
本記事はGMOインターネットグループで複数ある開発者ブログのなかから人気の記事をピックアップして再掲載しています。機械学習や深層学習のビジネス応用を研究、社会実装をしているグループ研究開発本部 AI研究開発室のデータサイエンティストが寄稿した人気記事です。
今回は最近話題になっている、確率モデル+深層ニューラルネットワーク(統合モデル)の一つのdiffusionモデルについて紹介したいと思います。
目次
はじめに
すでに、ご存知の方が多いかもしれませんが、最近話題になっている生成用の機械学習モデル、Stable DiffusionやDall-Eなど、性能が高い生成アルゴリズムやシステムにDiffusionモデルというコンセプトが採用されています。生成モデルとモデルといえば、最初に一番良く知られているのはGAN(Generative Adversarial Network)ですが、その後、他の有名な手法Variational Auto Encoder(VAE)も出てきました。Diffusion modelはVAEと同じく、確率グラフィカルモデル(Probabilistic Graphical Model)と深層ニューラルネットワークの技術を組み合わせをし、hybrid modelの一つです。また、VAEとdiffusion modelは以下の部分が似いていて、diffusion modelはVAEの発展形のモデルとしてよく言われています。
- 生成プロセスは学習した分布から潜在変数をsamplingし、ニューラルネットワーク上に変化させ、という生成プロセス
- モデルのloss関数の計算方法はにいています(Variational Inference, Reparameterization Tricksなど)
Diffusion modelについて
Diffusion Modelとは一言いうと、まず少しずつもの壊して、その壊れた状態から復元するというコンセプトです。具体的に、オリジナルデータに対して、各ステップ tに対して、少しずつGaussian Noiseを入れて(Forward process)、T ステップまで行います。Tは大きいければ、最終的にXTは完全にgausian 分布になり、そこから、少しずつnoiseを取り除いて、もとの画像を戻すという学習を行います。
Forward Process:
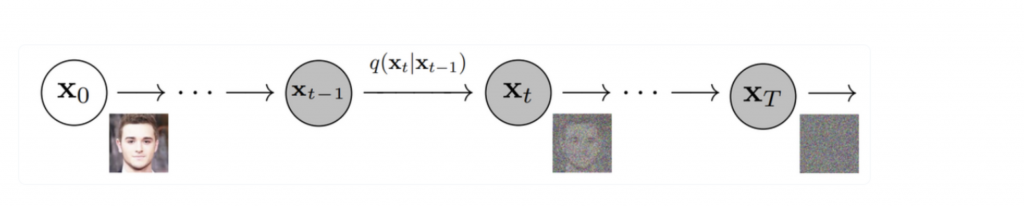
Reverse Process:

Forward processは基本的にgaussian分布からnoiseを適用し、そして、Reverse processsで、少しずつ加えたnoiseを取り除いてい、各ステップで、元のデータを戻すパラメータを学習する。学習が完了すれば、完全なrandom noiseから、データ生成することができます。
次は各重要な部分をかんたんにに詳しい内容とコードを説明します。
今回は基本的に以下のsampleコードをベースにかんたんにし
https://keras.io/examples/generative/ddim/
元の論文:
DENOISING DIFFUSION IMPLICIT MODELS(J.Song, et.al 2020)
https://arxiv.org/pdf/2010.02502.pdf
いくつか元の論文や実装が異なる部分がありますが、基本的にコンセプトや処理のアイデアは同じで、実装のときの入門としてはわかりやすいと思います。
Forward Process
元のデータ(x0)は少しいずつGausian Noiseを加えて、最終的にXTにするのは基本的に以下の式で、定義されます。
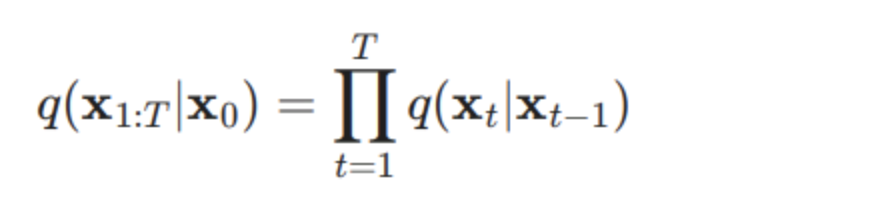
tのときにxの値(xt)は基本的に前のt-1の値に依存します。t-1の値から、以下の式でgaussian noiseに加えます。
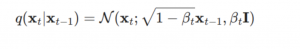
上記の式は各ステップのβが違う値として、設定必要です。基本的に、各ステップで、βの値が徐々に大きなれば良いですが、普通のdiffusionモデルではβの値はモデルで学習させることが多いですが、参考した実装のコードは以下の関数として定義されます。なので、tの値によって、すぐに計算できて、推論時に、自由にstepのサイスや値を変更できます。
def sinusoidal_embedding(x):
embedding_min_frequency = 1.0
frequencies = tf.exp(
tf.linspace(
tf.math.log(embedding_min_frequency),
tf.math.log(embedding_max_frequency),
embedding_dims // 2,
)
)
angular_speeds = 2.0 * math.pi * frequencies
embeddings = tf.concat(
[tf.sin(angular_speeds * x), tf.cos(angular_speeds * x)], axis=3
)
return embeddingsdef get_network(image_size, widths, block_depth):
noisy_images = keras.Input(shape=(image_size, image_size, 3))
noise_variances = keras.Input(shape=(1, 1, 1))
e = layers.Lambda(sinusoidal_embedding)(noise_variances)
.....そして、Forward processはかんたんに、元のデータに、計算したnoiseに追加するだけです。このおかげで、stepごとのnoiseパラメータが学習が不要になり、全体のアーキテクチャがシンプルになります。
#sample uniform random diffusion times
diffusion_times = tf.random.uniform(
shape=(batch_size, 1, 1, 1), minval=0.0, maxval=1.0
)
noise_rates, signal_rates = self.diffusion_schedule(diffusion_times)
# mix the images with noises accordingly
noisy_images = signal_rates * images + noise_rates * noisesReverse Process
Reverse Processは元の論文はかなり複雑ですが、今回のsampleコードではかなりsimpleになり、基本的にnoiseが加えたデータに対して、作成したネットワーク構造で、逆予測し、予測データ(画像)と予測noiseを分解し、徐々に元のデータと近づくような処理を行います。
with tf.GradientTape() as tape:
# train the network to separate noisy images to their components
pred_noises, pred_images = self.denoise(
noisy_images, noise_rates, signal_rates, training=True
)
noise_loss = self.loss(noises, pred_noises) # used for training
image_loss = self.loss(images, pred_images) # only used as metric
gradients = tape.gradient(noise_loss, self.network.trainable_weights)
self.optimizer.apply_gradients(zip(gradients, self.network.trainable_weights))
self.noise_loss_tracker.update_state(noise_loss)
self.image_loss_tracker.update_state(image_loss)def denoise(self, noisy_images, noise_rates, signal_rates, training):
# the exponential moving average weights are used at evaluation
if training:
network = self.network
else:
network = self.ema_network
# predict noise component and calculate the image component using it
pred_noises = network([noisy_images, noise_rates**2], training=training)
pred_images = (noisy_images - noise_rates * pred_noises) / signal_rates
return pred_noises, pred_images画像生成の例
基本的に、画像生成するコードは生成できます。
def diffusion_schedule(diffusion_times, min_signal_rate, max_signal_rate):
start_angle = tf.acos(max_signal_rate)
end_angle = tf.acos(min_signal_rate)
diffusion_angles = start_angle + diffusion_times * (end_angle - start_angle)
signal_rates = tf.cos(diffusion_angles)
noise_rates = tf.sin(diffusion_angles)
return noise_rates, signal_rates
def generate_images(diffusion_steps, stochasticity, min_signal_rate, max_signal_rate):
step_size = 1.0 / diffusion_steps
initial_noise = tf.random.normal(shape=(num_images, image_size, image_size, 3))
# reverse diffusion
noisy_images = initial_noise
for step in range(diffusion_steps):
diffusion_times = tf.ones((num_images, 1, 1, 1)) - step * step_size
next_diffusion_times = diffusion_times - step_size
noise_rates, signal_rates = diffusion_schedule(diffusion_times, min_signal_rate, max_signal_rate)
next_noise_rates, next_signal_rates = diffusion_schedule(next_diffusion_times, min_signal_rate, max_signal_rate)
sample_noises = tf.random.normal(shape=(num_images, image_size, image_size, 3))
sample_noise_rates = stochasticity * (1.0 - (signal_rates / next_signal_rates) ** 2) ** 0.5 * (
next_noise_rates / noise_rates)
pred_noises, pred_images = model([noisy_images, noise_rates, signal_rates])
noisy_images = (
next_signal_rates * pred_images
+ (next_noise_rates ** 2 - sample_noise_rates ** 2) ** 0.5 * pred_noises
+ sample_noise_rates * sample_noises
)
# denormalize
data_mean = tf.constant([[[[0.4705, 0.3943, 0.3033]]]])
data_std_dev = tf.constant([[[[0.2892, 0.2364, 0.2680]]]])
generated_images = data_mean + pred_images * data_std_dev
generated_images = tf.clip_by_value(generated_images, 0.0, 1.0)
# make grid
generated_images = tf.image.resize(generated_images, (plot_image_size, plot_image_size), method="nearest")
generated_images = tf.reshape(generated_images, (num_rows, num_cols, plot_image_size, plot_image_size, 3))
generated_images = tf.transpose(generated_images, (0, 2, 1, 3, 4))
generated_images = tf.reshape(generated_images, (num_rows * plot_image_size, num_cols * plot_image_size, 3))
return generated_images.numpy()以下のコードで、画像生成するために、最初の値(noise)が完全にランダムになって、その後、花の形にきれいに生成されることわかります。
<code>initial_noise = tf.random.normal(shape=(num_images, image_size, image_size, <span class=”hljs-number”>3</span>))</code>
各step数の生成する画像の質の比較は以下です。
diffusion step=1

diffusion step=10

diffusion step=80

まとめ
今回、確率モデル+ニューラルネットワーク(hybrid model)の一つ、Diffusionモデルを紹介しました。直近は生成モデルとしてはかなり精度が良くて、AIの分野でも注目度が高いです。実サービスでは、基本的に表形式のデータが多いため、普通の使い方(生成モデル)に比べて、工夫が必要だと思います。また、Diffusionモデル自体は元になるネットワークの構造が自由に設定できるので、色んなデータ形式のお応用も今後増えて行くではないかと思います。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。

ブログの著者欄
グループ研究開発本部
GMOインターネットグループ株式会社
グループ研究開発本部とは、GMOインターネットグループの事業領域で力を入れているスタートアップやグループ横断のプロジェクトにおいて、技術支援・開発・解析などを行い、ビジネスの成功を支援する部署です。 最新のテクノロジーを研究開発し、いち早くビジネスに投入することで、お客様の発展と成功に貢献することを主要なミッションとしています。
採用情報


関連記事
-

【中編】Hack-1グランプリ2026 デモデーレポート|ついにグランプリ決定!最優秀賞チームに開発秘話を聞く
デザイン
-

【前編】Hack-1グランプリ2026 デモデーレポート|AI時代の学生ハッカソンに圧倒される2日間。「小さくなる日本」をどう表現する?
デザイン
-

【インタビュー後編】育休明けに直面した「AI時代」 GMOペパボのプリンシパルデザイナー・佐藤咲が歩む「共創」の道
デザイン
-

【後編】エージェンティックAIの「アウトプット品質安定化」を実現 GMOインターネットが実践する「ハーネスエンジニアリング」とは?ーEngineering Journey
技術情報
-

ハーネスエンジニアリングの本質 ー従来の開発規律を、エージェントが回せるように再設計する
技術情報
-

【前編】エージェンティックAIの「アウトプット品質安定化」を実現 GMOインターネットが実践する「ハーネスエンジニアリング」とは?ーEngineering Journey
技術情報

KEYWORD
CATEGORY
-
技術情報(590)
-
イベント(235)
-
カルチャー(59)
-
デザイン(67)
TAG
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI TALK
- AI 機械学習強化学習
- AI/機械学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI活用事例
- AI駆動
- AMD
- APT攻撃
- AWX
- Behind the Scenes
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- ConoHaVPS
- CS
- CSS
- CTF
- DC
- Designship
- Desiner
- developer
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- engineering
- Engineering Journey
- eVTOL
- expert
- EXPERT CROSS
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOインターネットグループ陸上部 – GMOロボッツ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- Good Morning
- GPU
- GPUクラウド
- GTB
- Hack-1グランプリ
- Hack‐1グランプリ
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- Japan Drone
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- エージェンティックAI
- オブジェクト指向
- オンボーディング
- お名前.com
- クリエイター
- クリエイターインタビュー
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ハーネスエンジニアリング
- バックエンド
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- フロントエンド
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- ロボティクス
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 技術書典20
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 映像制作
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 空飛ぶクルマ
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-

【後編】デザイナーとしての自分を形作る「気合と反復」。対話を通じて実践する、豊田恵二郎の制作哲学
デザイン
-

【前編】創業時から変わらない「一貫性」で業界をリード GMO Flatt Security CCO・豊田恵二郎が語る、「エンジニアの背中を預かる」姿勢
デザイン
-

【第2回・AI TALK】GMOサイバーセキュリティ byイエラエ・三村 聡志さんに聞く、AI時代の攻撃と防御のいま
技術情報
-
【中編】Hack-1グランプリ2026 デモデーレポート|ついにグランプリ決定!最優秀賞チームに開発秘話を聞く
デザイン
-
【前編】Hack-1グランプリ2026 デモデーレポート|AI時代の学生ハッカソンに圧倒される2日間。「小さくなる日本」をどう表現する?
デザイン
-

【Expert Cross #1】“人生2周目”のエキスパートが挑む、「つながり」の構築と認知拡大
技術情報
採用情報

SNS FOLLOW
