
こんにちは。GMOインターネットグループ株式会社の新里です。
グループ会社でもあるワイン屋さんのシステム開発に関わることになりました。前回のvol.01ではレガシーシステムからの入替えについて書きましたが、今回はワインのラベルについての取組みについて、その一部をご紹介します。
目次
ワインラベル(エチケット)
ワインのラベルは色々なデザインがされていて千差万別です。このラベルはフランスではエチケットと読む(ラベルは英語読み)そうで、名称・収穫年・ブドウ品種…など、多くの情報が記載されています。
僕はそれほどワインに詳しい訳では無いですが、趣向を凝らしたラベルのデザインは見ていて飽きないですね。例えば、シャトームーン・ロスチャイルドのラベルはミロ、シャガール、ピカソといった作家がデザインをしていたりもします。
他にもラベルを見ていて気になったのが、


他にも探してみると、好みのラベルが見つかるかも知れません。昔よくあった、CDのジャケ買いのような感じで、ラベルを見てワインを買うといった事もあるかも知れません。
ラベルからワインを推定
ワイン屋さんでは販売するワインの写真を撮っていてデータとして残ってあります。この画像を使わない手は無いですね。
ワインのラベルから銘柄を機械学習で推定して、一般ユーザーが気軽にチェックしたり、在庫チェックのときにも利用するといった事が考えられます。このワインのラベルから銘柄・産地・ブドウの品種といった詳細情報を検索、一般ユーザーの評価といった情報を見る先行アプリは既にあるので、恐らく同様のことはできるはずです。
調べてみたところ、機械学習の画像マッチの他にもラベルの文字を読み取ることもある程度可能なことも分かりました(wine label reader toolkit, How to read a label on a wine bottle using computer vision ?)。ワインのラベルを正面から写真を取ると、上下が湾曲して歪むため、補正をかけてOCRとして読み取れるようにする、といった感じです。

ただし、ワインのラベルは必ずしも湾曲している物だけでは無いうえに、年数が経って読み取れない物もあったりします。そこで、とりあえずは画像のみの機械学習でワインのラベルを推定してみようと思います。
ラベルをクラス分け
大量のワインラベルの画像をパッと見た感じでは、ほとんど別々な気はしますが、同じようなデザインで分類できるのかもしれない?という期待がありました。そこで、k-meansでラベルの分類が可能か試してみます。
ラベル画像は189種銘柄、1600枚のラベル画像を対象にして、SqueezeNetを利用して特徴点を抽出、エルボー法で分類可能なクラス数をチェックしてみます。
from google.colab import drive
drive.mount('/content/drive')
!pip install torchinfo
import torch
import matplotlib.pyplot as plt
import glob
import cv2
import os
import torchvision.models as models
import torchvision
from torchvision import transforms
from PIL import Image
from sklearn.cluster import KMeans
pointmodel = torch.hub.load('pytorch/vision:v0.10.0', 'squeezenet1_0', pretrained=True)
pointmodel.fc = torch.nn.Identity()
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
if torch.cuda.is_available():
pointmodel.to('cuda')
features_data = []
files = glob.glob("/content/drive/MyDrive/label/*/*.jpg")
for f in files:
input_image = Image.open(f)
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
with torch.no_grad():
output = pointmodel(input_batch)
n = output.to('cpu').detach().numpy().copy()
features_data.append(n.reshape(-1, 2048)[0].tolist())
wcss = []
for i in range(1, 100):
kmeans = KMeans(n_clusters = i, max_iter = 300, n_init = 10, random_state = 0)
kmeans.fit(features_data)
wcss.append(kmeans.inertia_)
plt.figure(figsize=[100,20])
plt.plot(range(1, 100), wcss)
plt.grid()
plt.show()
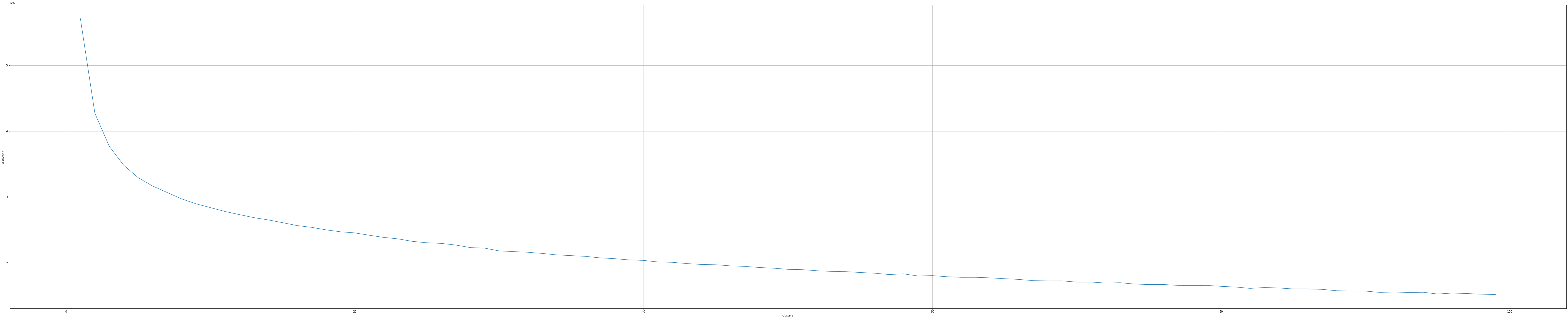
なーんか、微妙に収束してくれません。勢いで100クラスタくらいでやってもみましたが、かなり微妙な感じです。以前、広告のクリエイティブで似たようなクリエイティブとコンバージョンの関係について調べたことがあって、同様に似たようなラベルのクリエイティブで分類が出来るかしら?と想定したのですが(クリエイティブによって得られるコンバージョンの推定を行う感じですね)、手持ちのワインラベルのデータではちょっと無理筋そうです。
そこで、単純に特徴点を使ったラベル検索をしてみます。
Elasticでラベル検索
よくある(類似)画像検索ではFaissを使った例を見かけます。実はラベル画像検索でもFaissを使って検証はしていますが、他にも何かないかな?と思って調べてみたら、ElasticにANN(approximate nearest neighbor search)という機能が入っていました。
近隣ベクトル探索をL2 NORM, COS類似度など実行してくれます。ただ次元数は1024が最大ですが、インデックスの入れ替え・elastic上で使えるという運用上のメリットもあるので、とりあえず動かしてみます。
まずはマッピングは SqueezeNetに合わせて1000次元にして、同じくファイル名を登録しておきます。
curl -H 'Content-Type: application/json' -XPUT http://localhost:9200/wine_label -d '{
"mappings": {
"properties": {
"image_vector": {
"type": "dense_vector",
"dims": 1000,
"index": true,
"similarity": "l2_norm"
},
"file_name" : {
"type": "text"
}
}
}
}'次にデータの登録です。1000次元の特徴点(features_data)をラベル画像のファイル名と一緒に登録します。ちなみに、dense vectorの最大は1024次元ですが、mappingでは2048次元といった値も登録できます(最大は2048次元でindexなしです。ただ…indexなしだと近隣検索が出来ないので対象外になりますが)。その場合、bulid(or create)でデータを登録するときにexceptionが発生します。
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
client = Elasticsearch("http://localhost:9200")
def index_batch(f, i):
doc = [{
"_op_type": "index",
"_index": "wine_label",
"image_vector": i,
"file_name": f,
}]
bulk(client, doc)
for i, f in enumerate(files):
index_batch(f, features_data[i])最後にelasticに向けて検索を実行します。
input_image = Image.open("label_13.jpg")
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
# GPUに転送
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
# 推論実行
with torch.no_grad():
output = pointmodel(input_batch)
n = output.to('cpu').detach().numpy().copy()
display(input_image.resize((200, 200)))
query = {
"field": "image_vector",
"query_vector": n[0].tolist(),
"k": 10,
"num_candidates": 100
}
res = client.knn_search(index='wine_label', knn=query, source=["file_name"])
f = [d.get('_source') for d in res['hits']['hits']]
show_image_files([d.get('file_name') for d in f][:5])検索対象の画像(Benoit Lahaye, Champagne)

検索結果

検索画像(Jacquesson Champagne 744)

検索結果

それっぽくヒットしてはいますね。とりあえずElasitc ANNを使って特徴点ベクトルの近隣検索はできそうです。
ただし、使うにはもう少しかなぁ…と思うのが、次元数の最大が1024なので、これに合わせて次元の調整が必要になってくるという所ですね。FaissはGPUが使えて便利ですが、Elasticでは分散させてどうか?という所が今後の調査ポイントになってきそうです。
ブログの著者欄
新里 祐教
GMOインターネットグループ株式会社
プログラマー。GMOインターネットグループにて開発案件・新規事業開発に携わる。またオープンソースの開発や色々なアイデアを形にして展示をするなどの活動を行っている。
採用情報


関連記事







KEYWORD
CATEGORY
-
技術情報(575)
-
イベント(220)
-
カルチャー(55)
-
デザイン(58)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- GPU
- GPUクラウド
- GTB
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-

クレジットカード不正利用と戦う!秘密計算×AIの挑戦 — IPSJ-ONE 2026 登壇レポート
技術情報
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート後編】
イベント
-

【2025国際ロボット展 出展レポート】AI ❤ ROBOTs で描く、人とロボットが共存する社会
技術情報
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート前編】
イベント
-

【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-

ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
採用情報
SNS FOLLOW
