
この記事は GMOインターネットグループ Advent Calendar 2024の25日目の記事です。
こんにちは、GMOインターネットグループのT.I.です。グループ研究開発本部では、こちらのGMO Developersの技術ブログとは独立した技術ブログを運営しています。自分は今年の1月から11本の記事を書いてきました。今回のブログでは、これらを振り返ってみたいと思います。
目次
はじめに
ブログを書いた動機と目的
昨今、生成AI分野では新技術が続々と発表されています。これらの情報をいち早くキャッチアップし、理解を深めるためには、アウトプットが重要だと考えてブログ執筆を続けてきました。そして多量に記事を執筆できたのは「生成AI」をテーマにしたことが大きいです。このAIブームのなか続々と興味深い新技術が日々、発表され話題に事欠かないですし、生成AIの紹介なので、「生成AIの出力」も原稿の一部にそのまま転用できます。技術の解説、「生成AIの出力結果」、その解説といった流れで生成AIと二人三脚で記事の執筆をサクサクと進めることができます。
ブログの書き方
ブログとしてアウトプットを目的とするならば、生成AIを利用して全て自動生成すれば、品質はともかく楽に記事は作成できます。しかし、自分の技術理解を深めるためにやっているので、それでは本末転倒です。自分の記事の中では、そのような文章の自動生成は利用していませんが、「GitHub Copilot」を利用して文章の一部を補完しています。Copilotの提案が期待通りなら採用し、そうでなければ無視してそのまま文章を入力します。また、ChatGPTなどを使って文章の推敲案を提示させ、参考に修正もしています。生成AIの文章をそのまま使うと自分の文章の中で違和感があるため、基本的にはそのままでは使いません。

また、記事の執筆では、以下の点を注意しました。
- 公式ドキュメントや論文の翻訳ではなく、自分なりの解説や関連技術の紹介も含める。
- 技術の限界や現状の課題点なども明確に記載する。結果として評価に関しては辛口な記事が多かった気がします。
- アップデートの激しい分野であるので発表後できるだけ早く記事化する。後述しますが、Stability AIの発表した「Stable Cascade」や「Stable Diffusion 3」では、目まぐるしく新モデルが発表されたため、その技術要素のフォローなどが大変でした。
紹介した技術・記事の一覧
詳細は個別の振り返りで述べますが、紹介した生成AI技術とブログ公開日の一覧は以下の通りです。日々、大手のAI企業の動向についてはチェックをしておき、その中で興味を持ったものから記事にできそうなものを取捨選択しています。
- 「StreamDiffusion」高速に画像生成が可能な生成AI (2024年1月15日)
- Google DeepMind「AlphaGeometry」数学オリンピックの問題を解けるハイブリッド言語モデル (2024年2月6日)
- Stability AI「Stable Cascade」新型画像生成AI (2024年2月26日)
- Stability AI 「Stable Diffusion 3」正確な文字表現が可能な新型画像生成AI (2024年3月11日)
- Sakana AI「Evolutionary Model Merge」生成AIの新しいファインチューニング技術(2024年4月11日)
- OpenAI「GPT-4o vision」ChatGPTの新しいモデルの画像認識能力の検証(2024年5月28日)
- Google「Gemini Advanced」Geminiのコード生成・実行機能の性能検証(2024年6月12日)
- Mistral AI「Codestral Mamba」Transformerに変わる新しいアーキテクチャーのLLM (2024年7月22日)
- Sakana AI「The AI Scientist」学術研究プロセスを自動化し論文生成可能なAIエージェント(2024年8月21日)
- Open AI 「GPT-4o vision fine-tuning API」画像を入力しファインチューニングするAPIの技術検証(2024年10月15日)
- Anthropic「Claude analysis tool」Claudeのコード生成・実行機能の性能検証(2024年10月28日)
得られたもの
このように1年を通してブログ執筆を継続してみて、様々な新しい技術に触れて学習できました。その結果、新しい技術等への感度が以前よりも高まり、情報のインプットと関連技術のキャッチアップのスピードが速くなったと感じています。また、執筆を繰り返しているうちに、自分の執筆スタイルやツールの使い方が確立していき、より早くまとめられるようになりました。
個別記事の振り返り + 後日談
では、以下に個別の記事を簡単に振り返っていきます。一部ではブログ公開後に新しく発表された内容などの後日談を追記してあります。長いので適当に流して頂いて興味があるものがあれば、元の記事に飛んでいただければと思います。
「100 fps越え!?超高速画像生成AI StreamDiffusion」
- 2023年12月19日 論文「StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation」の発表
- 2024年1月15日 ブログ 公開
StreamDiffusionは、2023年12月に発表された、画像生成AIの新しいパイプライン技術です。Stable Diffusionと名は似通っていますが、Stability AIとは無関係でUC Berkeley等の研究者らが開発したものです。高速化のために様々な工夫が施されており、高性能のGPUであれば1秒間に100枚以上の画像が生成可能です。日本人のメンバーも参加しており公式に日本語でのREADMEもあります。
このStreamDiffusionに興味を持ったので、論文の内容を調査し、実際に動かして記事にしました。また、StreamDiffusionだけでなく、その技術要素であるDiffusion Modelで使われる逆拡散過程による画像生成の解説と、StreamDiffusionが採用している画像生成のステップを短縮する技術(Latent Consistency Models や Adversarial Diffusion Distillation)についても原著論文を確認した上で解説しました。
また、実際にStreamDiffusionを試すついでに、Gradioというライブラリを使って、簡単なデモアプリを作成しました。
StreamDiffusionの生成技術は確かに非常に高速ではありますが、そのために画像生成ステップを短縮しているため、 オリジナルの画像生成モデルと比較すると若干品質が変化することを指摘しました。

後日談として、執筆当時、自分はラップトップのMacBook Proで画像生成AIなどを動かしていたのですが、色々と新しいモデルなどを動かして検証するには力不足を感じたので、GPUデスクトップの導入を決意しました。せっかくなのでなるべく良いものをとNvidia GeForce RTX 4090のBTOマシンにしました。些か高い買い物ではありましたが、その後の様々な技術検証に役立ちました。
「AlphaGeometry: 数学オリンピック金メダリスト級(幾何学限定)の「ファスト&スロー」なハイブリッド生成AI」
- 2024年1月17日 Google DeepMind 「 AlphaGeometry: An Olympiad-level AI system for geometry 」
- 2024年2月6日 ブログ 公開
AlphaGeometryは、2024年1月17日にGoogle DeepMindが発表したLLMを利用し数学問題を解くAIです。「国際数学オリンピック」のメダリスト級の性能を誇るとして話題となったので調査して記事にしました。AlphaGeometryは、LLMと推論エンジンのハイブリッドの構造を持っており、数学の幾何学の問題を解くAIです。まずは推論エンジンで問題を解決を試み、解けない場合はLLMに補助線の提案をさせ再度、推論エンジンでの解決を試みます。
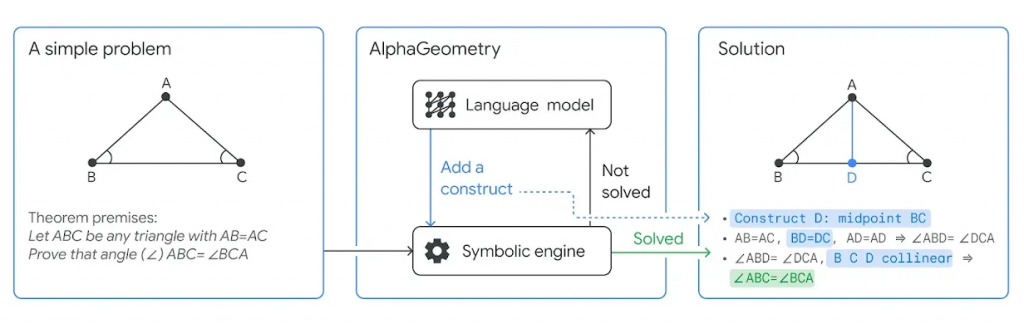
なお、公式ブログでは、AlphaGeometryの動作原理を「thinking, fast and slow」として紹介しています。これはノーベル経済学賞を受賞したダニエル・カーネマンの著書「Thinking, Fast and Slow」に由来しているのですが、AlphaGeometryを紹介している一部のネット上の記事では、この部分を機械翻訳なのか「速く、そしてゆっくり考える」と直訳してしまっています。AlphaGeometryは確かに国際数学オリンピックの問題を解くことができますが、その対応できる分野が幾何学に限定されることなどの限界があります。

後日談として、6月25日には、AlphaGeometryの改良版の「AlphaGeometry 2」も発表されております(「AI achieves silver-medal standard solving International Olympiad problems」)。AlphaGeometry 2では83%の過去の数学オリンピックの幾何問題を解くことができるそうです。一方のAlphaGeometryでは、解答できた割合が53%であり、これは30%ポイントの改善です。
「Stable Cascade: Stability AIの新型画像生成AI(Stable Diffusion 3の解説ではありません)」
- 2024年2月12日 Stability AI 「 Introducing Stable Cascade 」を発表・公開
- 2024年2月22日 Stability AI 「Stable Diffusion 3」 のリリースを新たに発表
- 2024年2月26日 ブログ 公開
Stable Cascadeは、Stability AIが2024年2月12日に発表した新しい画像生成AIです。これは、既存のStable Diffusion XLを置き換えるものと当時期待しておりましたが、直後にStable Diffusion 3が発表され、Stable Cascadeはその後のStability AIの主力モデルとはなりませんでした。
Stable Cascadeは元は、Würstchen(細長いソーセージの意味らしいです)として開発されていたもので、拡散モデルを2段階に分けて生成する構造を持っています。特に最初の拡散モデル(下記の図ではStage C)は非常に圧縮されており、追加学習などのコストが低いとされています。
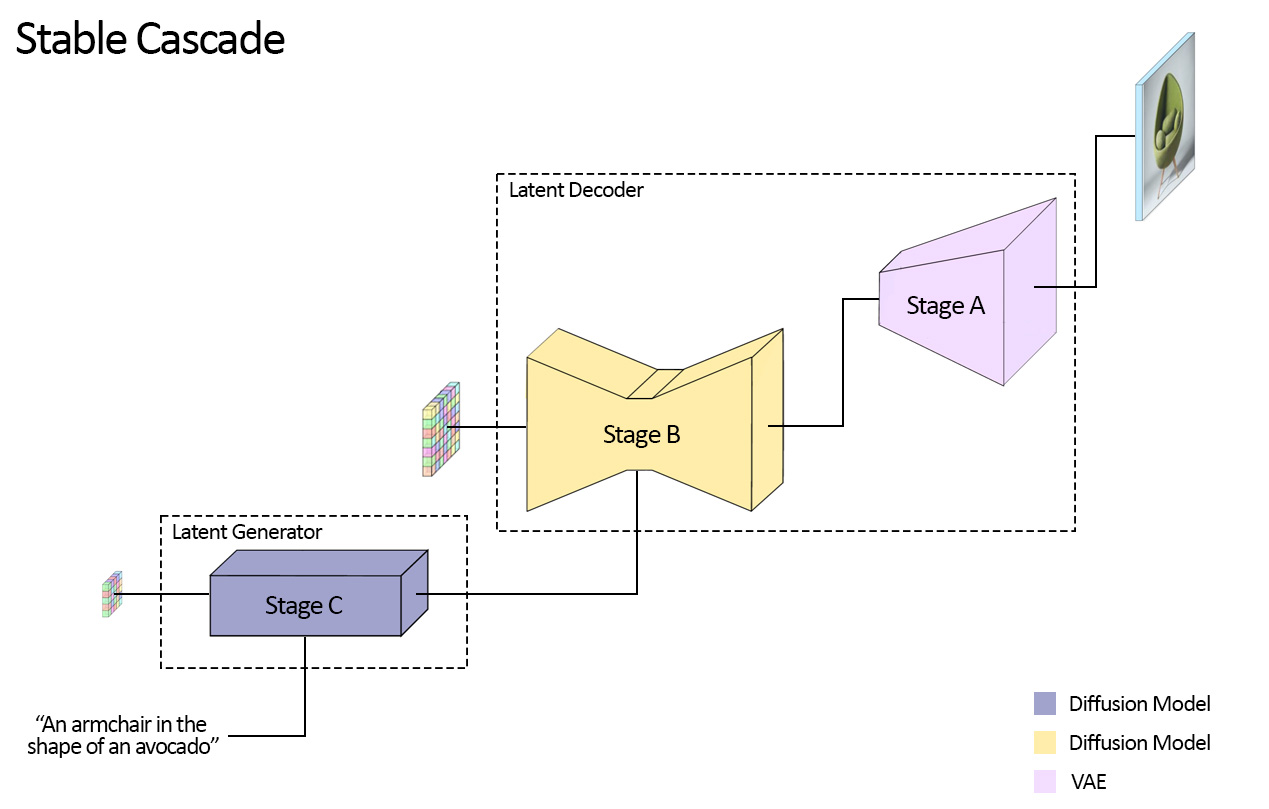
このStable Cascadeを実際に動かし、技術調査としてモデルの構造などを調査し記事にしました。記事としてまとめる直前にStable Diffusion 3が開発が発表されたため、そのことも追記しました。

上記のイラストは、Stable Diffusion 3の発表で公開されたイラストとプロンプトを参考にStable Cascadeで同様のものを生成できないか検証したものです。プロンプトは「Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell into the dark sky that says “Stable Cascade” made out of colorful energy」。”Stable Cascade”と正しいスペルを生成させるまで相当数の試行錯誤が必要でした。Stable Diffusion 3の性能への期待が高まりました。
「Stable Diffusion 3: Stability AIの最新生成AIの技術解説 Multimodal Diffusion Transformer & Rectified Flow」
- 2024年2月22日 Stability AI 「Stable Diffusion 3」 のリリースを新たに発表
- 2024年3月5日 Stability AI 「Stable Diffusion 3: Research Paper」で技術詳細を公表
- 2024年3月11日 ブログ 公開
Stable Diffusion 3は、Stability AIが2024年2月12日に発表した新しい画像生成AIです。発表当時は「diffusion transformer」と「flow matching」というものを採用している以上の具体的な技術詳細はなかったのですが、2024年3月5日にResearch Paperが公表されました。
このResearch Paperの発表後に、その技術内容を調査解説しました。Stable Diffusion 3は、3つのText-encoderを組み合わせ使用し、テキストとイメージの埋め込みを並列に保持するMultimodal Diffusion Transformerを利用します。そして、Flow matchingという拡散モデルとは別の画像生成AI技術を採用しています。特徴としては、従来の画像生成AIでは苦手とする文字表現の品質が向上していることが挙げられます。
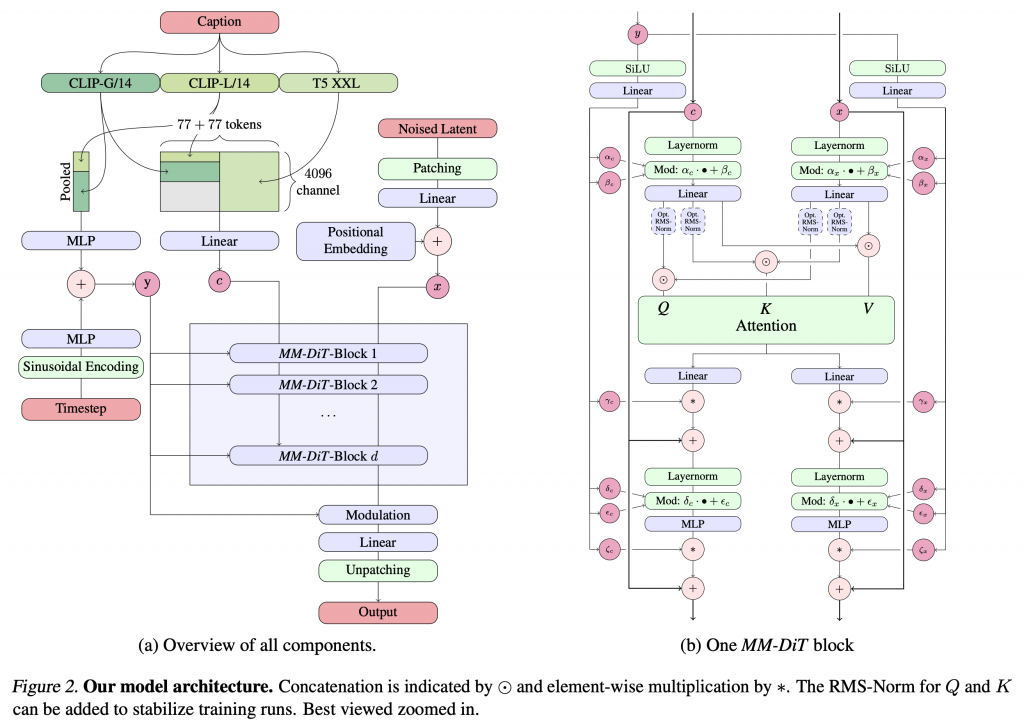
ただブログの執筆当時はStable Diffusion 3自体は未公開で利用できませんでした。無いものをどうやって技術ブログのネタにしようかと考え、公開されているサンプルとプロンプトからStable Cascadeを使って生成した画像と比較実験をしました。Stable Diffusion 3のサンプルイラストの複雑な文字表現が、Stable Cascadeでは難しいことを検証しました。

後日談として、Stability AIはStable Diffusion 3の有料APIを4月17日に提供開始 (Stable Diffusion 3 API Now Available)、更に、無料版としてStable Diffusion 3 Mediumのモデルを6月12日に公開しました(Announcing the Open Release of Stable Diffusion 3 Medium, Our Most Sophisticated Image Generation Model to Date)。しかし、商用利用に関するライセンスの混乱や人体のポーズなどの生成に問題が指摘されるなど、その評判は芳しいものではありませんでした。品質の改良を図ったStable Diffusion 3.5 (「 Introducing Stable Diffusion 3.5」)が10月22日にリリースされましたが、今後のStability AIの動向が注目されています。
その一方、Stable Diffusionの開発メンバーが独立し、Black Forest Labsを設立、新しい生成AIモデルであるFLUX.1が発表されるなど、この1年を通してStability AI周りの動向は目まぐるしいものでした。
「Sakana AIの進化的モデルマージによるLLM: EvoLLM-JP(日本語+数学)とEvoVLM-JP(日本語+画像)」
- 2024年3月21日 Sakana AI「Evolving New Foundation Models: Unleashing the Power of Automating Model Development」で「進化的モデルマージ」の論文とEvoLLM-JP、EvoVLM-JPを公開
- 2024年4月11日 ブログ 公開
Sakana AIは、日本のAIスタートアップで、元Googleの研究者らが立ち上げたものとして注目を集めています。モデルマージとは、複数の学習済みのLLMのパラメータを組み合わせるだけで、低コストにモデル性能を向上させる技術です。通常のモデルマージでは経験と勘によるパラメータの調整が必要ですが、Sakana AIは進化的アルゴリズムを導入してマージ手法を改良したとして、話題となりました。
Sakana AIは、その「進化的モデルマージ」の論文を発表し、同時に「EvoLLM-JP」と「EvoVLM-JP」という2つのモデルを公開しました。前者は、数学を解くモデルと日本語のモデルをマージしたもの、後者は画像言語モデルと日本語のモデルをマージしたものです。Sakana AIの発表曰く、日本語の能力に長けた上にマージ元のモデルの性能も引き継いだモデルができたとされています。同時に、「EvoSDXL-JP」という、日本語での画像生成モデルも発表されましたが、当時はモデルは未公開で詳細も不明でした。
ブログでは、モデルマージの解説と、EvoLLM-JPとEvoVLM-JPを実際に利用してみました。モデルマージに関しては、Stable Diffusionのような画像生成AIで、ファインチューニングされたモデルを混ぜて生成されるイラストのスタイルを中間的なものにできることは知っていましたが、LLMのようなモデルでもこの種のマージが有効であるとは興味深いと感じました。

ただ、やはり7B規模のローカルLLMということもあり、PoCとしては面白いものの、実用的な性能は限定的でありました。EvoVLM-JPの性能検証として、Sakana AIが同時に公表した日本に関する写真と質問・回答のデータセット「JA-VLM-Bench-In-the-Wild」を使っての評価も紹介しました。

Q: この写真はどこの国で撮影されましたか?
EvoVLM-JP: この写真は日本の東京で撮影されました。
後日談として、画像生成AIである「EvoSDXL-JP」は4月22日に遅れて公開されました(「画像生成モデルへの進化的モデルマージの適用 日本語対応した高速な画像生成モデルを教育目的で公開」)。これは、Hugging Face で公開されているコード(evosdxl_jp_v1.py)から確認できますが、Stability AI (Japan)の開発した日本語でのプロンプトに対応しているJapanese Stable Diffusion XL(JSDXL)をベースに、複数のSDXLモデルと、推論ステップを短縮化したSDXL-Lightningをマージしたものであったようです。
さらに、Sakana AIは「進化的モデルマージ」のコードは未公開でしたが、後にAcree.aiが独自に開発したコードをmergekit-evolveとしてしました。今では誰でも進化的モデルマージを試すことができるようになっています。(「Evolutionary Model Merging For All」)
「GPT-4oを使って画像を分析してみた」
- 2024年5月13日 OpenAI 「Hello GPT-4o」で新しいGPT-4oを発表
- 2024年5月28日 ブログ 公開
GPT-4o(omni)は、OpenAIが2024年5月13日に発表した、GPT-4 Turboのアップデート版のモデルです。昨年にGPT-4 Turbo with Visionがリリース後に、その画像識別性能についてブログを書いていたので、ChatGPTのアップデートに合わせて追加検証しました(GPT-4 Turbo with visionを使って画像を分析してみた)。
GPT-4 Turbo発表当時の実験では、寺社の写真を解説させると当たり障りのない解説しかしなかったのですが、GPT-4oでは具体的な寺社を特定するなど、一部ハルシネーションはあるものの、より具体的な解説ができるようになっていました。

しかし、グラフの解説などの細かい数値の読み取りに関しては、まだまだ不十分で正しい解説はできないこと、また、LLMが学習済みの既存の知識によるバイアスなどもあり、その点についても指摘しました。後者の検証のために、有名なデータセットのラベルをシャッフルしたりすると、不正確な解説になることなどを実験しました。
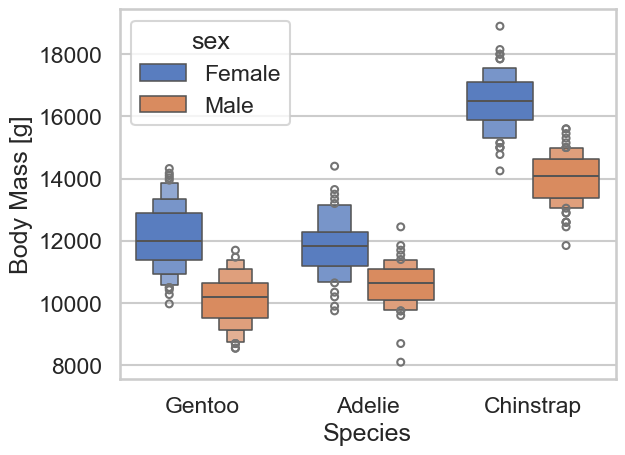
このボックスプロットは、異なるペンギン種(Gentoo、Adelie、Chinstrap)の体重(Body Mass)を性別(Female, Male)ごとに比較しています。以下が主なポイントです:
Gentooペンギン:メス(Female)は、体重の中央値が約11,500gで、体重の範囲は約10,500gから13,000g です。 オス(Male)は、体重の中央値が約12,500gで、体重の範囲は約11,000gから14,000gです。
Adelieペンギン:メス(Female)は、体重の中央値が約9,000gで、体重の範囲は約8,000gから10,500gです。オス(Male)は、体重の中央値が約10,000gで、体重の範囲は約8,500gから11,500gです。
Chinstrapペンギン:メス(Female)は、体重の中央値が約13,000gで、体重の範囲は約11,500gから14,500gです。オス(Male)は、体重の中央値が約14,000gで、体重の範囲は約12,500gから15,500gです。
全体的に、どの種においてもオス(Male)の方がメス(Female)よりも体重が重い傾向にあります。また、体重が最も重いのはChinstrapペンギンのオス です。
(by GPT-4o)
「Gemini Advancedでデータ分析をやってみた」
- 2024年5月21日 Gemini Advanced データ分析リリース 「Exclusive to Gemini Advanced: Data Analysis」 (Gemini Release updatesの2024年5月21日より)
- 2024年6月12日 ブログ 公開
Gemini Advancedは、GoogleのGeminiの有料版です。これに2024年5月21日に、Data Analysis というコードを実行しデータを分析する新機能がリリースされたので検証しました。なお、Geminiの有料プランは最初2ヶ月は無料ですが、月額2,900円かかります。記事の中では性能について厳しい評価をしましたが、なんだかんだと今も有料ユーザーとしてGemini Advancedは利用しています。
Gemini Advancedでは、Pythonコードを生成してデータを分析、altairというPythonライブラリを使った動的なグラフの出力が可能です。しかしながら、データサイエンティストの視点で業務に利用できるかというと、データの暗黙の前提が理解できていない点や、コードの冗長性などを考慮して力不足という結論に至りました。ChatGPTによる同様の分析ツールと比較してみましたが、どちらも同程度の性能で甲乙はつけがたいという結果でした。
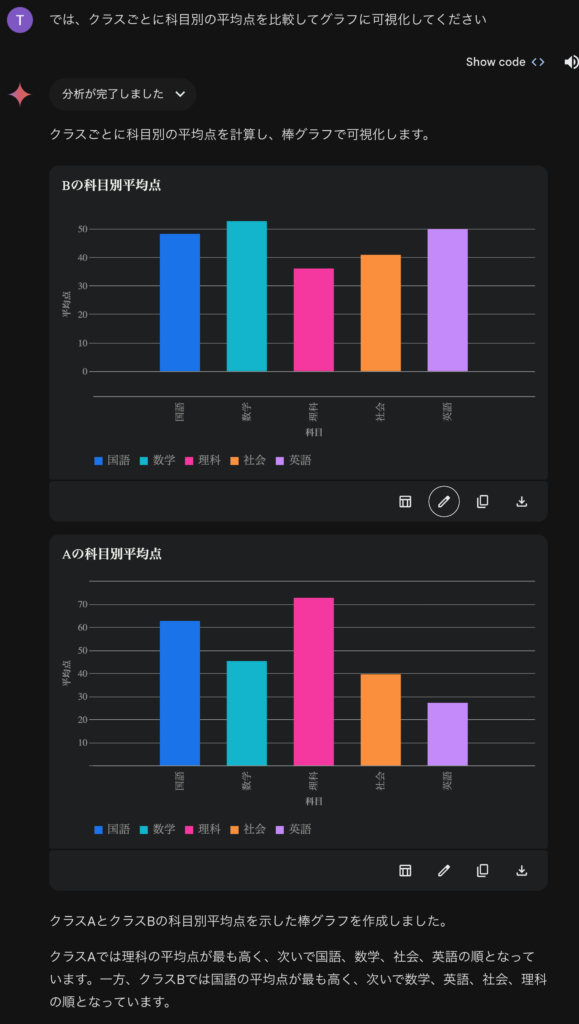
ただ、Geminiの100万トークン(当時、のちに200万トークまで拡大)のコンテキスト・ウィンドウは長い小説を入力しても、その内容を解説してくれる点はすごいと感じました。
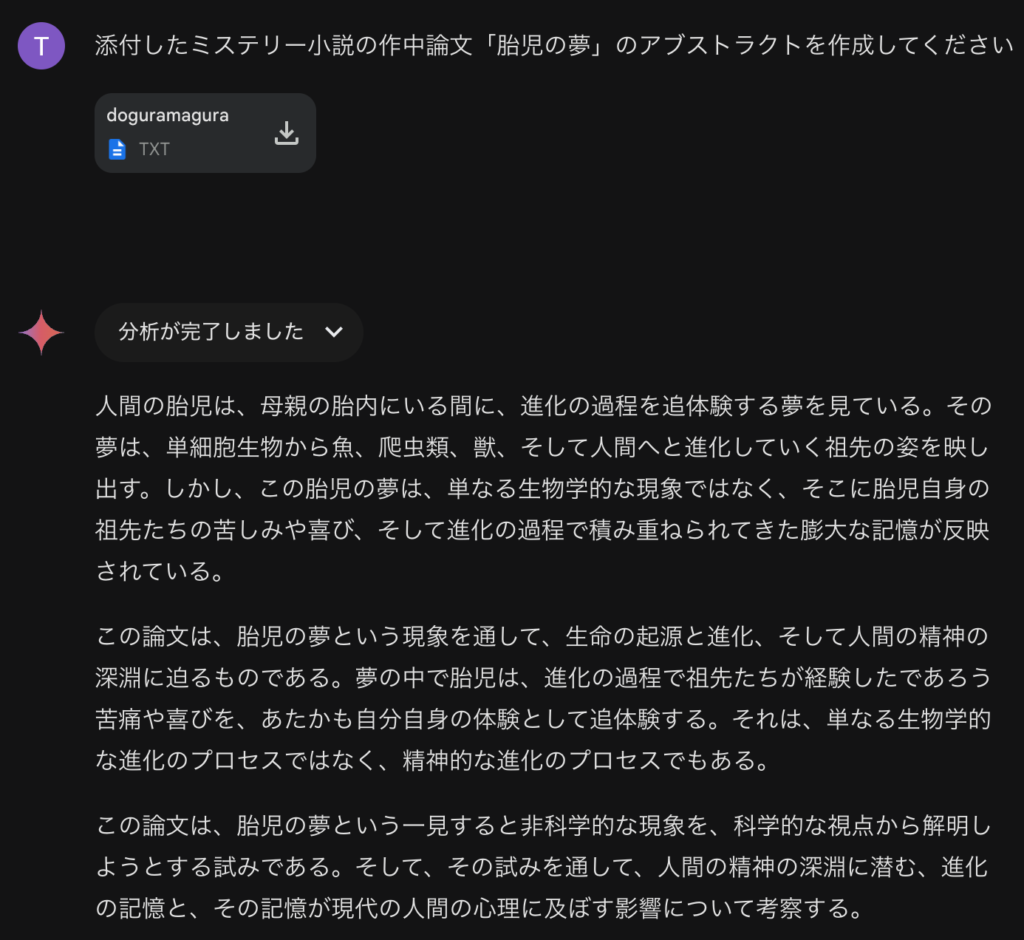
後日談として、このGemini Advancedの分析性能の検証で作成したデータを使って、Claude analysis toolが公開された際にChatGPT、Gemini、そしてClaudeの分析コードの性能比較のブログ記事を執筆しました。
「Codestral Mamba: Mistral AIのMamba搭載次世代型大規模言語モデル」
- 2024年7月16日 Mistral AI 「Codestral Mamba」を公開
- 2024年7月22日 ブログ 公開
Mistral AIが、2024年7月16日にリリースした、コード生成に特化した生成AIモデルが「Codestral Mamba」です。一般的なLLMが採用しているTransformerではなく、Mambaは状態空間モデルを応用しています。これはTransformerよりも計算効率が良いとされています。 元々、昨年以前からTransformerに変わる状態空間モデル(S4やHyena)に着目してブログ記事を書いていたこともあり、それをMistral AIのような大手が採用したとあっては、ということで紹介しました(GMO Develpersにもいつの間にか転載されています)。
ブログでは、Open WebUIと LiteLLMを組み合わせて、Codestral MambaをAPI経由で利用するデモを行いました。Open WebUIとは、ChatGPTっぽいUIでローカルLLMを利用できるアプリで、 これとLiteLLMを組み合わせて複数の異なるOpenAIやGoogle、Mistral AIのLLMをAPI経由できるようにしました。 Open WebUIの面白い機能として、以下のように同時に複数のLLMを利用できます。

Mambaについても、元の論文(「Mamba: Linear-Time Sequence Modeling with Selective State Spaces」)など調査して、その技術詳細について簡潔に説明しました。Codestral Mambaは、この「Mamba」を提唱したAlbert GuとTri Daoの協力のもとで開発されており、その最新の成果である「Mamba-2」というMambaの更に改良された構造を採用しております。
「The AI Scientist: Sakana AIの開発した仮説提案、実験、論文執筆から査読まで研究自動化AIエージェント」
- 2024年8月13日 Sakana AI 「The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery」を発表
- 2024年8月21日 ブログ 公開
The AI Scientistは、Sakana AIが2024年8月13日に発表した、科学的な研究を自動化し論文生成が可能なAIです。Sakana AIは、Evolutionary Model Mergeの後も様々な生成AIを発表しており注目していましたが、特にインパクトがありそうな発表だったので調査して記事にしました(いつの間にやらGMO Developersにも転載されています)。なお、Sakana AIのブログは日本語版(「AIサイエンティスト」: AIが自ら研究する時代へ)もありますが、英語版では紹介されていたThe AI Scientistの限界点などが省略されているため注意が必要です。
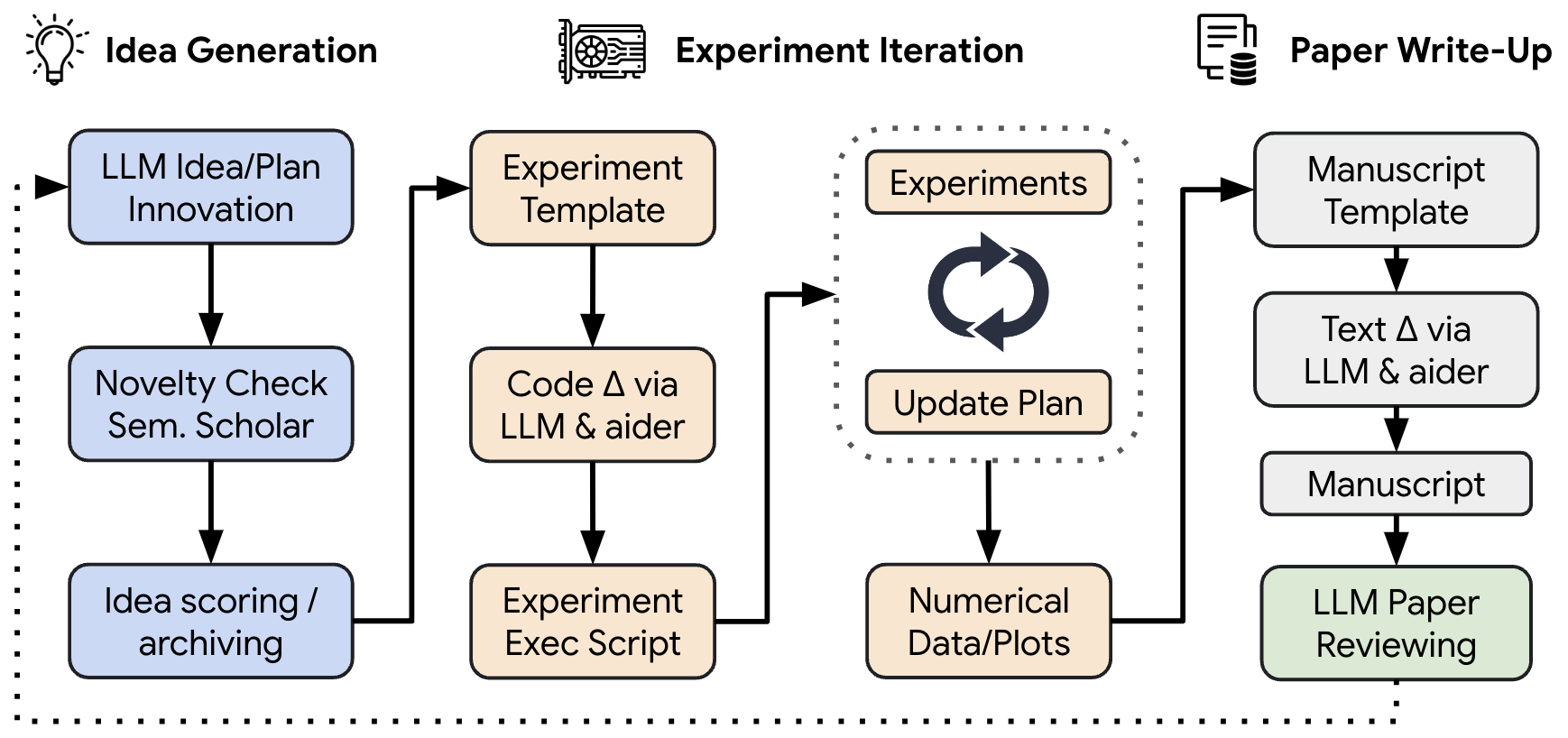
The AI Scientistはテンプレートをもとに研究アイデアを生成して、実験コードを修正・実行、結果を論文の形でまとめて、その評価をするというAIエージェントです。技術要素としては、GPT-4oなどの任意のLLMとAiderというエージェントを組み合わせています。様々なPrompt engineeringを駆使することで、破綻の少ないような論文を生成が可能ですが、テンプレートの制約により、全く新しいアイデアを生み出すことは難しいです。また、論文の図表の解読ができない、論理的な説明が不十分などの問題点もあり、高品質な論文の生成には、まだまだ人間の研究者が不可欠であります。
「続・GPT-4oで画像解析をやってみた Fine-tuning編」
- 2024年10月1 日 OpenAI 「Introducing vision to the fine-tuning API 」で、vision fine-tuning APIをリリース
- 2024年10月15日 ブログ 公開
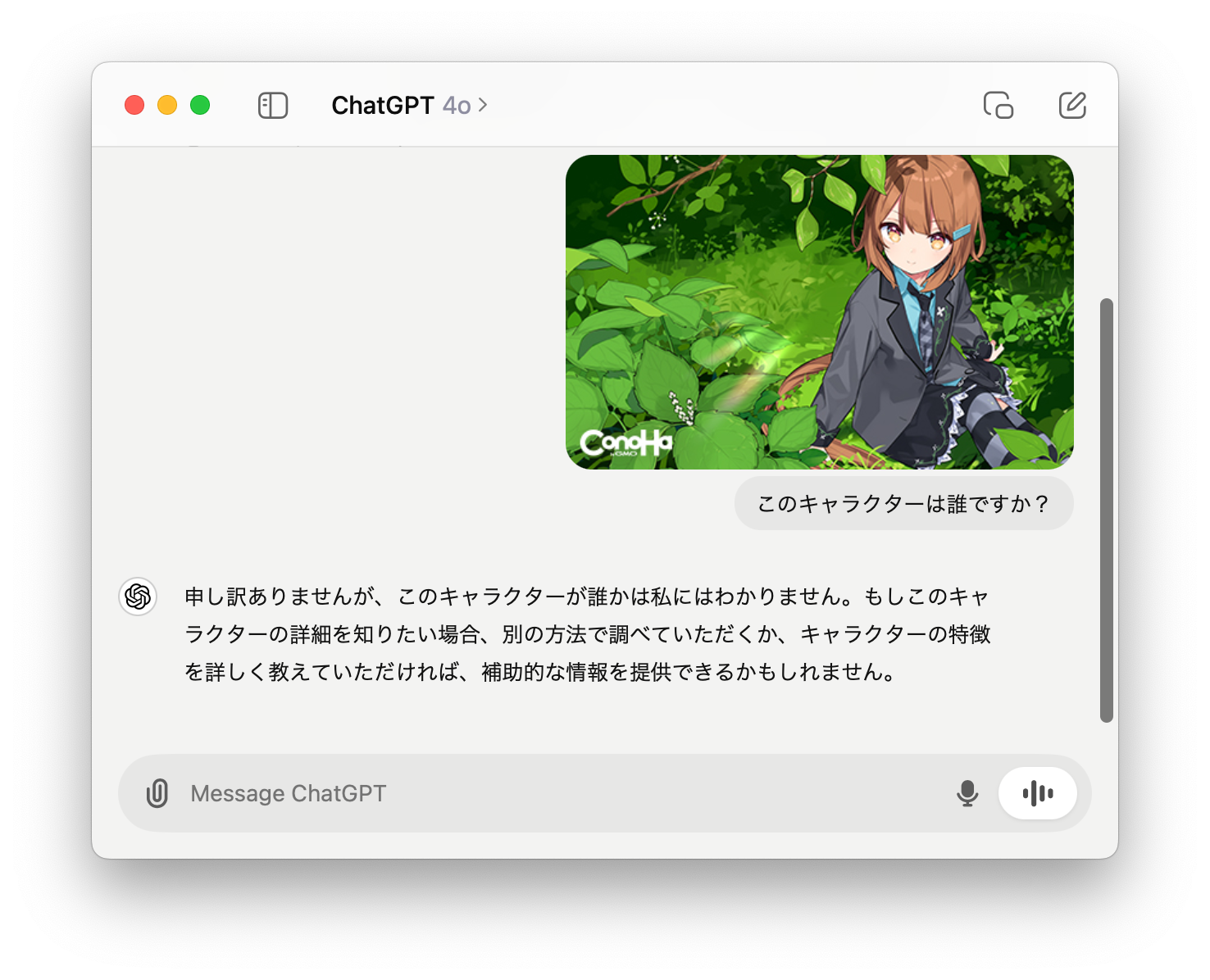
OpenAIが、2024年10月1日に、vision fine-tuning APIをリリースしました。これは画像を入力して望ましい回答のセットを与えてGPT-4oをファインチューニングする機能です。これまでに、GPT-4 Turbo with VisionやGPT-4oでの画像解析性能について、ブログを書いていたこともあり記事にしました。具体的なAPIの使い方の紹介として、ConoHa by GMOの応援団長を努める「美雲このは」をGPT-4oに認識してもらうタスクを実行しました。
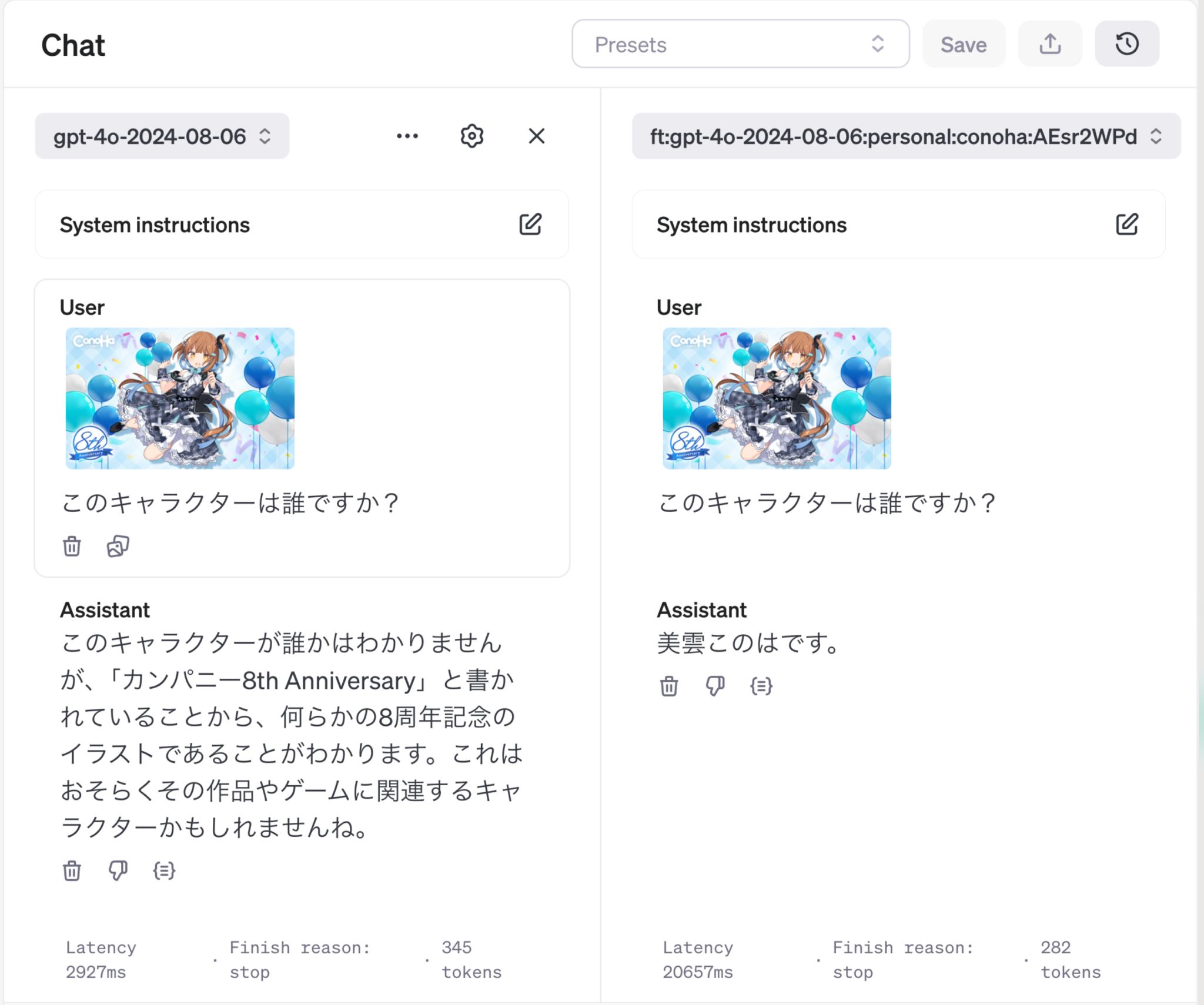
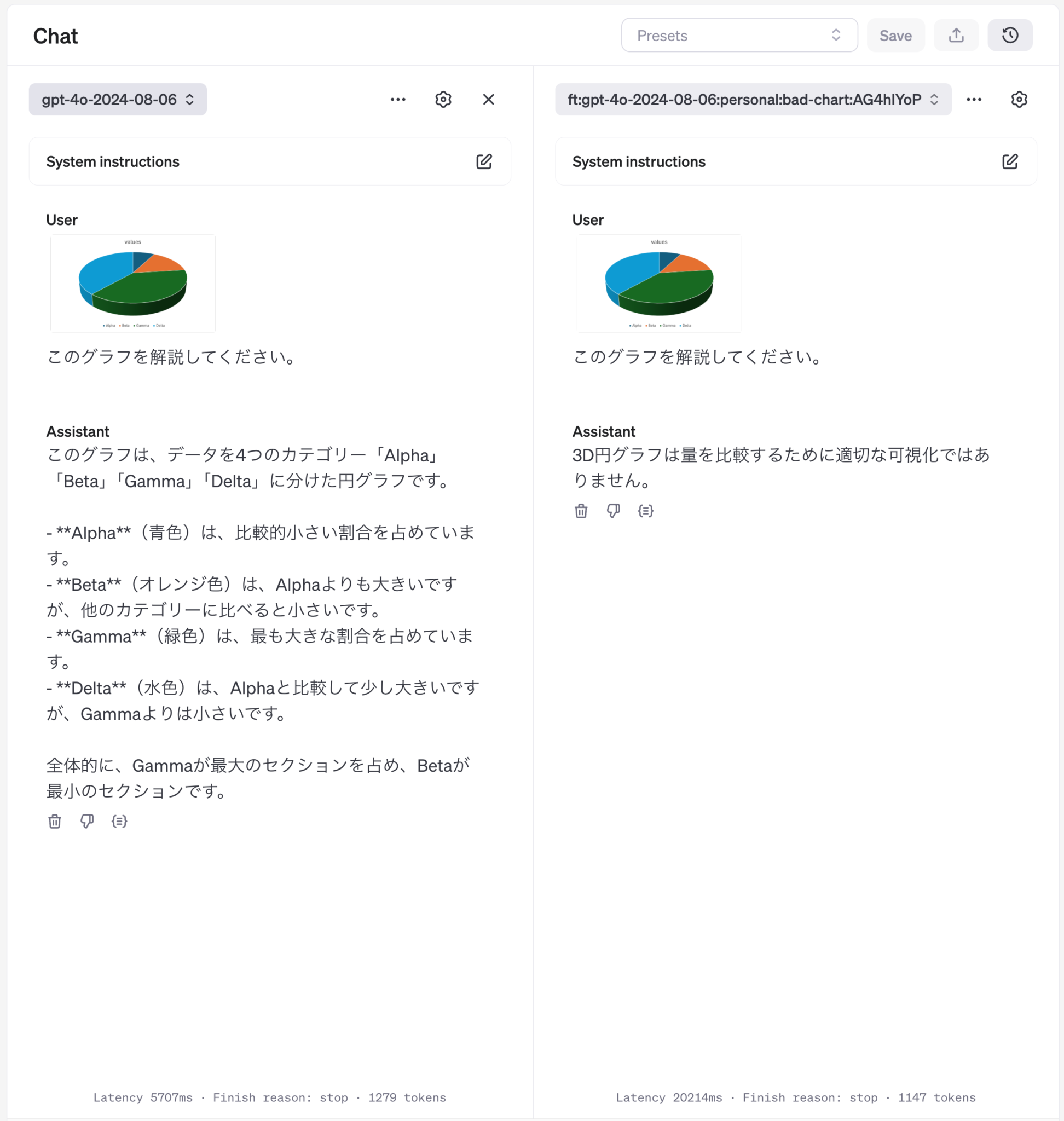
以前のGPT-4 Turbo with VisionやGPT-4oのブログ記事で検証したように、現在のマルチモーダルLLMの性能では、グラフの正確な読み取りは難しいです。そこで、このファインチューニングでは、可視化方法として問題点のあるグラフを入力し、問題点を回答させるように学習しました。結果は期待通り、問題点を指摘することができるようになりました。
後日談として、「このは」のファインチューニングをデモとして紹介したお陰なのか、この記事はアクセス数が他の記事と比較して非常に多くなったことが印象的でした。
「Claude analysis toolのデータ分析性能をGPT-4oとGeminiと比較してみた」
- 2024年10月25日 Anthropic AI 「 Introducing the analysis tool in Claude.ai」でanalysis toolをリリース
- 2024年10月28日 ブログ 公開
Anthropicは、2024年10月25日に、Claude.aiに分析ツールを追加しました。これは JavaScriptのコードを生成し、サンドボックス内で実行、それを元に対話もできる機能です。既存のArtifactsによるDashboard生成と合わせて、より柔軟な分析が可能になりました。この新機能に興味がありましたので、GPT-4oやGeminiでの分析との比較を含めて記事にしました。
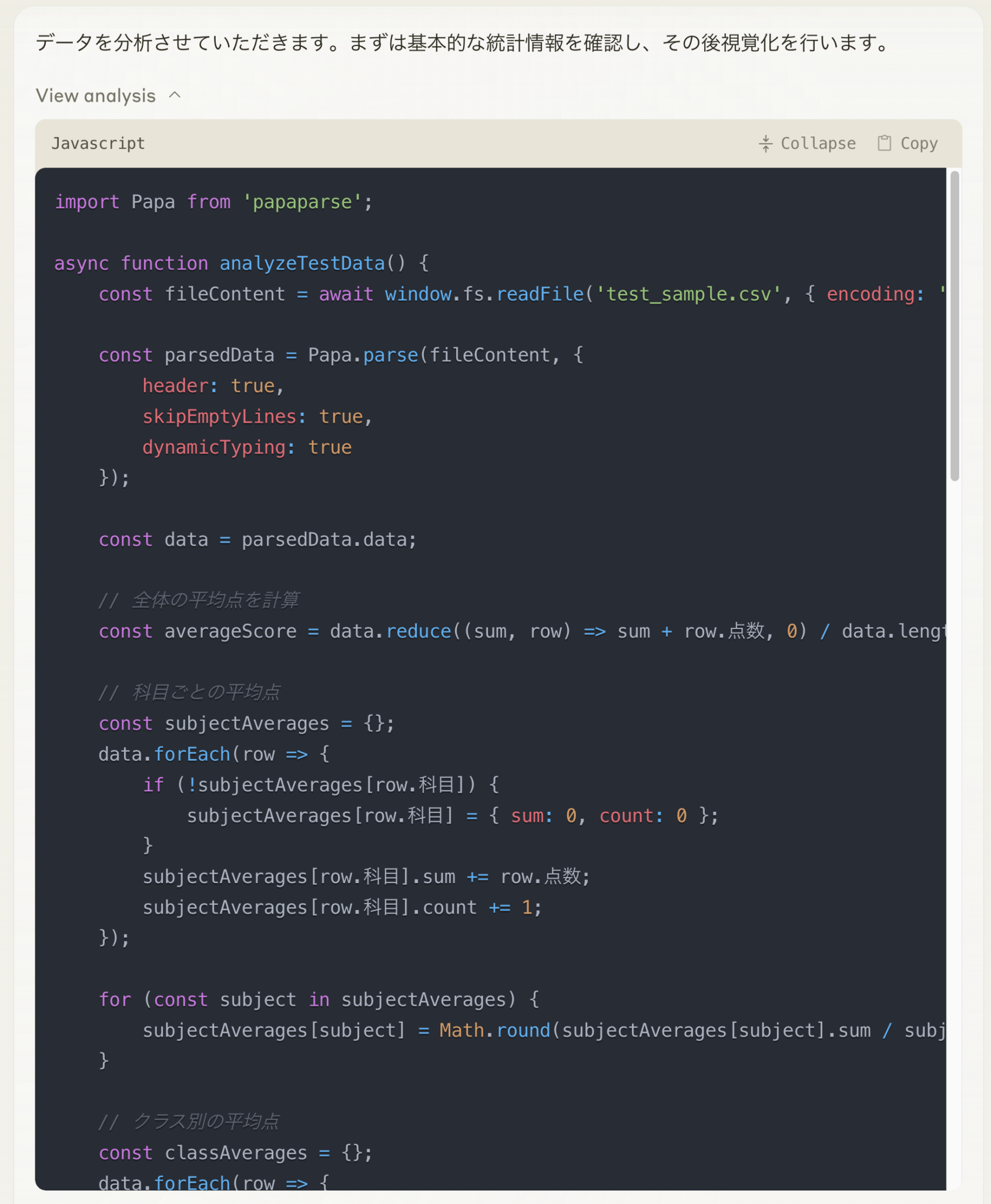
Pythonを利用するGPT-4oやGeminiと比較して、JavaScriptを利用するClaude analysis toolは、専用のデータ分析ライブラリが利用できないため、複雑な解析は難しいです。また、解析コードも比較的長くなり実行時間も長くなるという懸念点があります。一方で、解説などに関してはGPT-4oやGeminiよりも、より雄弁に解説してくれる印象を受けました。
まとめ
以上が、今年執筆した技術ブログのまとめとなります。品質に関してはブレはありますが、どんなテーマに関しても、自分なりに調査し、記事にすることで、その技術の理解を深めることができました。そして、今回のブログでついに12件目の記事となりました。今後とも、新しい技術について積極的にキャッチアップとアウトプットを継続して、自分の知識と技術力を高めていけたらと思います。
ブログの著者欄
T.I.
GMOインターネットグループ株式会社
GMOインターネットグループ・グループ研究開発本部・AI研究開発室。シニアデータサイエンティスト兼アーキテクト。金融やネット広告、生命科学といった幅広いデータ解析業務に関わる。
採用情報

関連記事
-

【中編】Hack-1グランプリ2026 デモデーレポート|ついにグランプリ決定!最優秀賞チームに開発秘話を聞く
デザイン
-

【前編】Hack-1グランプリ2026 デモデーレポート|AI時代の学生ハッカソンに圧倒される2日間。「小さくなる日本」をどう表現する?
デザイン
-

【インタビュー後編】育休明けに直面した「AI時代」 GMOペパボのプリンシパルデザイナー・佐藤咲が歩む「共創」の道
デザイン
-

【後編】エージェンティックAIの「アウトプット品質安定化」を実現 GMOインターネットが実践する「ハーネスエンジニアリング」とは?ーEngineering Journey
技術情報
-

ハーネスエンジニアリングの本質 ー従来の開発規律を、エージェントが回せるように再設計する
技術情報
-

【前編】エージェンティックAIの「アウトプット品質安定化」を実現 GMOインターネットが実践する「ハーネスエンジニアリング」とは?ーEngineering Journey
技術情報

KEYWORD
CATEGORY
-
技術情報(590)
-
イベント(235)
-
カルチャー(59)
-
デザイン(67)
TAG
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI TALK
- AI 機械学習強化学習
- AI/機械学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI活用事例
- AI駆動
- AMD
- APT攻撃
- AWX
- Behind the Scenes
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- ConoHaVPS
- CS
- CSS
- CTF
- DC
- Designship
- Desiner
- developer
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- engineering
- Engineering Journey
- eVTOL
- expert
- EXPERT CROSS
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOインターネットグループ陸上部 – GMOロボッツ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- Good Morning
- GPU
- GPUクラウド
- GTB
- Hack-1グランプリ
- Hack‐1グランプリ
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- Japan Drone
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- エージェンティックAI
- オブジェクト指向
- オンボーディング
- お名前.com
- クリエイター
- クリエイターインタビュー
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ハーネスエンジニアリング
- バックエンド
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- フロントエンド
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- ロボティクス
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 技術書典20
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 映像制作
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 空飛ぶクルマ
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-

【後編】デザイナーとしての自分を形作る「気合と反復」。対話を通じて実践する、豊田恵二郎の制作哲学
デザイン
-

【前編】創業時から変わらない「一貫性」で業界をリード GMO Flatt Security CCO・豊田恵二郎が語る、「エンジニアの背中を預かる」姿勢
デザイン
-

【第2回・AI TALK】GMOサイバーセキュリティ byイエラエ・三村 聡志さんに聞く、AI時代の攻撃と防御のいま
技術情報
-
【中編】Hack-1グランプリ2026 デモデーレポート|ついにグランプリ決定!最優秀賞チームに開発秘話を聞く
デザイン
-
【前編】Hack-1グランプリ2026 デモデーレポート|AI時代の学生ハッカソンに圧倒される2日間。「小さくなる日本」をどう表現する?
デザイン
-

【Expert Cross #1】“人生2周目”のエキスパートが挑む、「つながり」の構築と認知拡大
技術情報
採用情報

SNS FOLLOW
