
こんにちは。新里です。
Google Geminiが最近は色々と出してきていて、触ってみたくなってきました。そこで、Gemini Provision API (マルチモーダル)を使って画像の判別をしてみました。
目次
ワインのラベル判定
勢いでWeb上からワインのラベルをアップロードすると、対象のワインの情報を取得してくる物を作ってみました。プログラムに要した時間は1時間もかからない程度でした。
これはGoogle AI Studioが便利だった…というのもありますね。
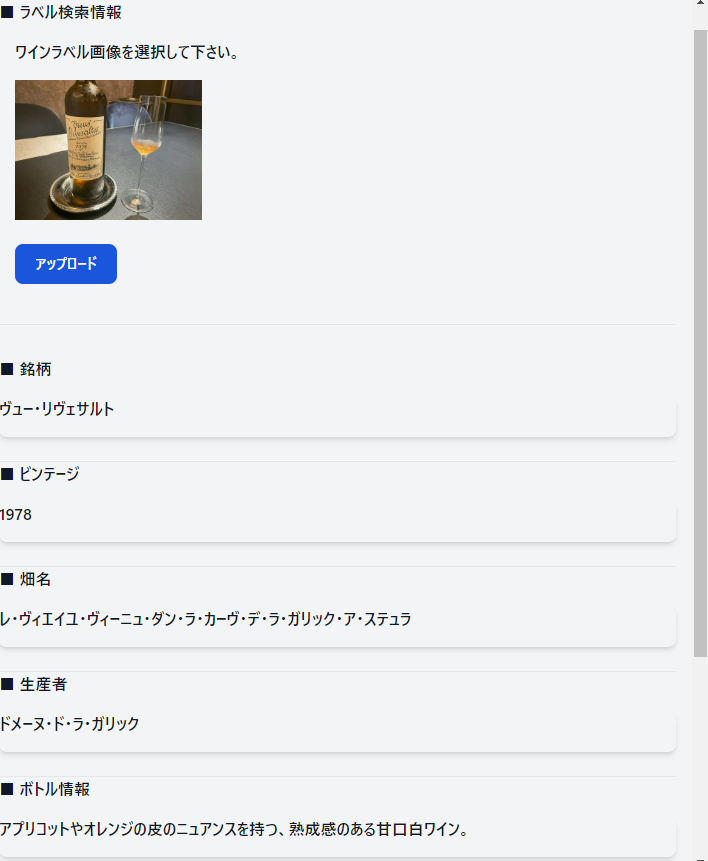
ローカルPCからワインのラベルがある画像をアップロードすると、対象のワイン情報を取得するものです。サクッと作ったついでに、GMOインターネットグループが2023年に行っていた「AIしあおうぜ」コンテストに出してみたら受賞にはなりませんでしたが、ピックアップ作品としてチョイスして頂きました。
Google AI Studioが便利
Google AI Studioは現在のところ英語版しかありませんが、いまの所は無料で使えるのでプロンプトやAPIを実験してみるにはお手軽な環境ですね。無料期間が2024年の初頭までみたいなので、いまのうちに使って遊んでみるのも良いです。

Google AI Studioの便利な所が、右上にある「Get code」から各種言語、Google Colabへのリンクもあって、プロンプトでテストしてみた内容をいきなりコード・Google Colab上で実際に動かすことが出来るのがめちゃくちゃ便利でした。
というのもあって、冒頭の1時間で実装できたというのも、この機能があってこそ…というのもあります。この辺のコードに展開する部分は他のサービスでは無いかなーと感じていたり、いかにもGoogleといった感じですね。

ここで生成されたコードを使うと簡単に自分のコードに入れ込めますね。僕の場合、フロントエンドはVue、バックエンドはPythonで作っていたので、組み込んだコードはこんな感じになりました。
class LabelImageView(APIView):
def post(self, request):
file = request.FILES['image']
genai.configure(api_key="your key")
# Set up the model
generation_config = {
"temperature": 0.4,
"top_p": 1,
"top_k": 32,
"max_output_tokens": 4096,
}
safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
}
]
model = genai.GenerativeModel(model_name="gemini-pro-vision",
generation_config=generation_config,
safety_settings=safety_settings)
image_parts = [
{
"mime_type": "image/png",
"data": file.read()
},
]
prompt_parts = [
"貴方はプロのソムリエです。この画像から銘柄・ビンテージ・畑名・生産者・ワインの説明を取得してきてください。結果はJSON形式で日本語のJSONにまとめてお願いします。\n\n",
image_parts[0],
]
response = model.generate_content(prompt_parts)
json_text = response.text
json_text = json_text.replace('```json', '')
json_text = json_text.replace('```', '')
data = json.loads(json_text)
return JsonResponse(data, safe=False)
PoCなので出力されたコードをほぼ、そのまま使っても全然普通に動きました。画僧ファイルを受け取ってGemini APIに投げているだけですね。最後に謎のreplaceをしているのは、LLMの応答としてそのままjson textを使えなかったので、jsonとして使えるように整形しています。
実は過去にも…
以前にもワインのラベル判定は実験的に検証をしていました。
ワインでもいかが? -Vol.02
この時は特徴点を使ったlabeling、近隣探索などなど…検証を行ってきましたが、うまくヒットさせることが難しかったでした。また、他のマルチモーダルは日本語や多言語が入ってくると、識字率が一気に下がってしまう問題もあります。多言語の文字を認識させるというは、なかなかハードルが高いですね。
Google Vision APIはOCRでも良いパフォーマンスを出しているというのもあって、この手の画像の中の文字認識をマルチモーダルとして扱う場合でも、非常によいパフォーマンスを出してくれました。
ただし、必ずしもラベルを正しく認識しているか?というとそうでもありませんでした。実際の画像とマルチモーダルが出してくる内容の差異を埋めるのは人の役目というわけです。
他の画像では?
他にもGeminiを使ってレシートを読み込みできるか?というのも試してみました。インボイス登録番号をレシートから判別して、実在性をチェックしてデータとして自動保存できるのでは?と。

レシートを色々と何枚か実験的に使ってみましたが、他のマルチモーダルで日本語が入ってきたり、この画像のように濡れ染みがあっても認識できるパフォーマンスを発揮できるのは、現時点では他にはありませんでした。
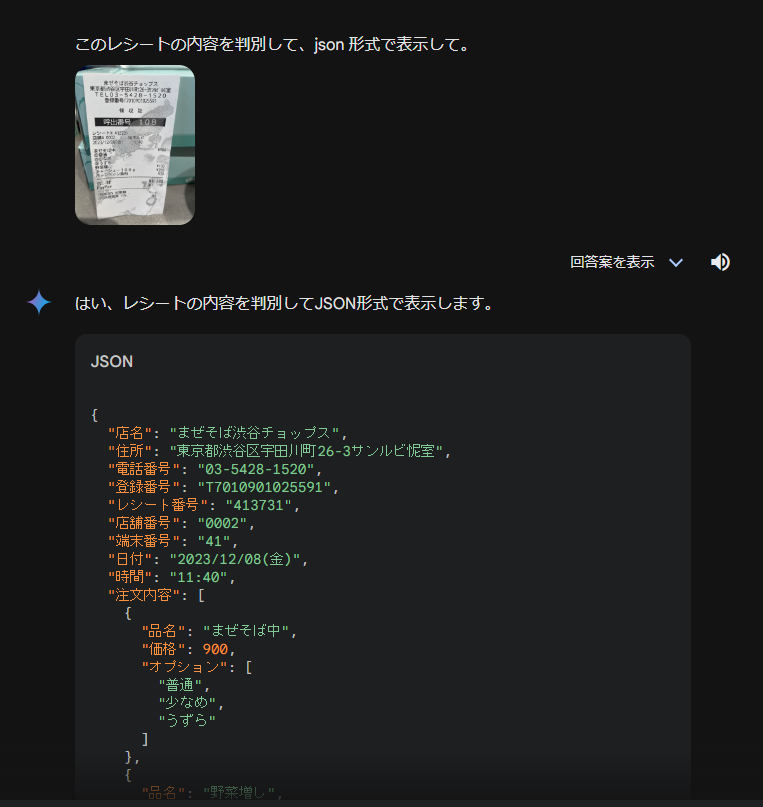
まさかここまで認識できるとは、かなり驚きです。
マルチモーダルの利活用
単純なOCRだけでは難しい処理がマルチモーダルLLMだと可能だと分かりました。従来は画像の中にある文字を読み取るだけでしたが、コンテキスト・意味がある物として読み取ることが出来る点が大きく違いますね。
画像の要素・コンテキストをプログラムが処理しやすい形式に変換するコンバーターとして、マルチモーダルLLMを使うという方法もアリなのかもしれません。
ブログの著者欄
新里 祐教
GMOインターネットグループ株式会社
プログラマー。GMOインターネットグループにて開発案件・新規事業開発に携わる。またオープンソースの開発や色々なアイデアを形にして展示をするなどの活動を行っている。
採用情報


関連記事
-

【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-

ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

【イベントレポート・後編】GMO Developers Day 2025 -Creators Night-|共創するデザイン組織と次世代クリエイターの可能性
デザイン
-

【イベントレポート・中編】GMO Developers Day 2025 -Creators Night-|変化に挑むクリエイターのキャリアと成長
デザイン
-

【イベントレポート・前編】GMO Developers Day 2025 -Creators Night-|AI時代の「クリエイティブ」を探る夜
デザイン
-

【イベントレポート】社内から未来を体験する-「ロボ触ろうぜ!」
技術情報

KEYWORD
CATEGORY
-
技術情報(573)
-
イベント(218)
-
カルチャー(55)
-
デザイン(58)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- GPU
- GPUクラウド
- GTB
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP




採用情報
SNS FOLLOW
