
OracleとChatGPTを組み合わせて何か面白いことができないかと考え、データベース内に保存されたテーブル定義やレコードをChatGPTにインプットして様々な処理をさせるプロシージャを作成してみました。
目次
作るもの
こちらが今回作成するもので、スキーマ名とテーブル名、そしてそのテーブルに対して行いたい操作を入力すると、ChatGPTから回答が得られる作りになっています。
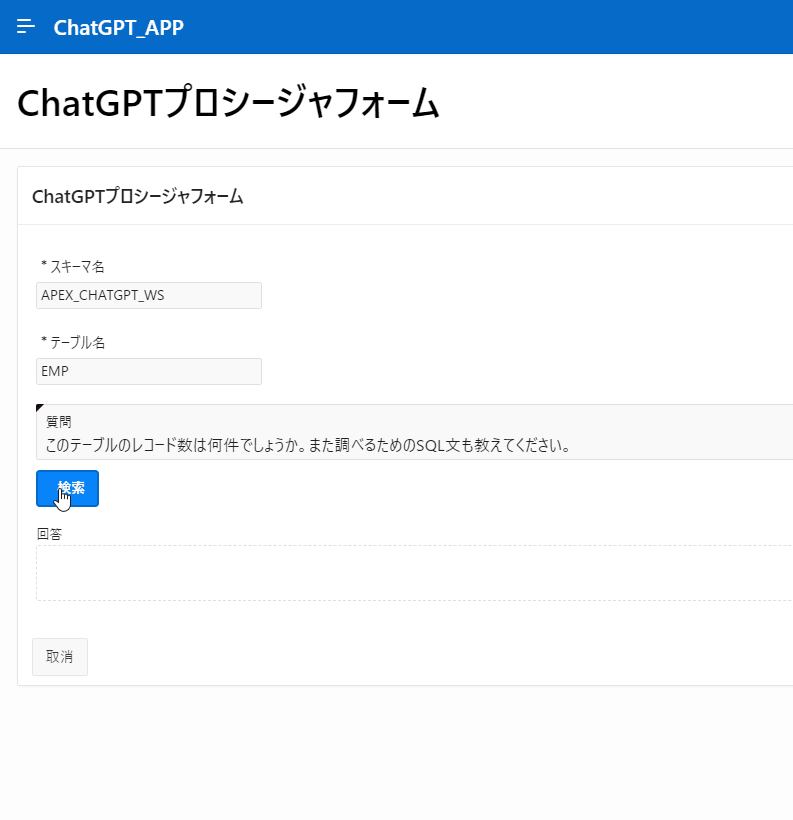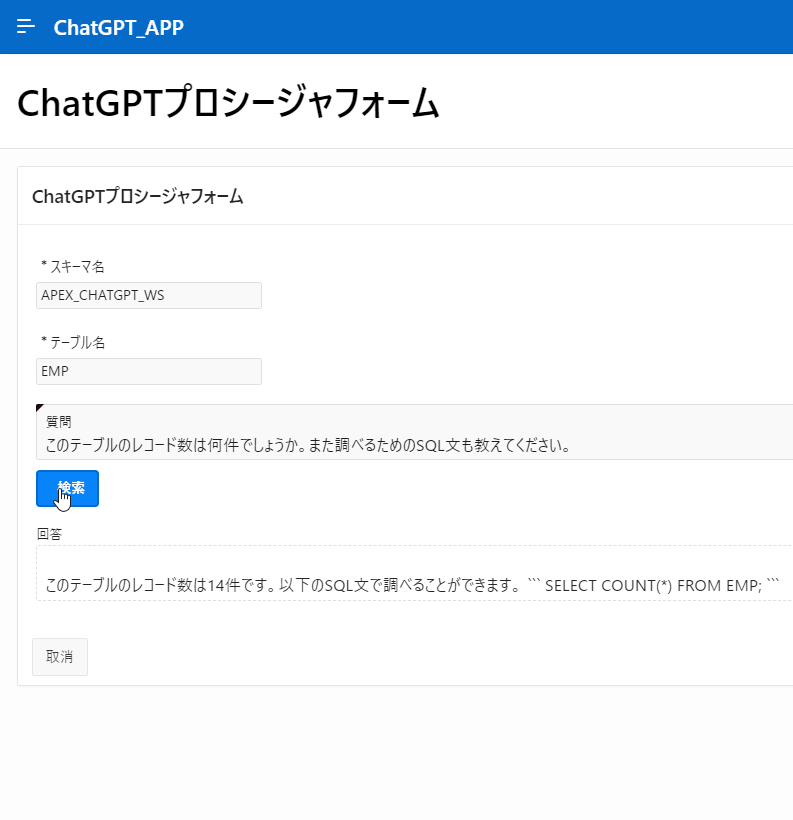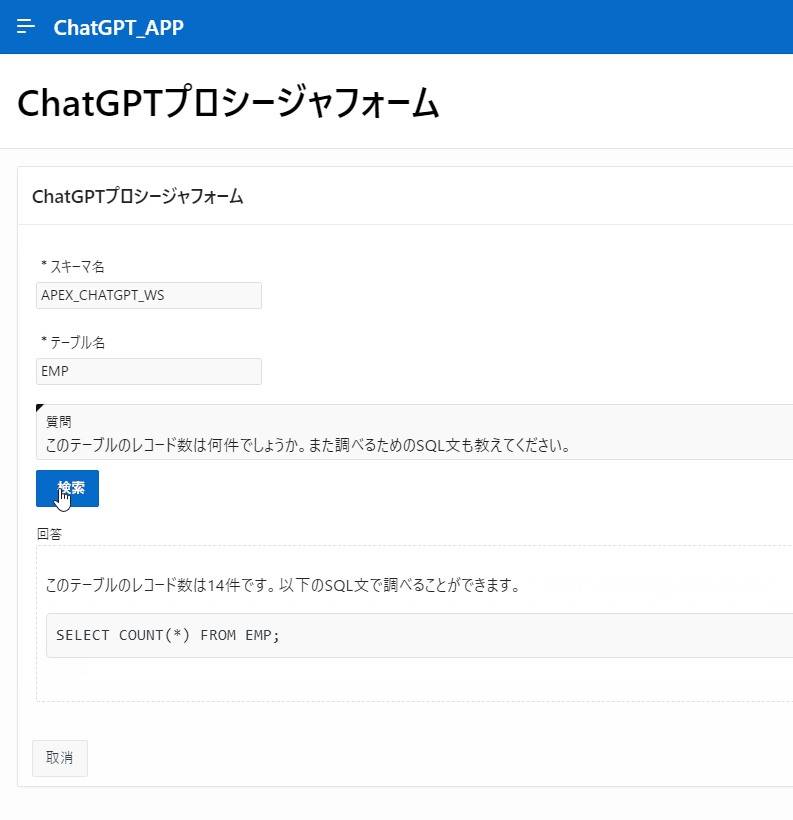
注意点、免責事項
本記事の情報は、筆者の個人的な見解や経験に基づくものであり、正確性、信頼性、完全性、最新性を保証するものではありません。本記事の情報やリンク先の内容によって生じた問題や損失について、筆者は一切の責任を負いません。本記事は予告なく内容が変更されることがあります。また、最新の情報については、他の情報源と照らし合わせて確認してください。利用者が本記事の情報に基づいて行った行為によって生じた損害について、筆者は一切の責任を負いません。
API経由とはいえ、データベース内部の情報をChatGPTへ渡しているため、本番データベースでの利用は想定しておりません。プロシージャで扱うデータには十分な注意を払ってください。
実行環境
| OS | DB | APEX | ORDS |
| Oracle Linux 7.6 | Oracle Database 19c | 22.2 | 23.1 |
準備
今回は、GUIで入出力の画面を作成したいという目的と、apex_web_serviceパッケージを使用する目的のためOracle APEXのインストールを行っています。
ChatGPT APIキーの入手やAPEX、Oracle RESTful Data Service(ORDS)のインストールが既に済んでいる方はテストテーブル作成まで読み飛ばしてください。
ChatGPT APIキーの入手
ChatGPTのAPIキーを入手していない場合、OpenAIにサインインし、以下のページ上にある「+ Create new sercret key」ボタンからsk-で始まる自身のAPIキーを入手してください。
https://platform.openai.com/account/api-keys
※APIキー流出によるセキュリティリスクにご注意ください。
Oracle Walletの設定
httpsでapiを実行するためには、接続先サーバのSSLサーバ証明書を検証するためのルートCA証明書が必要になります。
UTL_HTTPでHTTPS通信 / ORA-29024の回避
詳細については、上記の記事を参照してください。ここでは、コマンドのみを記載します。
ca-certificatesパッケージがない/古い場合は更新を行います。
# yum install ca-certificates以降はoracleユーザで実行します。
Oracle Walletを作成
$ su - oracle
$ ORACLE_WALLET_PATH=/opt/oracle/ca_wallet
$ ORACLE_WALLET_PWD=WalletPasswd123
$ mkdir -p ${ORACLE_WALLET_PATH}
$ orapki wallet create -wallet ${ORACLE_WALLET_PATH} -pwd ${ORACLE_WALLET_PWD} -auto_loginルートCA証明書を入手
$ cd ${ORACLE_WALLET_PATH}
$ wget https://curl.haxx.se/ca/cacert.pemルートCA証明書を変換
$ awk 'split_after == 1 {n++;split_after=0} /-----END CERTIFICATE-----/ {split_after=1} {print > "cert" n ".pem"}' < cacert.pemOracle WallletへルートCA証明書を追加
$ for i in /opt/oracle/ca_wallet/cert*.pem
do
orapki wallet add -wallet ${ORACLE_WALLET_PATH} -trusted_cert -cert "$i" -pwd ${ORACLE_WALLET_PWD}
doneOracle APEXおよびOracle RESTful Data Serviceのインストール
Oracle APEXインストレーション・ガイド リリース22.2
Oracle REST Data Services インストレーションおよび構成ガイド リリース22.2
Oracle APEXの環境作成(5) – APEXのインストール
こちらも詳細な手順は公式ドキュメント含む、上記のリンクをご覧ください。
Oracle APEXのインストール
公式サイトから 2023/04/20 現在の最新版である22.2のzipファイルをダウンロードし、任意のディレクトリに配置して展開してください。
ダウンロードするには、『Oracle APEX 22.2 – すべての言語』というリンクをクリックしてください。
$ mkdir /home/oracle/tools
$ cd /home/oracle/tools
$ unzip ./apex_22.2.zip展開したディレクトリへ移動
$ cd /home/oracle/tools/apex完全開発環境のインストール
今回APEXは、PDB [ORCLPDB1] に対してインストールしていきます。
$ sqlplus / as sysdbaalter session set container = ORCLPDB1;APEXアプリケーションユーザおよびAPEXファイルユーザの表領域はSYSAUX、一時表領域はTEMP、APEXイメージの仮想ディレクトリは/i/としています。
@apexins.sql SYSAUX SYSAUX TEMP /i/日本語リソースのロード
@load_trans.sql JAPANESEAPEXインスタンス管理者アカウントの作成
@apxchpwd.sql管理アカウント名はADMINのままで作成しています。
パスワードは6文字以上、1つ以上の数字、一つ以上の記号、1つ以上の小文字のアルファベットを含む必要があります。
Enter the administrator's username [ADMIN]
User "ADMIN" does not yet exist and will be created.
Enter ADMIN's email [ADMIN]
Enter ADMIN's password [] ***APEX_PUBLIC_USERユーザをアンロックします。
alter user apex_public_user no authentication account unlock;構成スクリプトを実行してRESTfulサービスを構成します。
@apex_rest_config.sqlプロンプトが表示されたら、APEX_LISTENERアカウントおよびAPEX_REST_PUBLIC_USERアカウントのパスワードを入力します。
Enter a password for the APEX_LISTENER user: ***
Enter a password for the APEX_REST_PUBLIC_USER user: ***Oracle APEXでWebサービスを使用するには、Oracle Databaseでネットワーク・サービスを有効にする必要があるため有効化を行います。
BEGIN
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => '*',
ace => xs$ace_type(privilege_list => xs$name_list('connect'),
principal_name => 'APEX_220200',
principal_type => xs_acl.ptype_db));
END;
/Oracle RESTful Data Serviceのインストール
rpmを用いたOracle RESTful Data Serviceのインストールの場合、jdkのインストールが行われないので別途インストールを行います。
$ sudo rpm -ivh https://download.oracle.com/java/17/latest/jdk-17_linux-x64_bin.rpmrpmでOracle RESTful Data Serviceをインストール
$ sudo rpm -ivh https://yum.oracle.com/repo/OracleLinux/OL7/oracle/software/x86_64/getPackage/ords-23.1.0-9.el7.noarch.rpm対話モードでセットアップ
$ ords --config /etc/ords/config install今回はPDBで動作させるため、データベース・サービス名にPDBのサービス名 [ORCLPDB1] を指定しています。
また、APEX静的リソースの場所も [/home/oracle/tools/apex/images] と指定しています。
番号を入力して、インストールのタイプを選択します
[1] データベースのORDSのインストールまたはアップグレードのみを実行する
[2] データベース・プールを作成または更新して、データベースのORDSをインストール/アップグレードする
[3] データベース・プールの作成または更新のみを実行する
Choose [2]:
番号を入力して、使用するデータベース接続タイプを選択します
[1] 基本(ホスト名、ポート、サービス名)
[2] TNS (TNS別名、TNSディレクトリ)
[3] カスタム・データベースURL
Choose [1]:
データベース・ホスト名を入力 [localhost]: localhost
データベースのリスニング・ポートを入力してください [1521]: 1521
データベース・サービス名を入力してください [ORCLCDB]: ORCLPDB1
管理者ユーザー名を入力してください: sys
SYS AS SYSDBAのデータベース・パスワードを入力してください: ****
データベース・ユーザー: SYS AS SYSDBA URL: jdbc:oracle:thin:@//localhost:1521/ORCLPDB1に接続しています
情報の取得中.
ORDS_METADATAおよびORDS_PUBLIC_USERのデフォルト表領域を入力してください [SYSAUX]:
ORDS_METADATAおよびORDS_PUBLIC_USERの一時表領域を入力してください [TEMP]:
番号を入力して、有効化する追加機能を選択します:
[1] データベース・アクション(すべての機能を有効化)
[2] REST対応SQLおよびデータベースAPI
[3] REST対応SQL
[4] データベースAPI
[5] なし
Choose [1]:
番号を入力して、ORDSをスタンドアロン・モードで構成および起動します
[1] ORDSをスタンドアロン・モードで構成および起動する
[2] スキップ
Choose [1]:
番号を入力して、プロトコルを選択します
[1] HTTP
[2] HTTPS
Choose [1]:
HTTPポートを入力してください [8080]:
APEX静的リソースの場所を入力します: /home/oracle/tools/apex/images2023-04-20T11:04:17.772Z INFO Oracle REST Data Services initialized
Oracle REST Data Services version : 23.1.0.r0861423
Oracle REST Data Services server info: jetty/10.0.12
Oracle REST Data Services java info: Java HotSpot(TM) 64-Bit Server VM 17.0.7+8-LTS-224完了後は上述のような出力が行われた後、Oracle RESTful Data Serviceが起動しますが、プロンプトが戻ってこないため一度Ctrl+Cで抜けます。
抜けた後、再度systemctlで起動を行います。
Oracle RESTful Data Serviceの起動
$ systemctl start ordsOracle RESTful Data Serviceを起動したらAPEXワークスペースの作成を行います。
APEXワークスペースの作成
APEX管理サービスにサインイン
サインインページは以下になります。
http://<ホスト名>:<ポート番号>/ords/apex_admin
今回はこちら。
http://localhost:8080/ords/apex_admin
APEXインスタンス管理者アカウントのユーザ名とパスワードを入力してサインインします。

ワークスペースの作成
「ワークスペースの管理」 > 「ワークスペースの作成」
ワークスペース名に任意の名前を入れて次へ
今回は[ChatGPT_dev]という名前を付けました。
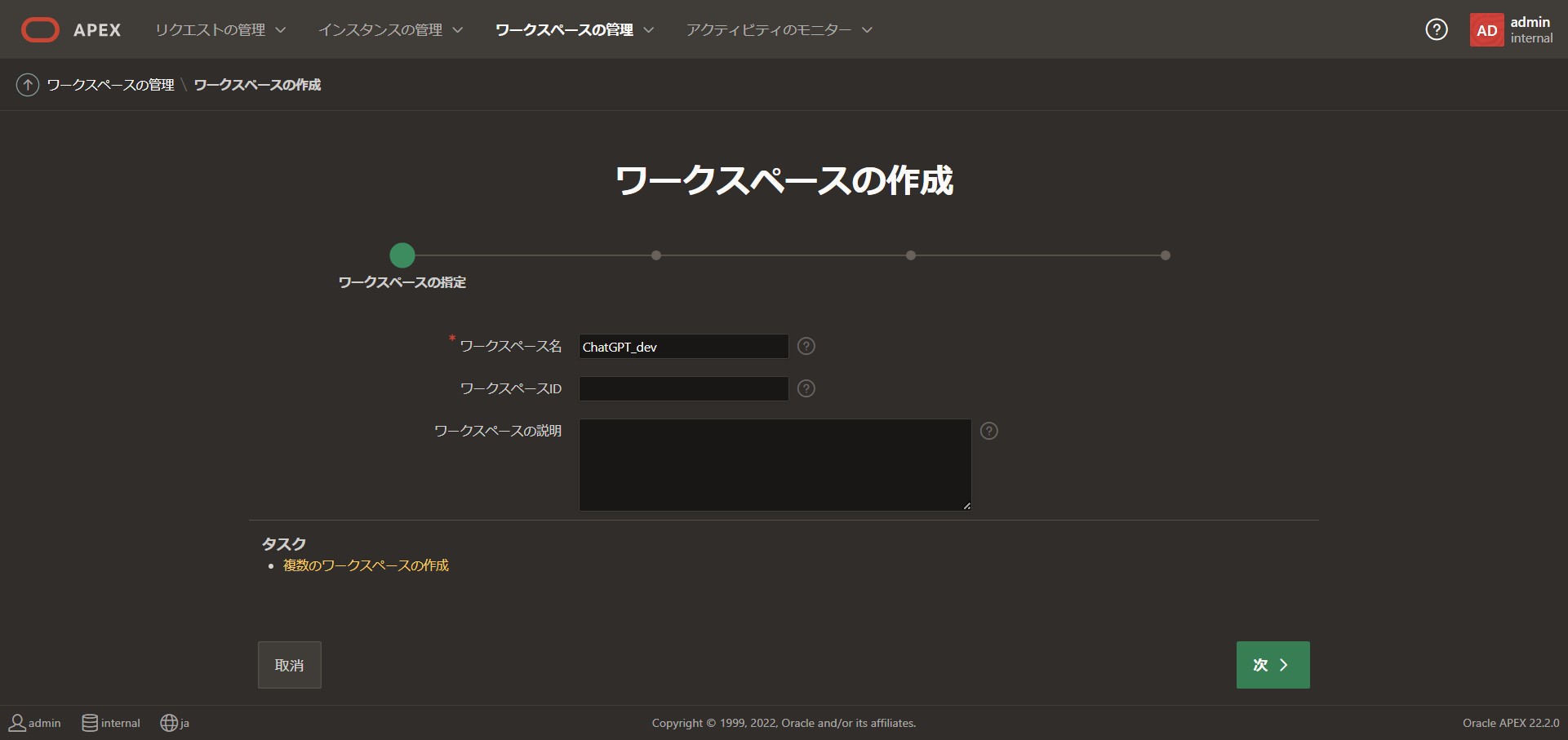
スキーマは新規で作成しています。
既存スキーマの再利用:[いいえ]
スキーマ名:[APEX_CHATGPT_WS]
領域割り当て制限(MB):[100]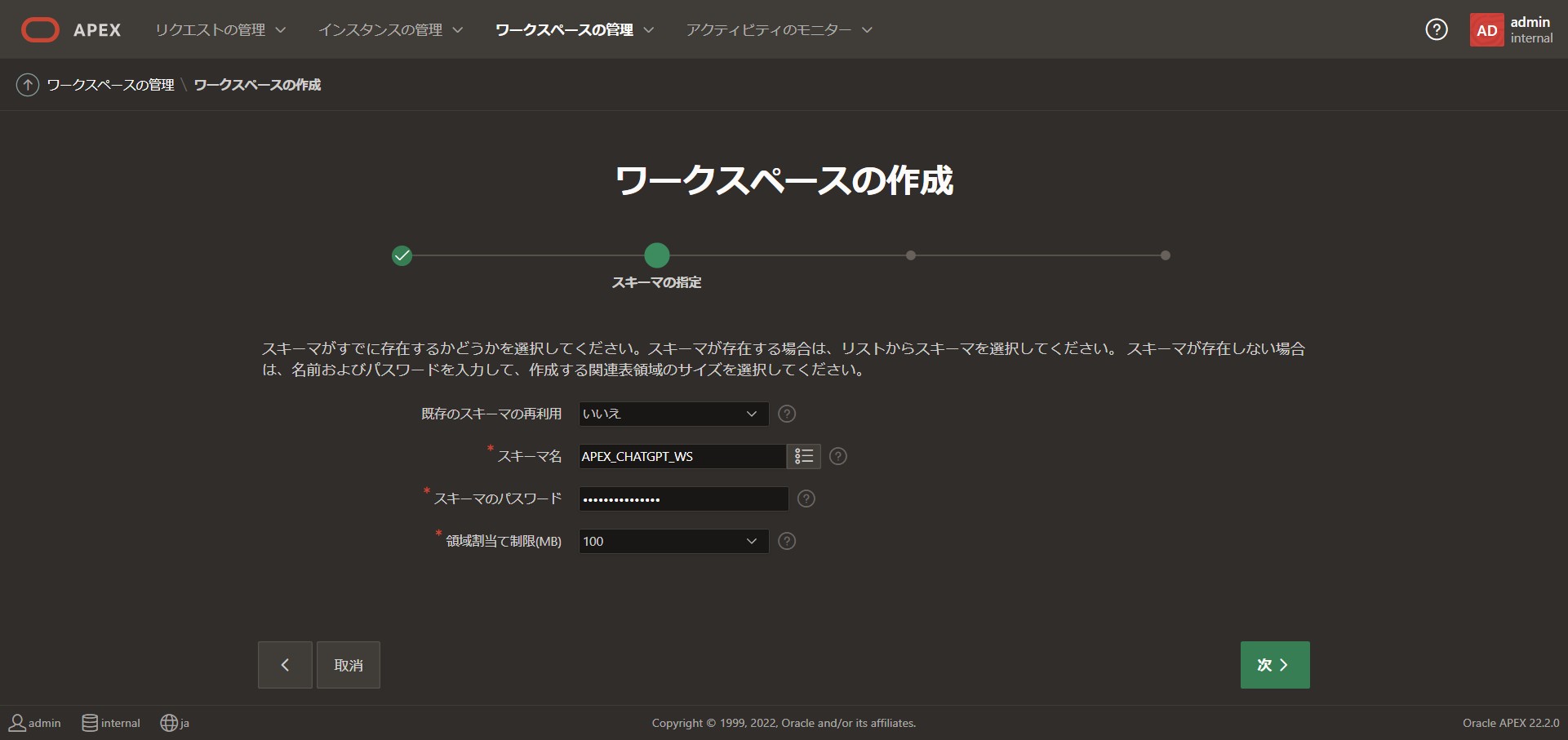
ワークスペース管理者の名前、パスワード、メールアドレスを入力します。
管理者のユーザ名:[APEX_CHATGPT_ADMIN]
管理のパスワード:[任意のパスワード]
電子メール:[任意の電子メールアドレス]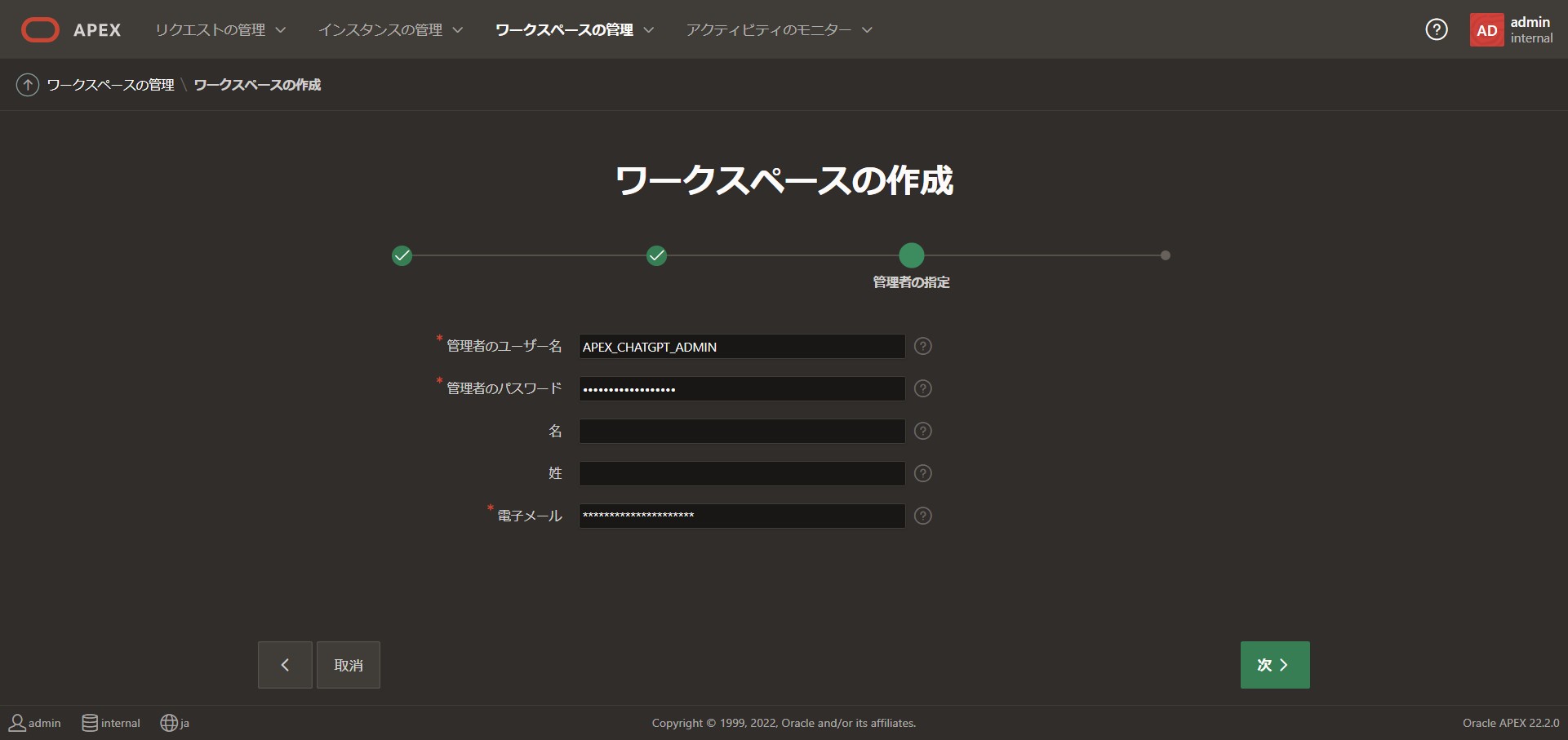
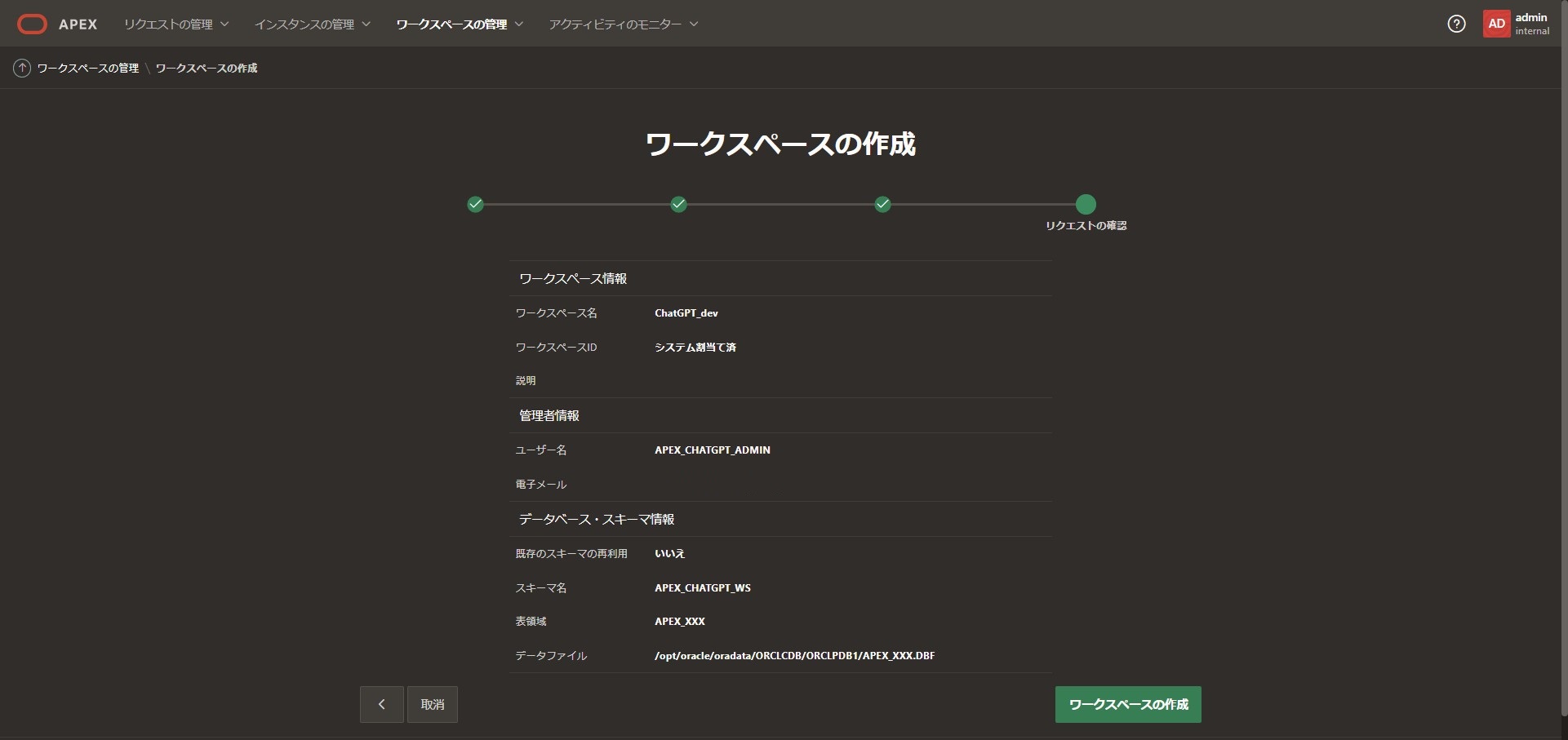
内容に問題無ければ「ワークスペースの作成」ボタンを押しましょう。
ワークスペースへサインイン
作成したワークスペースへサインインします。
http://<ホスト名>:<ポート番号>/ords
今回はこちら。
http://localhost:8080/ords
ワークスペース名:[ChatGPT_dev]
ユーザ名:[APEX_CHATGPT_ADMIN]
初回はパスワードの変更を求められるので新しいパスワードの入力を行います。
テストテーブルの作成
テストテーブルの作成
「SQLワークショップ」 > 「SQLコマンド」
からテストテーブルを作っていきます。
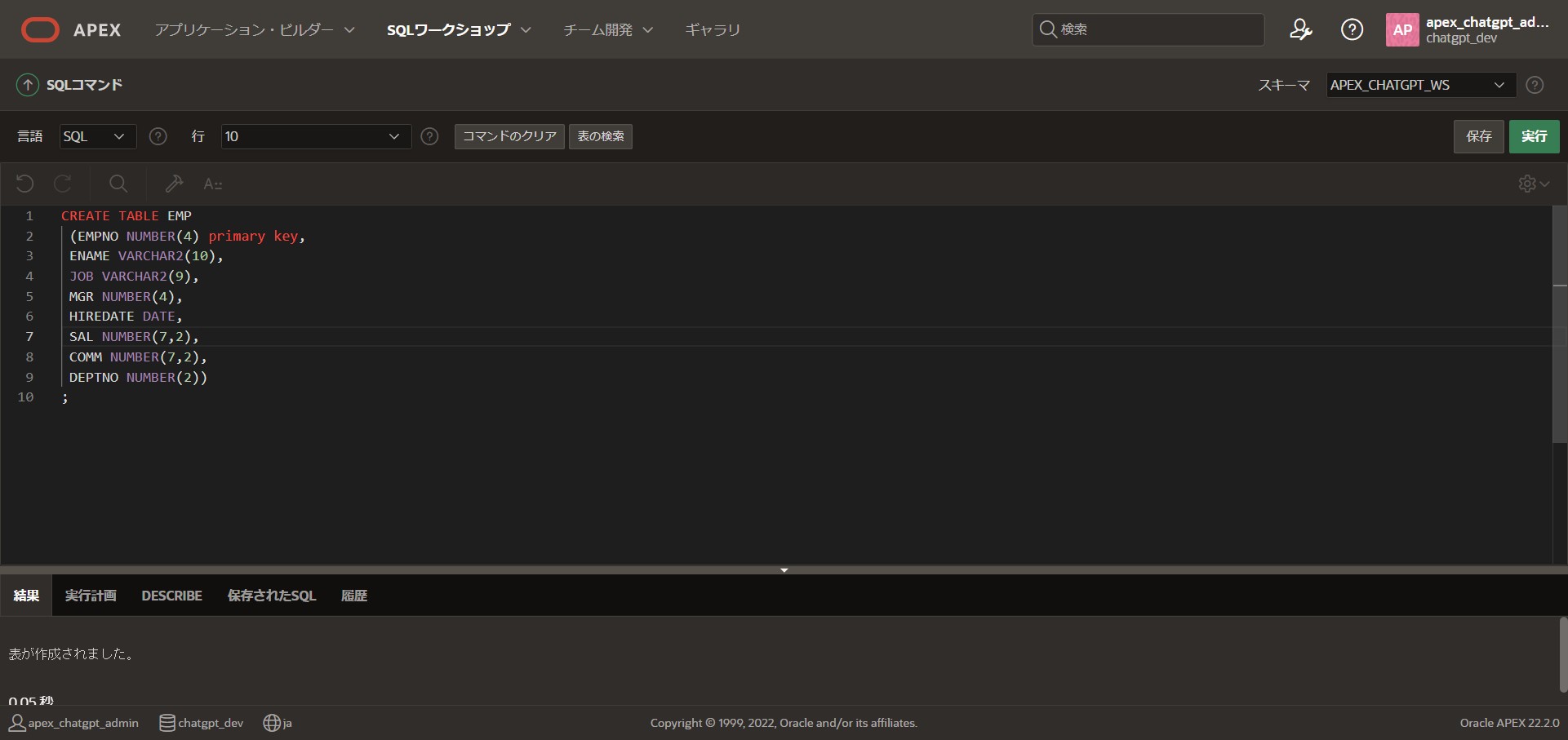
下記CREATE文を張り付け、「実行」ボタンを押してテーブルを作成します。
CREATE TABLE EMP
(EMPNO NUMBER(4) primary key,
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2))
;
データの登録
続けてデータの登録を行います。
同様に以下のinsert文を貼り付け、「実行」を行います。
insert all
into EMP values (7369,'SMITH','CLERK',7902,'1980/12/17',800,null,20)
into EMP values (7499,'ALLEN','SALESMAN',7698,'1981/02/20',1600,300,30)
into EMP values (7521,'WARD','SALESMAN',7698,'1981/02/22',1250,500,30)
into EMP values (7566,'JONES','MANAGER',7839,'1981/04/02',2975,null,20)
into EMP values (7654,'MARTIN','SALESMAN',7698,'1981/09/28',1250,1400,30)
into EMP values (7698,'BLAKE','MANAGER',7839,'1981/05/01',2850,null,30)
into EMP values (7782,'CLARK','MANAGER',7839,'1981/06/09',2450,null,10)
into EMP values (7788,'SCOTT','ANALYST',7566,'1987/04/19',3000,null,20)
into EMP values (7839,'KING','PRESIDENT',null,'1981/11/17',5000,null,10)
into EMP values (7844,'TURNER','SALESMAN',7698,'1981/09/08',1500,null,30)
into EMP values (7876,'ADAMS','CLERK',7788,'1987/05/23',1100,null,20)
into EMP values (7900,'JAMES','CLERK',7698,'1981/12/03',950,null,30)
into EMP values (7902,'FORD','ANALYST',7566,'1981/12/03',3000,null,20)
into EMP values (7934,'MILLER','CLERK',7782,'1982/01/23',1300,null,10)
select * from dual;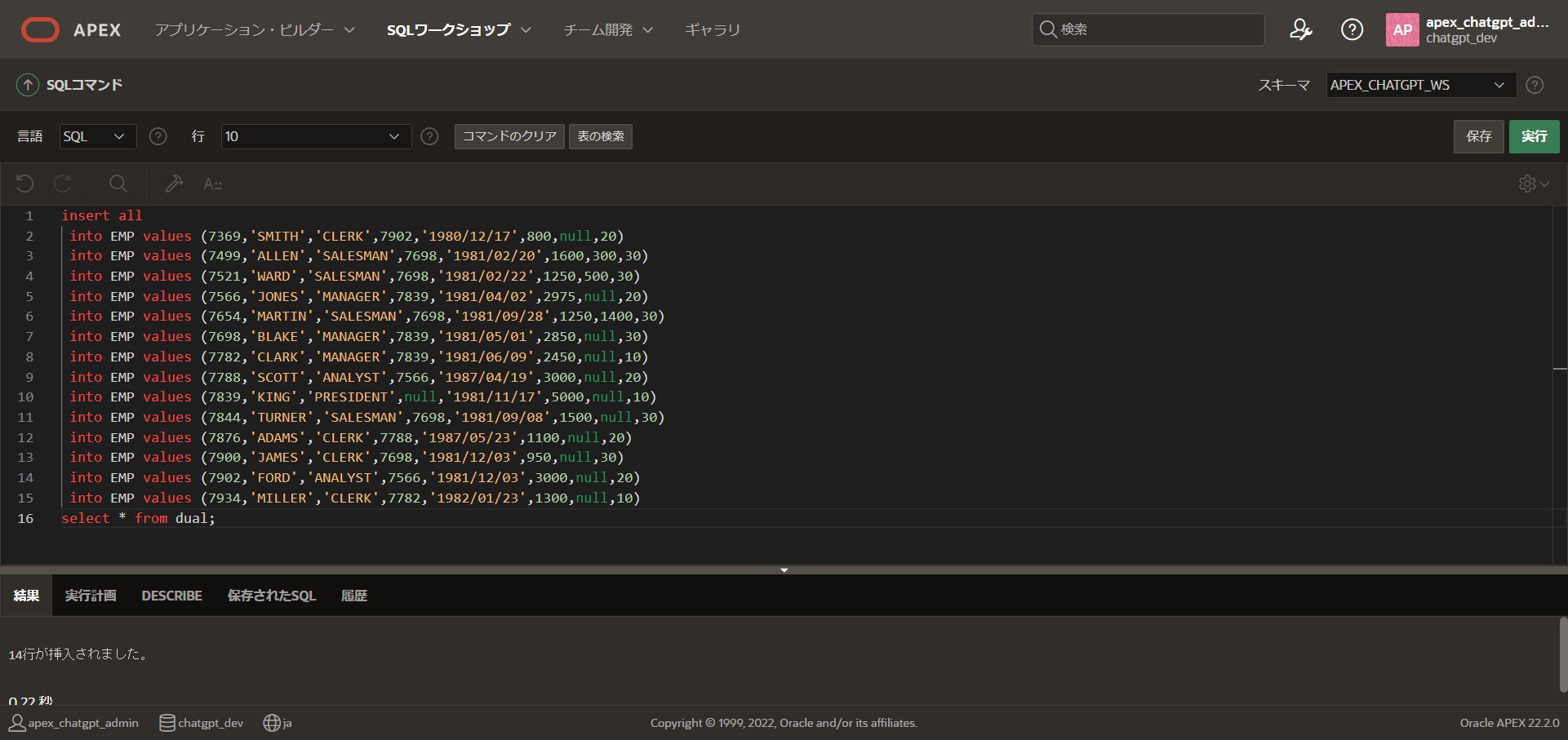
さてこれでようやく準備が整いました。
プロシージャの作成
引き続きAPEXのSQLコマンドを利用して、プロシージャの作成を行っていきます。
プロシージャ内の変数
l_ora_wallet_path, l_ora_wallet_pass はOracle Walletの配置場所とパスワードを
l_api_key は、ご自身で取得したChatGPTのAPIキーを入力してください。
プロシージャの処理の流れは以下の通りです。
- 引数 l_schema, l_table で指定されたテーブルの定義を取得
- 上記テーブルのデータを最大100件取得
- 1,2,で取得した内容と引数 l_request の内容をChatGPTのAPIへインプット
- 引数 l_answer に格納されたChatGPTからの返答内容を表示
CREATE OR REPLACE PROCEDURE proc_chatgpt3_5( l_schema in varchar2, l_table in varchar2, l_request in clob, l_answer out clob)
IS
l_definition clob;
l_record clob;
l_answer_json clob;
l_assistant clob;
l_content clob;
l_ora_wallet_path varchar2(200) := '/opt/oracle/ca_wallet';
l_ora_wallet_pass varchar2(200) := 'WalletPasswd123';
l_api_key varchar2(200) := 'sk-***';
l_url varchar2(4000) := 'https://api.openai.com/v1/chat/completions';
l_model varchar2(200) := 'gpt-3.5-turbo';
l_system varchar2(4000) := 'あなたは優秀なORACLEデータベースエンジニアです。';
l_eof varchar2(10) := '|EOF|';
l_eol varchar2(10) := '|EOL|';
CURSOR c_definition IS select owner, table_name, column_name, column_id, data_type, nullable from all_tab_columns where owner = l_schema and table_name = l_table order by column_id;
l_defval c_definition%ROWTYPE;
l_cols varchar2(4000);
l_sql_stmt varchar2(4000);
TYPE t_cursor IS REF CURSOR;
c_record t_cursor;
l_recval varchar2(4000);
BEGIN
OPEN c_definition;
LOOP
FETCH c_definition INTO l_defval;
EXIT WHEN c_definition%NOTFOUND;
IF l_definition IS NULL THEN
l_definition := l_defval.owner|| l_eof ||
l_defval.table_name|| l_eof ||
l_defval.column_name|| l_eof ||
l_defval.column_id|| l_eof ||
l_defval.data_type|| l_eof ||
l_defval.nullable|| l_eol
;
ELSE
l_definition := l_definition||
l_defval.owner|| l_eof ||
l_defval.table_name|| l_eof ||
l_defval.column_name|| l_eof ||
l_defval.column_id|| l_eof ||
l_defval.data_type|| l_eof ||
l_defval.nullable|| l_eol
;
END IF;
IF l_cols IS NULL THEN
l_cols := l_defval.column_name;
ELSE
l_cols := l_cols||'||'''|| l_eof ||'''||'||l_defval.column_name;
END IF;
END LOOP;
CLOSE c_definition;
l_sql_stmt := 'select '|| l_cols ||' from '|| l_schema ||'.'|| l_table ||' where rownum <= 100';
OPEN c_record FOR l_sql_stmt;
LOOP
FETCH c_record INTO l_recval;
EXIT WHEN c_record%NOTFOUND;
IF l_record IS NULL THEN
l_record := l_recval|| l_eol ;
ELSE
l_record := l_record||l_recval|| l_eol ;
END IF;
END LOOP;
CLOSE c_record;
l_assistant := l_definition||'上記は「テーブル定義」です。列区切り文字は「'|| l_eof || '」、行区切り文字は「'|| l_eol ||'」、左から順にowner,table_name,column_name,column_id,data_type,nullableの情報になります。\n'||
l_record||'上記は「テーブルのサンプルレコード(最大100件)」です。「テーブル定義」のcolumn_id順に並び、列区切り文字は「'|| l_eof || '」、行区切り文字は「'|| l_eol ||'」です。';
l_content := '{"model":"'||l_model||'",
"messages": [{"role":"system", "content":"'||l_system||'"},
{"role":"assistant", "content":"'||l_assistant||'"},
{"role":"user", "content":"'||l_request||'"}] }';
apex_web_service.g_request_headers(1).name := 'Content-Type';
apex_web_service.g_request_headers(1).value := 'application/json';
apex_web_service.g_request_headers(2).name := 'Authorization';
apex_web_service.g_request_headers(2).value := 'Bearer '||l_api_key;
l_answer_json := apex_web_service.make_rest_request(
p_url => l_url,
p_http_method => 'POST',
p_body => l_content,
p_wallet_path => 'file:'||l_ora_wallet_path,
p_wallet_pwd => l_ora_wallet_pass
);
SELECT JSON_VALUE(l_answer_json, '$.choices.message.content') INTO l_answer FROM DUAL;
EXCEPTION
WHEN OTHERS THEN
IF c_definition%ISOPEN THEN
CLOSE c_definition;
END IF;
IF c_record%ISOPEN THEN
CLOSE c_record;
END IF;
l_answer := 'error occurred.';
END;
/エディタに張り付けて、「実行」を行います。
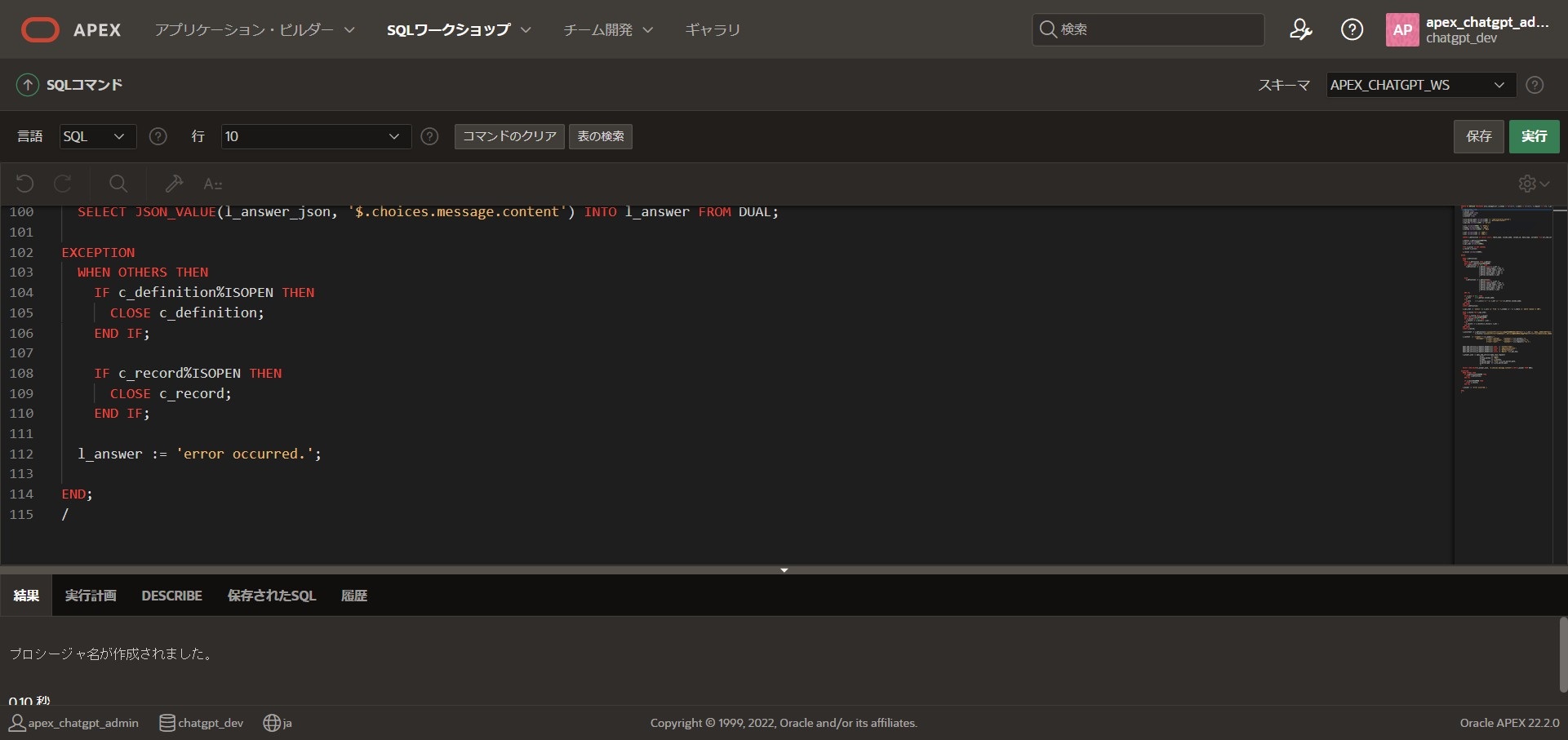
アプリケーションの作成
アプリケーションの作成
続いてプロシージャを動かすアプリケーションをAPEXで作っていきます。
「アプリケーション・ビルダー」 > 「作成」 > 「新規アプリケーション」
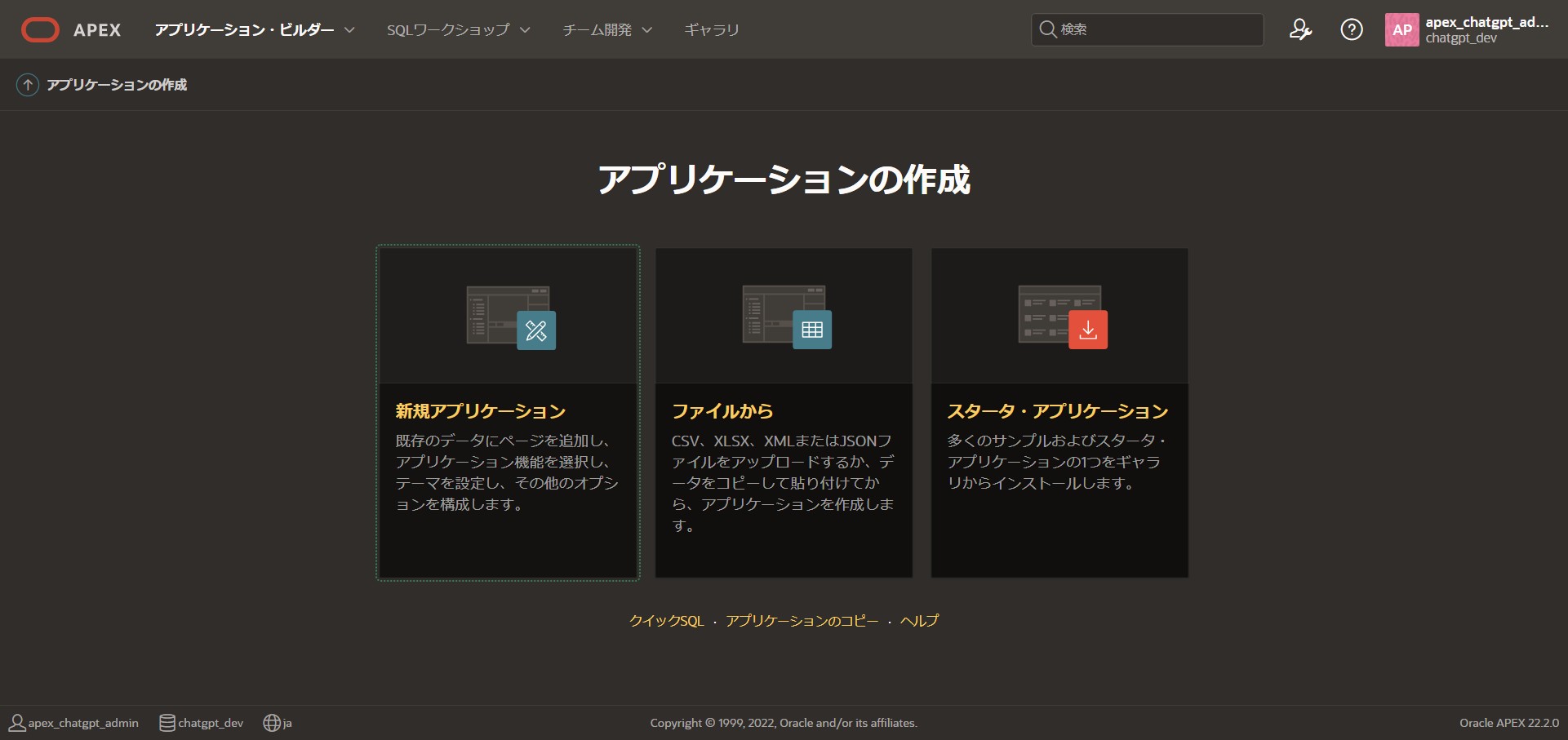
名前:[ChatGPT_APP]
で「アプリケーションの作成」を行います。
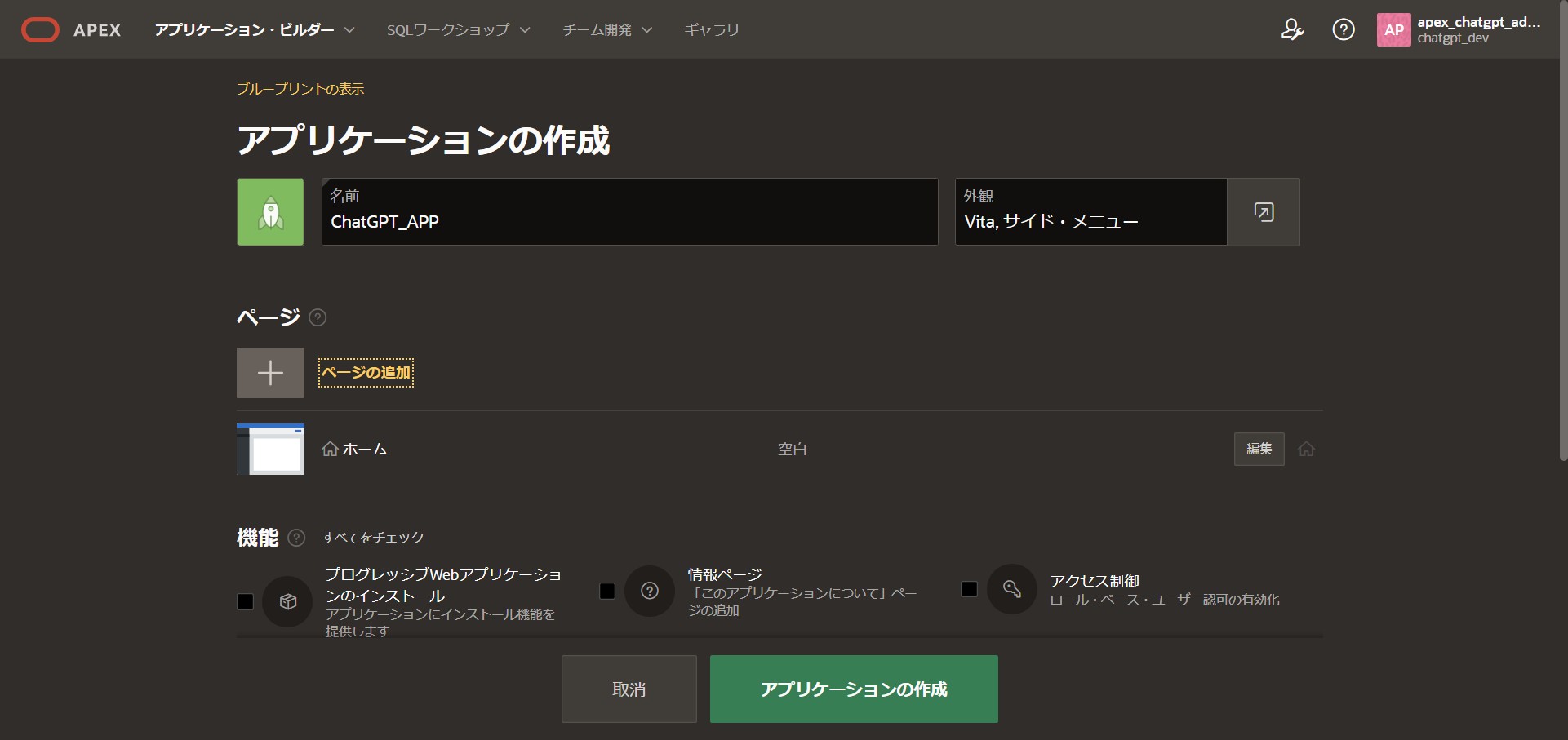
ページの作成
次にフォームページを作成します。
「ページの作成」から レガシー・ページ タブ内にある「ローカル・プロシージャのフォーム」を選択し、「次」へ
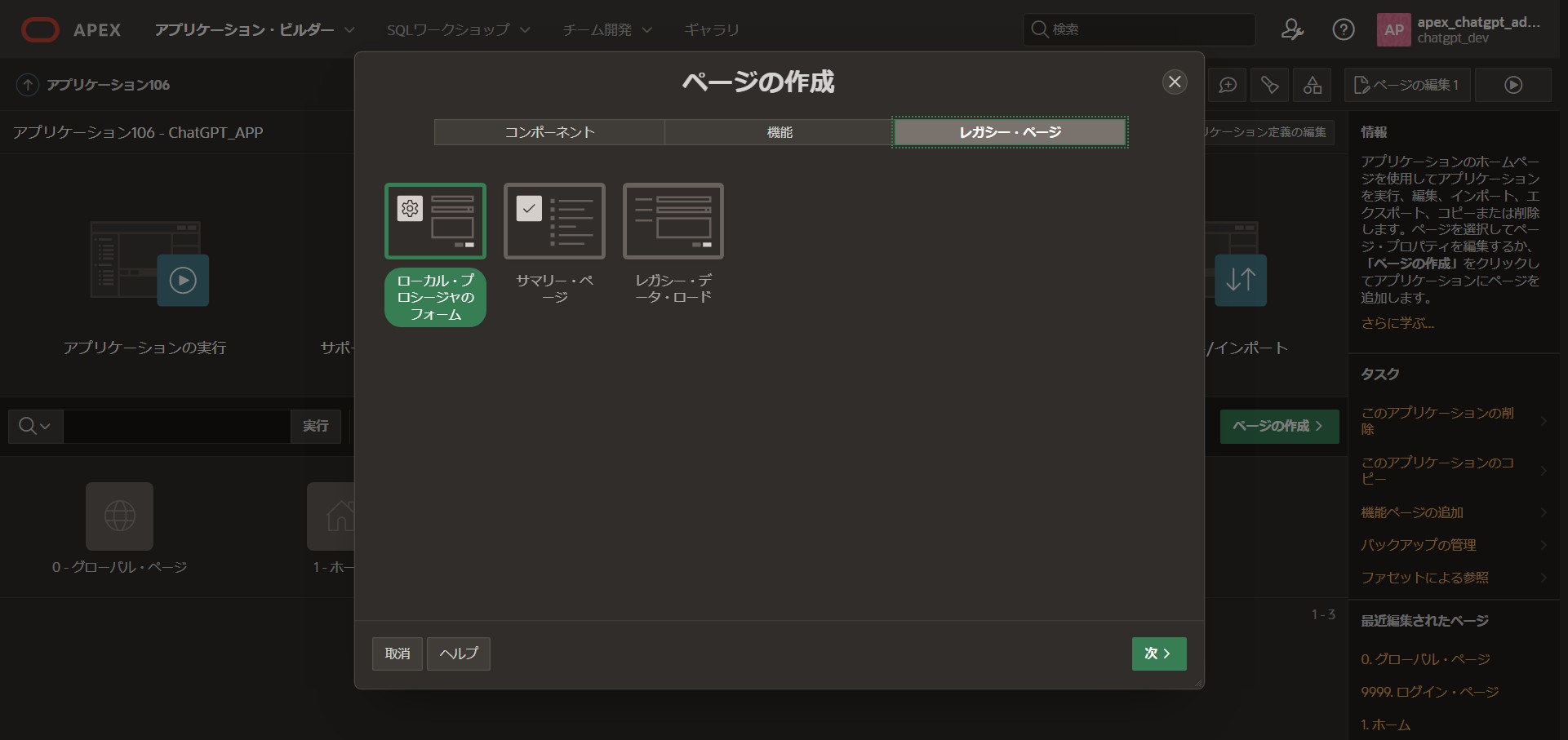
ローカル・プロシージャフォームの作成
ページ番号:[2]
名前:[ChatGPTプロシージャフォーム]
で「次」へ
ページ番号が2以外の場合、以降の手順に出てくる『P2_』という部分は、自身が使用したページ番号に読み替えて実行するように注意してください。

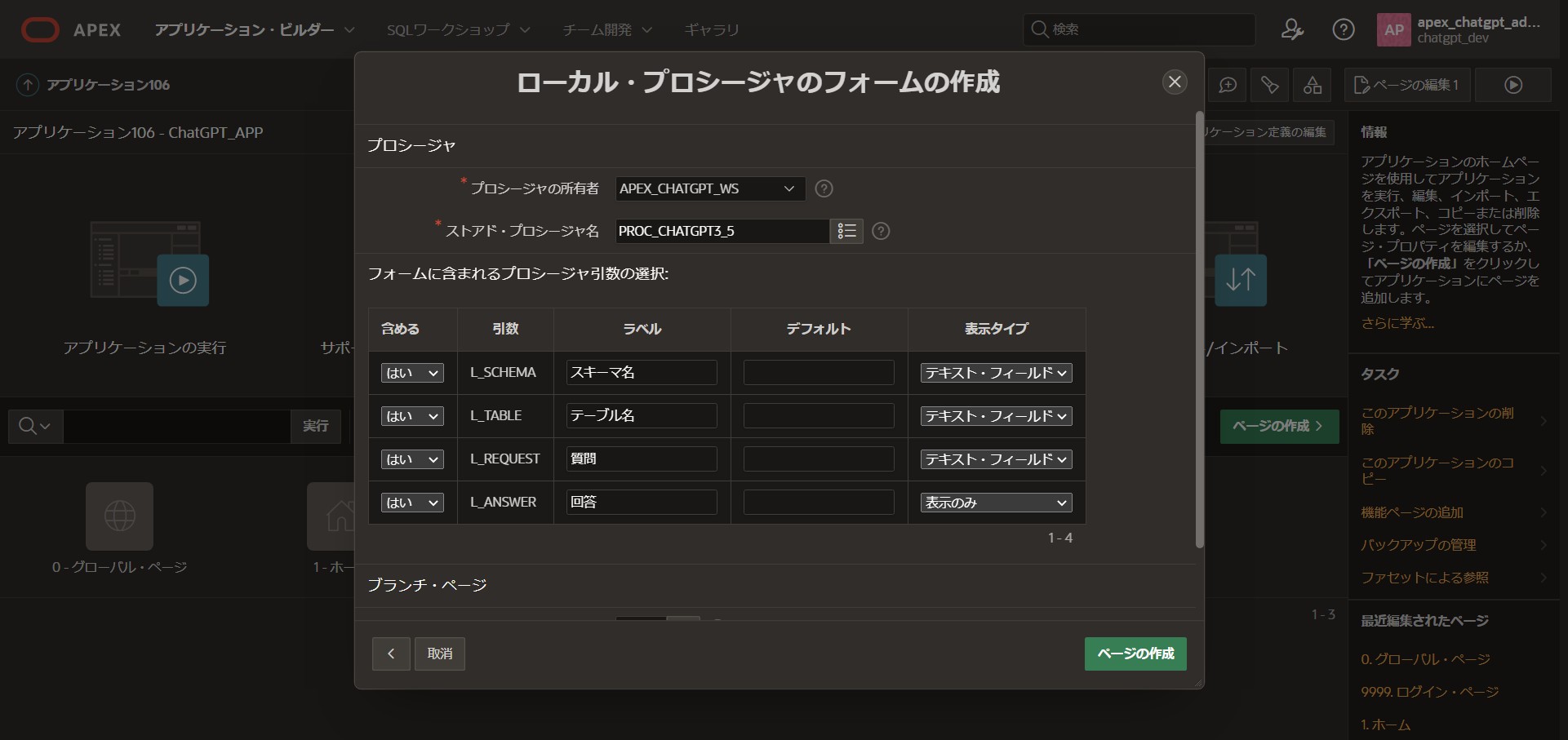
プロシージャの所有者:[APEX_CHATGPT_WS]
ストアド・プロシージャ名:[PROC_CHATGPT3_5]
フォームに含まれるプロシージャ引数の選択は以下のよう設定にします。
含める | 引数 | ラベル | デフォルト | 表示タイプ |
| はい | L_SCHEMA | スキーマ名 | テキスト・フィールド | |
| はい | L_TABLE | テーブル名 | テキスト・フィールド | |
| はい | L_REQUEST | 質問 | テキスト・フィールド | |
| はい | L_ANSWER | 回答 | 表示のみ |
「ページの作成」ボタンを押して作成。
ページ・デザイナの編集
各フォームの機能を編集していきます。
アイテム
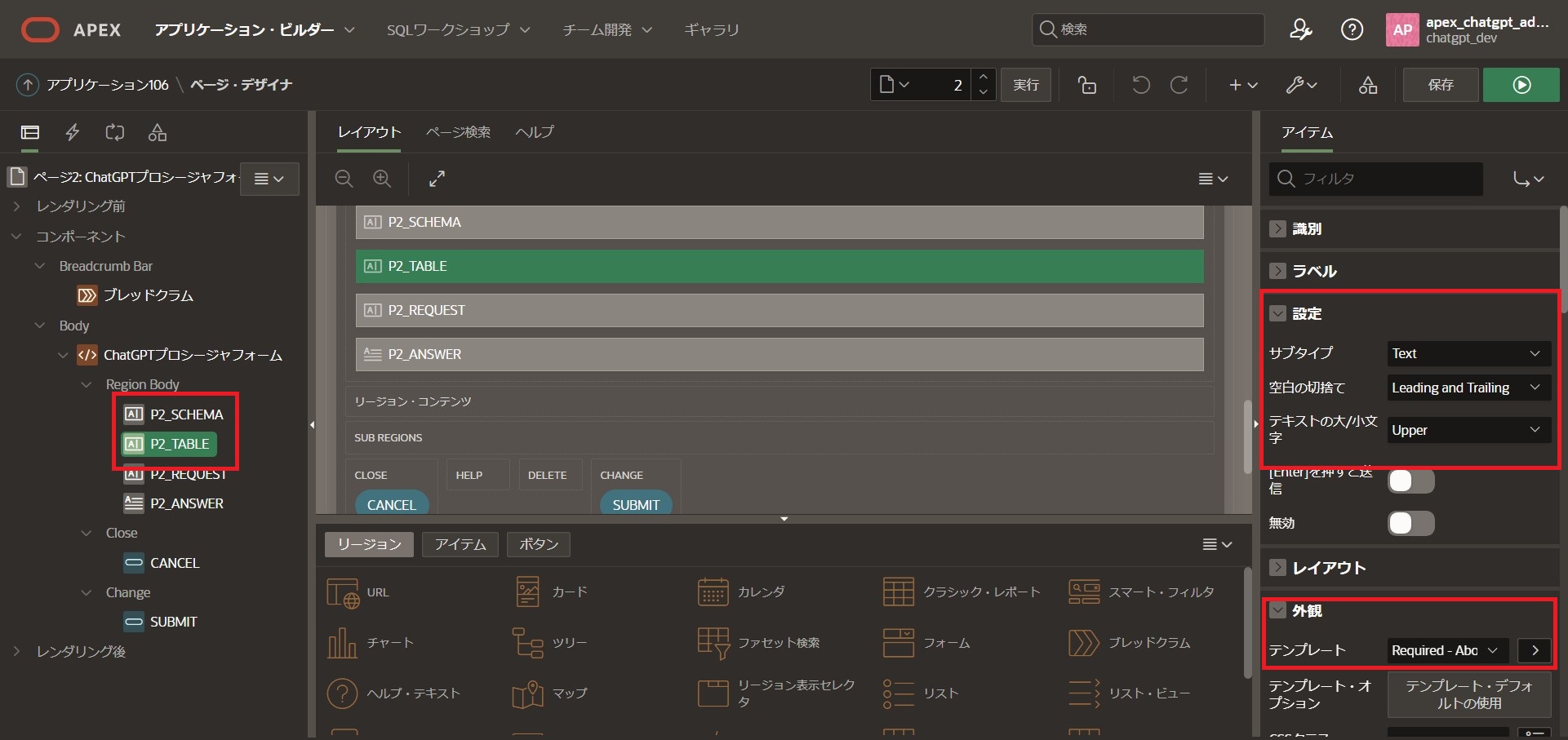
Region Bodyから「P2_SCHEMA」を選択
右側のサイドメニューを以下の通り編集します。
設定
空白の切り捨て:[Leading and Trailing]
テキストの大/小文字:[Upper]
外観
テンプレート:[Required – Above]
「P2_TABLE」も同じ設定へ変更します。
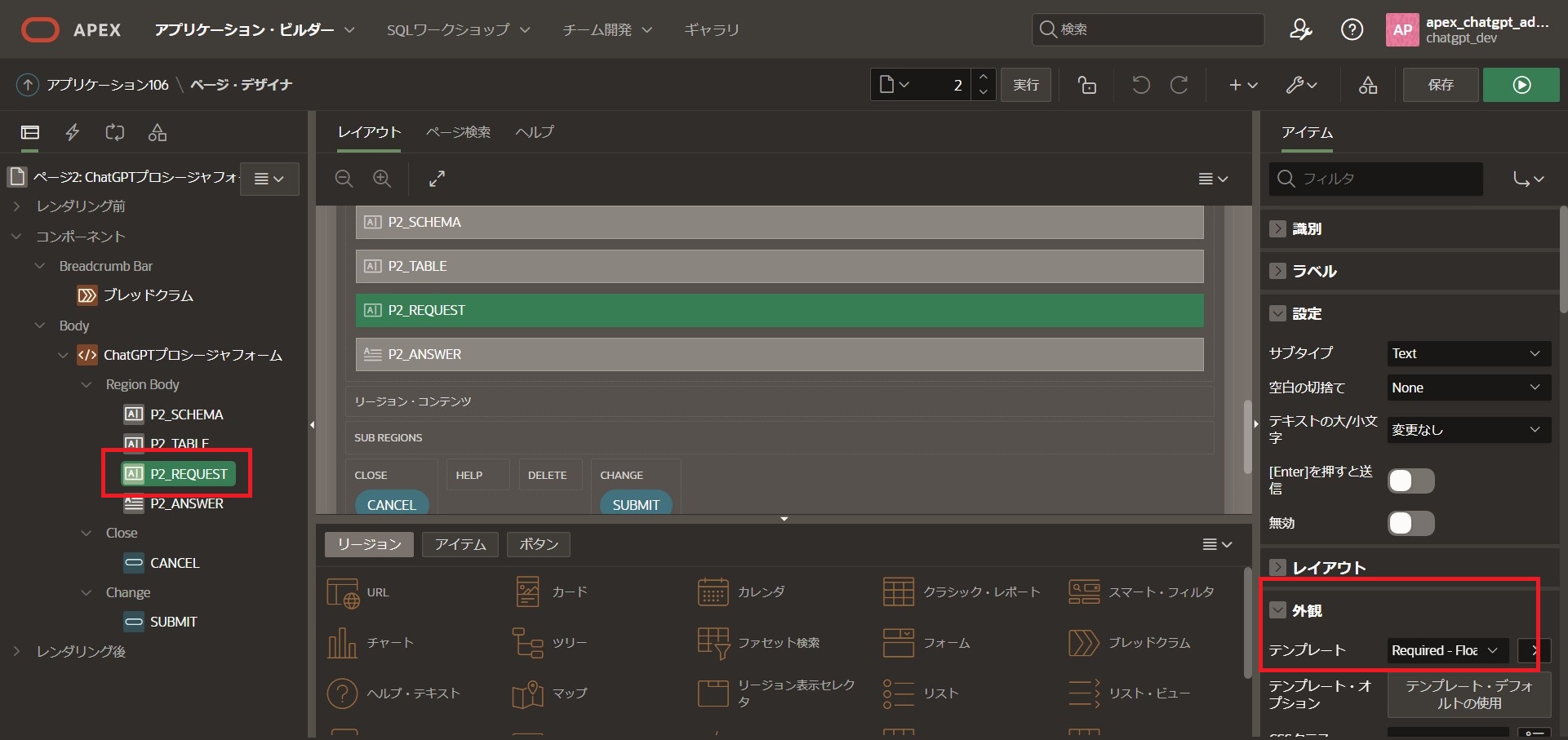
続いて「P2_REQUEST」を選択
右側のサイドメニューを以下の通り編集します。
外観
テンプレート:[Required – Floating]
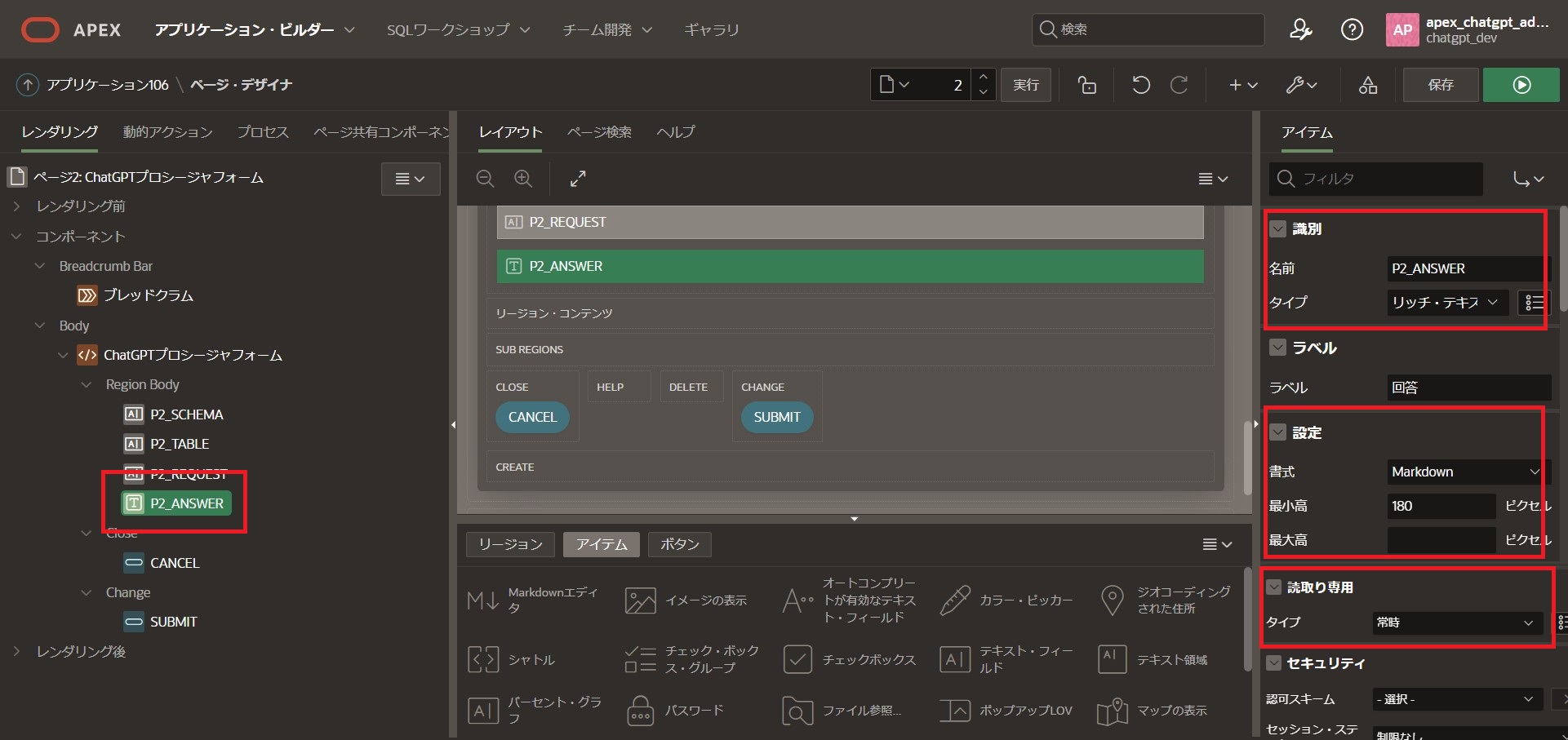
最後に「P2_ANSWER」を選択
右側のサイドメニューを以下の通り編集します。
識別
タイプ:[リッチ・テキスト・エディタ]
設定
書式:[Markown]
読み取り専用
タイプ:[常時]
ボタン
ChatGPTにリクエストを投げるボタンを作成します。
Region Bodyから「P2_REQUEST」を右クリックし、「下にボタンを作成」をクリック
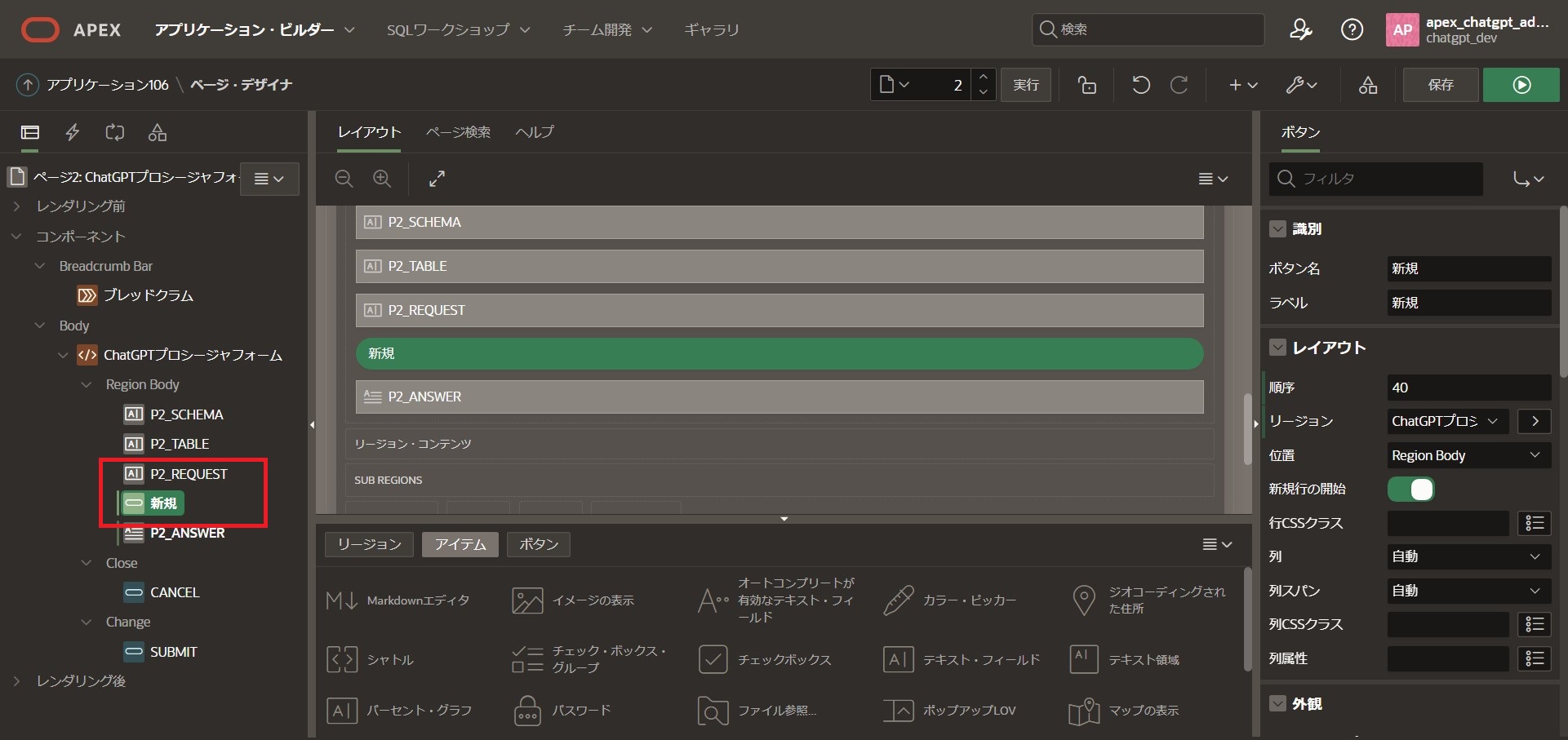
作成された「新規」ボタンの右側のサイドメニューを以下の通り編集します。
識別
ボタン名:[検索]
ラベル:[検索]
外観
ボタン・テンプレート:[Text with Icon]
ホット:[有効化]
動作
アクション:[動的アクションで定義]
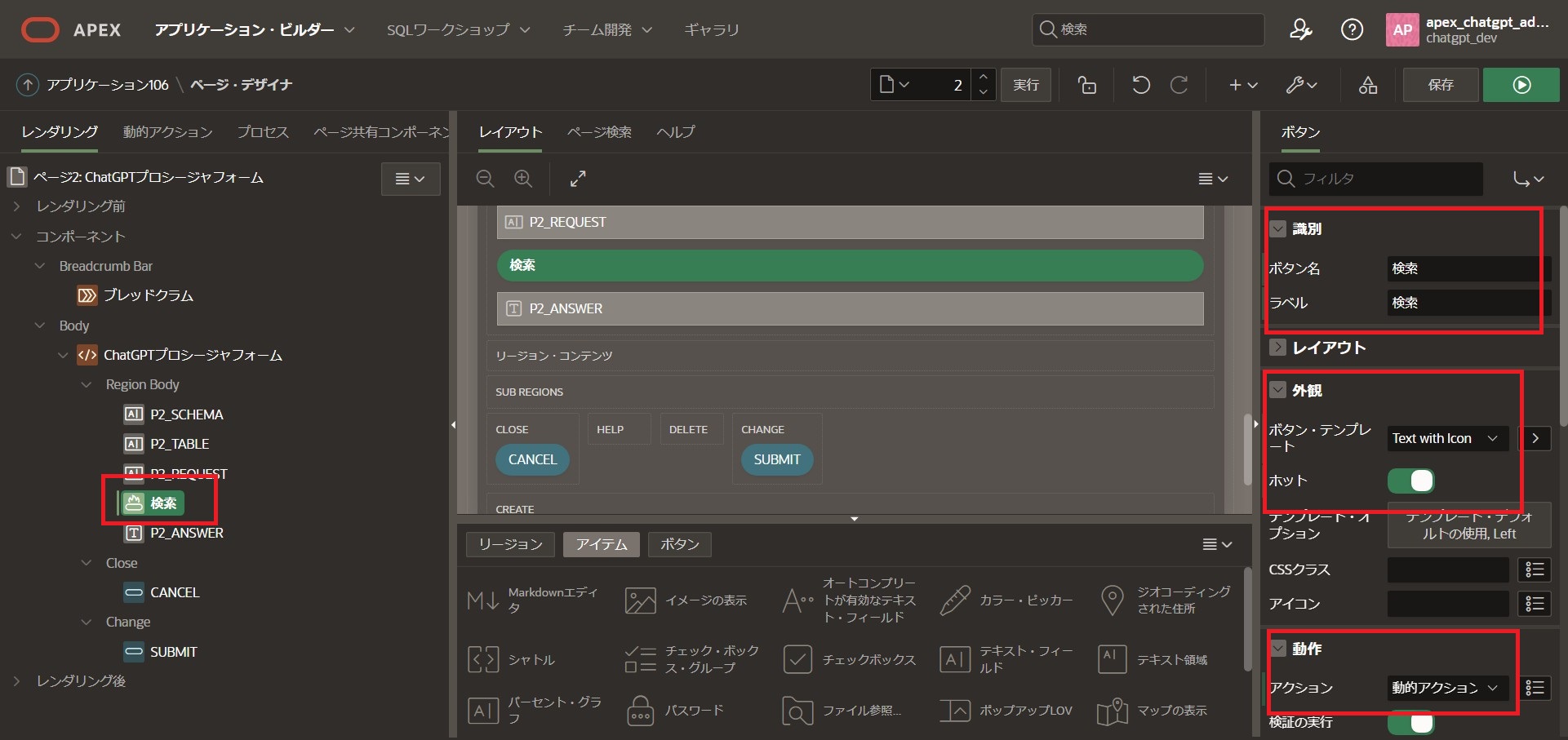
Region Bodyから「検索」を右クリックし、「動的アクションの作成」をクリック
「動的アクション」 > 「新規」 > 「True」 > 「表示」を選択
右側のサイドメニューを以下の通り編集します。
識別
アクション:[サーバー側のコードを実行]
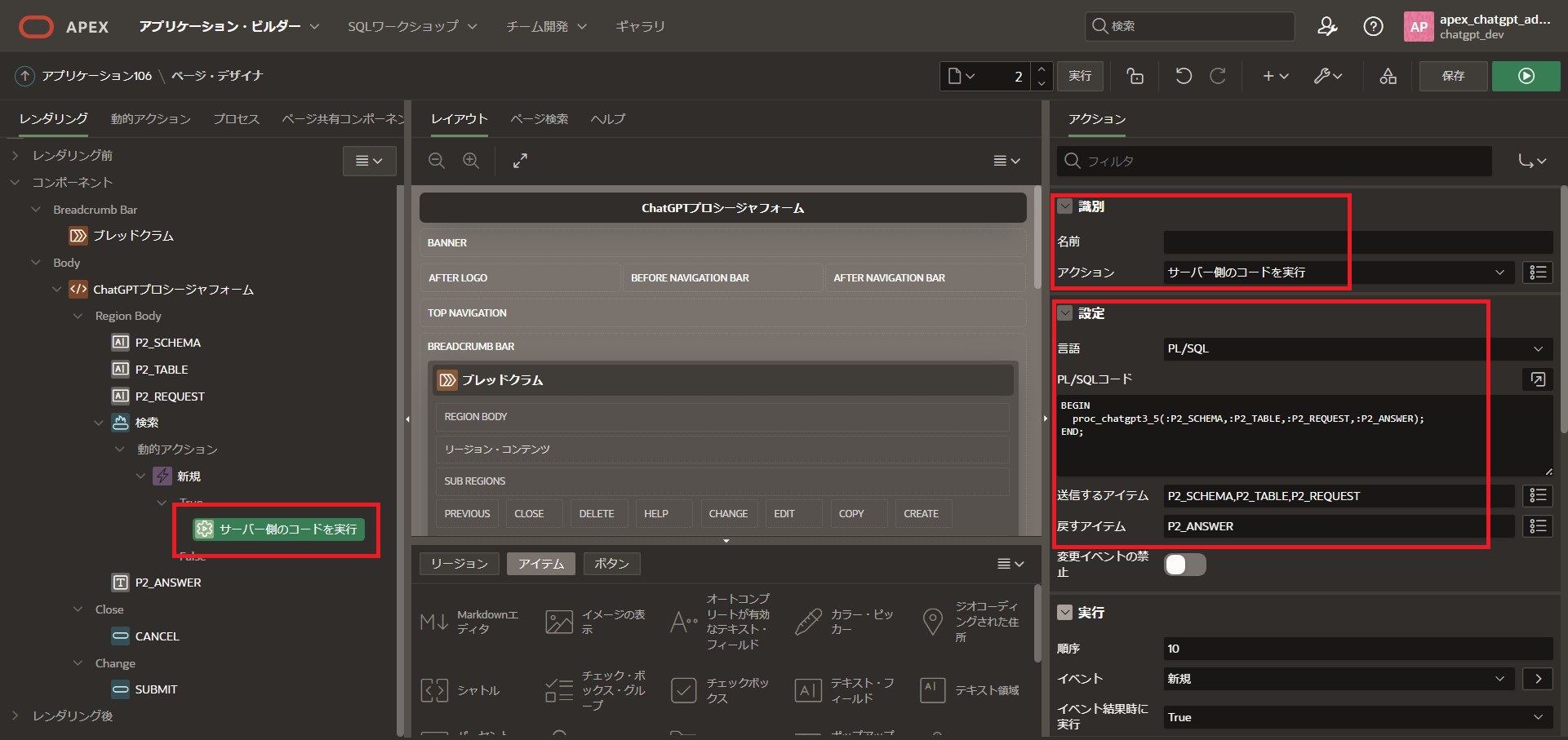
設定
PL/SQLコード のアイコンをクリックしてコードエディタへ以下のコードを入力
(P2_部分はページ番号に合わせ適宜変更をしてください)
BEGIN
proc_chatgpt3_5(:P2_SCHEMA,:P2_TABLE,:P2_REQUEST,:P2_ANSWER);
END;送信するアイテム:[P2_SCHEMA,P2_TABLE,P2_REQUEST]
戻すアイテム:[P2_ANSWER]
(P2_部分はページ番号に合わせ適宜変更をしてください)
ChatGPTからのレスポンスにMarkdown書式が含まれていた場合、崩れて表示されてしまうため、ページを更新するアクションも作成します。
前段で作成した「サーバー側のコードを実行」を右クリックし、「アクションの作成」をクリック
右側のサイドメニューを以下の通り編集
識別
アクション:[JavaScriptコードを実行]
設定
コード欄に以下のコードを入力
location.reload();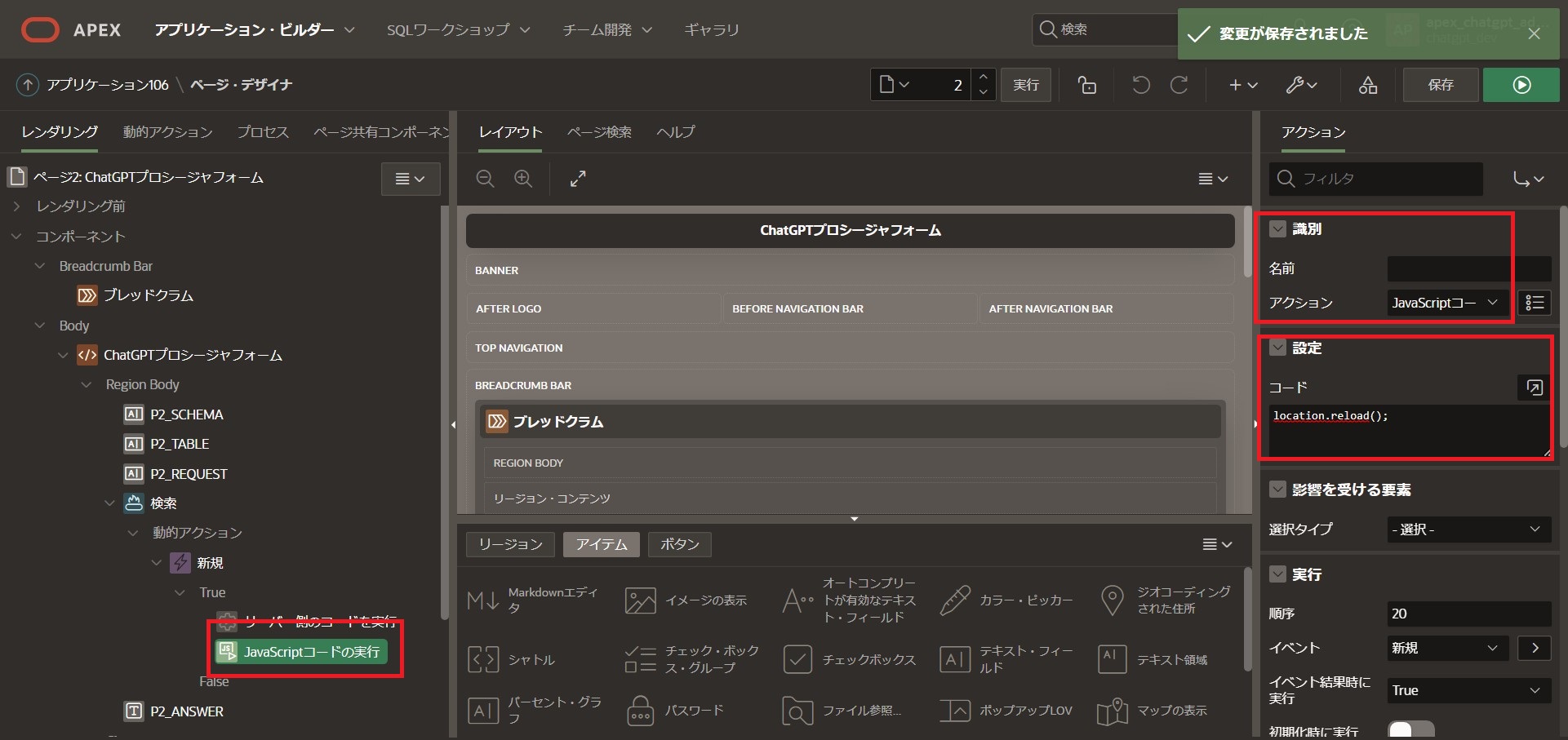
最後にトップの「ChatGPTプロシージャフォーム」をクリックし、ナビゲーション部分を以下の通り編集します。
ナビゲーション
保存されていない変更の警告:[無効化]
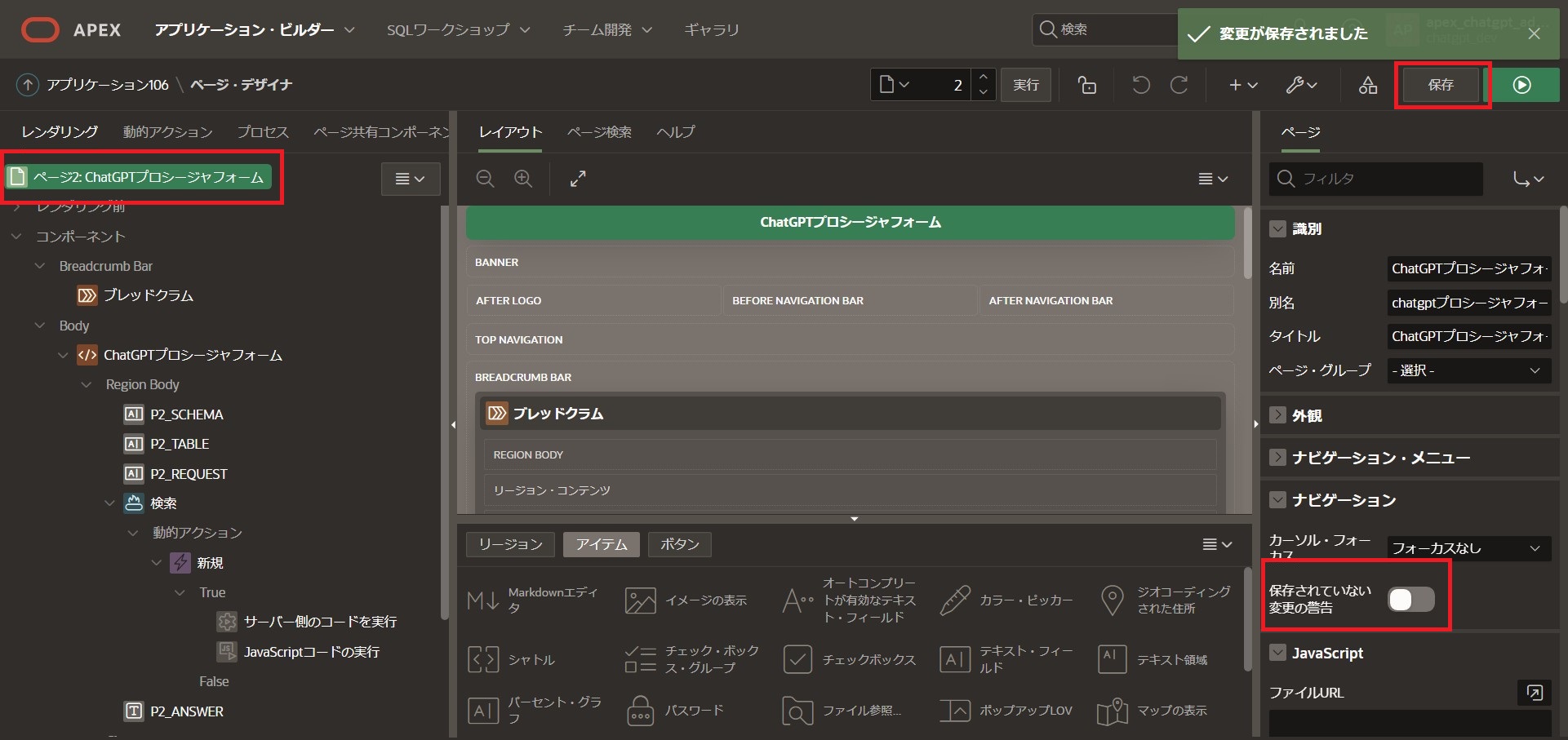
「保存」をしたら作成完了です。
動作確認
それでは動作確認を行っていきましょう。
ワークスペースのユーザで作成したアプリケーションへログインします。
http://localhost:8080/ords/r/chatgpt_dev/chatgpt-app
サイドバーから「ChatGPTプロシージャフォーム」を開きます。
問題無く表示されたらいくつか質問をしていきましょう。
質問1
スキーマ名:[APEX_CHATGPT_WS]、テーブル名:[EMP]
質問:[このテーブルのレコード数を教えてください。またレコード数を取得するためのSQL文も教えてください。]
「検索」ボタンを押してしばらく待ちます。
回答:
このテーブルのレコード数は14です。レコード数を取得するSQL文は以下の通りです。
SELECT COUNT(*) FROM EMP;
または
SELECT COUNT(1) FROM EMP;
どちらのSQL文でも同じ結果が得られます。
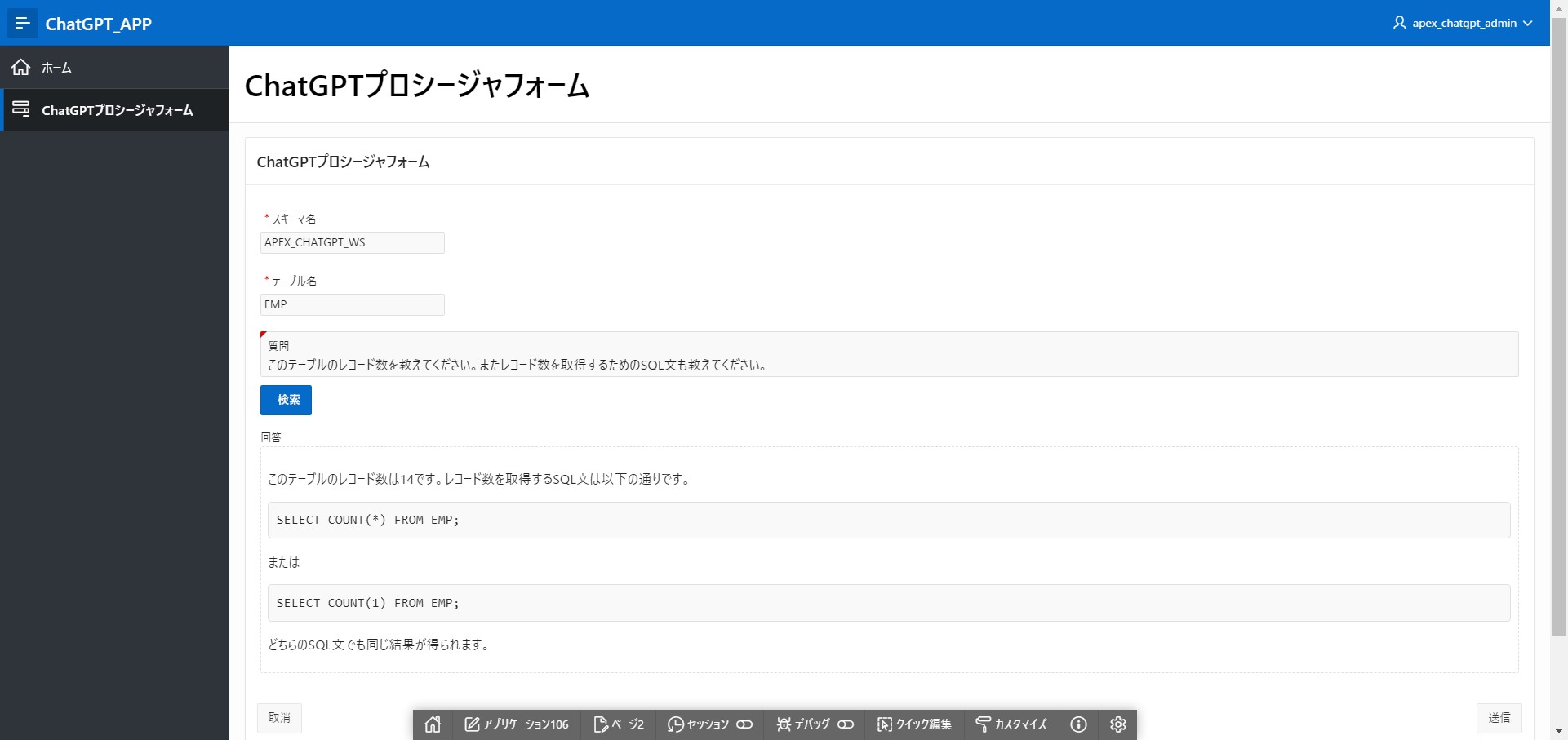
期待した通りの回答が返ってきました。
ただ、同様の質問を別のタイミングでした時は以下の結果となりました。
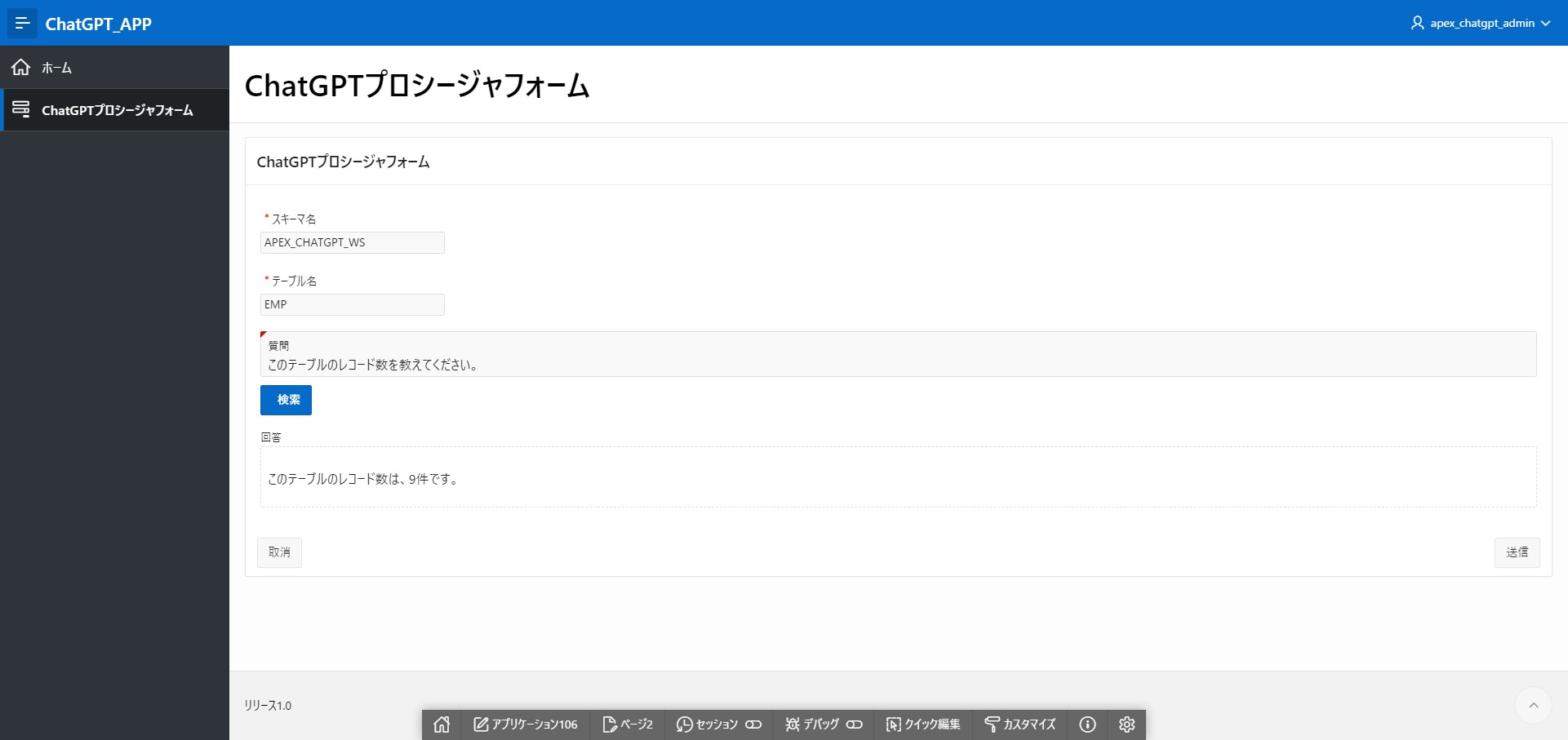
ここでは「レコード数は、9件です」と誤った回答が行われました。
データをインプットしていても、完全な回答をしてくれるわけではないのですね。
次はもう少し複雑な質問にしてみます。
質問2
次はテーブルの正規化をしてもらいましょう。
スキーマ名:[APEX_CHATGPT_WS]、テーブル名:[EMP]
質問:[このテーブルの正規化を進めたいです。どのようにテーブルを分ければよいでしょうか。]
回答:
まずは、このテーブルの中から、重複しているデータや、複数の値を持ってしまっている列を洗い出してみましょう。
例えば、このテーブルの場合、部門情報が含まれておらず、部門IDが列に含まれているため、部門の情報を追加する必要があります。また、MGR列には、上司の社員番号が保存されていますが、これは従業員テーブル自身に従属的な列であり、繰り返しグループを持つため、別の従業員テーブルを作成する必要があります。
したがって、従業員(Employee)テーブル、部門(Department)テーブル、上司(Manager)テーブルを作成する必要があります。また、テーブル定義には明示されていませんが、従業員に付随するプロジェクト(Project)情報がある場合や、従業員の役職(Position)情報がある場合は、それらも別のテーブルとして分離する必要があります。
従業員テーブル:
・従業員番号(Employee ID)
・従業員名(Employee Name)
・雇用日(Hire Date)
・雇用形態(Job)
・給与(Salary)
・コミッション(Commission)
・部門ID(Department ID)
・上司ID(Manager ID)
部門テーブル:
・部門ID(Department ID)
・部門名(Department Name)
・場所(Location)
上司テーブル:
・上司ID(Manager ID)
・上司名(Manager Name)
・雇用日(Hire Date)
・雇用形態(Job)
・給与(Salary)
・コミッション(Commission)
・部門ID(Department ID)
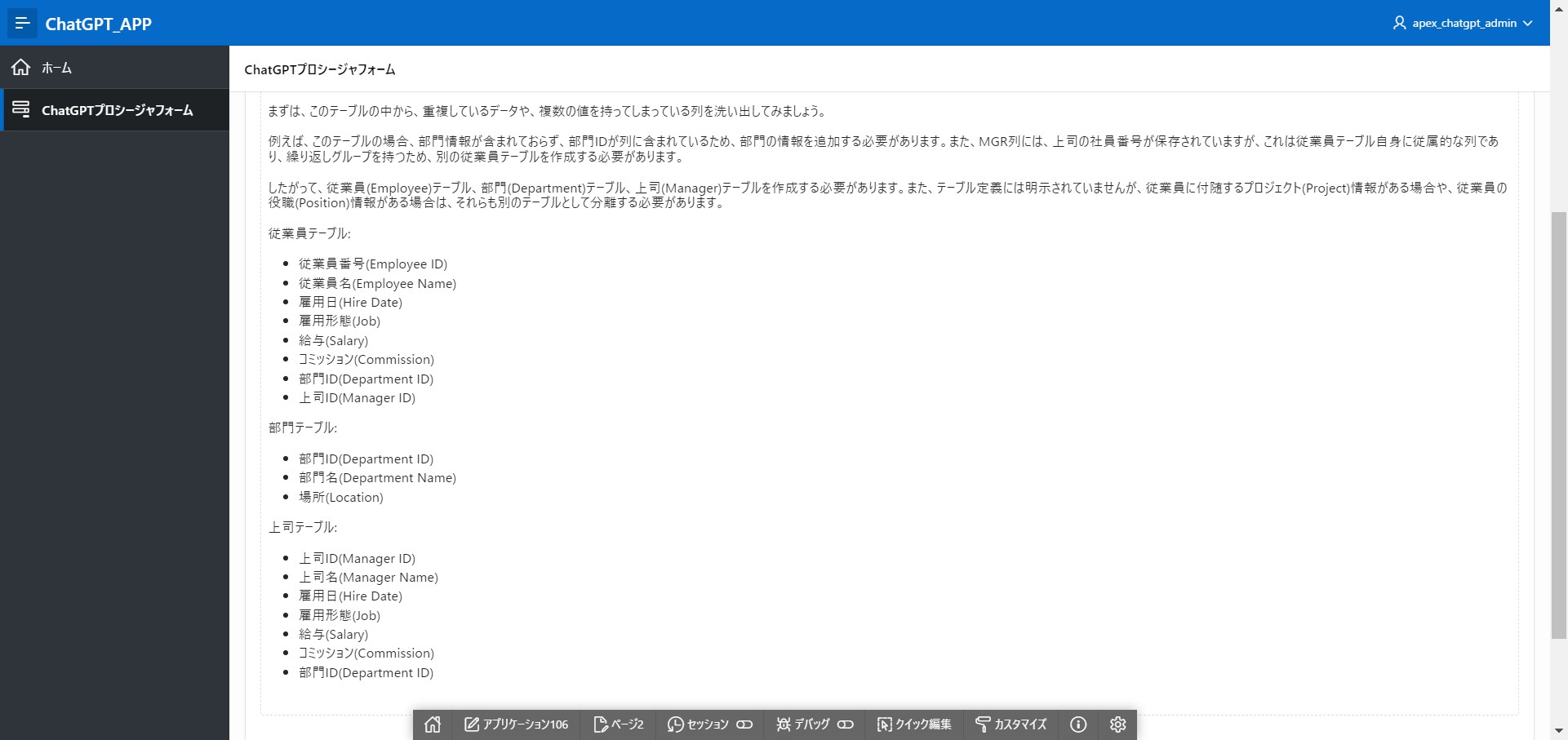
上司テーブルが必要かはわかりませんが・・・正規化も行えるようです。
また、テーブル名やカラム名からこのテーブルが従業員の情報を記録したテーブルということも認識しているようです。
質問3
従業員テーブルであるということを理解しているようなのでカラム名を書かずに質問をしてみます。
スキーマ名:[APEX_CHATGPT_WS]、テーブル名:[EMP]
質問:[雇用されてから40年以上経過した従業員の一覧を教えてください。対象従業員の給与を10%アップさせるためのSQL文も教えてください。]
回答:
以下がSQL文になります。SELECT empno, ename, hiredate, sal FROM emp WHERE months_between(sysdate, hiredate)/12 >= 40; UPDATE emp SET sal = sal * 1.1 WHERE months_between(sysdate, hiredate)/12 >= 40;
最初のSELECT文では、現在日から入社日までの経過月数を求め、年数に換算して40年以上働いている従業員を抽出しています。
次にUPDATE文では、同じ条件で絞り込んだ従業員の給与を10%アップデートしています。
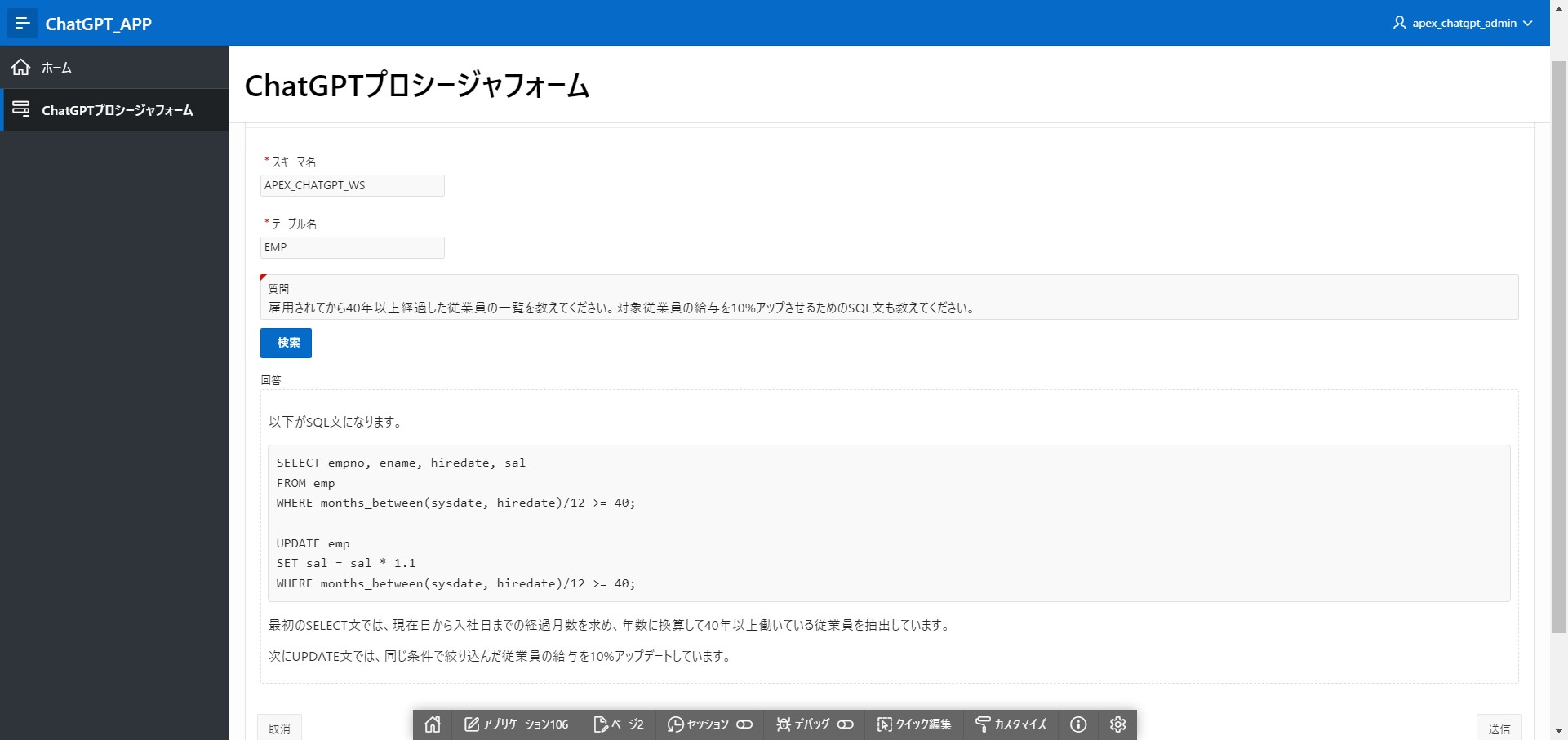
期待したSQL文は得られましたが、アウトプットの量を減らすためか一覧は出力されませんでした。
質問4
最後は結合をさせてみます。
スキーマ名:[APEX_CHATGPT_WS]、テーブル名:[EMP]
質問:[従業員と上司の名前を並べて表示してください。またその時使用するSQL文も教えてください。]
回答:
次のSQL文を使用して、従業員と上司の名前を並べて表示することができます。SELECT e.ename AS employee_name, m.ename AS manager_name FROM emp e LEFT JOIN emp m ON e.mgr = m.empno ORDER BY m.ename, e.ename;
このSQL文では、JOINを使用して従業員表(emp)を上司表(emp)と結合することにより、従業員と上司の名前を表示します。ORDER BYを使用して、上司の名前、従業員の名前の順でソートされます。また、LEFT JOINを使用しているため、上司がいない(社長である)従業員の名前も表示されます。
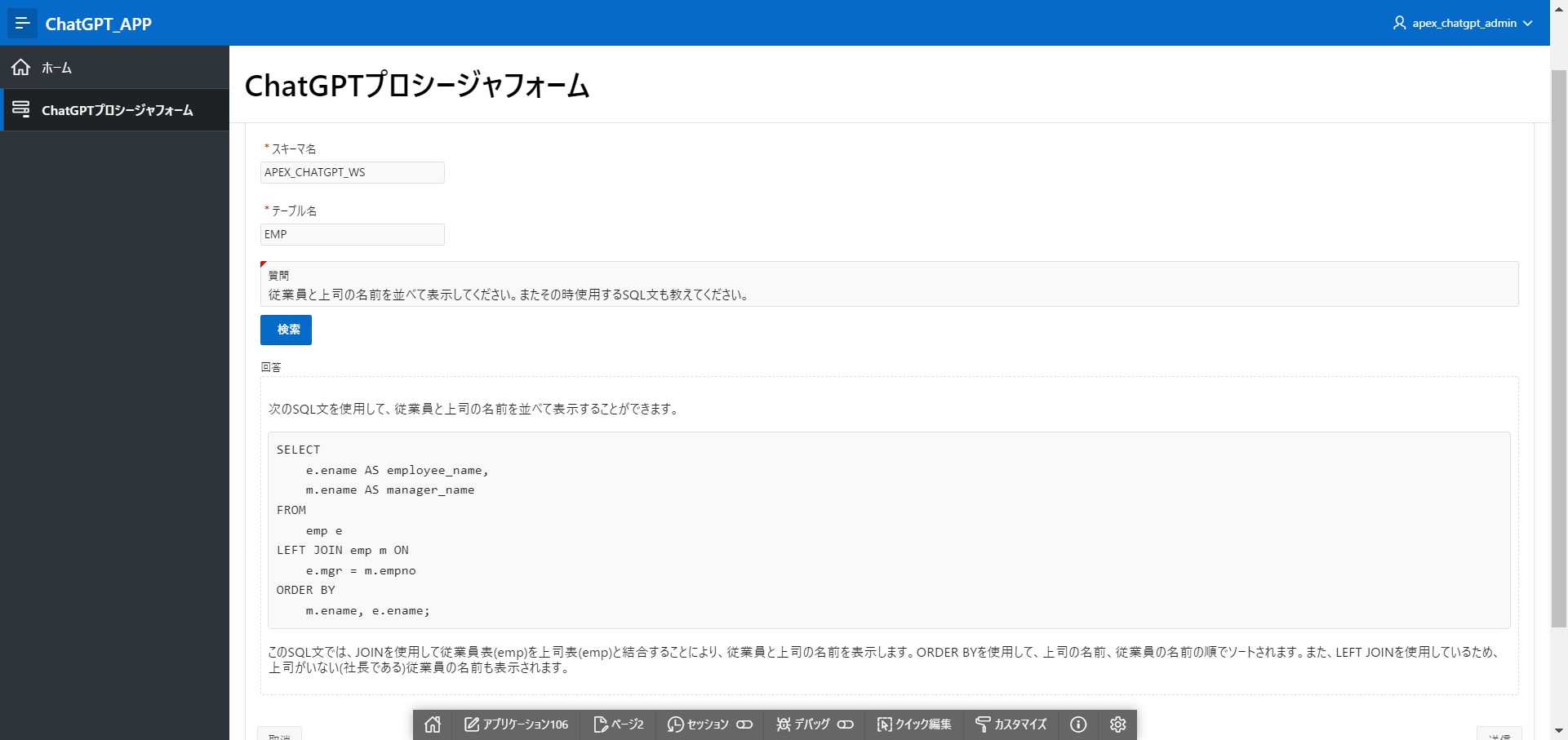
正しいSELECT文が返ってきましたが、こちらもアウトプットの量を減らすためか「従業員の名前と上司の名前を並べて表示してください」については無視されてしまいました。
おわりに
今回はある程度意図した回答を得られたときのサンプルを記載しておりますが、完全に誤りのない情報を得ることは難しいようで、不正確なレコード数や不正確な合計値を返してくることもありました。
得られる結果に注意を払う必要はありますが、適切に活用すればデータベース設計やアプリケーション開発に大きな貢献をしてくれる可能性を感じさせてくれる結果となりました。
Oracleの機能として大規模言語モデルが提供される日も近いかもしれませんね。
参考サイト
https://yaitcon.hashnode.dev/explain-view-sql-via-chatgpt-with-plsql
https://cosol.jp/techdb/2015/12/https_using_utl_http_how_to_aviod_ora-29024/
ブログの著者欄
採用情報


関連記事
-

【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-

ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

【イベントレポート・後編】GMO Developers Day 2025 -Creators Night-|共創するデザイン組織と次世代クリエイターの可能性
デザイン
-

【イベントレポート・中編】GMO Developers Day 2025 -Creators Night-|変化に挑むクリエイターのキャリアと成長
デザイン
-

【イベントレポート・前編】GMO Developers Day 2025 -Creators Night-|AI時代の「クリエイティブ」を探る夜
デザイン
-

【イベントレポート】社内から未来を体験する-「ロボ触ろうぜ!」
技術情報

KEYWORD
CATEGORY
-
技術情報(573)
-
イベント(218)
-
カルチャー(55)
-
デザイン(58)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- GPU
- GPUクラウド
- GTB
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP




採用情報
SNS FOLLOW
