
旧来のIT運用からの脱却を目指し、日々奮闘しているプロジェクトマネージャーの視点から、Splunk Observability Cloudの導入によるシステムの可視化と、AIによるトラブル原因分析について初心者向けに解説します。
目次
はじめに
現代のIT環境はますます複雑化し、さまざまなシステムやアプリケーションが相互に依存しています。このような環境を効率的に管理し、問題を迅速に特定・解決するには、高度な可視化とモニタリングが不可欠です。そこで登場するのが、 Splunk Observability Cloudです。
本記事では、初心者向けにSplunk Observability Cloudを使用してシステムの可視化を実現する機能を紹介します。また、AIによるトラブルの原因分析も併せて取り上げます。
※具体的な導入手順や画面ショットは、Splunk社無料トレーニングコースでも閲覧可能ですので、そちらも合わせてご参照ください。
Splunk Observability Cloudとは?
Splunk Observability Cloudは、システムの状態やパフォーマンスをリアルタイムで監視し、データを可視化するための強力なツールです。Splunk Observability Cloudは以下のような主な機能を提供します
- メトリクスの収集と監視
- トレースやログの可視化
- 異常検知とアラートの設定
- ダッシュボードの作成とカスタマイズ
これにより、運用チームはシステムの健全性を常に把握することができます。
システムの可視化の基本手順
では、Splunk Observability Cloudを使用してシステムの可視化を実現する基本手順を見てみましょう。
1. Splunk Observability Cloudの導入
まず、Splunk Observability Cloudのアカウントを作成し、必要なソフトウェアを導入します。公式サイトから無料トライアル版も入手できるので、初心者でも気軽に始めることができます。
※公式サイト画像(こちらから利用登録申請できます)

2. データの収集
次に、監視したいシステムやアプリケーションからメトリクス、トレース、ログを収集します。さまざまなデータ収集エージェントが提供されており、簡単に組み込むことができます。
※データ収集に関する公式サイトの説明のリンク
3. ダッシュボードの作成
収集したデータを基に、Splunkのダッシュボードを作成します。これにより、複雑な情報を一目で把握できるようになります。ドラッグアンドドロップで簡単にカスタマイズできるため、技術的な知識が少なくても直感的に操作できます。
※デフォルトでダッシュボードのテンプレートが複数準備されています。
4. アラートの設定
異常を迅速に検出するために、アラートを設定します。特定のメトリクスがしきい値を超えた場合に通知を受け取るように設定することで、問題が深刻化する前に対処することが可能です。
※アラート設定に関する公式サイトの説明のリンク
5. Splunk Observability Cloudの各種機能の紹介
Splunk Observability Cloudはアプリ・インフラ双方の監視/管理が可能です。アプリはAPM(アプリケーション パフォーマンス監視)、インフラはIM(インフラストラクチャ監視)を用います。
◆APM(アプリケーション パフォーマンス監視)
自動的に生成されたサービス マップ、タグ分析、トレース検索を使用して、アプリケーションの依存関係を確認し、問題を切り分け、パフォーマンスを最適化します。
※サービスマップも自動生成されます。これで不具合箇所が一目瞭然です。例えば特定のAPI呼び出しに遅延が発生した場合、その原因がデータベースのクエリにあるのか、外部サービスとの通信にあるのかを特定できます。
※下記はデータベースのリクエストのリアルタイムグラフにおいて、スパイクしているグラフを確認し、具体的のどこの部分で遅延が発生しているかを、サービスマップで確認するサンプル画像です。
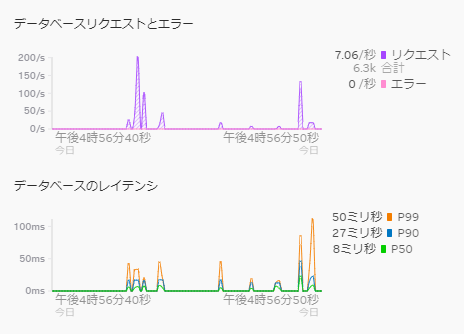
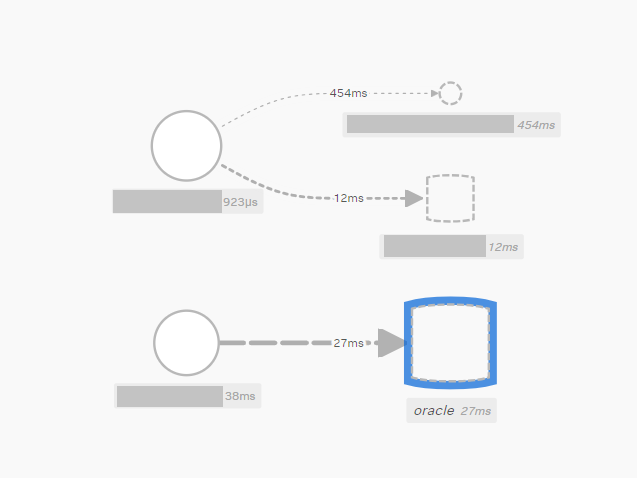
◆IM(インフラストラクチャ監視)
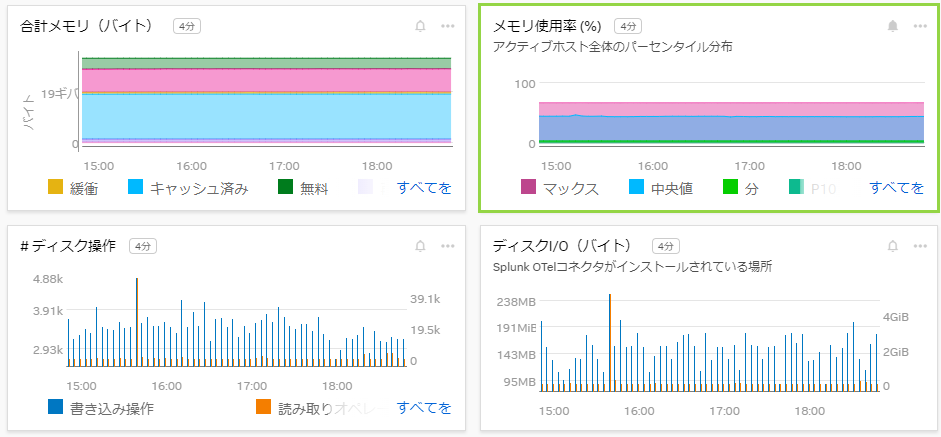
集計ビューでパターン、傾向、異常を見つけたり、個々のホスト、コンテナ、データベースなどの健全性、パフォーマンス、容量をリアルタイムで詳細に分析したりできます。
※メモリ使用率やディスクI/Oなど容易に監視することができます。例えばメモリ使用率の急上昇を検知し、どのアプリケーションが原因かを特定することで、迅速な対応が可能になります。
AIによるトラブル原因分析
Splunk Observability Cloudでは、AIを活用した問題解決も可能です。AIによる異常検知、根本原因分析を組み合わせることで、システムの運用管理が次のレベルに進化します。
1. AIによる異常検知
AIを活用することで、過去のパフォーマンスデータに基づいて異常な振る舞いを予測し、リアルタイムで通知することができます。これにより、特定の値に関して閾値を設けるなどの、単純なルールでは検知させるのが難しいものが、AIによって普段の傾向と異なる異常な状態として検知させられるようになります。
2. 根本原因分析
トレースやログデータをAIが解析のサポートをします。対話形式でAIに分析させることで、問題の根本原因を特定のするための情報収集の工数が削減出来ます。これにより、問題解決のスピードが飛躍的に向上します。
※Splunk社によるデモ動画が一般公開されています。
おわりに
Splunk Observability Cloudを使用することで、システムの可視化と監視が劇的に改善され、AIによるトラブル原因分析が新しいレベルの運用効率をもたらします。初心者でも簡単に始められるため、ぜひ試してみてください。
参考URL
[Splunk Observability Cloud公式サイト]
https://www.splunk.com/ja_jp/products/observability-cloud.html
[Splunk Observability 無料トレーニングコース]
https://www.splunk.com/ja_jp/training/free-courses/overview.html#observability
[Splunkの無料トライアル版]
https://www.splunk.com/ja_jp/download.html
これらのリソースを活用して、皆さんもシステム管理を効率化してみてください。
ブログの著者欄
佐藤 悠
GMOインターネットグループ株式会社
GMOインターネットグループ株式会社に入社後、運用チームのリーダーとして実業務面のマネジメントに従事。 その他、障害原因調査と再発防止策の立案、ベンダーコントロール、予算策定などを対応。 現在はプロジェクトマネージャーとして、運用の自動化やシステムの可視化機能を導入するプロジェクトを推進しています。
採用情報


関連記事
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート後編】
イベント
-

【2025国際ロボット展 出展レポート】AI ❤ ROBOTs で描く、人とロボットが共存する社会
技術情報
-

【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-

ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

【イベントレポート・後編】GMO Developers Day 2025 -Creators Night-|共創するデザイン組織と次世代クリエイターの可能性
デザイン
-

【イベントレポート・中編】GMO Developers Day 2025 -Creators Night-|変化に挑むクリエイターのキャリアと成長
デザイン

KEYWORD
CATEGORY
-
技術情報(574)
-
イベント(220)
-
カルチャー(55)
-
デザイン(58)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- GPU
- GPUクラウド
- GTB
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-
第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート後編】
イベント
-
【2025国際ロボット展 出展レポート】AI ❤ ROBOTs で描く、人とロボットが共存する社会
技術情報
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート前編】
イベント
-
【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-
ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

コールセンターでSpeech2Speech AIを繋ぐときに知っておきたい3つの接続方式
技術情報
採用情報
SNS FOLLOW
