
本記事はGMOインターネットグループで複数ある開発者ブログのなかから人気の記事をピックアップして再掲載しています。
機械学習や深層学習のビジネス応用を研究、社会実装をしているグループ研究開発本部 AI研究開発室のデータサイエンティストが寄稿した人気記事です。
目次
TL;DR
- フランスのAIスタートアップであるMistral AIは、2024年7月16日に Codestral MambaというLLMを発表・公開しました。これはコード生成に特化したLLMで、従来のTransformerに変わってMambaという新しいアーキテクチャーを採用しています。
- 公開されているCodestral Mambaをローカルで実行することも可能ですが、API keyを利用してOpen WebUIとLiteLLMを組み合わせてCodestral Mambaを実行してみました。Open WebUIを使うことでChatGPT風のGUIで、複数のLLMを簡単に切り替えたり同時に利用できるようになります。
- Mambaは状態空間モデルを利用することで、従来のTransformerよりも高速かつ効率的に長いcontext windowに対応できるとされています。Mambaは入力データをフィルタリングし、重要な情報のみを保持するSelection Mechanism、そしてGPUのメモリ構造を考慮した効率化、そして簡略化されたモデル構造が特徴です。
- 更にTransformerと状態空間モデルとの対応関係をヒントに、Mambaを改良したMamba-2というモデルも開発されています。Codestral Mambaは、このMamba2を応用したLLMとして開発されています。

Codestral Mamba
こんにちは、グループ研究開発本部・AI研究室のT.I.です。Mistral AIが、2024年7月16日に発表した「Codestral Mamba」という新しいLLMについて紹介します。Mistral AIとは、2023年にMetaやGoogle DeepMindの元従業員らによって創設されたフランスのAIスタートアップであり、これまでにMistral や Mixtral (Mistral の Mixture-of-Experts版)、Codestralなどのモデルを開発・公開してきました。今回新たに発表されたCodestral Mambaは、Code生成のタスクに特化したモデルです。Mistralのモデル名のお約束である「なんとかstral」はさておき、「Mamba」は一体何を意味しているのでしょうか?
今日のLLMの基盤技術であるTransformerは、様々なタスクに対して高い性能を発揮するものの、入力長の二乗に比例して計算コストが増えるという問題があります。以前に、それを克服する手法として状態空間モデルを応用したS4やHyenaと、その応用例(HyenaDNA
)をBlogで紹介してきました。今回のCodestral Mambaは、その発展系の1つである「Mamba(Mamba: Linear-Time Sequence Modeling with Selective State Spaces)」に基づいています。MistralはこのMambaに着目し、Codestral Mambaを開発しました。Mambaは、コブラ科のヘビの一属で、複数の種がアフリカに生息しています。高い毒を持っており、噛まれたら非常に危険です。それに因んでか、Mistral AIのCodestral Mambaの紹介では、以下のような文言が使われています。
As a tribute to Cleopatra, whose glorious destiny ended in tragic snake circumstances, we are proud to release Codestral Mamba, a Mamba2 language model specialised in code generation, available under an Apache 2.0 license.
(DeepLによる訳) 栄光の運命を悲劇的な蛇の境遇で終えたクレオパトラへのオマージュとして、コード生成に特化したMamba2言語モデル、Codestral MambaをApache 2.0ライセンスで公開する。
同日にMistral AIは、Mathstralという数学の問題を解くためのLLMも発表していますが、そちらはアルキメデス(287 BC-212 BC)の生誕2311周年記念(?)だそうです。
Mistral AIの発表によるとCodestral Mambaは、Mambaの発表者であるAlbert GuとTri Daoの両名の協力のもと開発されました。彼らは状態空間モデルに深く関わってきた研究者で、Albert GuはS4、Tri DaoはHyenaの論文の著者です。Codestral Mambaは、Transformerの代わりにMambaを採用することで、従来よりも高速かつ効率的に長いcontext windowに対応することができます。検証では、25.6万トークンまでの入力に対応できることが確認されています。
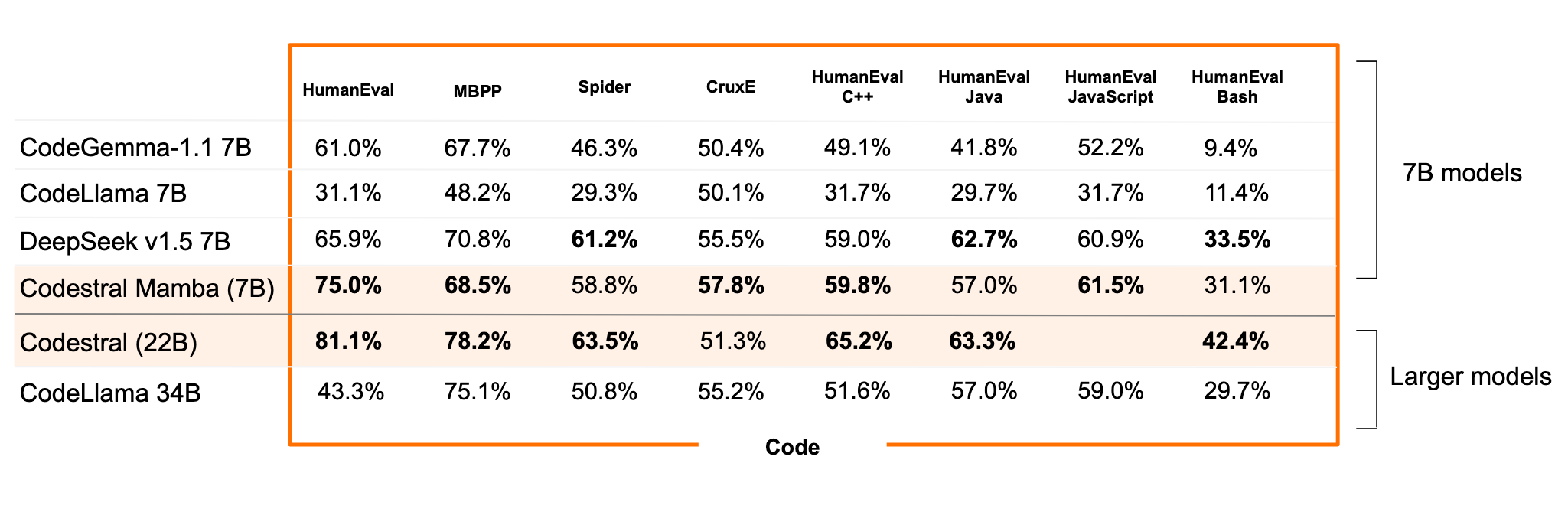
Codestral Mambaの性能。Codestral Mambaは、Code生成のタスクに特化したモデルです。その性能は、複数のベンチマークでSoTAを達成しています。Codestral Mambaは、7B parameter のモデルですが、Codestral (22B)と比較しても同程度の性能を発揮しています。
Codestral MambaをOpen WebUI(+LiteLLM)で動かしてみた
Codestral Mamba は、mistral-inference SDKやHuggingFaceでcheckpointをdownloadしてローカルで使用できます。簡単に使用するには、Mistral AIのLa Plateforme (https://console.mistral.ai/)にアクセスして、API KEYを取得するのが良いでしょう。今回はそのAPIを使用して、Open WebUIとLiteLLMを組み合わせて、ChatGPT風のGUIで使ってみました。
Open WebUIとは、ChatGPTっぽいUIでChatGPT(APIを使用)や、ローカルのLLMを使用できるアプリケーションです。異なるLLMを簡単に切り替えて利用できます。また、これにLiteLLMで建てたサーバーに接続することで、ChatGPTやGeminiなどのモデルを同時に利用できます(要API KEY)。こちらの記事を参考に環境を構築しました(Open WebUIがすごい)。この記事の場合AWS Bedrockへ接続していましが、今回は各種API KEYを利用して、ローカルで構築しました。なお、GPT-4oも利用できるように、Open AI APIとGPT-4oのモデルも追加してあります。
Docker Composeを使って、Open WebUIとLiteLLMのコンテナを立ち上げます。compose.yamlはこうして
services:
open-webui:
image: ghcr.io/open-webui/open-webui
container_name: open-webui
volumes:
- open-webui:/app/backend/data
ports:
- 8080:8080
environment:
- 'WEBUI_SECRET_KEY='
- 'ENABLE_OLLAMA_API=false'
- 'OPENAI_API_BASE_URL=http://litellm:4000'
- 'OPENAI_API_KEY=sk-12345' # これはただのdummyなので適当で大丈夫です
litellm:
image: ghcr.io/berriai/litellm:main-stable
environment:
- 'OPENAI_API_KEY=${OPENAI_API_KEY}'
- 'MISTRAL_API_KEY=${MISTRAL_API_KEY}'
volumes:
- ./litellm/config.yaml:/config.yaml
command: [ "--config", "/config.yaml" ]
volumes:
open-webui: {}利用するモデルについては、compose.yamlのあるディレクトリ以下にlitellm/config.yamlを配置して、以下のように設定します。
model_list:
- model_name: OpenAI / gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
- model_name: Mistral / Codestral Mamba
litellm_params:
model: mistral/codestral-mamba-latest
api_key: os.environ/MISTRAL_API_KEY環境変数で各種API KEYを設定して、docker compose upで立ち上げるだけです。簡単ですね。Open WebUIをブラウザで開いてアカウントを作成すると、既視感たっぷりな画面が表示されます。
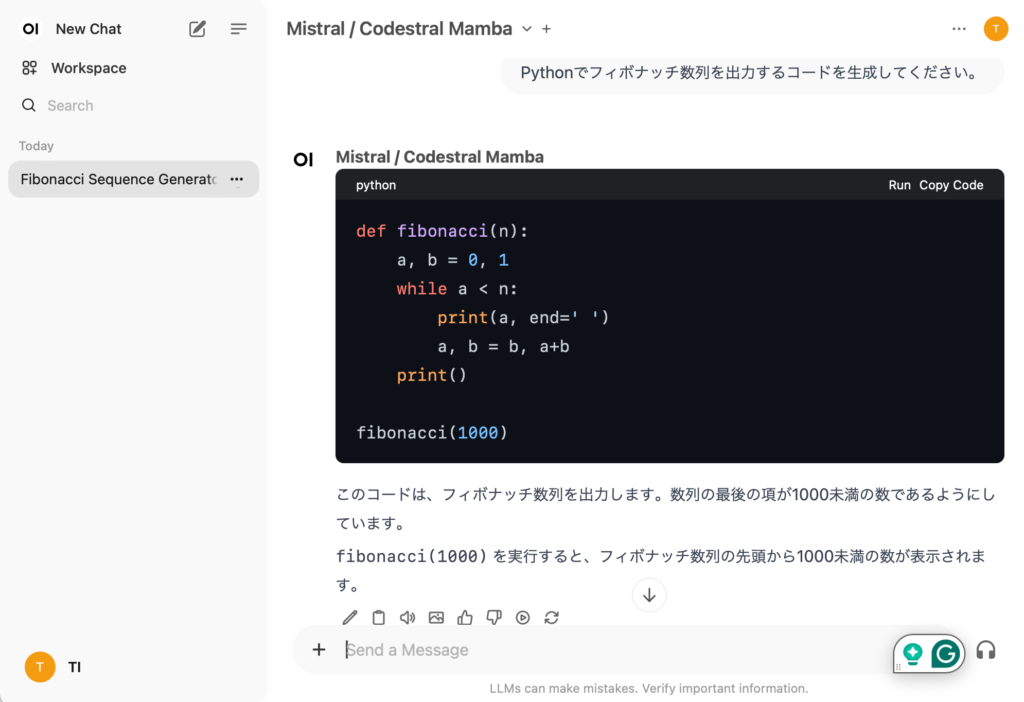
モデルとして、先ほどconfig.yamlで設定したモデルが表示されていますので、Codestral Mambaを選択して、あとはChatGPTと同じように使えます。Codestral MambaによるCode生成の結果の例。いくらか簡単な例を生成して試しただけですが、それなりにうまく生成してくれる感じです。生成速度もGPT-4oと比べても同程度で高速でストレスなく利用できます。
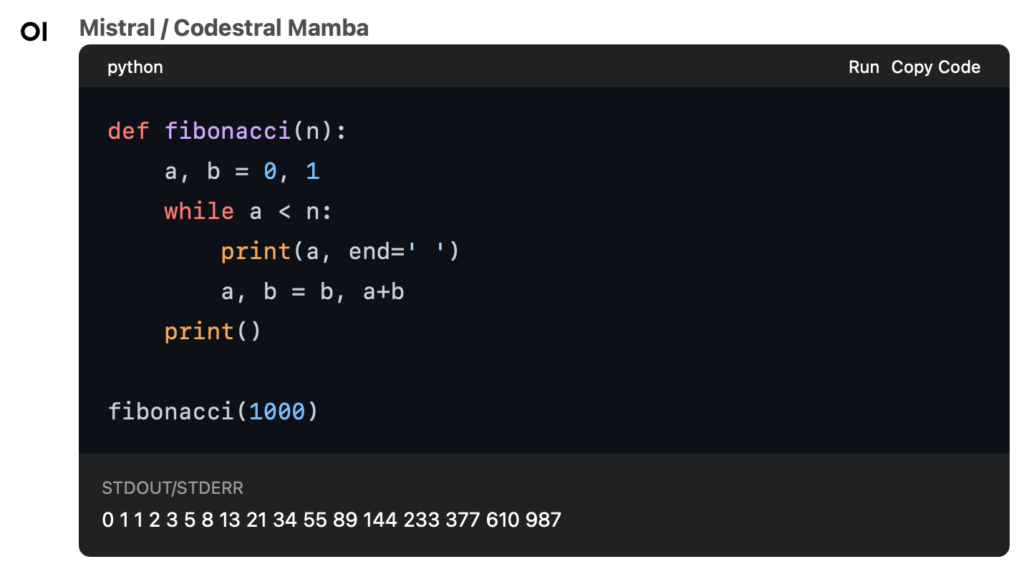
ChatGPTなどでは、出力したコードのブロックには、コピーするボタンが付いていますが、Open WebUIの場合、更にRunというプログラムをその場で実行できる機能が付いています。特殊なライブラリが不要な標準的なコードに関しては、そのまま実行して結果を確認できます。
Open WebUIの面白い機能として、複数のLLMを同時に利用できます。簡単な生成結果の比較には十分に使えるかもしれません。

なお、頑張ればいくらでもモデルを追加して同時実行可能です。下記の例は、GeminiやClaude、ChatGPTの複数のモデルを同時に実行しています。あまり多すぎるのも五月蝿くて使いにくいですので、精々2〜3個程度が限界かと思います。

Mambaって何ですか?
さて、とりあえずCodestral Mambaを試すことはできましたが、Mambaとは一体何でしょうか?既存のLLMでは、計算コストが入力長の二乗に比例して増大するという問題があります。これはLLMの根幹になっているTransformerが、入力されたトークン間の組を全て評価するという原理的な弱点であります。これを解決する有力なアプローチとして状態空間モデル(State space model)を使った研究が注目されています。状態空間モデルとは、入力 u に対してシステム内部の状態 x を通じて出力 y が生成されるモデルです。時系列データや制御システムのモデリングに広く使われています。
x˙(t)=A(t)x(t)+B(t)u(t),y(t)=C(t)x(t)+D(t)u(t)
この状態空間モデルを応用することで、計算コストの増加が入力長の二乗ではなく線形になるという利点があります。過去のBlogで紹介したS4やHungry Hungry Hippos (H3)、そしてHyenaなどがその代表例です。ここ最近、LLMやVLM、Stable Diffusionなどの紹介にかまけて手付かずでしたが、状態空間モデルに基づく研究も着実に進んでおります。その中でも特に注目されているものの1つが、昨年末に発表された「Mamba (Mamba: Linear-Time Sequence Modeling with Selective State Spaces)」です。日本ではKotoba technologyが、Mambaを日本語でも学習させた Kotomambaという2.8B parameterのLLMを発表しています。更にMambaの改良版であるMamba2 (Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality)が登場し、Codestral Mambaは後者を元にコード生成に特化したLLMとして開発されています。日本語でのわかりやすい解説としては、「 【Mamba入門】Transformerを凌駕しうるアーキテクチャを解説(独自の学習・推論コード含む)」が分かりやすくまとまっていますので、興味のある方は参照してみてください。
MambaとSelection Mechanism
Mambaの重要なポイントは以下の3つです。
- Selection Mechanism: 入力データに対して、重要でない情報をフィルタリングし重要な情報のみを保持
- Hardware-aware Algorithm: GPUのメモリ構造を考慮した効率化
- シンプルなモデル構造: H3やHyenaではTransformerに類似したQuery-Key-Valueの構造を持っていましたが、Mambaではそれらを更に簡略化した構造を採用
S4では、状態空間モデルのパラメーターとして、行列 A,B,C があります。
h′(t)=Ah(t)+Bx(t),y(t)=Ch(t)
これを時間の刻みを離散化(Δ)して、変数を変換すると
ht=A―ht−1+B―xt,yt=C―ht
これは最終的に1次元の畳み込み演算で処理できます。
K―=(CB―,CAB―,…,CA―kB,…),y=x∗K―
S4では、これを効率的に計算するために行列に関しては特殊な条件を課しています。計算の効率は良いものの(A―,B―)は、時間のステップに依存しない一定の定数となっています。このLinear Time Invariance(LTI)という性質が、State Space Modelの計算効率と引き換えにある種のタスクへの性能を制限していました。この解決のために著者らが考案したものが、Selective State Space Modelsです。
TransformerのAttentionでは、情報を圧縮することなく全てのcontextを保持することで高い性能を発揮しますが、非効率でした。一方のRecurrent Neural Network(RNN)は、情報を圧縮することで計算効率を向上させていますが、性能としてはTransformerに劣ります。Selective State Space Models は、情報を圧縮する以下の2つのタスクに同期づけられて開発されています。
- Selective Copying taskは、ランダムな位置にある覚えるべき重要なトークンをコピーする
- Induction Heads taskは、覚えるべきトークンが文脈に応じて変化し、それを記憶・回答
下記は、Copying taskとSelective Copying task, Induction Heads taskの概念図になります。色がある部分が重要な箇所で、黒は特殊なトークンを表しています。Copying taskでは、重要な情報が一定の位置にあるためにS4のようなLTIの性質を持つSSMで対応できます。しかし、Selective Copying taskでは、重要な情報はランダムに配置されています。また、Induction Heads task の場合では、黒のトークンの直前にあるものを覚えて回答する必要があります。これらのタスクに対しては、入力に動的に対応する必要があるためS4のようなLTIの性質を持つSSMでは処理が難しいです。
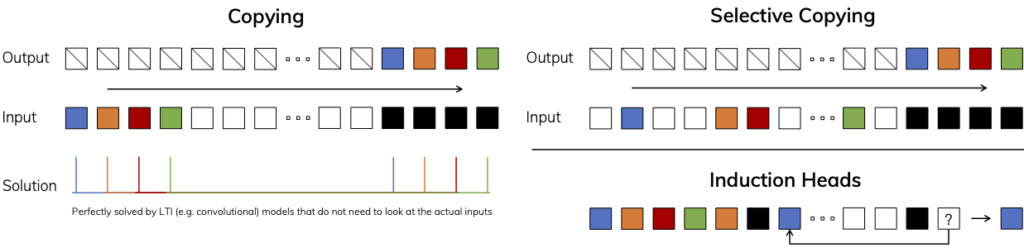
このSelection Mechanismに対応するために、Mambaの論文では、SSM(S4)を改良したSSM+Selection(S6)という新しいアルゴリズムを導入しています。S6では、入力に応じて B と C、Δを動的に変化させます。

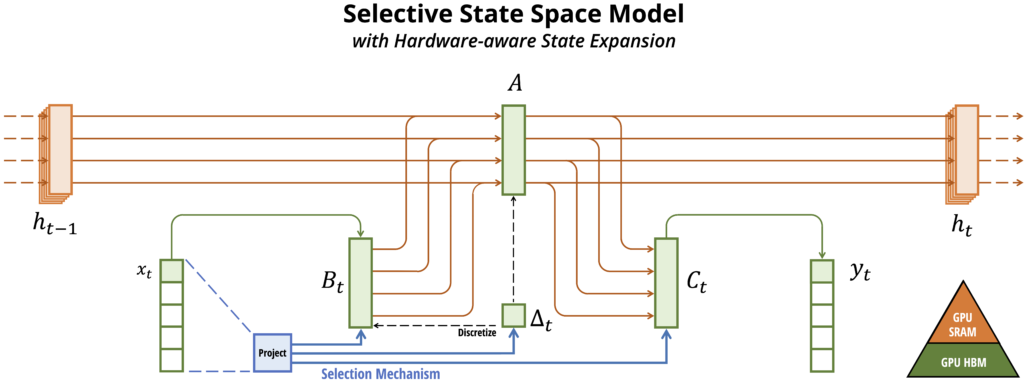
Selective State Space Modelでは、S4で出来ていたような畳み込みでの計算効率化が出来ません。そこで、GPUのメモリ構造に合わせた効率化を行っています。GPUでは、HBM(High Bandwidth Memory)という大量・低速なメモリとSRAMという小容量・高速なメモリを組み合わせて使用しています。これらのメモリ間のデータのやり取りを減らすことで、計算効率を向上させています。以下は、その概念図となります。色は、各々のデータがどのメモリで処理されているかを示しています。入力 x に対して出力 y の計算には、latent state h や、各行列 A,B,C などの情報が必要ですが、SRAMを活用することで、HBMとのデータの移動を減らしています。
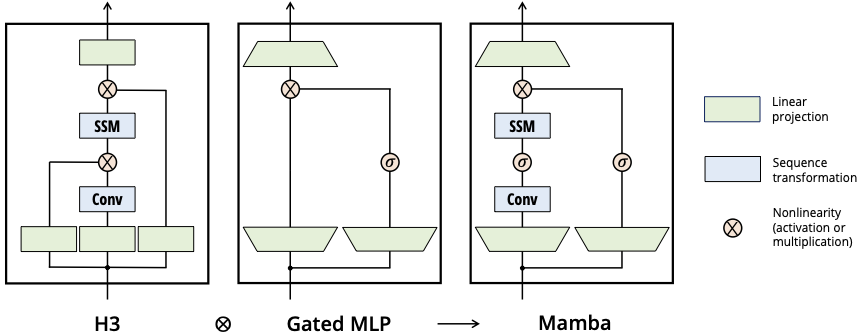
Mambaのモデル構造は、下記の通りです。Hungry Hungry Hippos(H3)やHyenaが採用してた、Transformerに類似したQuery-Key-Valueの構造を持っていましたが、それらを更に簡略化した構造を採用しています。
以上のようにして考案されたMambaは、状態空間モデルをもとにしたfoundation modelで、計算効率の高さとTransformerに匹敵する性能さを両立しています。Mambaの論文中では、Selective Copying task, Induction Heads taskでのS6 Algorithmの有用性を検証し、自然言語処理やDNA sequence modeling、更に音声データ生成などのタスクでの従来のモデルとの性能評価を実施しています。Mambaが発表されたのは、2023年末ですが、その後、Mambaを応用した様々な研究が続々と発表されています。Awesome-Mamba-Papers (https://github.com/yyyujintang/Awesome-Mamba-Papers)に、まとめられています。Mambaに関する研究は、以下のように非常にハイペースで出ていることがわかります。
- (Arxiv 23.12.01) Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- (Arxiv 24.01.08) MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts
- (Arxiv 24.01.24) MambaByte: Token-free Selective State Space Model
- (Arxiv 24.01.31) LOCOST: State-Space Models for Long Document Abstractive Summarization
- (Arxiv 24.02.01) BlackMamba: Mixture of Experts for State-Space Models
- (Arxiv 24.02.06) Can Mamba Learn How to Learn? A Comparative Study on In-Context Learning Tasks
- (Arxiv 24.02.08) Mamba-ND: Selective State Space Modeling for Multi-Dimensional Data
- (Arxiv 24.02.15) Hierarchical State Space Models for Continuous Sequence-to-Sequence Modeling
- (Arxiv 24.02.19) Pan-Mamba: Effective pan-sharpening with State Space Model
- (CVPR24) State Space Models for Event Cameras
- (Arxiv 24.02.26) DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models
- (Arxiv 24.03.03) The Hidden Attention of Mamba Models
- (Arxiv 24.03.08) MamMIL: Multiple Instance Learning for Whole Slide Images with State Space Models
- (Arxiv 24.03.11) MambaMIL: Enhancing Long Sequence Modeling with Sequence Reordering in Computational Pathology
- (Arxiv 24.03.12) Motion Mamba: Efficient and Long Sequence Motion Generation with Hierarchical and Bidirectional Selective SSM
- (Arxiv 24.03.13) ClinicalMamba: A Generative Clinical Language Model on Longitudinal Clinical Notes
- (Arxiv 24.03.26) State Space Models as Foundation Models: A Control Theoretic Overview
- (Arxiv 24.03.28) Jamba: A Hybrid Transformer-Mamba Language Model
- (Arxiv 24.03.29) HARMamba: Efficient Wearable Sensor Human Activity Recognition Based on Bidirectional Selective SSM
- (Arxiv 24.04.07) VMambaMorph: a Visual Mamba-based Framework with Cross-Scan Module for Deformable 3D Image Registration
- (Arxiv 24.04.12) SpectralMamba: Efficient Mamba for Hyperspectral Image Classification
- (Arxiv 24.05.13) MambaOut: Do We Really Need Mamba for Vision?
- (Arxiv 24.05.19) NetMamba: Efficient Network Traffic Classification via Pre-training Unidirectional Mamba
- (Arxiv 24.05.23) EHRMamba: Towards Generalizable and Scalable Foundation Models for Electronic Health Records
- (Arxiv 24.05.26) Mamba4KT: An Efficient and Effective Mamba-based Knowledge Tracing Model
- (Arxiv 24.05.26) Zamba: A Compact 7B SSM Hybrid Model
- (Arxiv 24.05.30) MSSC-BiMamba: Multimodal Sleep Stage Classification and Early Diagnosis of Sleep Disorders with Bidirectional Mamba
Transformersは状態空間モデルである: MambaからMamba-2へ
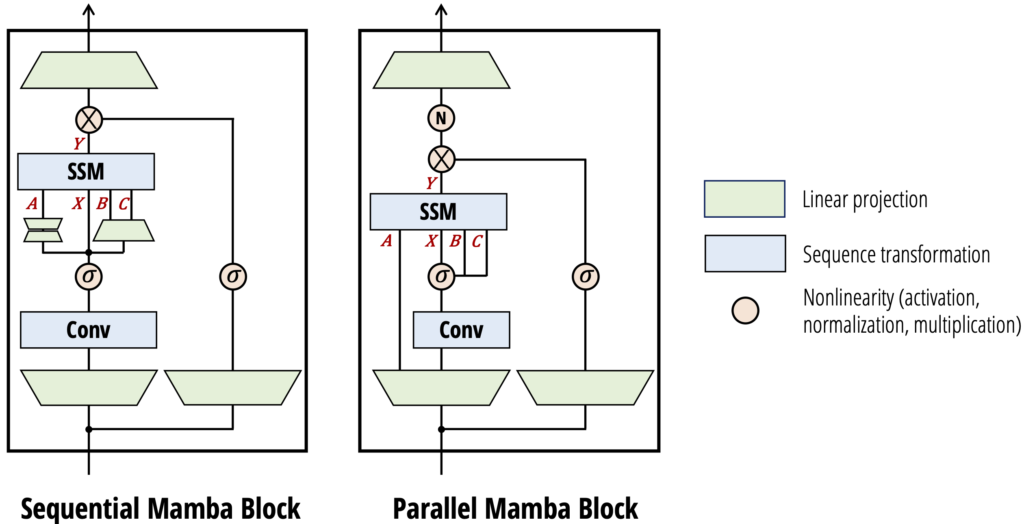
さて、Tri DaoとAlbert Guの両名がICML2024で「Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality」(https://icml.cc/virtual/2024/poster/32613,https://arxiv.org/abs/2405.21060)という発表をしました(2024年7月24日)。その中で、Mambaの改良版としてMamba-2を発表しました。Codestral Mambaは、このMamba-2をベースにして開発されています。この研究では、従来のTransformerとSSMの関係を明らかにし、その関係を利用して、より効率的なモデルを設計する方法を提案しています。以下は、State Space Model と Attention、およびStructured Matricesという概念の関係性を示す図です。
S4などの論文でも議論されていましたが、ある特殊な構造を持つ行列(Structured Matrices)を利用することで、SSMの計算効率を向上させることができます。この研究では、Structured MatricesとAttention、SSMとAttentionの関係性を解き明かしています。このDuality(双対性)というものは、異なる2つの概念が実は表裏一体のものであることを指す言葉です。これらの対応関係を解き明かすことで、これまでに他の分野の研究で得られていた知見をSSMへと応用することが可能になります。Mamba-2では、この双対性を応用しモデル構造を改良し、従来のMambaから2-8倍もの高速化に成功しました。
まとめ
今回のBlogでは、Mistral AIが発表したCodestral Mambaについて、Open WebUIを使ったデモと、MambaというTransformerを置き換える可能性のある新技術を解説しました。Mambaの紹介が主だったので、あまり触れませんでしたが、Open WebUIは、GPTsのような機能や、ファイルの読み込みなどの多くの機能がありますので、興味のある方はぜひ試してみてください。(参考資料「Open WebUI (Formerly Ollama WebUI) がすごい」、「Open WebUI (Formerly Ollama WebUI) がすごい2(RAGもすごい)」)これまで状態空間モデルを使った研究は、着々と進められてはおりましたが、基礎研究が多く実用的なモデルはあまり出ていませんでした。今回、Mistral AIがMambaを採用したことでTransformerに依存しないfoundation modelが続々と登場する可能性があります。Mambaが一般化すると、Transformerを基盤としていた従来のモデルでは難しい長い入力長へのタスクが実現し、効率化することが期待されます。
さて、これからMambaが興味深いと調べると、2024年7月15日には、Tri DaoとAlbert Guらによる新しい研究が発表されていました。「Hydra: Bidrectional State Space Models Through Generalized Matrix Mixers(https://arxiv.org/abs/2407.09941)」蛇の次はHydraですか、Medusaとか出てきそうですね。

グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。

参考文献
- Mistral AI Codestaral Mamba https://mistral.ai/news/codestral-mamba/
- Open WebUI https://openwebui.com
- LiteLLM https://www.litellm.ai
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces arXiv:2312.00752 https://arxiv.org/abs/2312.00752
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality arXiv:2405.21060 https://arxiv.org/abs/2405.21060
- 過去のBlogでの状態空間モデルに関する記事
・「Is Attention All You Need? Part 1 Transformer を超える(?)新モデルS4」https://recruit.gmo.jp/engineer/jisedai/blog/is-attention-all-you-need/
・「Hyena: 次世代LLMへ向けたTransformerを超える新機械学習モデル Is Attention All You Need? Part 3」https://recruit.gmo.jp/engineer/jisedai/blog/hyena/
・「HyenaDNA: DNAの言語を読み解くLLMの新たなる応用」https://recruit.gmo.jp/engineer/jisedai/blog/hyenadna/
ブログの著者欄
グループ研究開発本部
GMOインターネットグループ株式会社
グループ研究開発本部とは、GMOインターネットグループの事業領域で力を入れているスタートアップやグループ横断のプロジェクトにおいて、技術支援・開発・解析などを行い、ビジネスの成功を支援する部署です。 最新のテクノロジーを研究開発し、いち早くビジネスに投入することで、お客様の発展と成功に貢献することを主要なミッションとしています。
採用情報


関連記事
-

【イベントレポート・後編】GMO Developers Day 2025 -Creators Night-|共創するデザイン組織と次世代クリエイターの可能性
デザイン
-

【イベントレポート・中編】GMO Developers Day 2025 -Creators Night-|変化に挑むクリエイターのキャリアと成長
デザイン
-

【イベントレポート・前編】GMO Developers Day 2025 -Creators Night-|AI時代の「クリエイティブ」を探る夜
デザイン
-

【イベントレポート】社内から未来を体験する-「ロボ触ろうぜ!」
技術情報
-

【開催レポート・後編】第5回 京大ミートアップ|フィジカルAI最前線
技術情報
-

CES 2026参加レポート:事前調査編
技術情報

KEYWORD
CATEGORY
-
技術情報(571)
-
イベント(216)
-
カルチャー(55)
-
デザイン(58)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AI人財
- AMD
- APT攻撃
- AWX
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- GPU
- GPUクラウド
- GTB
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP






採用情報
SNS FOLLOW
