
この記事は GMOインターネットグループ Advent Calendar 2025 18日目の記事です。
こんにちは、GMOインターネットグループのT.I.です。グループ研究開発本部では、こちらのGMO Developersの技術ブログとは独立した技術ブログを運営しています。自分は今年の1月から12本の記事を書いてきました。今回のブログでは、これらを振り返ってみたいと思います。
目次
はじめに
さて、昨年に引き続き今年もAdvent Calendarを担当させて頂きます。今年も日夜、生成AI技術の進展を追い続け、理解を深めるためのインプット・アウトプットを繰り返していると、いつの間にやら以下のような12本の記事となりました。
- OpenAI o1 pro mode でデータ分析してみた〜「Deliberative Alignment」による推論能力と安全性の強化〜 (2025年1月17日)
- DeepSeek R1 and V3 〜OpenAI o1級のオープンモデルの作り方〜 (2025年2月3日)
- Mercury CoderとLLaDA: 拡散言語モデルによる高速文章生成 (2025年3月12日)
- GPT-4oの中身(予想)とGlyph-ByT5〜文字の画像生成への挑戦〜 (2025年4月11日)
- FramePack and FramePack-eichi 〜高速・省メモリなローカル動画生成AI〜 (2025年5月2日)
- BAGEL: ByteDanceの画像生成・編集も可能なマルチモーダル統合オープン生成AI (2025年6月10日)
- OpenAIのGPT Image 1 APIで入力画像に高い忠実度(high input fidelity)の画像生成を試してみた (2025年7月23日)
- LangExtract: Gemini駆動でテキストからデータ抽出できるGoogleのPythonライブラリ (2025年8月12日)
- Nano Banana: Gemini 2.5 Flash Image(とQwen-Image-Edit)で画像生成・編集を試してみた (2025年9月1日)
- Gemini CLI extensionsでNano Bananaを使ってみた〜バイブコーディングな画像生成・編集〜 (2025年10月14日)
- gpt-oss-safeguard: OpenAIのポリシーベースのテキスト分類専用の推論型オープンモデル (2025年11月5日)
- Nano Banana Pro (Gemini 3 Pro Image)で画像生成・編集をやってみた (2025年11月25日)
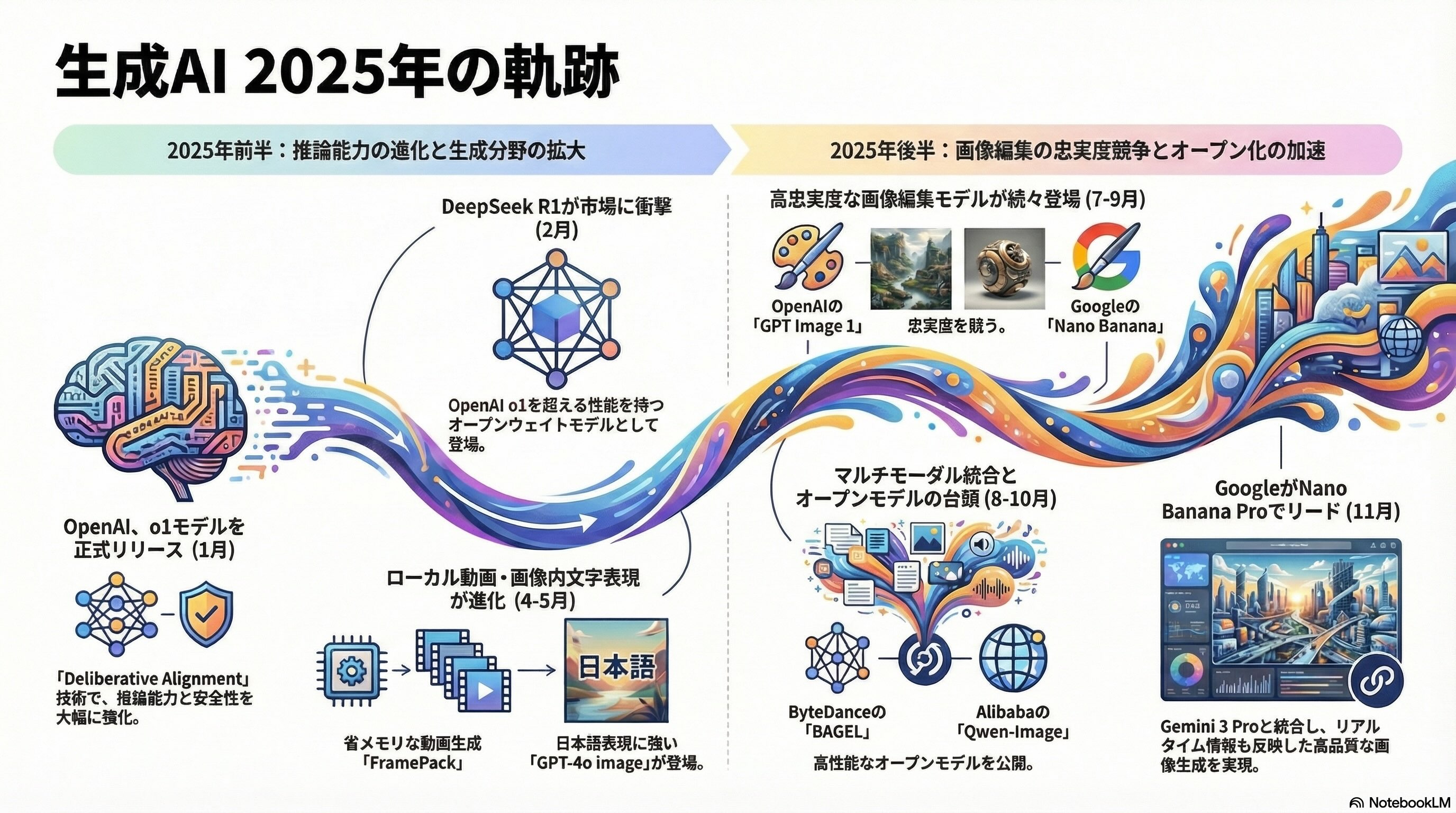
今年を振り返ると、OpenAIのo1やDeepSeek-R1のような深く長く考えるモデルの登場に始まり、拡散言語モデルや高忠実度な画像生成、ローカルでの動画生成、マルチモーダル統合モデルなど、多岐にわたる技術進展がありました。以下に各記事の概要と後日談をまとめて振り返ってみたいと思います。終わってみるとOpenAIやGoogleなどの注目度の高いトピックを紹介していたので、今年一年の技術の発展の流れが良い感じにフォローできました。
今年の画像生成AI技術のハイライトと言える「Nano Banana Pro」で本記事のインフォグラフィックを作成するとこのような感じになります。
ブログの書き方などや工夫については昨年の記事にあるので割愛します。
個別記事の振り返り
OpenAI o1 pro mode でデータ分析してみた〜「Deliberative Alignment」による推論能力と安全性の強化〜
- 2024年9月12日 OpenAI 「o1-preview」発表
- 2024年12月5日 ChatGPT 「Proプラン」と「o1」正式版リリース
- 2024年12月20日 「Deliberative Alignment」技術公開と「o3, o3-mini」発表
- 2025年1月17日 ブログ公開
OpenAIは2024年9月に「o1-preview」を発表しました。このo1モデルは従来のモデルとは異なり深く長い時間考えることで性能を高めるモデルであり、当時のGPT-4oから大きく性能が改善されました。
そして、2024年12月にOpenAIは「12 Days of OpenAI」と題して、連日新技術発表を行いました。その初日(12月5日)にChatGPT Proプランと「o1」を正式リリースしました。ChatGPT Proプランは、$200/月の料金という強気な価格設定ですが、o1が更に深く長く考える「o1 pro mode」が利用可能です。また最終日の12月20日には、o1モデルの基礎技術である「Deliberative Alignment」の技術レポートを公開し、更に新モデル「o3」の開発中と発表しました(注:deliberative 「熟慮の」という意味)。
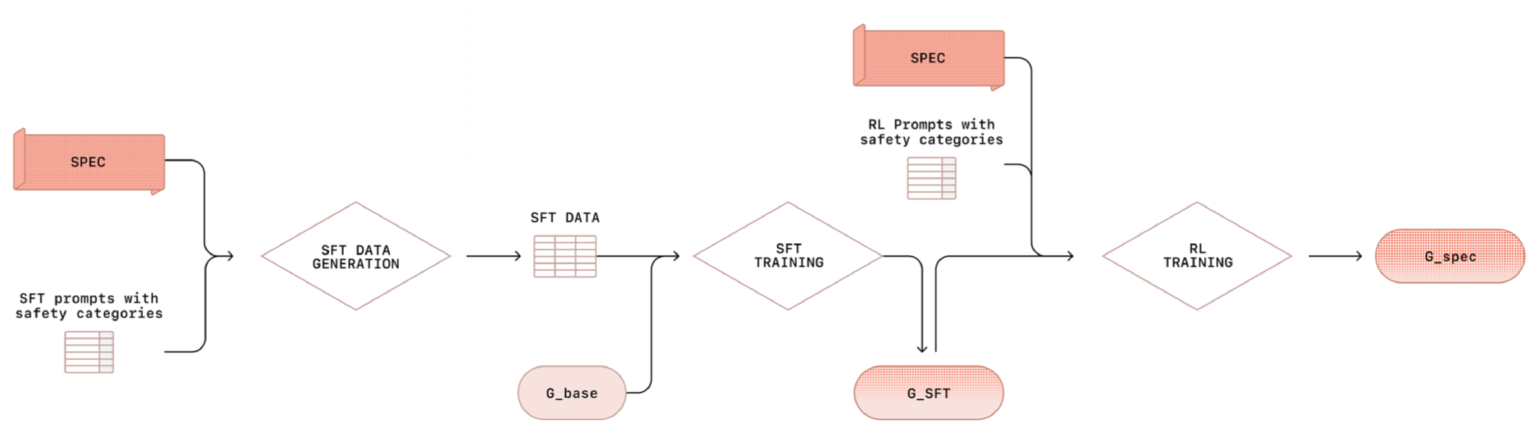
このブログでは、その技術要素に興味があったため「Deliberative Alignment」を一般的なLLMの学習プロセスである、事前学習、指示チューニング、選好チューニングを踏まえて解説しました。Deliberative Alignmentでは、プロンプトと推論過程、そして出力を組み合わせ学習データを作成し、教師あり学習と続いて強化学習を施すものです。その高い推論により「o1」や「o3」の高い推論能力と安全性が達成されます。
後日談: OpenAIのその後のモデル展開
その後も、OpenAIは以下のように様々な新モデルをリリースし続けました。
- 「GPT-4.5」(2025年2月27日)
- 「o3 & o4-mini」(2025年4月16日)
- 「gpt-oss」(2025年8月5日)
- 「GPT-5」(2025年8月7日)
- 「gpt-oss-safeguard」(2025年10月29日)
- 「GPT-5.1」(2025年11月12日)
- 「GPT-5.2」(2025年12月11日)
- 「GPT Image 1.5」(2025年12月16日)
「gpt-oss」と「gpt-oss-safeguard」は、OpenAIの発表したオープンウェイトのモデルで、後者に関しては後のブログ記事で紹介します。
OpenAIは着実に新モデルをリリースしているかに見えますが、GPT-4.5は性能はともかく、高いAPIコストが話題となり(参考「【詳報】GPT-4.5の特徴は? 教師なし学習で性能向上、OpenAI史上最大サイズ、API利用は超高価」)、GPT-5では、旧モデルである「GPT-4o」との人格(?)の落差が激しく、「4o君を返してよ」という声が多く聞かれました(参考「わたしのChatGPT 4oを返して! GPT-5登場で失われた旧AIの復活願う#keep4o運動を最新AIはこう分析する(CloseBox)」)。
その反省を踏まえて性格を矯正したGPT-5.1がリリースされましたが、追い討ちをかけるように11月18日にリリースされた「GoogleのGemini 3 Pro」の好調を受けて、緊急にGPT-5.2がリリースされると噂され(参考「OpenAI、次期モデル「GPT-5.2」を間もなく公開か」)、噂通りに12月11日にGPT-5.2が公開されました(参考「Introducing GPT 5.2」)。
更に、Nano Banana との対抗か、新しい画像生成AIである「GPT Image 1.5」もつい先日(12月16日)に登場しました。画像生成・編集機能が更に改善されたようです。
OpenAIのChatGPT、GoogleのGemini、そしてAnthropicのClaudeと所謂、AI御三家が激しい競争を繰り広げておますが、OpenAIのリードが徐々に縮まってきている印象です(これからどうなることやら)。
DeepSeek R1 and V3 〜OpenAI o1級のオープンモデルの作り方〜
- 2025年1月20日 「DeepSeek R1」発表
- 2025年2月3日 ブログ公開
DeepSeekが発表した「DeepSeek-R1」は、あのOpenAIのo1モデルを超える性能を持つだけではなく、学習のコストが非常に低く、更にオープンウェイトと当時大きな話題となりました。結果として、2025年1月末にNvidiaの株価が急落するなど社会的にも大きなインパクトを与えました。DeepSeekはR1の技術レポートを公開したので興味がありブログで解説しました。
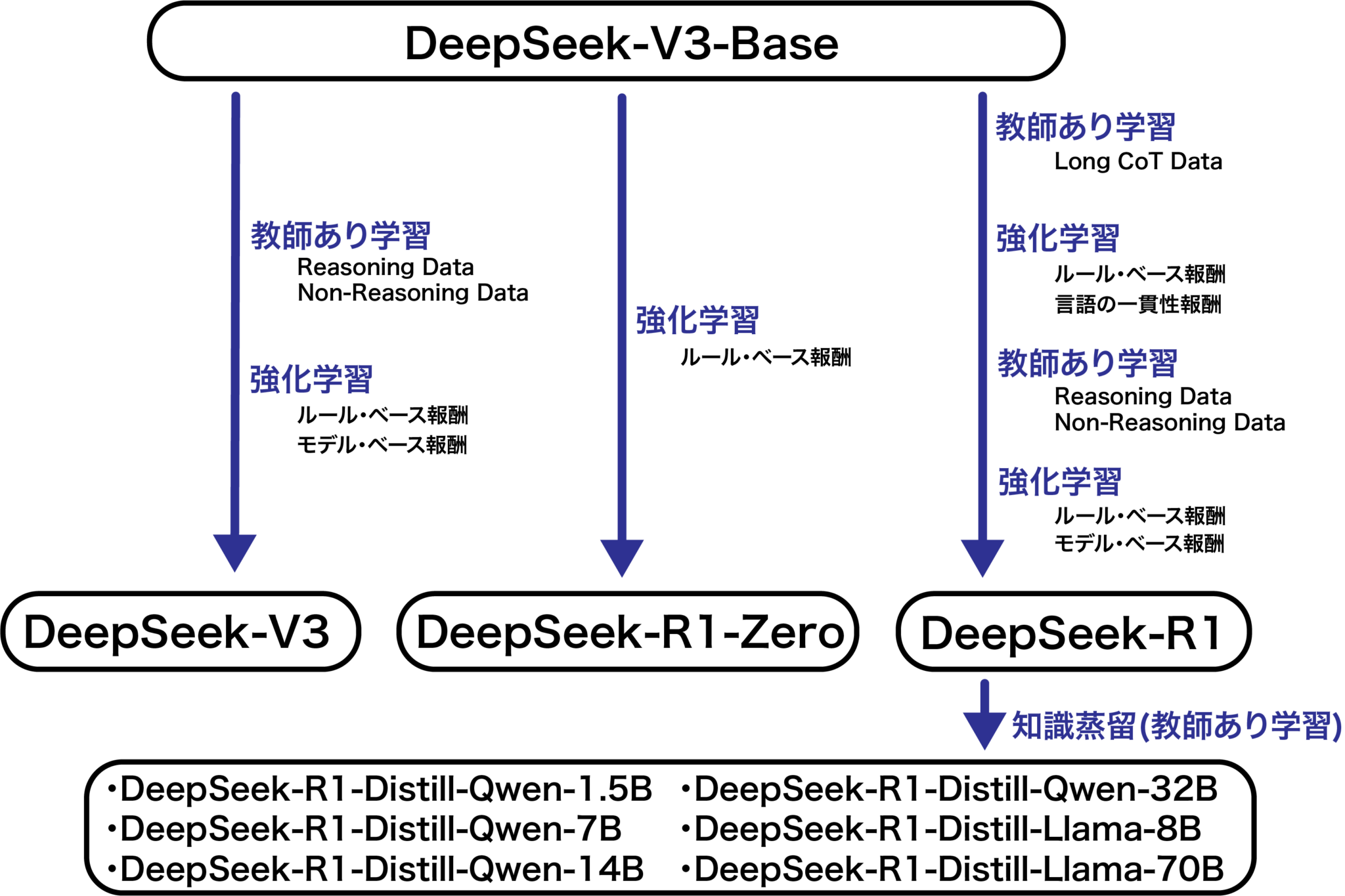
DeepSeek-R1は6710億パラメーターの巨大な推論型の言語モデルであり、「DeepSeek-V3-Base」を特殊な手法でファインチューニングしたものです。同時期に発表された「DeepSeek-R1-Zero」は、数学やコーディングなどの問題を解く強化学習のみで学習されたモデルですが、DeepSeek-R1-Zeroは、それだけでもo1レベルの性能を達成しています。他にもDeepSeek-R1から知識蒸留した小型モデルも多数公開されました。R1の学習のフローはo1モデルと類似し、推論過程のデータをもとに多段階の教師あり学習と強化学習で性能を向上させています。
後日談: DeepSeek-R1の論文、Natureに掲載
公開されていたDeepSeek-R1の技術レポートは、なんとあの三大科学誌の1つ「Nature」の論文として9月17日に出版されました。

掲載された論文は「DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning」というタイトルです。オープンアクセスになっているので、どなたでも読むことができます。

Mercury CoderとLLaDA: 拡散言語モデルによる高速文章生成
- 2025年2月14日 Ant Group「LLaDA 8B」発表
- 2025年2月26日 Inception Labs「Mercury Coder」発表
- 2025年3月12日 ブログ公開
一般的な言語モデルは自己回帰型で、文章の次の単語(Token)を一つずつ予測し文章を生成します。一方で「拡散言語モデル」という全く別の手法の研究も進められています。拡散言語モデルには、いくつか方式がありますが、Masked Diffusion Modelでは、ランダムにマスクされた単語を予測し文章を生成します。並列に複数の単語を同時生成でき、一文字づつの自己回帰型よりも高速な文章生成が可能です。
拡散言語モデルの利点は、自己回帰型の言語モデルにある「逆転の呪い」が軽減される点です。これは逆方向の推論が難しいという問題であり、例えば「トム・クルーズの母親はメアリー・リー・ファイファー」という関係を学習すれば「トム・クルーズの母親は?」には回答できますが、逆に「メアリー・リー・ファイファーの息子は?」には正しく回答できない問題です(The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A”)。

Inception Labsが発表した「Mercury Coder」は、コード生成に特化した拡散言語モデルで、Webサービスとしてリリースされた初めてのもので興味を持ち紹介しました。また、同時期に発表されていたオープンな拡散言語モデルであるAnt Groupが発表していた「LLaDA」もローカルで実行してみました。
Mercury Coderではコードを作成して実行できます。「テトリス」を作ろうとしたのですが、うまくプレイできるものにはならず、性能に関してはまだまだ改善の余地がある印象でした。

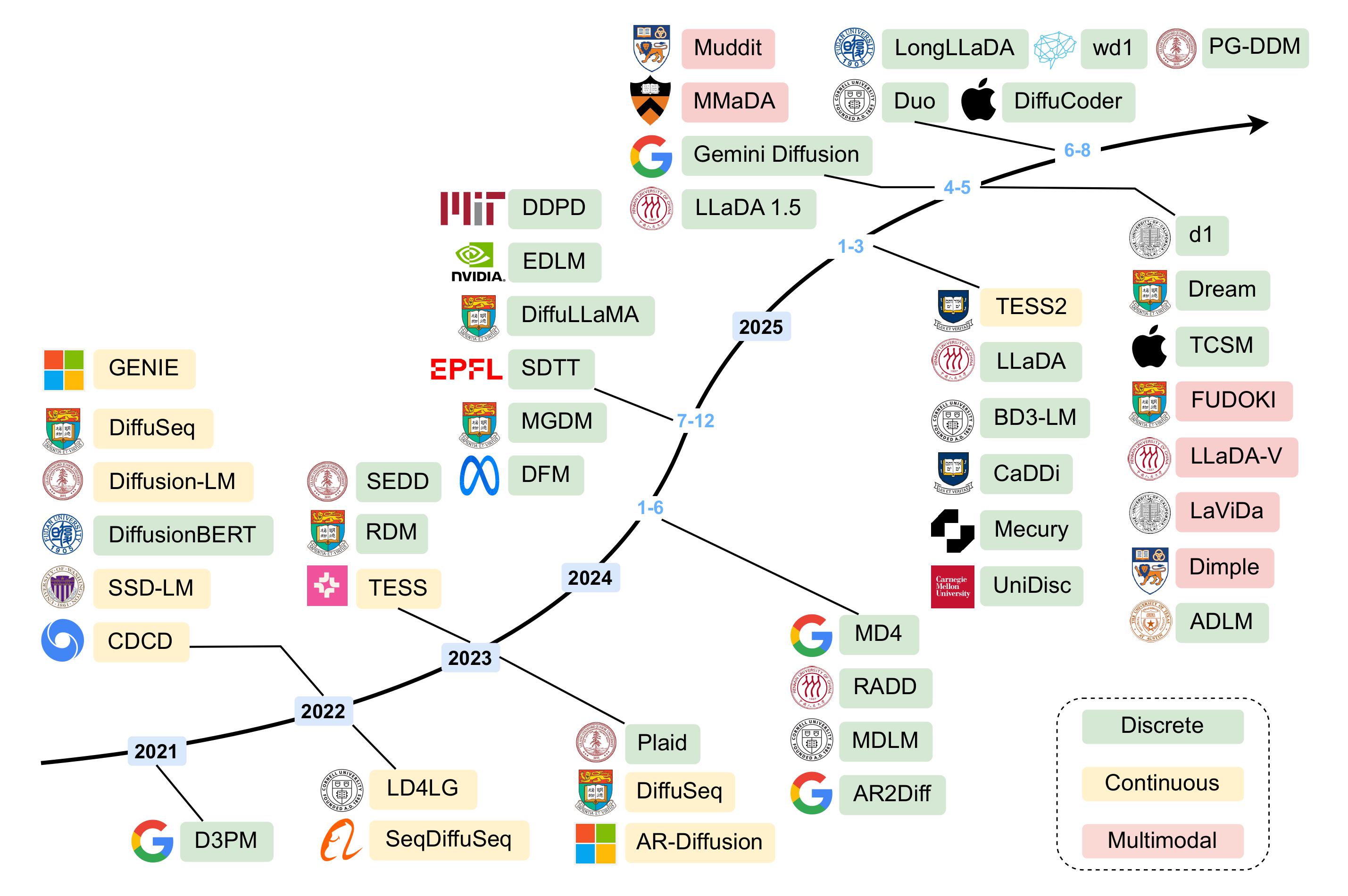
後日談: 拡散言語モデルのその後の展開
その後も続々と拡散言語モデルが発表されております。Googleが技術デモとして「Gemini Diffusion」を発表、マルチモーダルへの拡張、Apple「DiffuCoder」、ByteDance「Seed Diffusion」など発表しております。ブログで紹介していたLLaDAも1000億パラメータのLLaDA2.0 Flashと、160億パラメータのLLaDA2.0 miniが、12月12日に発表されました。今後どうなることでしょうか。
主要な拡散言語モデルの発表例
- 「Gemini Diffusion」 (2025年5月20日)
- 「MMaDA Multimodal Large Diffusion Language Mode」 (2025年5月21日)
- 「FUDOKI」(2025年5月26日)
- 「Muddit」 (2025年5月29日)
- 「DiffuCoder」 (2025年6月25日)
- 「Seed Diffusion」(2025年7月31日)
- 「LLaDA2.0」(2025年12月12日)
GPT-4oの中身(予想)とGlyph-ByT5〜文字の画像生成への挑戦〜
- 2025年3月25日 OpenAI「4o image generation」発表
- 2025年3月26日 「BizGen(Glyph-ByT5-v3)」発表
- 2025年4月11日ブログ公開
今年は画像生成モデルの性能が大きく改善した年でした。これまでのモデルは少ない文字数のアルファベットならば生成可能でしたが、日本語の文字表現が非常に苦手でした。OpenAIの「GPT-4o image generation」は、日本語も含めた文字表現がこれまでにないほど改善されました。この記事では、公開情報等から4o image generationのモデル構造について考察、Stable Diffusion などの従来のモデルの文字表現について振り返りました。
また、オープンモデルで多言語の文字生成のために研究されていた「BizGen(Glyph-ByT5)」も紹介し、実際に試しました。このモデルは文字を表現のためのByT5エンコーダーとSDXLベースのモデルを組み合わせたもので、インフォグラフィックのような複雑な構造が生成可能です。ただし、個別の要素の座標の指定が必要で利用は難しいです。文字のクオリティは、一応は読めますが、失敗例も多く、実用にはまだまだ不足している印象でした。

後日談: 複雑な文字表現(中国語)が可能な画像生成オープンモデルの発展(Qwen-Image, HunyuanImage 3.0, Z-Image)
- Alibaba「Qwen-Image」(2025年8月4日)
- Tencent「HunyuanImage 3.0」(2025年9月28日)
- Alibaba「Z-Image」(2025年11月27日)
Alibabaの「Qwen-Image」は、ローカルで実行可能なオープンモデルで、文字表現も大きく改善されています。構造は200億パラメータの Multimodal Diffusion Transformer (MMDiT)を採用、flow matching を利用しています。これはStable Diffusion 3 と同等手法です。プロンプトのエンコーディングには Qwen2.5 VLを採用しております。

Tenscentの「HunyuanImage 3.0」は、Mixture of Experts (MoE)を採用した、Diffusion Transformerベースの画像生成モデルです。オープンウェイトでありますが、800億パラメータもの巨大モデルで、実行には4 x 80GB以上(推奨は4x80GB)のVRAMが必要です。流石に一般家庭にあるPCでは無理ですね、

11月27日には、AlibabaのTongyi-MAIチームが、「Z-Image」を発表しました。これはScalable Single-Stream Diffusion Transformer (S3-DiT)という構造を持ち、テキストエンコーダーにはQwen3-4Bを使用、パラメータ数はQwen-Imageの200億に対して、Z-Imageは60億という小型モデルです。Z-Image-Base, Turbo, Editの3種類が開発されており、「Z-Image-Turbo」という高速版が先立って公開されました。Z-Image-Turboでは、画像生成の高速・高品質化のためにDecoupled-DMD(Distribution Matching Distillation)とDMDR(Distribution Matching Distillation meets Reinforcement Learning)という手法で追加学習され、16GのVRAMで動作します。1枚あたり数秒で高い文字表現力の画像が生成できます(参考:RTX 4090 の場合、1024×1024の解像度で約4秒)。


FramePack and FramePack-eichi 〜高速・省メモリなローカル動画生成AI〜
- 2025年4月17日「FramePack」発表
- 2025年4月21日「FramePack-eichi」発表
- 2025年5月2日 ブログ公開
OpenAIのSoraやGoogleのVeoなど、動画生成AIに関しても近年関心と発展が著しい分野です。しかし、ローカルでの動画生成となると、非常に高い計算リソースと長い生成時間から手軽に試せるものがありませんでした。Illyasviel氏が開発した「FramePack」は、省メモリで高速で、長時間動画が生成可能なモデルとして注目されました。
FramePackでは、過去の入力画像を順次圧縮しメモリを効率化、更に、最後のフレームを先に生成し、時間方向を逆に生成し生成動画の品質を向上させるなど、いくつかの工夫がなされています。
「FramePack-eichi」はFramePackの現地改修仕様です。eichiでは、最初と最後のフレームの画像の間を補完し、より意図した通りの動画が制作可能です。名前の由来は公式GitHubのREADMEによると以下の通りです。
Endframe Image CHain Interface (EICHI)
Endframe: エンドフレーム機能の強化と最適化
Image: キーフレーム画像処理の改善と視覚的フィードバック
CHain: 複数のキーフレーム間の連携と関係性の強化
Interface: 直感的なユーザー体験とUI/UXの向上
「eichi」は日本語の「叡智」(深い知恵、英知)を連想させる言葉でもあり、AI技術の進化と人間の創造性を組み合わせるという本プロジェクトの哲学を象徴しています。 つまり叡智な差分画像から動画を作成することに特化した現地改修仕様です。
実に、熱い熱量を感じさせてくれます。
ブログでは、FramePackとFramePack-eichiを使って動画を生成し遊んでみました。ローカルのRTX 4090環境で、1フレームあたり約2.5秒、全体で5秒の動画の生成には数分かかりますが、手軽に試せる点が良いですね。
後日談: FramePack-F1とFramePack-P1、そしてFramePack-eichiの消失?
また、Illyasviel氏は、5月3日には、未来方向へのフレーム生成をする「FramePack-F1」を公開、6月26には、改良版である「FramePack-P1」も発表しています。ただ、P1の詳細は未公開です。
FramePack-eichiの開発も継続され、FramePack-F1の技術を取り入れた「お壱」などのも追加されました。更に海外からの協力により多言語対応も進みました。何とも熱い展開ではないでしょうか?READMEにも以下のように書かれています。
「eichi」は日本語の「叡智」(深い知恵、英知)を連想させる言葉でもあり、AI技術の進化と人間の創造性を組み合わせるという本プロジェクトの哲学を象徴しています。 つまり叡智な差分画像から動画を作成することに特化した現地ワールドワイド改修仕様です。叡智が海を越えた!
と、大いに盛り上がっていたのですが、終わりは突然やってきました。

2025年9月末にFramePack-eichはリポジトリごと削除されてしまいました(参照「Framepack eichiの消失?について」)。
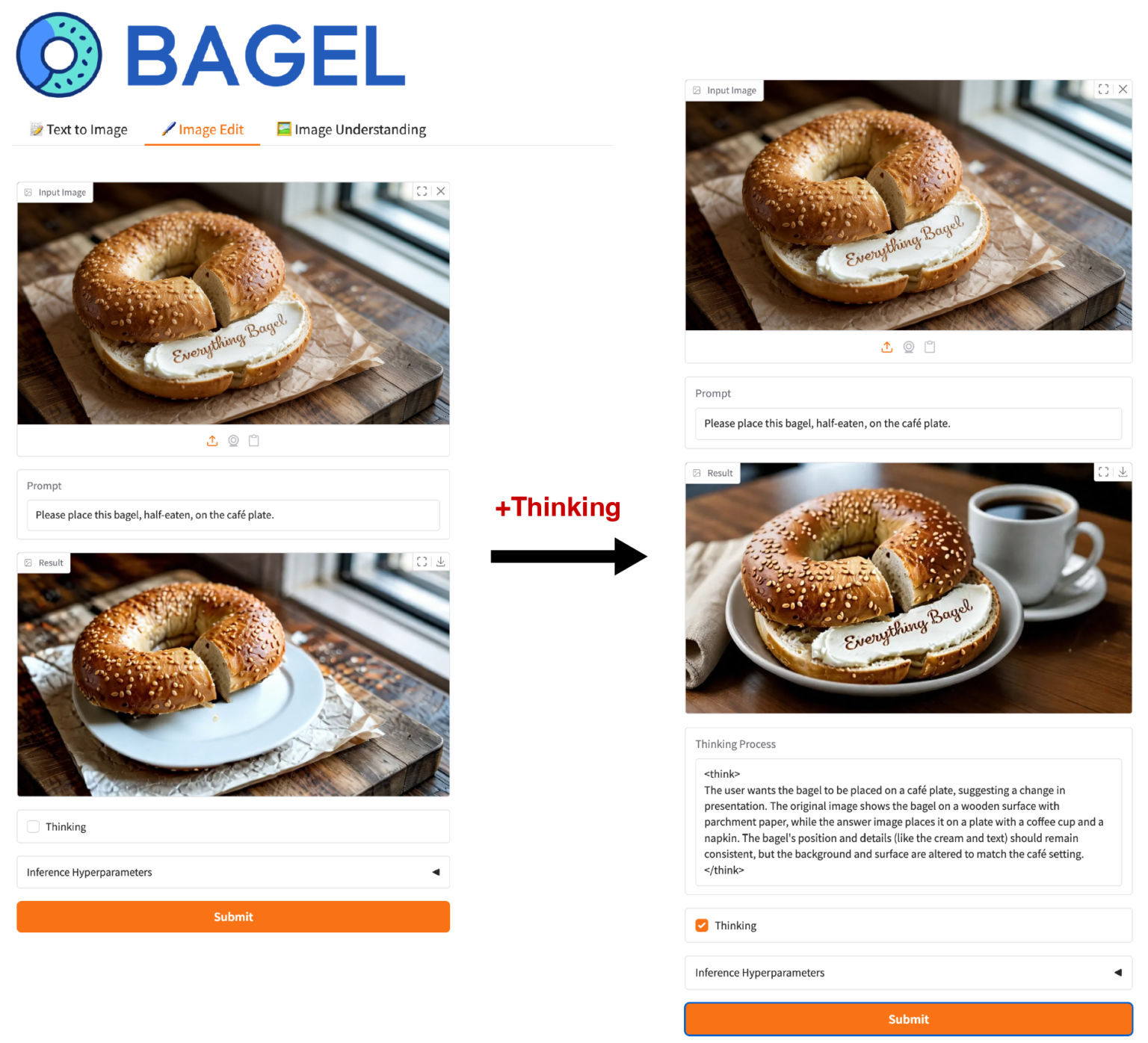
BAGEL: ByteDanceの画像生成・編集も可能なマルチモーダル統合オープン生成AI
- 2025年5月20日 ByteDance 「BAGEL」発表
- 2025年6月10日 ブログ公開
「BAGEL」はByteDanceが公開したマルチモーダル統合型の生成AIです。画像やテキストという複数のモダリティを統合して処理、LLMの知識を利用した画像生成や編集が可能です。BAGELは更に、Thinkingモードが搭載され、長考により高度な推論や生成が可能です。
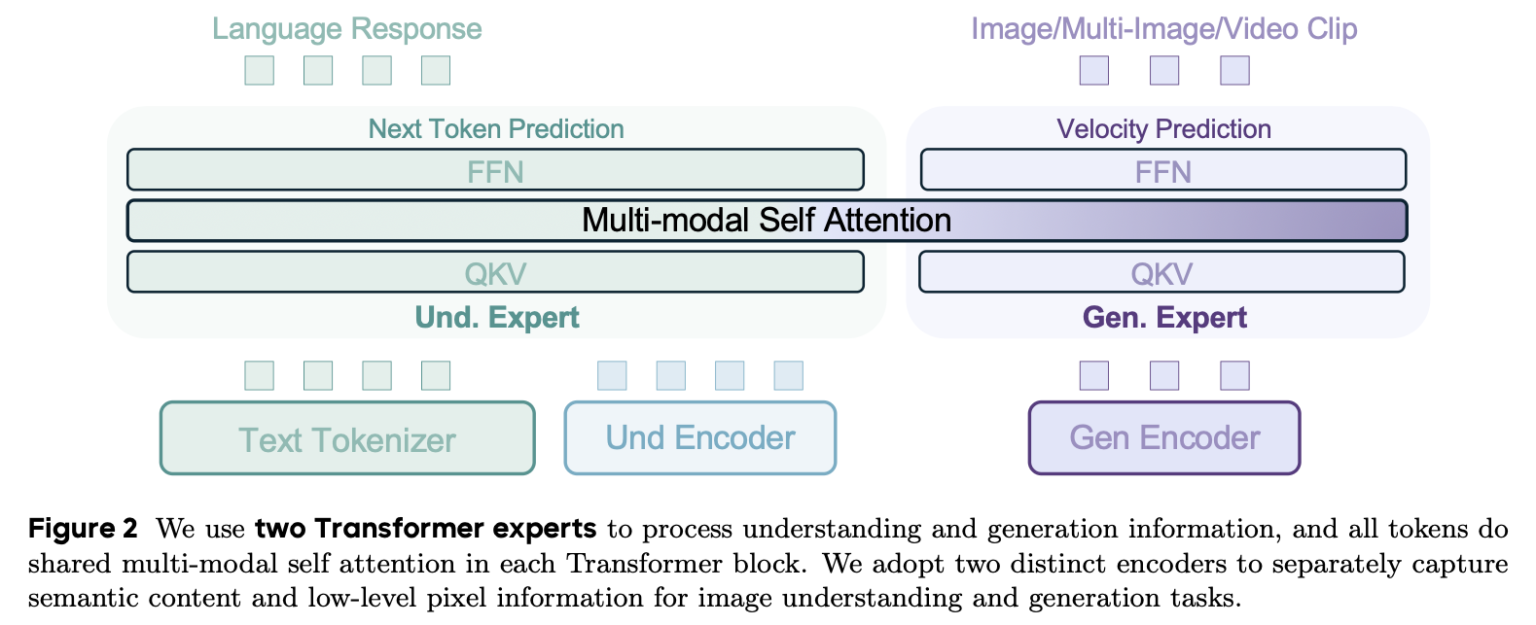
ブログでは、公開されたBAGELモデルを使って、実際に画像生成や編集を試してみました。BAGELは量子化なしの場合、32GB以上のVRAMが必要ですが、量子化すると12GB以上のVRAMで動作可能です。
後日談: HyperBagelの発表
ByteDanceは、9月23日に「Hyper-Bagel」を発表しました。生成が大幅に高速化されているそうですが、技術仕様のみでモデルは未公開となっております。
OpenAIのGPT Image 1 APIで入力画像に高い忠実度(high input fidelity)の画像生成を試してみた
- 2025年4月23日 OpenAI 「gpt-image-1 API」発表
- 2025年7月17日 OpenAI 「high fidelity mode」の提供開始
- 2025年7月23日 ブログ公開
OpenAIは、文字表現などが強化された画像生成機能を「gpt-image-1」としてAPI提供を4月下旬に開始しました。これを更に入力画像への忠実度を高める「high fidelity mode」を7月中旬に追加しました。このAPIの利用には免許証などの身分証とWebカメラで顔認証による本人確認が追加で必要となります。
ブログではhigh fidelity modeによる画像生成・編集を試して、Black Forest LabsのFLUX.1 KontextやGemini(当時はImagen 4)と比較しました。入力したアイテムや人物などの特徴をどの程度忠実に再現できるかを比較したところ、GPT Image 1のhigh fidelity modeは非常に高い忠実度で再現できました。

後日談: Nano BananaとFLUX.2の発表
当時、Gemini (Imagen 4)は、OpenAIのGPT Image 1と比較して忠実度が低い印象でしたが、その後のアップデート(Nano Banana/Nano Banana Pro)で大きく改善されました。また、Black Forest Labsも、2025年11月26日には、「FLUX.2」を発表してモデルの改良を進めています。
LangExtract: Gemini駆動でテキストからデータ抽出できるGoogleのPythonライブラリ
- 2025年7月30日 Google 「LangExtract」発表
- 2025年8月12日 ブログ公開
「LangExtract」は、Googleが公開したLLMを利用した非構造化データから情報抽出するPythonライブラリです。データ分析業務では常に綺麗な構造化データがあると限らず、その場合、非構造化データからの情報抽出が必要です(面倒で辛い作業です)。LangExtractは、その種のタスクを簡単に実行できるように設計されています。
LangExtractでは、プロンプトでタスク定義、抽出したいデータの構造を例示してます。結果は構造化された形式とテキストの何処から抽出されたのかが可視化されます。ブログでは、ニュース記事からの経済指標の数値などの情報抽出や長い売上レポートからの、月次の売上数字の抽出などを試してみました。
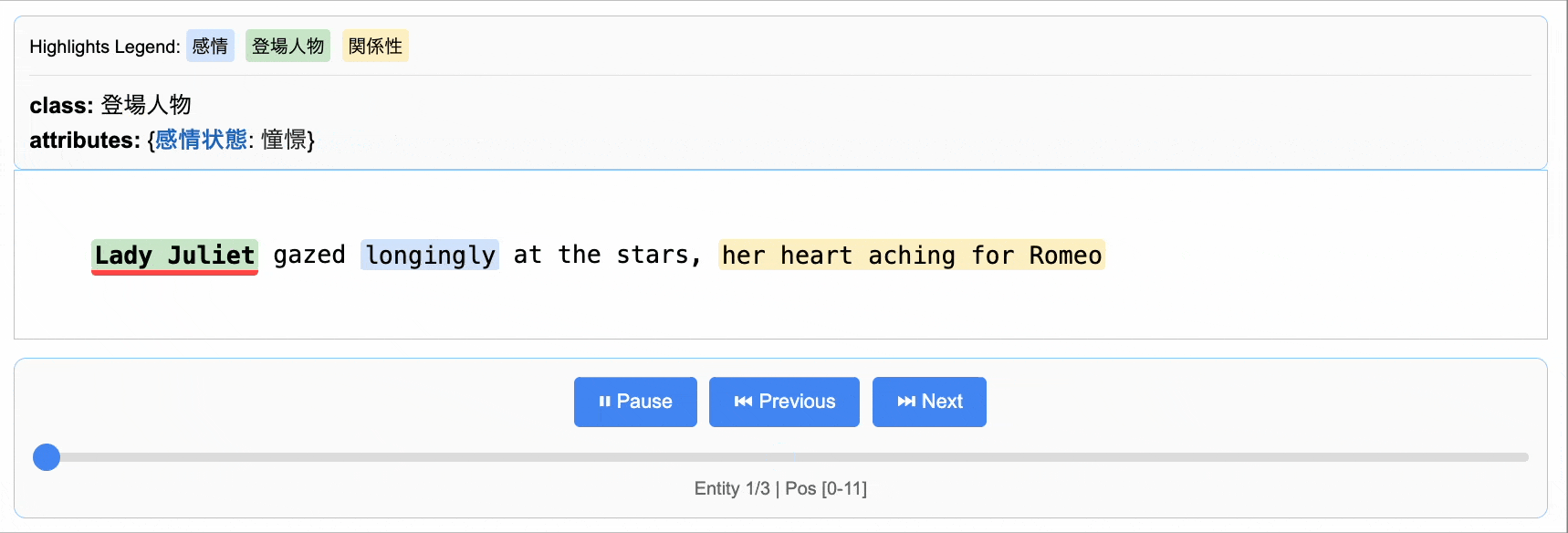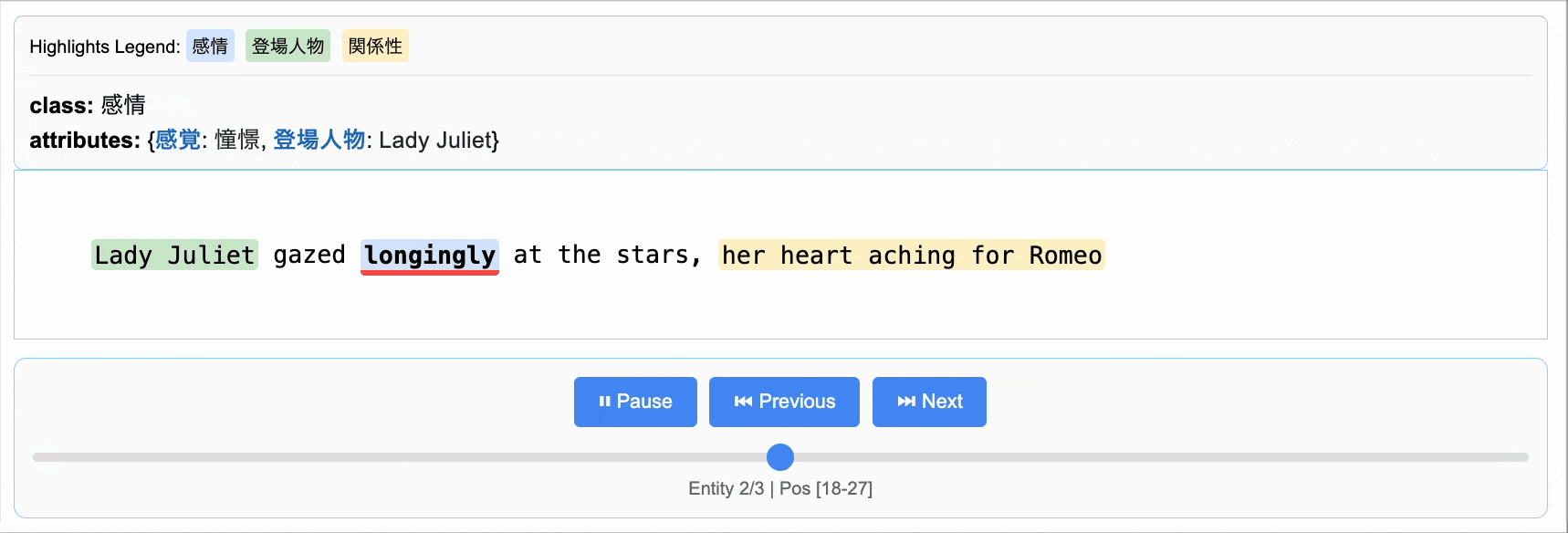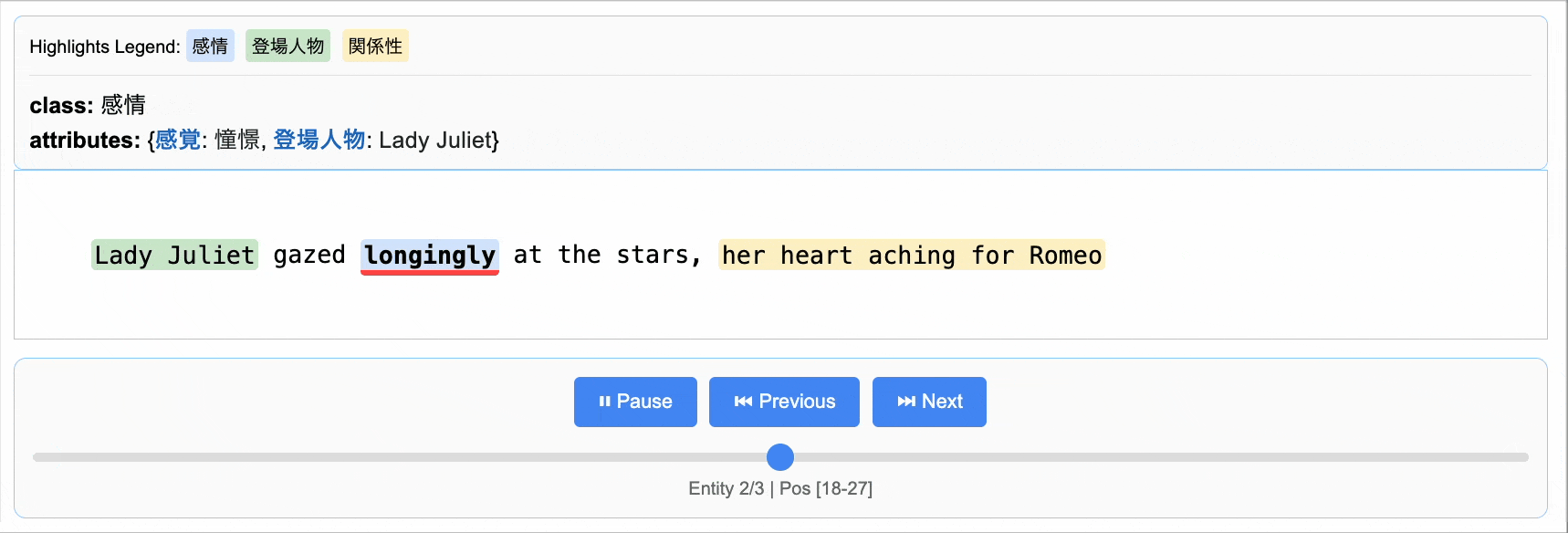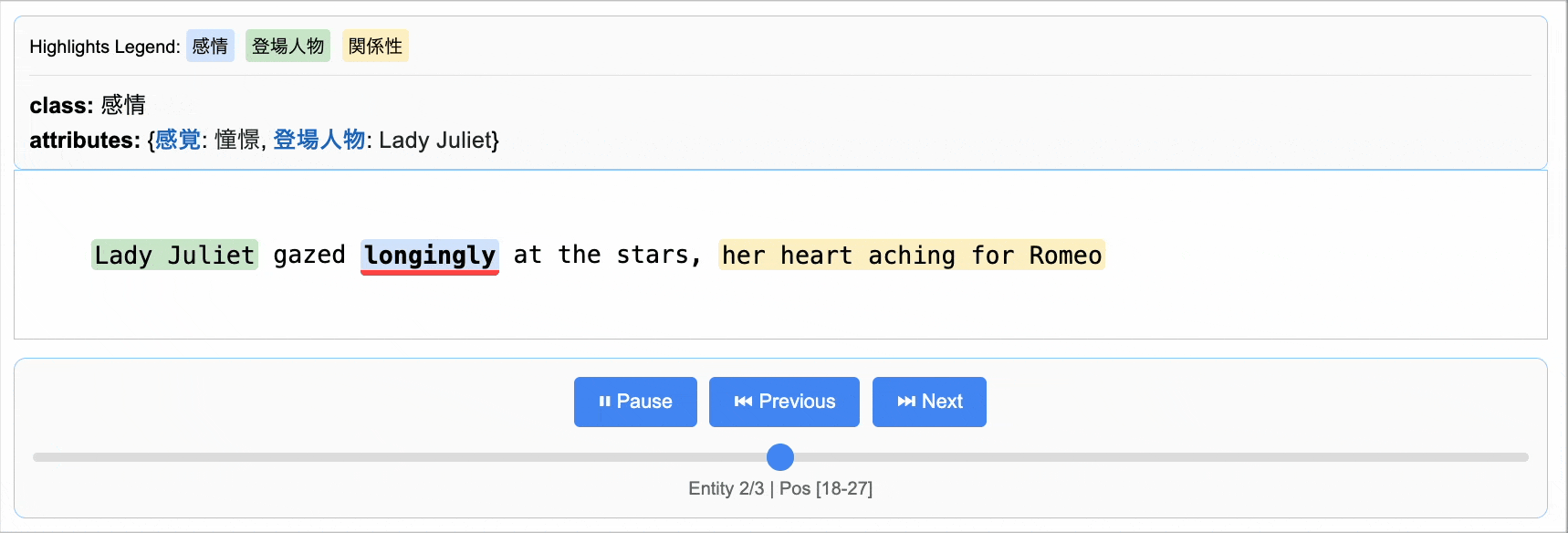
Nano Banana: Gemini 2.5 Flash Image(とQwen-Image-Edit)で画像生成・編集を試してみた
- 2025年8月19日 Alibaba 「Qwen-Image-Edit」発表
- 2025年8月26日 Google 「Nano Banana」発表
- 2025年9月1日 ブログ公開
さて、OpenAIのGPT Image 1 APIの高い忠実度の実験の際、Geminiの性能は今ひとつという印象を持ちました。しかし、Googleの新たに発表した「Gemini 2.5 Flash Image(通称Nano Banana)」で性能は大きく改善されました。また、同時期に、Qwen-Imageを画像編集用に改良した「Qwen-Image-Edit」も発表されています。この記事ではこれらの画像生成・編集モデルを実際に試してみました。

後日談: Qwen-Image-Edit-2509とNano Banana Proの発表
Nano Bananaについては、すぐに紹介するようにGemini 3 Proに組み込まれた「Nano Banana Pro」が登場し、更に、画像生成・編集の自由度や表現性、品質が向上しました。また、Qwen-Image-Editを複数の画像入力などに対応した「Qwen-Image-Edit-2509」が9月23日に公開されました。
Gemini CLI extensionsでNano Bananaを使ってみた〜バイブコーディングな画像生成・編集〜
- 2025年6月25日 Google 「Gemini CLI」発表
- 2025年10月8日 Google 「Gemini CLI extensions」発表
- 2025年10月14日 ブログ公開
さて、昨今、AIエージェントの開発が盛んになっています。Googleも「Gemini CLI」というオープンソースのAIエージェントフレームワークを6月に発表しました。その追加機能として、10月に「Gemini CLI extensions」が発表されました。これはMCPサーバーとカスタムコマンドとそのコンテキストファイルなどの技術要素からなるもので、AtlassianやFigmaなどの複数のパートナー企業がextensionsを公開しております。
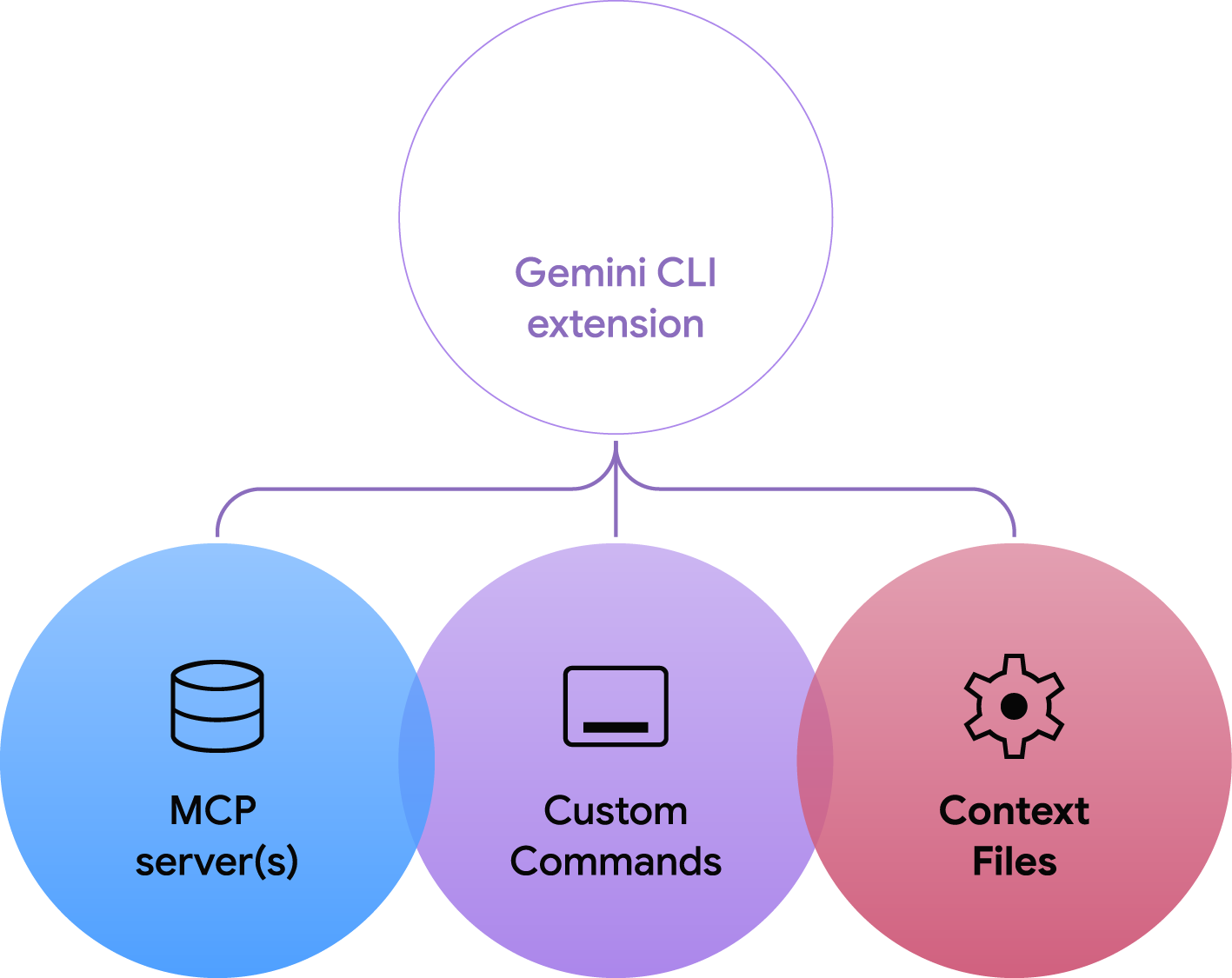
このブログでは、Gemini CLIを利用したデータ分析環境の構築とEDAのデモ、また、Nano Banana extensionを利用した画像生成・編集のデモを紹介しました。
$ gemini
███ █████████ ██████████ ██████ ██████ █████ ██████ █████ █████
░░░███ ███░░░░░███░░███░░░░░█░░██████ ██████ ░░███ ░░██████ ░░███ ░░███
░░░███ ███ ░░░ ░███ █ ░ ░███░█████░███ ░███ ░███░███ ░███ ░███
░░░███ ░███ ░██████ ░███░░███ ░███ ░███ ░███░░███░███ ░███
███░ ░███ █████ ░███░░█ ░███ ░░░ ░███ ░███ ░███ ░░██████ ░███
███░ ░░███ ░░███ ░███ ░ █ ░███ ░███ ░███ ░███ ░░█████ ░███
███░ ░░█████████ ██████████ █████ █████ █████ █████ ░░█████ █████
░░░ ░░░░░░░░░ ░░░░░░░░░░ ░░░░░ ░░░░░ ░░░░░ ░░░░░ ░░░░░ ░░░░░
Tips for getting started:
Ask questions, edit files, or run commands.
Be specific for the best results.
/help for more information.
Using: 2 open files (ctrl+g to view) | 1 GEMINI.md file | 1 MCP server (ctrl+t to view)
> いいかんじのコアラのアイコンを作成してください
✓ generate_icon (nanobanana MCP Server) {"style":"modern","prompt":"A cute and friendly koala","background":"transparent","sizes":[16,32…
Successfully generated 6 image variation(s)
Generated files:
/Users/TI/Documents/gemini-cli-eda-demo/nanobanana-output/a_cute_and_friendly_koala_modern.png
/Users/TI/Documents/gemini-cli-eda-demo/nanobanana-output/a_cute_and_friendly_koala_modern_1.png
/Users/TI/Documents/gemini-cli-eda-demo/nanobanana-output/a_cute_and_friendly_koala_modern_2.png
/Users/TI/Documents/gemini-cli-eda-demo/nanobanana-output/a_cute_and_friendly_koala_modern_3.png
/Users/TI/Documents/gemini-cli-eda-demo/nanobanana-output/a_cute_and_friendly_koala_modern_4.png
/Users/TI/Documents/gemini-cli-eda-demo/nanobanana-output/a_cute_and_friendly_koala_modern_5.png
✦ コアラのアイコンを6種類作成しました。ファイルは nanobanana-output ディレクトリに保存されています。また、定義されているカスタムコマンドの/generateや/editコマンドなどをを使ってより詳細に画像生成・編集の指示も可能です。
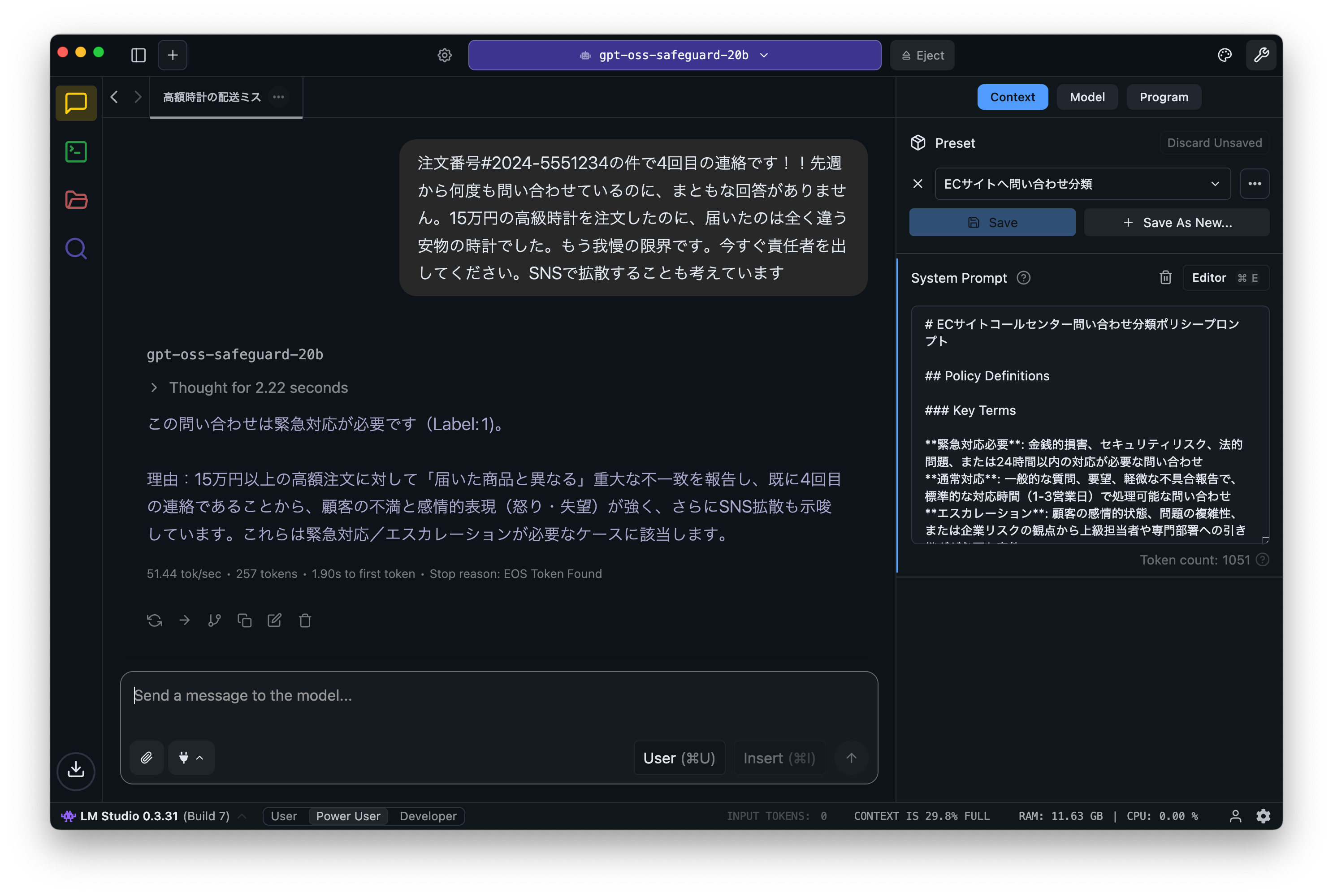
gpt-oss-safeguard: OpenAIのポリシーベースのテキスト分類専用の推論型オープンモデル
- 2025年8月5日 OpenAI 「gpt-oss」発表
- 2025年10月29日 OpenAI「gpt-oss-safeguard」発表
- 2025年11月5日 ブログ公開
OpenAIは、8月に「gpt-oss」というオープンウェイトモデルを公開しました。これはgpt-oss-120bとgpt-oss-20bの2つのモデルからなり、後者の小型モデルであれば16GBのVRAMで動作します。性能は、前者はOpenAIのo4-mini、後者はo3-miniと同等の性能を持つとされています。Apache 2.0ライセンスでウェイトが公開されており、ファインチューニングも可能です。「gpt-oss-safeguard」は、gpt-ossモデルをベースとしてOpenAIのポリシーベースのテキスト分類タスクに特化した推論型オープンモデルです。
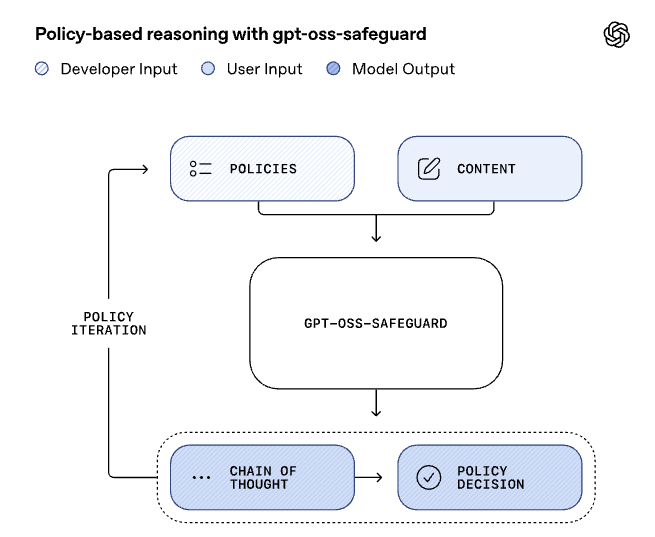
このブログでは、LM Studioを利用してgpt-oss-safeguardの利用方法とECサイトへの問い合わせを分類する例などを紹介しました。
Nano Banana Pro (Gemini 3 Pro Image)で画像生成・編集をやってみた
- 2025年11月20日 Google 「Nano Banana Pro」発表
- 2025年11月25日 ブログ公開
さて、すでに紹介したNano Bananaの時点で画像生成・編集機能の高さは圧倒的に感じておりましたが、更にGoogleではGemini 3 Proに組み込まれた「Nano Banana Pro」を発表しました。Gemini 3 Proの推論能力を活かして、より熟考し画像を生成・編集します。元のNano Bananaよりも更に表現力豊かな画像が生成可能です。

ブログでは、Nano Banana ProをPythonからGemini APIやGoogle AI Studioを利用し、画像を編集する例を紹介しました。Nano Banana Pro では、4Kまでの高解像度の画像や最大14枚までの画像入力が可能です。入力画像のうちで人物なら5名まで、アイテムなら6個まで一貫性を保って生成できます。

また、Google検索と連動させリアルタイム情報を反映した画像生成も可能です。

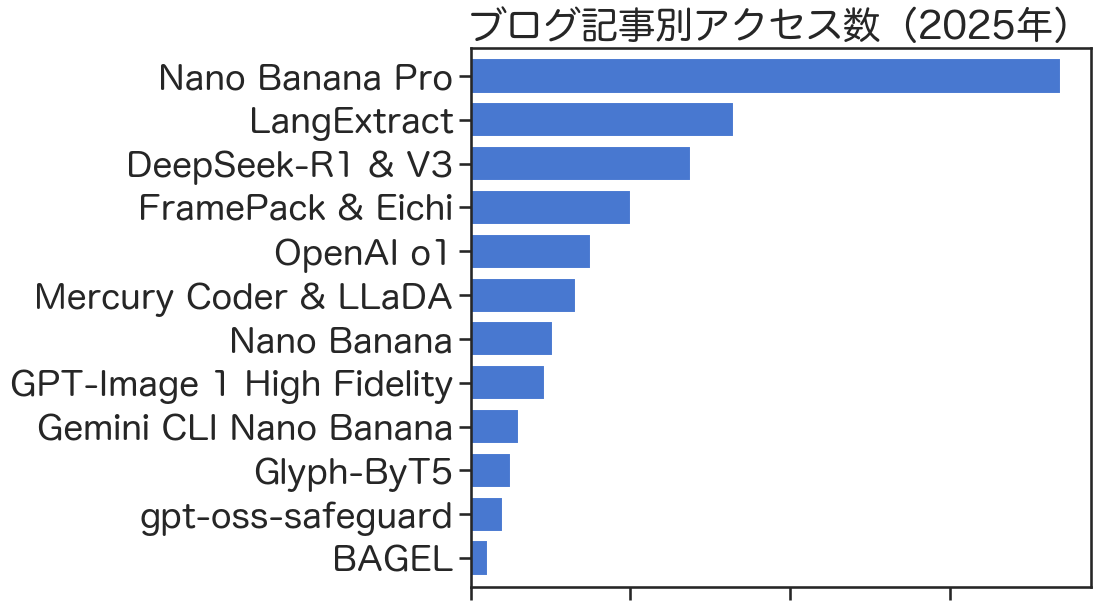
後日談:ブログのアクセス数が、とてつもない量となりました
Nano Banana Pro の画像生成能力の高さから様々な界隈で話題となっている上に、ブログ公開が Nano Banana Proの登場直後ということもあり、この記事のアクセス数がこれまでに見たことがないレベルで増えました(具体的な件数は秘密ですが)。恐るべしはNano Banana Proですね。
まとめ
なんだかんだと、今年一年も所謂生成AIに振り回された感がありますね。画像生成に関しては、予想以上の発展を遂げました。文字表現の強化やLLMとの統合されたマルチモーダル化による生成画像の品質の向上、そして、GPT Image 1やNano Banana(Pro)のような一貫性の高い画像生成・編集モデルの登場など、非常に興味深い一年でした。
ブログの著者欄
T.I.
GMOインターネットグループ株式会社
GMOインターネットグループ・グループ研究開発本部・AI研究開発室。シニアデータサイエンティスト兼アーキテクト。金融やネット広告、生命科学といった幅広いデータ解析業務に関わる。
採用情報


関連記事
-

【中編】Hack-1グランプリ2026 デモデーレポート|ついにグランプリ決定!最優秀賞チームに開発秘話を聞く
デザイン
-

【前編】Hack-1グランプリ2026 デモデーレポート|AI時代の学生ハッカソンに圧倒される2日間。「小さくなる日本」をどう表現する?
デザイン
-

【インタビュー後編】育休明けに直面した「AI時代」 GMOペパボのプリンシパルデザイナー・佐藤咲が歩む「共創」の道
デザイン
-

【後編】エージェンティックAIの「アウトプット品質安定化」を実現 GMOインターネットが実践する「ハーネスエンジニアリング」とは?ーEngineering Journey
技術情報
-

ハーネスエンジニアリングの本質 ー従来の開発規律を、エージェントが回せるように再設計する
技術情報
-

【前編】エージェンティックAIの「アウトプット品質安定化」を実現 GMOインターネットが実践する「ハーネスエンジニアリング」とは?ーEngineering Journey
技術情報

KEYWORD
CATEGORY
-
技術情報(590)
-
イベント(233)
-
カルチャー(59)
-
デザイン(67)
TAG
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI TALK
- AI 機械学習強化学習
- AI/機械学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI活用事例
- AI駆動
- AMD
- APT攻撃
- AWX
- Behind the Scenes
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- ConoHaVPS
- CS
- CSS
- CTF
- DC
- Designship
- Desiner
- developer
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- engineering
- Engineering Journey
- eVTOL
- expert
- EXPERT CROSS
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOインターネットグループ陸上部 – GMOロボッツ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- Good Morning
- GPU
- GPUクラウド
- GTB
- Hack-1グランプリ
- Hack‐1グランプリ
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- Japan Drone
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- エージェンティックAI
- オブジェクト指向
- オンボーディング
- お名前.com
- クリエイター
- クリエイターインタビュー
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ハーネスエンジニアリング
- バックエンド
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- フロントエンド
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- ロボティクス
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 技術書典20
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 映像制作
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 空飛ぶクルマ
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-

【後編】デザイナーとしての自分を形作る「気合と反復」。対話を通じて実践する、豊田恵二郎の制作哲学
デザイン
-

【前編】創業時から変わらない「一貫性」で業界をリード GMO Flatt Security CCO・豊田恵二郎が語る、「エンジニアの背中を預かる」姿勢
デザイン
-

【第2回・AI TALK】GMOサイバーセキュリティ byイエラエ・三村 聡志さんに聞く、AI時代の攻撃と防御のいま
技術情報
-
【中編】Hack-1グランプリ2026 デモデーレポート|ついにグランプリ決定!最優秀賞チームに開発秘話を聞く
デザイン
-
【前編】Hack-1グランプリ2026 デモデーレポート|AI時代の学生ハッカソンに圧倒される2日間。「小さくなる日本」をどう表現する?
デザイン
-

【Expert Cross #1】“人生2周目”のエキスパートが挑む、「つながり」の構築と認知拡大
技術情報
採用情報
SNS FOLLOW
