
本記事はGMOインターネットグループで複数ある開発者ブログのなかから人気の記事をピックアップして再掲載しています。機械学習や深層学習のビジネス応用を研究、社会実装をしているグループ研究開発本部 AI研究開発室のデータサイエンティストが寄稿した人気記事です。
目次
ChatGPT に追加でデータを与える課題へのアプローチ
Llamaindex で ChatGPT と連携した社内文書の QA ツールを構築した際にハマったことを書いていきます。
ChatGPT は非常に有用ですが、知っている情報が古いという問題があります。
また社内の独自データは当然ですが学習されておらず回答に含めることができません。
この解決策として、外部から新しいデータを与えて回答を生成したいときは以下の方法があります。
- Fine-tuning
- In-Context Learning
Fine-tuning はモデル自体にデータを与えて再学習させる方法です。
回答精度も高く良い手法なのですが、2023年4月現在では推論精度の高い GPT3.5、GPT4 に対応しておらず davinci 等の GPT3 を使う必要があり、かつ API 利用料も通常の回答生成より高めのため、私は個人的に「もうちょっと待ってからやろうかな」と思っています。
In-Context Learning のほうはチャット文脈に情報を付与することでその会話の文脈の中で回答が可能になる手法です。
Fine-tuning よりも弱い点としては一連のチャット文脈で送れる情報に限定されるとうところです。
こちらは API の gpt-3.5-turbo を使ってお手軽に実装できるので、簡単なQAなどの要件であれば充分な成果が狙えると考えました。
今回やりたいこと
社内文書のデータを ChatGPT と連携した QA ツールを構築したいです。
In-Context Learningを用いた ChatGPT QA ツールのコアの部分はLangChainやLlamaindexを使って Python 数行で実装できます。
ただ作り始めて感じた疑問は、まともな回答が得られない場合、どのような点をチューニングできるのかということでした。
今回はここをQAシステムを開発しながら、改善できた点をいくつか紹介します。
結論ファースト
・Llamaindex はベクター検索を行ってから ChatGPT の API を実行するので、ベクター検索のデータの塊(チャンク)を整理して検索オプションパラメータを設定するとよい。
つくったもの
まず今回の検証のベースとなるアプリケーションは、弊社 VPS サービス Conoha の API についてのドキュメントに基づいて回答する ChatGPT です。
※Conoha API はインターネット上に公開されている情報なので、疑似的な課題設定です。実際のシステムは別のAPI仕様書を読み込ませています。
システム構成
ひとまず Python の Jupyter Notebook でコアな部分を構築しました。
以下のライブラリに依存しています。
Llamaindex
0.5.11
LLM の In-Context Learning をさらっと実装できるフレームワークです。
公式ドキュメント
https://gpt-index.readthedocs.io/en/latest/index.html
GitHub
https://github.com/jerryjliu/llama_index
LangChain
0.0.135
Llamaindex をはじめとしたツール群を OpenAI API を連携できるフレームワークです。他にも Google 検索と連携したりいろいろできるのでむしろこれが今後の潮流を生み出しそうな気がします。
公式ドキュメント
https://docs.langchain.com/docs/
GitHub
https://github.com/hwchase17/langchain
Faiss
faiss_cpu-1.7.3
Facebookが開発したベクター検索ライブラリ。意味が近い文書を検索できます。ベクトル検索とか近傍探索という人もいます。距離計算をあらわす距離計算は L2 、コサイン類似度、ボロノイ領域 IndexIVFFlat を利用できます。検索対象データはローカルにファイルとして保存しています。GPU版とCPU版があり特にボロノイ領域の検索は高速なはず。
OpenAI API
0.27.4
ChatGPT の API が簡単に実行できる公式ライブラリです。
将来的にはWebブラウザやSlackをインターフェースとして作り込むことを想定していますが、まだJupyter Notebookで動かしているだけなので、その範囲に限定して解説していきます。
ライブラリのインストールはさっとやってしまうとこんな感じです。
!pip install -U langchain !pip install -U openai !pip install -U llama-index !pip install -U faiss-cpu
各ライブラリの入門的な内容は他にもいい記事がたくさんあるので今回は割愛させてください。
ユースケース
Conoha の Image 一覧を取る API に関する情報を gpt-3.5-turbo に問い合わせます。
Conoha API の情報は10種類ほどローカルでベクター検索できるようになっています。
Python でベクター検索して関連文書とともに gpt-3.5-turbo に API で質問をして回答を表示します。
はじめに書いたソースコード
元ネタとなる API の定義情報は以下のURLのものを出力してローカルでテキストファイルにしてあります。
https://www.conoha.jp/docs/image-get_images_list.php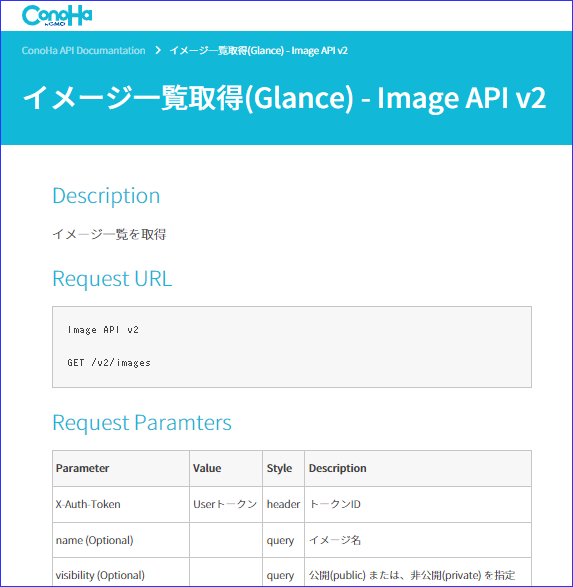
Python です。
os.environ["OPENAI_API_KEY"] = "XXXXXXXXXXXXXXX"
from llama_index import SimpleDirectoryReader, ServiceContext, GPTSimpleVectorIndex, LLMPredictor
from langchain.chat_models import ChatOpenAI
#data dirからテキストファイルの情報を取得
documents = SimpleDirectoryReader('data_conoha_api').load_data()
# gpt-3.5-turbo を指定(現状デフォルトは davinci )
service_context = ServiceContext.from_defaults(llm_predictor = LLMPredictor(llm= ChatOpenAI( model_name="gpt-3.5-turbo"))
# documents をもとに Embbeddings API を通信してベクター取得し GPTSimpleVectorIndex を生成
index = GPTSimpleVectorIndex.from_documents(documents, service_context=service_context)
# save to disk
index_json = 'index_conoha_api.json'
index.save_to_disk(index_json)
# プロンプト
qry =" Conoha Imageの一覧を取るAPI のリクエストメソッド、URL、ヘッダー、リクエストボディ、をCURLの例とともに教えてください。RESの例も教えてください。 ?"
# ベクター検索 + Chat Completion API 実行
response=index.query(qry)
print(response)
プロンプトはこちらです。
” Conoha Imageの一覧を取るAPI のリクエストメソッド、URL、ヘッダー、リクエストボディ、をCURLの例とともに教えてください。RESの例も教えてください。 ?”
実行すると最終的に以下のような結果が得られました。
リクエストメソッドはGET、URLは/v2/images、ヘッダーにはX-Auth-Tokenが必要で、トークンIDが値として渡されます。リクエストボディはありません。CURLの例は以下の通りです。
REQ
curl -i -X GET \
-H "Accept: application/json" \
-H "X-Auth-Token: 35941e7df872405d84e5b026dba8323c" \
https://image-service.tyo1.conoha.io/v2/images
RESの例は以下の通りです。
HTTP/1.1 200 OK
Date: Tue, 09 Dec 2014 10:17:20 GMT
Server: Apache
Content-Length: 6102
Content-Type: application/json
{
"images": [
{
"status": "active",
"name": "testsnap",
(以下、とても長いので省略します)
はじめにしてはだいぶよい感じなので、同じ原理で社内の文書を適用すればあらゆるものが gpt-3.5-turbo に QA させたり要約させることができる見込みが立ちました。
Llamaindex 処理フロー
Llamaindex の中の処理が何をやっているのかもう少し説明しておきます。
処理順序はログで出してみるとどんなことをやっているかすぐにわかりました。
ベクターストアの構築処理
1 元ネタの文書のテキストファイルをローカルフォルダに入れておく。そのフォルダからdocumentオブジェクトを取得する。(Web上のURLでもよい)
2 OpenAI の Embeddings API で元ネタ文書をベクター化し Index 作成。
3 ローカルの専用ファイルとしてベクターを保存する。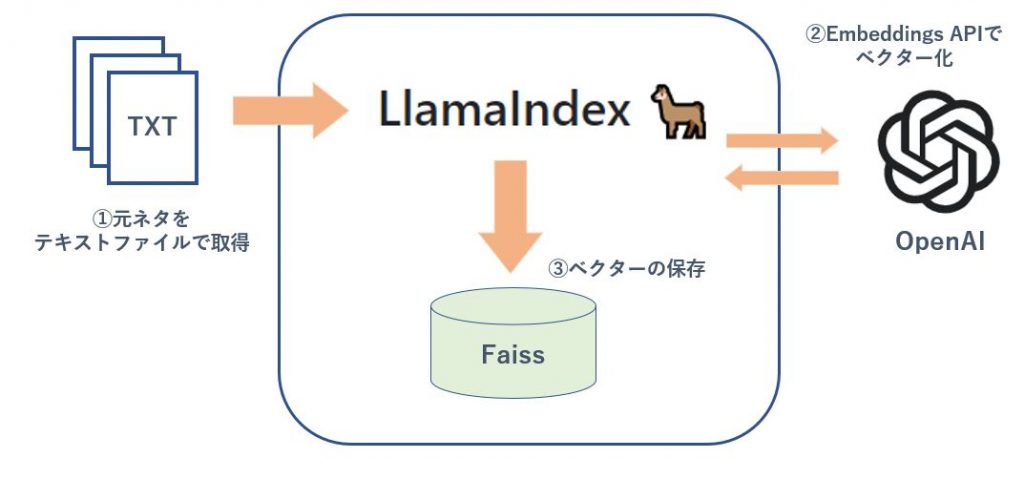
質問回答の処理
1 「質問文」を受け取る。
2 「質問文」を OpenAI の Embeddings API でベクター化。
3 「質問文」のベクターでローカルファイルへベクター検索して、類似性が高い文章をいくつか取得。
4 「質問文」と「類似性が高い文書」を一緒にプロンプトにまとめて OpenAI API で gpt-3.5-turbo に質問(Chat Completion API 実行)。
5 「質問文」と「1回目の回答」と「類似性が高い文書その2」を一緒にプロンプトにまとめて OpenAI API で gpt-3.5-turbo に質問(Chat Completion API 実行)(Refine処理)。
⇒ 類似性の高い文書があるだけ Refine 処理を繰り返す。
6 最終回答を表示。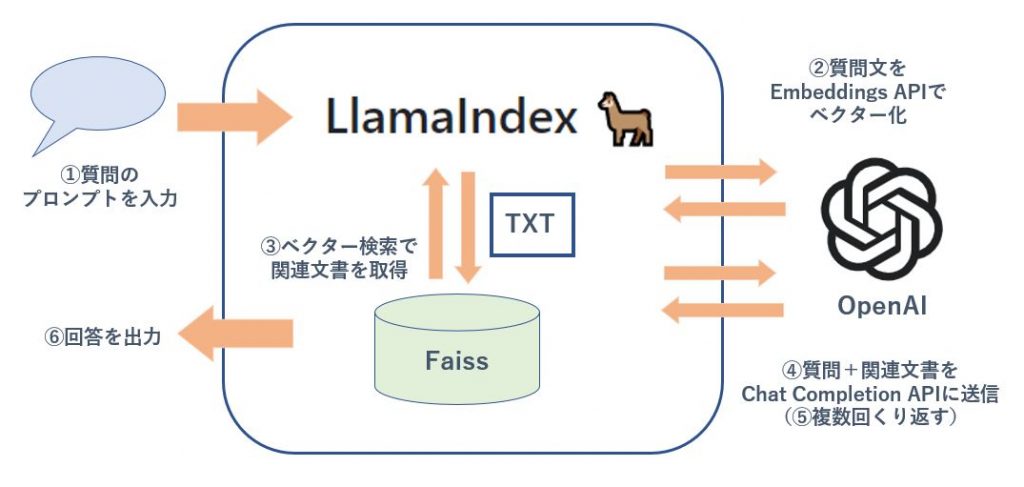
処理とリクエストを見ると、ローカルでベクター検索でひっかけてきた元ネタ文章の塊をそっくりプロンプトに入れてAPIのリクエストで渡しているだけというとても原始的な仕組みになっています。
ChatGPT の画面と同様に Chat Completion API で1回のプロンプトに含められる情報には上限があります。これが Llamaindex の In-Context Learning の限界です。そのため情報の塊をどのように整理するかがちゃんとした回答を得られるかの重要なキーになってきます。
Llamaindex チューニング課題
ここからが本題です。
以下のような構成になっています。
本質的な課題
元ネタのテキストファイルをベクター検索のチャンクに収まるように意味の塊にする
個別の改善課題
1 ベクター検索の2番目のドキュメントが正解だったりする問題
2 複数のドキュメントを読ませると間違える確率が上がる問題
3 失敗している理由がよくわからない問題
4 ときおり英語で返してくる問題
5 OpenAI API がタイムアウトする問題
将来役に立ちそうなTips
ローカルファイルを小さくしたい
回答をもっと厳密にしたい
本質的な課題 元ネタのテキストファイルをベクター検索のチャンクに収まるように意味の塊にする
いい回答を得るためには、プロンプトに何を含めるかが最重要課題です。
元ネタのテキストファイルをベクター検索の1つの塊(チャンク)に収まるように意味の塊にすることで、正しいプロンプトを生成できるようになります。
Llamaindex における塊(チャンク)は元ネタのテキストファイルから GPTSimpleVectorIndex や GPTFaissIndex の document オブジェクト生成時に自動で生成されます。
ログを読む限り1チャンクのサイズは以下のように見受けられました。
・元ネタの 1 txt ファイル = 1 チャンクで作られていた
・10kbを超えるファイルはチャンクが分割された
Llamaindex ではベクター検索にヒットしたドキュメントが1つの塊(チャンク)で取得され gpt-3.5-turbo に丸ごと送られます。(下の「課題4 ときおり英語で返してくる問題」で内部のプロンプトの詳細を説明します。)
丁度いいサイズにしておくことで Chat Completion API リクエストに余計な情報を入れなくて済むメリットがあると思っています。
一方、極端に小型化すると一気に多くの情報を送れず ChatGPT が充分なレスポンスを作れないというデメリットがあり、トレードオフの関係にあります。
ほしい回答をしてもらうためには、この塊(チャンク)をいい感じにすることが本質的に重要になります。
現段階でもっともシンプルに実現するためには、もともとのtxtファイルを「意味」の塊で分割してつくっておくことが必要です。
(例えば1つのAPIについてのテキスト情報が10Kを超える場合、リクエストパラメータの解説で1つのテキストファイル、レスポンスパラメータで1つのテキストファイルとする)
そして必要な情報がChatGPTに渡らない場合、テキストファイルを意味のまとまりで作り変えてチャンクを再生成するという工夫が求められると思います。
個別の改善課題を以下で紹介します。
課題1 ベクター検索の2番目のドキュメントが正解だったりする問題
ベクター検索では人間からの質問文とコサイン類似度が近いと判定された文章がレスポンスされてきます。
よくある事象として、ベクター検索の結果の2番目のドキュメントが欲しい情報だったりすることがあります。(これはGoogle検索などでもよく見かけるケースだと思います)
しかし Llamaindex はデフォルトではベクター検索結果の1番目のドキュメントだけを対象にして gpt-3.5-turbo に問い合わせ処理をするため、いきなりまともな回答が得られないという事態が発生します。
実例を見ていきましょう。
Conoha の VM イメージの一覧を取得する API についての質問をプロンプトに入れます。
qry =" Conoha Imageの一覧を取るAPI のリクエストメソッド、URL、ヘッダー、リクエストボディ、を Curl の例とともに教えてください。レスポンスの例も教えてください。 ?"
qry =" Conoha Imageの一覧を取るAPI のリクエストメソッド、URL、ヘッダー、リクエストボディ、を Curl の例とともに教えてください。レスポンスの例も教えてください。 ?"
現状ベクターストアには「トークン発行」、「イメージ一覧取得」、「請求データ一覧取得」など10種類のAPIドキュメントが格納されています。
この質問のベクター検索でひっかかったドキュメントはどういうわけか「トークン発行」でした。
DEBUG:llama_index.indices.utils:> Top 1 nodes: > [Node 2] [Similarity score: 0.812943] Conoha API トークン発行 - Identity API v2.0
当然 gpt-3.5-turbo に問い合わせるとこんなレスポンスが来ます。
DEBUG:llama_index.indices.response.builder:> Initial response:
何かのワードが誤検知されてしまうとこういった検索結果の汚染が発生します。
similarity_top_k
解決方法として query 時のパラメータ similarity_top_k を指定します。
# ベクター検索 + Chat Completion API 実行
similarity_top_k は類似文書をベクター検索した際に上位何件まで返しますかという設定です。複数のドキュメントをヒットさせることができると Llamaindex は繰り返し処理をするため正解の文書を読む確率が上がるわけです。
しかしこれによってまた次の問題が発生します。
課題2 複数のドキュメントを読ませると間違える確率が上がる問題
複数の文書をもとにして回答生成をするとノイズになってしまい、結果として変な回答が出ることがあります。
再び実例を見ていきましょう。
上記のイメージ一覧取得APIの質問からベクター検索でひっかかったドキュメントは以下の3つでした。
1つ目が「トークン発行」
2つ目が「イメージ一覧取得」
3つ目が「請求データ一覧取得」
DEBUG:llama_index.indices.utils:> Top 3 nodes: > [Node 2] [Similarity score: 0.812943] Conoha API トークン発行 - Identity API v2.0 > [Node 4] [Similarity score: 0.807114] イメージ一覧取得(Glance) - Image API v2 > [Node 3] [Similarity score: 0.78922] 請求データ一覧取得 - Account(Billing) API v1
2つ目が正解なのですが、3つ取得してしまうことで処理的に非常に効率が悪い状況が発生します。
1 まず質問と1つ目の情報をくっつけたのプロンプトを飛ばします。
2 質問と1つ目のレスポンスと2つ目の情報をくっつけて次のプロンプトを飛ばします。
3 質問と2つ目のレスポンスと3つ目の情報をくっつけて次のプロンプトを飛ばします。
これが Llamaindex の Refine と呼ばれる回答精査処理なのですが、仮に 2 で正解していても 3 が入ることでノイズになってしまい gpt-3.5-turbo が変なことを言い出すことがあります。
(それに3回のやりとりは API の token を結構消費してしまうので、コスト的にもあまりよくありません。)
required_keywords
この解決のためには検索結果からノイズの除去が必要です。
パラメータで検索時の必須キーワードと除外キーワードの設定を行うことでノイズ除去ができます。
例えば上記の問題の場合「イメージ」という単語を絶対に含んでいますということ指定します。
key_str="イメージ" exc_str="" # ベクター検索 + Chat Completion API 実行 response=index.query(qry, similarity_top_k=3, required_keywords=[key_str], exclude_keywords=[exc_str] )
こうすることで正確な情報を伝達できるようになり、回答が改善できます。
(jupyterなのでべた書きで実行してしまっていますが、画面からプロンプトで受け取るときはフォーマットを決めてプログラム上で加工などをする必要があります。)
similarity_top_k で3つの文書を取得することはメリットもデメリットもあるので、required_keywords を活用する工夫で改善することができます。
課題3 失敗している理由がよくわからない問題
以上のような問題はただ実行しているだけだと全く分析できません。
ちゃんと元ネタのドキュメントに答えが書いてあるのに、なんで読み込めないんだ!とイライラが募るのでログを出してやりましょう。
import logging # ログレベルの設定 logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)
当たり前なんですがログを出すと結構な情報がわかります。
- OpenAI API の実行回数
- OpenAI API の処理時間
- OpenAI API に送った Token 数
- ベクター検索に引っかかったドキュメントのコサイン類似度
response.get_formatted_sources()
もうひとつ。
gpt-3.5-turbo が回答を生成したときに一緒に送ったドキュメントを出力する機能があります。
response.get_formatted_sources()
たとえば上記の例で3つのドキュメントが参照されたのはこちらのように出力されました。
> Source (Doc id: 25f2390e-7068-4331-b5b2-312754ed49a8): Conoha API トークン発行 - Identity API v2.0 Description 有効なトークン情報を取得する Request URL identity API v2.0... > Source (Doc id: db57709a-25b4-4272-8bf1-23993ab04d63): イメージ一覧取得(Glance) - Image API v2 Description イメージ一覧を取得 Request URL Image 一覧API v2 GET /v2/im... > Source (Doc id: 95011a8f-a0ae-46b8-b181-5dcb8c26423f): 請求データ一覧取得 - Account(Billing) API v1 Description 課金アイテムへの請求データ一覧を取得します。 Request URL billing API ...
これでソースとなっているインデックスの文章を確認できます。
required_keywordsが適用された後の結果が出るので、その効果検証も可能です。
もし変なものが参照されてしまっているのであれば、元ネタの文章を書き直したり必須キーワードを修正したりすることで検索制度を改善できる可能性があります。
課題4 ときおり英語で返してくる問題
処理の中では初回の質問チャットと、回答に別情報を付与して精査するRefineのチャットの2回が行われます。
そこでなぜか突然 API から英語でレスポンスがかえってくることがあります。
この原因は初回QAのプロンプト、 次の精査プロンプトがデフォルトで英語で書かれているためです。
対処法として、質問文に「日本語で返してください」と追記するのが手っ取り早い方法です。
それでもデフォルトの英語が残っていると gpt-3.5-turbo はこの文脈では英語をつかっていいんだなと解釈してしまうことがあるので、サービス的に完全に除去したい場合はデフォルトのプロンプト自体を日本語に修正することが確実な方法です。
from llama_index.prompts.prompts import RefinePrompt, QuestionAnswerPrompt
QA_PROMPT_TMPL = (
"私たちは以下の情報をコンテキスト情報として与えます。 \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"あなたはAIとして、この情報をもとに質問を日本語で答えます。前回と同じ回答の場合は同じ回答を行います。: {query_str}\n"
)
qa_prompt = QuestionAnswerPrompt(QA_PROMPT_TMPL)
REFINE_PROMPT = ("元の質問は次のとおりです: {query_str} \n"
"既存の回答を提供しました: {existing_answer} \n"
"既存の答えを洗練する機会があります \n"
"(必要な場合のみ)以下にコンテキストを追加します。 \n"
"------------\n"
"{context_msg}\n"
"------------\n"
"新しいコンテキストを考慮して、元の答えをより良く洗練して質問に答えてください。\n"
"コンテキストが役に立たない場合は、元の回答と同じものを返します。")
refine_prompt = RefinePrompt(REFINE_PROMPT)
# ベクター検索 + Chat Completion API 実行
response=index.query(qry,
text_qa_template=qa_prompt,
refine_template=refine_prompt,
similarity_top_k=3,
required_keywords=[key_str]
)
日本語のほうがtokenが多くなるので API 利用コストが上がってしまうという点だけご留意ください。
公式にも記載がありました。
https://gpt-index.readthedocs.io/en/latest/how_to/customization/custom_prompts.html
課題5 OpenAI API がタイムアウトする問題
APIから長いレスポンスが来る場合非常に重くなりますが、デフォルト60秒でタイムアウトします。
ぜんぜんレスが返ってこない場合は request_timeout=120 などとしてやりましょう。
from langchain.chat_models import ChatOpenAI from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler from llama_index import LLMPredictor,ServiceContext llm=ChatOpenAI( request_timeout=120, #streaming =True, #callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]), model_name="gpt-3.5-turbo") llm_predictor = LLMPredictor(llm=llm) service_context = ServiceContext.from_defaults(llm_predictor = llm_predictor)
streaming が動けばよかったのですがうまくいきませんでした。どうやらライブラリの実装が移行期のようで、マニュアル通りやってもソースコードと整合性があっていないように感じました。
ここまでで今回のアプリケーションで具体的に役に立った部分を説明しました。
ここからは将来的に役に立ちそうなチューニング箇所を書いていきます。
Tips1 ローカルファイルを小さくしたい
ローカルのファイルを読んでいるだけなのではじめに利用した SimpleVectorStore でも充分に早いですが、Llamaindex では Faissという Facebook が開発したベクター検索ライブラリが使えます。
こちらは GPU も対応しており、とにかく早いことがウリです。(今回サイズが大きなものが用意できず検索速度の比較数値を出せないのが悔やまれる)
また Faiss を使うとファイル容量が SimpleVectorStore の3分の1になったので、将来的に大規模化することを想定するとメリットになるだろうと考えています。
検索用 index オブジェクトの生成を丸ごと置き換えてやります。
GPT SimpleVectorStore 同様に GPTFaissIndex でもコサイン類似度を利用したコードで書いています。
# Faiss 連携 import faiss from llama_index import GPTFaissIndex # dimensions of text-ada-embedding-002 d = 1536 # コサイン類似度 faiss_index = faiss.IndexFlatIP(d) # APIを実行しFaissのベクター検索ができるようにする index = GPTFaissIndex.from_documents(documents, faiss_index=faiss_index, service_context=service_context ) # save index to disk index.save_to_disk( 'index_faiss.json', faiss_index_save_path="index_faiss_core.index" )
他にもベクター検索のエンジンは複数対応しているようでした。
- Postgres
https://gpt-index.readthedocs.io/en/latest/guides/tutorials/sql_guide.html - Pinecone
https://github.com/jerryjliu/llama_index/tree/66db86d2e875fb47384a77a0469bc6c6f45c866e/examples/data_connectors
Tips2 回答をもっと厳密にしたい
temparetureパラメータで回答の多様性を指定できます。
デフォルトは0.7のようですが変なことを言いすぎるときはここを減らしてください。
Web 上のサンプルコードではみなさん tempareture = 0 をしていて、正確性を最重視する設定になっています。
# ベクター検索 + Chat Completion API 実行 response=index.query(qry, tempareture = 0, text_qa_template=qa_prompt, refine_template=refine_prompt, similarity_top_k=3, required_keywords=[key_str] )
未解決:元ネタのドキュメントがどのように Embeddings API に送られているか
ここは最後までよくわからなかったところです。
ベクター検索につかうデータを生成するとき、 text-embeddings-ada-002 モデルを利用すると最大token数は8192が制限になります。
ただ、DEBUGログでは14000tokensも送っていたのでパッと見でオーバーしています。
元ネタのテキストを小分けのファイルにしたりしてみたのですがが、分割した後でもDEBUGログ上でAPIの実行回数が1回でした。
これは上限にひっかからないの?実は失敗しているの?と思いながら結局よくわかりませんでした。
感想
In-Context Learning が非常に簡単に使えて楽しかったです。
ただ簡単ゆえに、どちらかといえばベクター検索精度の問題になってしまったため、使い道は QA のような短答問題に絞られるかなあと思っています。
やっぱり Fine-tuning をがっつりやるのが本番になるのではないでしょうか。
ただ llama_index-0.5.11 とか langchain-0.0.135 とか、こんな出来立ての OSS をまじめに検証するもんじゃないですね。
あまりにホットすぎて2週間ぐらいでバージョンがどんどん変わります。
その都度引数が変わってやり直しの憂き目にあいました。
もう少し安定しないと実践投入は悩むところ。
最後に宣伝です!
グループ研究開発本部の次世代システム研究室では、最新のテクノロジーを調査・検証しながらインターネットの新規サービスの開発を行うエンジニアを募集しています。募集職種一覧 からご応募をお待ちしています。

ブログの著者欄
グループ研究開発本部
GMOインターネットグループ株式会社
グループ研究開発本部とは、GMOインターネットグループの事業領域で力を入れているスタートアップやグループ横断のプロジェクトにおいて、技術支援・開発・解析などを行い、ビジネスの成功を支援する部署です。 最新のテクノロジーを研究開発し、いち早くビジネスに投入することで、お客様の発展と成功に貢献することを主要なミッションとしています。
採用情報

関連記事
-

【中編】Hack-1グランプリ2026 デモデーレポート|ついにグランプリ決定!最優秀賞チームに開発秘話を聞く
デザイン
-

【前編】Hack-1グランプリ2026 デモデーレポート|AI時代の学生ハッカソンに圧倒される2日間。「小さくなる日本」をどう表現する?
デザイン
-

【インタビュー後編】育休明けに直面した「AI時代」 GMOペパボのプリンシパルデザイナー・佐藤咲が歩む「共創」の道
デザイン
-

【後編】エージェンティックAIの「アウトプット品質安定化」を実現 GMOインターネットが実践する「ハーネスエンジニアリング」とは?ーEngineering Journey
技術情報
-

ハーネスエンジニアリングの本質 ー従来の開発規律を、エージェントが回せるように再設計する
技術情報
-

【前編】エージェンティックAIの「アウトプット品質安定化」を実現 GMOインターネットが実践する「ハーネスエンジニアリング」とは?ーEngineering Journey
技術情報

KEYWORD
CATEGORY
-
技術情報(590)
-
イベント(235)
-
カルチャー(59)
-
デザイン(67)
TAG
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI TALK
- AI 機械学習強化学習
- AI/機械学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI活用事例
- AI駆動
- AMD
- APT攻撃
- AWX
- Behind the Scenes
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- ConoHaVPS
- CS
- CSS
- CTF
- DC
- Designship
- Desiner
- developer
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- engineering
- Engineering Journey
- eVTOL
- expert
- EXPERT CROSS
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOインターネットグループ陸上部 – GMOロボッツ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- Good Morning
- GPU
- GPUクラウド
- GTB
- Hack-1グランプリ
- Hack‐1グランプリ
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- Japan Drone
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- エージェンティックAI
- オブジェクト指向
- オンボーディング
- お名前.com
- クリエイター
- クリエイターインタビュー
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ハーネスエンジニアリング
- バックエンド
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- フロントエンド
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- ロボティクス
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 技術書典20
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 映像制作
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 空飛ぶクルマ
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-

【後編】デザイナーとしての自分を形作る「気合と反復」。対話を通じて実践する、豊田恵二郎の制作哲学
デザイン
-

【前編】創業時から変わらない「一貫性」で業界をリード GMO Flatt Security CCO・豊田恵二郎が語る、「エンジニアの背中を預かる」姿勢
デザイン
-

【第2回・AI TALK】GMOサイバーセキュリティ byイエラエ・三村 聡志さんに聞く、AI時代の攻撃と防御のいま
技術情報
-
【中編】Hack-1グランプリ2026 デモデーレポート|ついにグランプリ決定!最優秀賞チームに開発秘話を聞く
デザイン
-
【前編】Hack-1グランプリ2026 デモデーレポート|AI時代の学生ハッカソンに圧倒される2日間。「小さくなる日本」をどう表現する?
デザイン
-

【Expert Cross #1】“人生2周目”のエキスパートが挑む、「つながり」の構築と認知拡大
技術情報
採用情報

SNS FOLLOW
