
こんにちは。グループ研究開発本部 次世代システム研究室です。
議事録作成に手間がかかるため、コア業務に集中できないと感じている方は多いでしょう。このような方におすすめなのがAIを活用した議事録の自動作成です。今回のブログでは、OpenAI社が開発したChatGPT APIとWhisperを使った音声ファイルの要約システムの構築を紹介したいと思います。
目次
1.やりたいこと
目的:音声ファイルの要約を自動化すること
使用する技術:OpenAIのChatGPTとWhisper
実現手段:
- Dockerで音声自動要約専用サーバーを構築
- Flaskを利用して音声ファイルを処理するAPIを作成
- Whisperで音声ファイルをテキストに変換
- ChatGPT APIで要約を生成
- 要約テキストをユーザーに返却
2.環境構築
2-1.Whisperサーバー構築
Whisperとは、OpenAIが開発している汎用的な音声認識モデルです。
インターネット上から収集した68万時間におよぶ音声データで学習され、音声翻訳や言語識別だけでなく、多言語音声認識を行うことができるマルチタスクモデルでもあるモデルになります。Whisperの日本語の単語誤り率は6.4%であり、他の言語と比較しても高い精度で文字起こしが可能だと言えます。
今回はDocker環境を使うので以下のDockerfileを実装しました。
ROM python:3.10-slim
WORKDIR /python-docker
COPY requirements.txt requirements.txt
RUN apt-get update && apt-get install git -y
RUN pip3 install --upgrade pip
RUN pip3 install -r requirements.txt
RUN pip3 install "git+https://github.com/openai/whisper.git"
RUN pip3 install --upgrade openai
RUN apt-get install -y ffmpeg
COPY . .
EXPOSE 5000
CMD [ "python3", "-m" , "flask", "run", "--host=0.0.0.0"]音声自動要約専用サーバーは、Python 3.10-slimベースのDockerイメージを使用し、requirements.txtで指定されたPythonパッケージをインストールします。WhisperとOpenAIのPythonパッケージをインストールし、FlaskフレームワークでAPIを実装します。APIをポート5000で実行するように指定しています。また、音声・動画の変換、再生、録画などを行うためffmpegもインストールしておきます。requirements.txtに以下の内容で準備します。
autopep8==1.6.0
certifi==2021.10.8
charset-normalizer==2.0.7
click==8.0.3
et-xmlfile==1.1.0
Flask==2.0.2
idna==3.3
itsdangerous==2.0.1
Jinja2==3.0.2
MarkupSafe==2.0.1
numpy==1.21.3
openai==0.19.0
openpyxl==3.0.9
pandas==1.3.4
pandas-stubs==1.2.0.35
pycodestyle==2.8.0
python-dateutil==2.8.2
python-dotenv==1.0.0
pytz==2021.3
requests==2.26.0
six==1.16.0
toml==0.10.2
tqdm==4.62.3
urllib3==1.26.7
Werkzeug==2.0.22-2.ChatGPT API向けの設定
2023年3月2日(米国時間では1日)、OpenAIのChatGPTのAPIが公開されました。
プログラムからChatGPTを使うため、APIキーを発行してもらわなければなりませんので、OpenAIにログインし、右上のアイコンからView API Keyをクリックします。APIのページにいけるので、そこから新しいシークレットキーをcreateします。作成されたsecret keyはメモしておきましょう。
OpenAIから取得したAPIキーを.envファイルを設定しますしょう。
LASK_APP=app
FLASK_ENV=development
# Once you add your API key below, make sure to not share it with anyone! The API key should remain private.
OPENAI_API_KEY=sk-jxxxxxxxxx2-3.音声自動要約アプリの実装
さて、APIサーバーのエントリースクリプト(app.py)を実装しましょう。
このソースコードは、Flaskフレームワークを使用してWebアプリケーションを構築し、Whisper及びChatGPT APIを使用して音声ファイルを自動要約します。
「/summary」エンドポイントにPOSTリクエストを送信すると、音声ファイルを受け取り、Whisperを使用してテキストに変換し、OpenAI APIを使用して自動要約を作成し、JSON形式で結果を返します。
中身は以下の通りです。
from flask import Flask, abort, request
from tempfile import NamedTemporaryFile
import os
import whisper
import openai
import torch
# NVIDIA GPUが利用可能かどうかを確認
torch.cuda.is_available()
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# Whisperモデルをロードする
model = whisper.load_model("medium", device=DEVICE)
# OpenAPI APIキーを設定する
openai.api_key = os.getenv("OPENAI_API_KEY")
app = Flask(__name__)
@app.route("/")
def welcome():
return "Welcome to my Blog Post about ChatGPT and Whisper!"
@app.route('/summary', methods=['POST'])
def handler():
if not request.files:
# ユーザーがファイルを渡さなかった場合は、400 (Bad Request) エラーを返す
abort(400)
results = []
# ユーザーが渡したすべてのファイルに対してループする
for filename, handle in request.files.items():
# 一時ファイルを作成する.
temp = NamedTemporaryFile()
# ユーザーがアップロードしたファイルを一時ファイルに書きこむ
handle.save(temp)
# Whisperモデルで音声の一時ファイルからテキストを取得する
result = model.transcribe(temp.name)
# Sテキストを要約する
summary_result = summary_text(result['text'])
# 結果オブジェクトを作成する
results.append({
'transcript': result['text'],
'language': result['language'],
'summary': summary_result,
})
# JSON形式で結果を返却する
return {'results': results}
def summary_text(transcribed_text):
if len(transcribed_text) == 0:
return ""
print(generate_prompt(transcribed_text))
try:
response = openai.Completion.create(
model="text-davinci-003",
max_tokens=1024,
stop=None,
prompt=generate_prompt(transcribed_text),
temperature=0.7,
)
print(response)
return response.choices[0].text
except Exception as e:
print(e)
return ""
def generate_prompt(transcribed_text):
return """以下の文章は日本語におかしいなところを修正してください。修正した文章を説明不要で箇条書き文章のみに簡潔に答えてください:
{}""".format(transcribed_text)summary_text関数は、テキストを受け取り、OpenAI APIを使用して自動要約を作成します。 関数のパラメータは以下のとおりです。
model:使用する言語モデルの種類を指定する(ここでは”text-davinci-003″を使用)
max_tokens:生成される文章の最大トークン数を指定する(ここでは1024を指定)
stop:生成される文章の停止語を指定する(ここでは指定せずNoneとしている)
prompt:生成される文章のプロンプトとなる文章を指定する(ここではtranscribed_textを引数として渡してgenerate_prompt()で作成)
temperature:文章生成のランダム性を調整するパラメータ。0に近いほど一意な文章が生成されやすく、1に近いほど一般的な文章が生成されやすくなる。0から1の値を指定する(ここでは0.7を指定)。
このChatGPTのAPI仕様が公開されているので興味の方はご参照ください。
2-4.アプリケーションサーバを起動
早速、dockerコマンドで音声自動要約サーバーのImageをビルドしましょう。Dockerfileが存在するディレクトリに移動し、以下のコマンドを実施しましょう。
docker build -t audio-summary-api . 大量の依存関係を解決するために必要なパッケージをインストールしたり、GPUカード対応のためサイズの大きいファイルのダウンロードが発生するのでビルド時間が10分以上になります。
Docker Imageをビルドできたら次のコマンドでAPIサーバを立ち上がりましょう。
docker run -p 5000:5000 audio-summary-api ここまでは音声自動要約サーバーの準備ができました。
3.実験結果と評価
3-1.自動要約された音声ファイル
早速、音声自動要約APIを検証しましょう。次のcurlコマンドを使用してこのAPIを検証できます。
curl -F "file=@/path/to/file" http://localhost:5000/summary 結果として、JSONオブジェクトに以下の項目が含まれるはずです。
language: Whisperが音声ファイルから認識したテキストの言語
transcript: Whisperが音声ファイルから認識したテキストの本文
summary: ChatGPTが要約したテキスト
今回は、次世代システム研究室の新卒メンバー1年目後のインタビュー動画から音声を抽出して構築したシステムでテキストに要約したいと思います。yt-dlpなどPythonのライブラリを使用して音声抽出が可能ですが、今回のブログでは対象外としました。
3-2.要約結果
ChatGPT APIの出力を安定するまでモデルを切り替えたり、Promptの内容をチューニングしたりする必要がありますしたのでソースコードに記載したPromptのように対応しましたが、
ChatGPTのInputとなるWhisperのOutputをチューニングが大事ですね。ちなみに、Whisperモデルは以下の9種類がありますが、今回は日本語を対応する多言語モデルのみ使います。
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
各Whisperモデルを検証するため、app.pyにてwhisper.load_modelにモデル名を指定しましょう。
# Load the Whisper model:
model = whisper.load_model("base", device=DEVICE)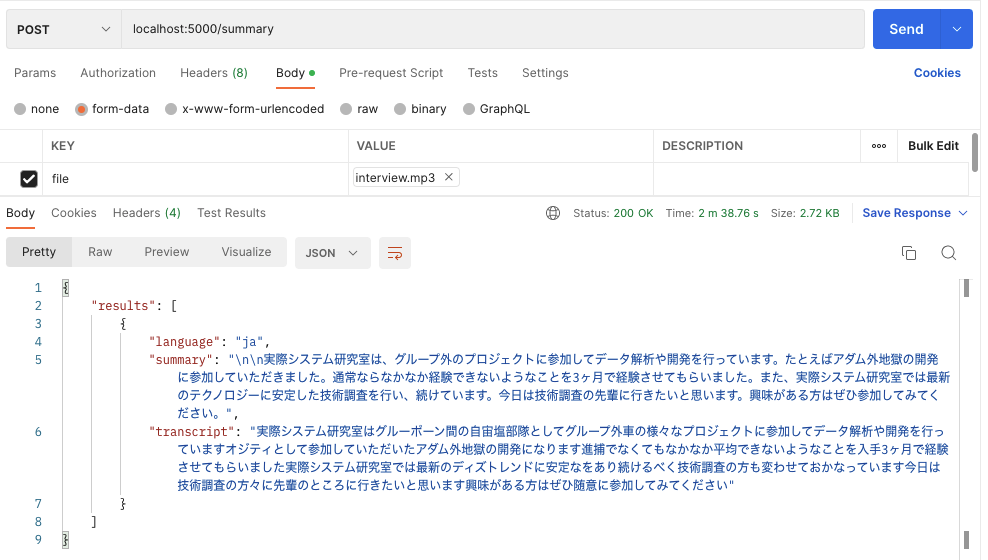
音声ファイルを指定して、自動要約APIを実行しましょう。APIの実行には、私自身がよくPostmanを使っているので、今回もPostmanで検証を行いたいと思います。
使えませんね。。ベースモデルだとWhisperのOutputとなるtranscriptが非常に精度が低いため、音声からテキストに変換した結果は全く使えませんでした。。
Whisperベースモデルの検証結果に加えて、上位のモデルも含めた検証結果を確認したいと思います。そのため、ソースコードにてWhisperモデルをmediumに設定して検証してみましょう。
# Whisperモデルをロードする
model = whisper.load_model("medium", device=DEVICE)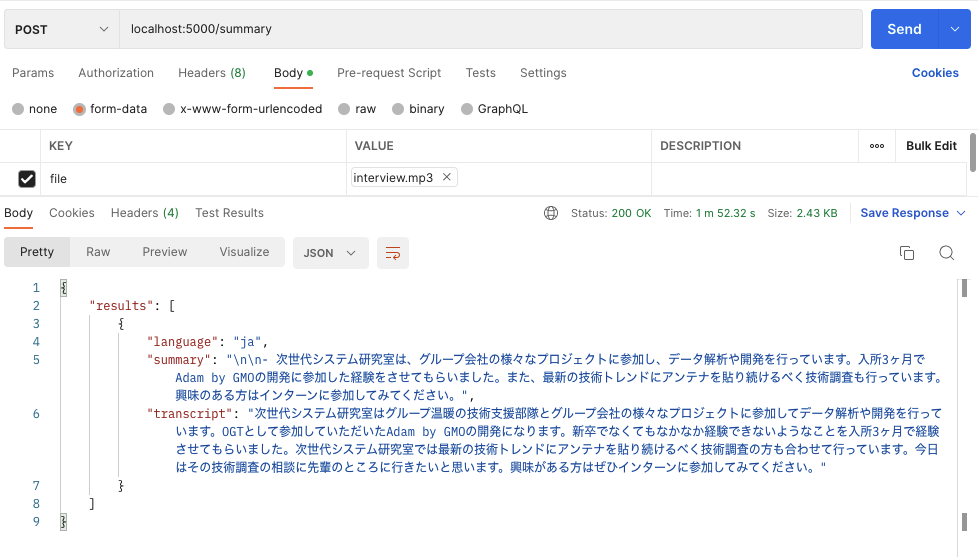
見事、mediumモデルを使うとtranscriptの内容がかなり改善されたため、ChatGPTによる要約結果であるsummaryも大幅に改善されました。厳密に言えば、この要約文章はまだ改善の余地があると思いますが、意味はかなり明確になりました。
今回の検証結果は以下のテーブルでまとめました。
| Whisper model | モデルサイズ | 音声ファイルサイズ | 初回サーバ起動時間 | 自動要約時間 | 精度 |
|---|---|---|---|---|---|
| tiny | 72.1MB | 950Kb | 40秒 | 15秒 | 非常に低い |
| base | 139MB | 950Kb | 1分38秒 | 17~20秒 | 非常に低い |
| small | 461MB | 950Kb | 4分19秒 | 28秒 | 低い |
| medium | 1.42GB | 950Kb | 14分08秒 | 1分24秒 | 良い |
| large | 2.87GB | 950Kb | 起動不可(リソース不足) | – | 使えない |
検証結果からみるとWhisperモデルは、モデルサイズが大きくなるほど高い精度が得られます。特に、最近large-v2モデルも公開されているようですので、さらなる精度を期待できますね。今回の検証は、Whisperのmediumモデルからは良さそうな精度を得ましたが、Macbook ProのPCではその以上の精度を期待するlargeモデルが正常に実行できないことは少し残念でした。また、モデルサイズの大きさや処理速度に大きく影響を与える問題を発見しました。モデルの初回ダウンロードのためサーバの立ち上がる時間が長い場合があるため、リアルタイム対応は複雑な対応になるかもしれませんが、短期間で音声認識にはGPUカードを搭載する高スペックなサーバーを検討するか有料版のWhisper APIおよびChatGPT APIの利用を検討したほうがよさそうです。最近、OpenAIの有料版APIの導入により、1時間のミーティングをわずか3分で議事録を作成できるようになった記事が公開されましたので。
ChatGPT API (GPT-4)とWhisper APIの利用費用
今回のブログでは、Whisperの実行環境を自分で構築し、ChatGPT APIのtext-davinci-003モデルを使用して無料で音声自動要約システムを構築しました。しかし、より高性能なAPIであるGPT-4やWhisper APIを使用する場合は、以下の価格表に記載されている料金が必要となります。この価格表はOpenAIが正式に公開しているページに記載しているのでご参照くだだい。
今回の検証音声ファイルの長さが30秒程度、生成したトークンが1000以内なので、GPT-4およびWhisper API(large-V2 モデル)を使うと1回の要約は$0.036(3/29現在のドル円は1$=131.5円で換算すると4.8円)になるかと思います。
| モデル | トークンタイプ | 価格 |
|---|---|---|
| GPT-4 | プロンプトトークン | 1000あたり$0.03 |
| サンプルトークン | 1000あたり$0.06 | |
| GPT-4-0314 | プロンプトトークン | 1000あたり$0.03 |
| サンプルトークン | 1000あたり$0.06 | |
| GPT-4-32K | プロンプトトークン | 1000あたり$0.06 |
| サンプルトークン | 1000あたり$0.12 | |
| GPT-4-32K-0314 | プロンプトトークン | 1000あたり$0.06 |
| サンプルトークン | 1000あたり$0.12 | |
| Whisper large-V2 モデル | 1分あたり0.006ドル |
まとめ
いかがでしょうか?このブログでは、OpenAIが開発したChatGPT APIとWhisperを活用して、音声ファイルの自動要約方法を紹介しました。Whisperを使うことで、多言語の音声ファイルを文字起こしし、その後ChatGPTを使って、インタビューや議事録などのテキスト文章を簡単かつ迅速に要約することができます。
ただし、Whisperの実験情報からわかるように、低いスペックなマシンではモデルサイズやサーバー立ち上がる時間、自動要約時間などの課題が残されています。特に、大規模な音声ファイルを短期間で処理するためには、有料版のAPIを使うか、もしくはGPUカード搭載サーバーでの実行が必要であると思います。
今後は、この自動要約の機能をさらに便利なGUIに加えて、Slackなどのコラボレーションツールに組み込んで、議事録の作成作業を一層自動化することが期待できるのではないでしょうか?
宣伝
グループ研究開発本部の次世代システム研究室では、最新のテクノロジーを調査・検証しながらインターネットのいろんなアプリケーションの開発を行うアーキテクトを募集しています。募集職種一覧 からご応募をお待ちしています。

ブログの著者欄
グループ研究開発本部
GMOインターネットグループ株式会社
グループ研究開発本部とは、GMOインターネットグループの事業領域で力を入れているスタートアップやグループ横断のプロジェクトにおいて、技術支援・開発・解析などを行い、ビジネスの成功を支援する部署です。 最新のテクノロジーを研究開発し、いち早くビジネスに投入することで、お客様の発展と成功に貢献することを主要なミッションとしています。
採用情報


関連記事
-

【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-

ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

【イベントレポート・後編】GMO Developers Day 2025 -Creators Night-|共創するデザイン組織と次世代クリエイターの可能性
デザイン
-

【イベントレポート・中編】GMO Developers Day 2025 -Creators Night-|変化に挑むクリエイターのキャリアと成長
デザイン
-

【イベントレポート・前編】GMO Developers Day 2025 -Creators Night-|AI時代の「クリエイティブ」を探る夜
デザイン
-

【イベントレポート】社内から未来を体験する-「ロボ触ろうぜ!」
技術情報

KEYWORD
CATEGORY
-
技術情報(573)
-
イベント(217)
-
カルチャー(55)
-
デザイン(58)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- GPU
- GPUクラウド
- GTB
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP




採用情報
SNS FOLLOW
