく、インターネットへの「爪痕」(前編)
技術情報
-

デザインカンファレンス「Yoitoi Summit 2026」をGMOYours・フクラスにて開催!
デザイン
-

攻撃者優位の時代に問われる「使命感」 GMO Flatt Security&GMOサイバーセキュリティ byイエラエが描く、AI時代のセキュリティ構想(後編)ーEngineering Journey
技術情報
採用情報

SNS FOLLOW
