
こんにちは。GMOインターネットグループ株式会社の新里です。
最近はDALL・E 2、Midjourney、Stable Diffusionなどを使って画像を自動生成するのはよく見かけますね。他にもOpenAIが出したChatGPTでテキストで対話するモデルだったり、機械学習は本当に日進月歩で進んでいるように感じます。ここでは、OpenAIが2022年末に公開したPoint-Eを使って、テキストから3Dモデルを生成してみます。
目次
テキストから3Dを生成~3Dプリンタで印刷
入力としてテキストから3Dモデルを生成するものは色々ありました。
Point-E (OpenAI)、Dream Fusion(Google)、Magic3D(NVIDIA)などですね。GoogleはImagen(Text to Image)のモデルは公開していないので、Stable Diffusionを利用したStable Fusionというのも公開されていました。
ここではPoint-Eを使って3Dモデルを生成、さらにそのモデルを3Dプリンタで印刷する所までやってみます。
Point-Eのコード
お手軽にGoogle Colab上でPoint-Eを動かしてみます。githubにサンプルコードがあるので、そのままGoogle Colabに持ってくれば動きました。テキストから点群を作ってくれるのは text2pointcloud.ipynb ですね。あと、メッシュにする pointcloud2mesh.ipynb を使えばPLYファイルを生成・OBJなどに変換して3Dプリンタで印刷できそうです。
どちらのコードも非常にシンプルでマージしてしまえば、サクッと動かせそうです。
!pip install -U scikit-image
!pip install git+https://github.com/openai/point-e
!nvidia-smi
import torch
from PIL import Image
from tqdm.auto import tqdm
import matplotlib.pyplot as plt
from point_e.diffusion.configs import DIFFUSION_CONFIGS, diffusion_from_config
from point_e.diffusion.sampler import PointCloudSampler
from point_e.models.configs import MODEL_CONFIGS, model_from_config
from point_e.util.plotting import plot_point_cloud
from point_e.models.download import load_checkpoint
from point_e.util.pc_to_mesh import marching_cubes_mesh
from point_e.util.point_cloud import PointCloud
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# モデル群をダウンロード
base_name = 'base40M-textvec'
base_model = model_from_config(MODEL_CONFIGS[base_name], device)
base_model.eval()
base_diffusion = diffusion_from_config(DIFFUSION_CONFIGS[base_name])
upsampler_model = model_from_config(MODEL_CONFIGS['upsample'], device)
upsampler_model.eval()
upsampler_diffusion = diffusion_from_config(DIFFUSION_CONFIGS['upsample'])
base_model.load_state_dict(load_checkpoint(base_name, device))
upsampler_model.load_state_dict(load_checkpoint('upsample', device))
# 生成する点群の設定
sampler = PointCloudSampler(
device=device,
models=[base_model, upsampler_model],
diffusions=[base_diffusion, upsampler_diffusion],
num_points=[1024, 4096 - 1024],
aux_channels=['R', 'G', 'B'],
guidance_scale=[3.0, 0.0],
model_kwargs_key_filter=('texts', ''),
)
# "一人がけのソファで、ゆったりとした背もたれ" というプロンプト
prompt = 'One-person sofas with spacious backrests.'
# 3Dモデルの生成と表示
samples = None
for x in tqdm(sampler.sample_batch_progressive(batch_size=1, model_kwargs=dict(texts=[prompt]))):
samples = x
pc = sampler.output_to_point_clouds(samples)[0]
fig = plot_point_cloud(pc, grid_size=3, fixed_bounds=((-0.75, -0.75, -0.75),(0.75, 0.75, 0.75)))
# ここから点群をメッシュ化
name = 'sdf'
model = model_from_config(MODEL_CONFIGS[name], device)
model.eval()
model.load_state_dict(load_checkpoint(name, device))
mesh = marching_cubes_mesh(
pc=pc,
model=model,
batch_size=4096,
grid_size=128,
progress=True,
)
# PLYとして保存
with open('model.ply', 'wb') as f:
mesh.write_ply(f)生成された3Dモデル
出来たmodel.plyをダウンロードしてきて、ビューアーで見るとこんな感じになりました。
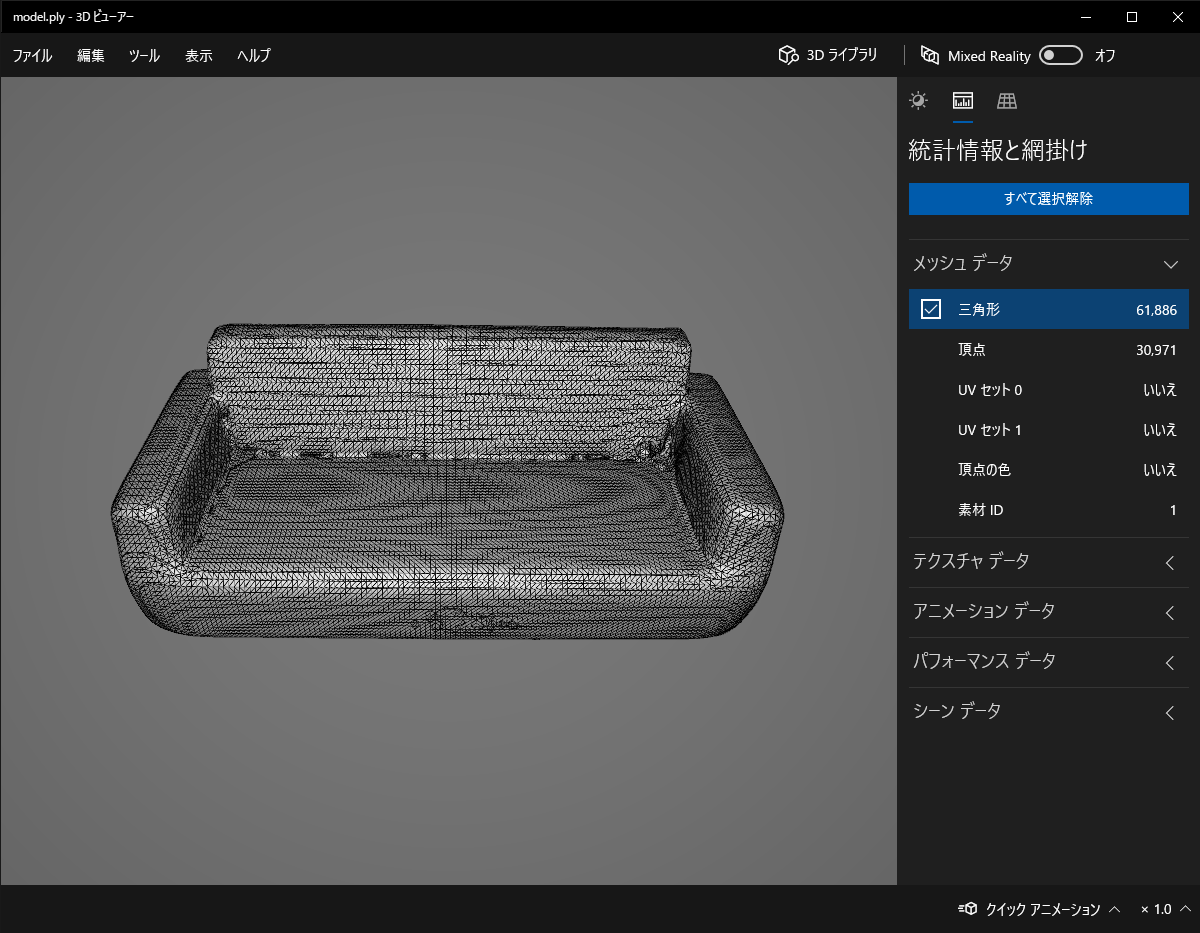
それっぽいソファーな感じですね。1人用のはずが、2人くらいは座れそうな気はしますが、良い感じです。
PLYをOBJ、STLにMeshLabなどで変換して3Dプリンタに与えてスライスします。
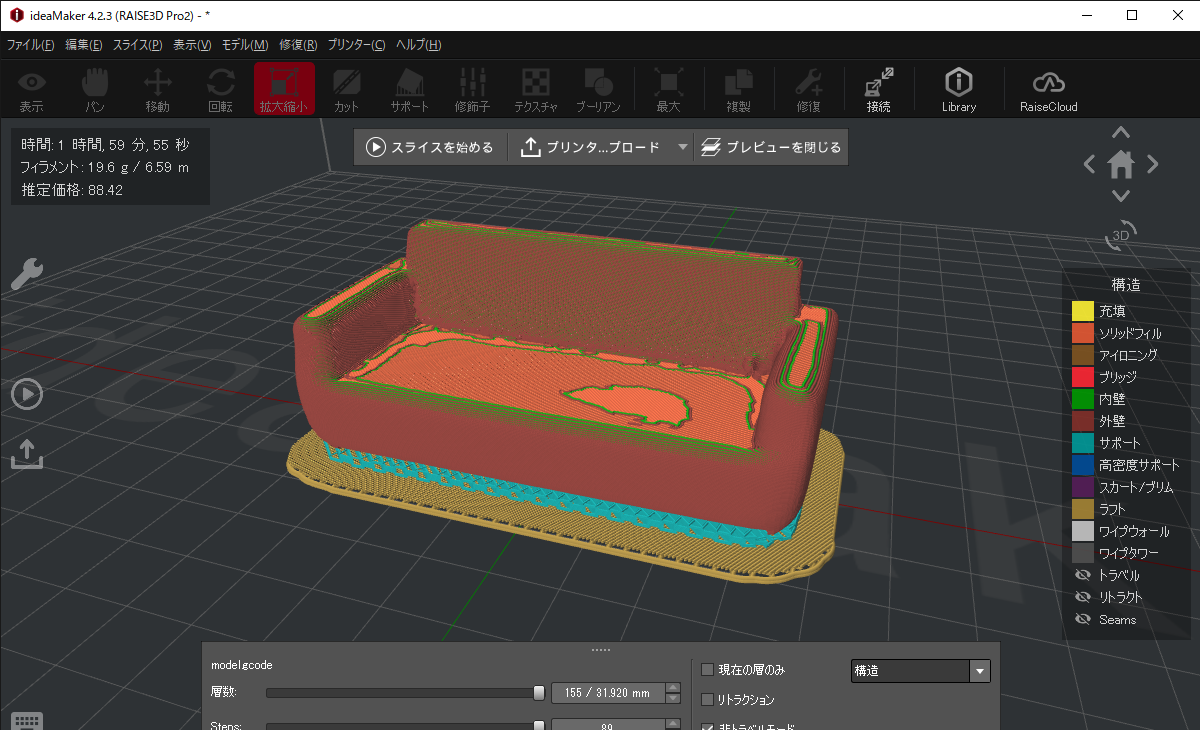
出来たもの
フィラメントは赤で出力したので、以下のような感じになりました。椅子の方は”2023年に流行るオシャな椅子”というプロンプトで出力したものです。

これからも期待
一応、プロンプトを与えて現物が出来るという所まで出来ましたが、複雑な構造などはまだ少し微妙です。例えば、これは「リンゴの形をした妖精」というプロンプトを与えたときのものです。
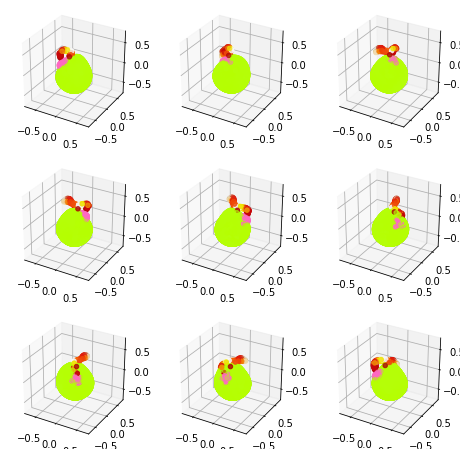
うーん、ちょっと何か微妙な感じがしますね。
ただ、「こんな物が欲しい・見てみたい」と指示をすると、画面上だけではなく、実際に現物・リアルな物として出力できるという世界線が近づいてきた感じがします。
ブログの著者欄
新里 祐教
GMOインターネットグループ株式会社
プログラマー。GMOインターネットグループにて開発案件・新規事業開発に携わる。またオープンソースの開発や色々なアイデアを形にして展示をするなどの活動を行っている。
採用情報


関連記事
-

【2025国際ロボット展 出展レポート】AI ❤ ROBOTs で描く、人とロボットが共存する社会
技術情報
-

【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-

ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

【イベントレポート・後編】GMO Developers Day 2025 -Creators Night-|共創するデザイン組織と次世代クリエイターの可能性
デザイン
-

【イベントレポート・中編】GMO Developers Day 2025 -Creators Night-|変化に挑むクリエイターのキャリアと成長
デザイン
-

【イベントレポート・前編】GMO Developers Day 2025 -Creators Night-|AI時代の「クリエイティブ」を探る夜
デザイン

KEYWORD
CATEGORY
-
技術情報(574)
-
イベント(219)
-
カルチャー(55)
-
デザイン(58)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- GPU
- GPUクラウド
- GTB
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-
【2025国際ロボット展 出展レポート】AI ❤ ROBOTs で描く、人とロボットが共存する社会
技術情報
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート前編】
イベント
-
【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-
ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

コールセンターでSpeech2Speech AIを繋ぐときに知っておきたい3つの接続方式
技術情報
-

ZTNAはVPNの代替にならない:失敗パターン3選と回避策
技術情報
採用情報
SNS FOLLOW
