
この記事は「GMOインターネットグループ Advent Calendar 2024」10日目の記事です。
みなさまこんにちは。GMO NIKKO株式会社の春田と申します。
生成AI関連サービスが群雄割拠するようになった昨今、いかがお過ごしでしょうか?
今回はOpenAIのモデルであるGPT-4o-miniモデルをファインチューニングし、Web記事のカテゴリをローコスト&高速に予測するために実装したことや注意点について紹介していこうと思います。
目次
はじめに
Web広告の運用にあたっては、Webメディア・コンテンツが提供する内容を理解することが重要です。特にプライバシー問題が提起されるようになってきた昨今では、個々のユーザにミートするような運用の困難性が上がっていることから、Webコンテンツの分析の需要はますます高まっていくと考えられます。
GPTモデルの導入
今回使用したのは、OpenAIが公開している gpt-4o-mini モデルです。こちらを選択した理由としては以下のようなものがあります。
- ファインチューニング可能なモデルの中で高精度かつ、今回出力として必要なのは文章ではなく1つのカテゴリなので
gpt-4oまで使わなくてもgpt-4o-miniで十分 - 入力1M Token当たり $0.3 と非常に安価1
「カテゴリ」の定義とTokenizerについて
Webコンテンツに対して「カテゴリ」を定義する必要があります。これは独自定義でも事前に定義された一覧でもなんでも良いですが、相当細分化しない限り基本的には1000を超えることはないものとします。また、カテゴリ自体に親子関係のない1階層分のみをコンテンツに付与することを考えます。
OpenAIのGPTモデルなどに用いられているTokenizerの動作は、こちらのページから確認することが可能です。Token自体の説明は割愛しますが、同じ色で着色された0 ~ 999までの数値は1 Tokenとして認識され、1000以降は2 Tokenに分割されることがわかります。2
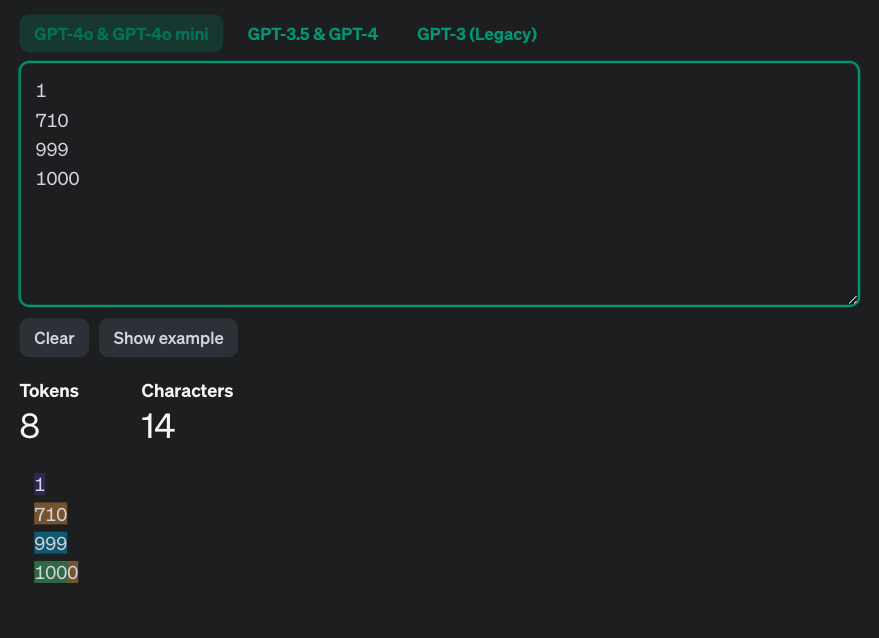
つまり、それぞれのカテゴリーを数値化して0 ~ 999に対応させることで、必ず1 Tokenとして扱うことができます。この事は後述するファインチューニングで関係してきます。3
GPTモデルのファインチューニング
gpt-4o-mini モデルをファインチューニングします。チューニングはOpenAIのWebUI上でも簡単にできますが、今回はPythonを使用してOpenAIクライアントライブラリからデータファイルとjobを投げます。OpenAIのアカウント設定とAPI_KEY、組織IDを既に取得していることを仮定しています。
ここで、学習用ファイルとしてtrain_data.jsonlを、検証用ファイルとしてval.jsonlをあらかじめ作成しておきます。
{"messages": [{"role": "system", "content": "与えられた文章のカテゴリを数字で予測してください"}, {"role": "user", "content": "[コンテンツA] ->"}, {"role": "assistant", "content": "1"}]}
{"messages": [{"role": "system", "content": "与えられた文章のカテゴリを数字で予測してください"}, {"role": "user", "content": "[コンテンツB] ->"}, {"role": "assistant", "content": "2"}]}
{"messages": [{"role": "system", "content": "与えられた文章のカテゴリを数字で予測してください"}, {"role": "user", "content": "[コンテンツC] ->"}, {"role": "assistant", "content": "63"}]}
.
.
.各行の末尾にある"assistant"の応答内容を見てください。こちらが先ほど言っていたコンテンツカテゴリに対応する0 ~ 999のカテゴリIDになります。
from openai import OpenAI
import os
os.environ["API_KEY"] = "sk-xxxxxxxxxxxxxxxxxxxx"
# APIキーの設定
client = OpenAI(
api_key=os.environ["API_KEY"],
organization='org-xxxxxxxxxx',
)
train_data_path = "train_data.jsonl"
val_data_path = "val.jsonl"
client.files.create(
file=open(train_data_path, "rb"),
purpose="fine-tune"
)
client.files.create(
file=open(val_data_path, "rb"),
purpose="fine-tune"
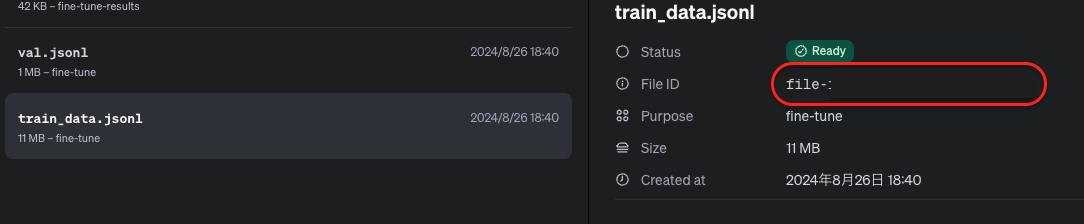
)OpenAIにファインチューニング目的でそれぞれのファイルをアップロードします。こちらのjobが完了すると、OpenAIのダッシュボードのストレージ一覧にアップロードしたファイルの一覧が表示されています。それぞれのファイルのFile IDは続くファインチューニングjobで使用します。
client.fine_tuning.jobs.create(
training_file="file-xxxxxxxxxxxxxxxx",
validation_file="file-yyyyyyyyyyyyyyyy",
model="gpt-4o-mini-2024-07-18",
hyperparameters={
"n_epochs": 3,
#"batch_size": 32,
#"learning_rate_multiplier": 1.8
}
)上述のコードでファインチューニングjobの実行が可能です。以下のことに注意しつつパラメータを設定してください。
training_fileとvalidation_fileは先ほど確認したFile IDを指定modelは使用したいベースモデル名を指定4hyperparametersはさらに以下を設定しますepochs: epoch数の設定。学習用データを一巡する回数のことです。batch_size: バッチサイズの設定。基本的に設定する必要はないと思います。learning_rate_multiplier: 学習率のスケーリングの因子。過学習や未学習にならないよう適切な値を設定する必要があります。指定しなければ自動で良さそうな値に後から設定されます。
注意したいのはhyperparametersのn_epochsの設定です。こちらも指定しなければ自動的に決定されて学習が進んでいきますが、学習コストに大いに影響する部分のため、一旦テストで学習ジョブを走らせる場合などで事前に設定したいケースもあるかと思います。コストは以下の計算式になります。
入力ファイル全体Token数 × n_epochs × (100万入力トークンあたりの学習コスト ÷ 100万)単純に考えて入力ファイルのToken数が多い場合、epoch数が増えるとその倍数分だけ増えることになります。感覚的には大体3 ~ 4程度で問題ないと思います。
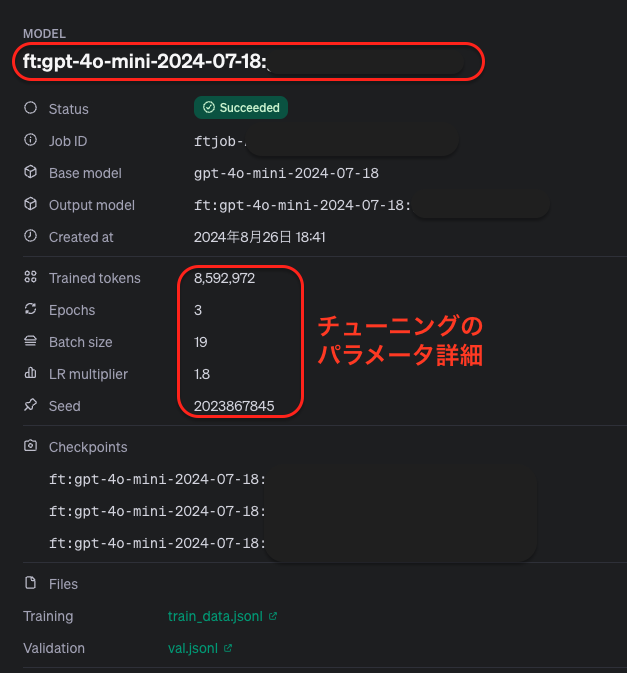
これらを行うことで、以下のように実際に用いられたパラメータを含むチューニング済みモデルの詳細をWebUI上で確認することができます。ここで確認できるMODEL IDは推論時に必要となります。
推論時の並列処理の実装
学習したモデルを使用して実際にカテゴリを予測していきます。予測のためのデータファイルは既に用意されているという前提で話を進めます。
Webコンテンツというものは今やインターネット上で膨大に存在し、完全新規で作成されるものから既存のものが頻繁に更新されるものまでリアルタイムに増えていきます5。そのため、予測対象のデータ数も多くなりがちです。何も考えずにOpenAIのAPIを叩くコードを書くと処理が直列のため、捌くのに時間がかかってしまいます。
そこで、本記事ではPython Pandas内の処理を手軽に並列処理し高速化するPandarallelというライブラリを使用します。
from pandarallel import pandarallel
import pandas as pd
import numpy as np
import time
from openai import OpenAI
# 同時処理件数
MAX_PREDICTION_COUNT = 8000
# 最大ワーカー数
MAX_WORKERS = 20
pandarallel.initialize(nb_workers=MAX_WORKERS)
def categorize(df):
for i in range(0, len(df), MAX_PREDICTION_COUNT):
if i != 0:
time.sleep(60)
df_part = df[i:i + MAX_PREDICTION_COUNT]
df_part.loc[:, ['predictions', 'probs']] = df_part.parallel_apply(lambda row: get_openai_response(row), axis = 1)
if i == 0:
result_df = df_part
else:
result_df = pd.concat([result_df, df_part], ignore_index = True)
return result_df
def get_openai_response(row):
try:
openAI_client = OpenAI(
api_key = API_KEY,
organization = ORGANIZATION_ID,
)
pred_categories = []
pred_probs = []
response = openAI_client.chat.completions.create(
model = MODEL_ID,
messages = row['prompt'],
temperature = 0,
logprobs = True,
top_logprobs = TOP_LOGPROBS,
max_tokens = 1,
)
pred_contents = response.choices[0].logprobs.content[1].top_logprobs
for pred_content in pred_contents:
pred_categories.append(int(pred_content.token))
pred_probs.append(np.exp(pred_content.logprob))
except Exception as e:
pred_categories = [-1 for _ in range(TOP_LOGPROBS)]
pred_probs = [0.0 for _ in range(TOP_LOGPROBS)]
return pd.Series({'predictions': pred_categories, 'probs': pred_probs})parallel_apply関数によって、データフレームの1行ごとに処理する独自処理を定義し並列実行することが可能です。コード内のAPI_KEY、ORGANIZATION_ID、MODEL_IDはそれぞれ書き換える必要があります。プロンプトを適切に設定したPandas.Dataframeをcategorize関数に投げればGPTモデルによるカテゴリ予測が開始されます。
注意点として、OpenAIのAPIが1分間に送信できるリクエスト数やトークン数には制限がありTierごとに異なります。そのためMAX_PREDICTION_COUNTはこの制限(RPM)も考慮して設定する必要があります。また、nb_workersは実行環境に合わせて適切な値に設定する必要があります。ここがオーバーヘッドになると、逆に処理時間がかかったり処理そのものが失敗する可能性があります。
また、ここで重要なこととしてmax_tokensを1に設定しています。これにより、先ほど説明した1 Token分のカテゴリIDのみを出力するように調整することが可能です。
おわりに
今回は様々な形態をとるWebコンテンツのうち「テキスト」にのみ焦点を当て、ファインチューニングした GPT-4o-mini モデルを活用することで、低コストかつ高速に記事のカテゴリを予測する方法について簡単に触れました。また導入した結果として、Webコンテンツのカテゴリメンテナンス工数の削減や、予測精度の向上という成果を達成することができました。
脚注
- 2024年12月時点
- 改行も1 Token扱いされているため、この画像では見た目よりもトータルのToken数が多めに出ています。
- ただし、この方法は今後Tokenizerが更新されたタイミングで仕様が変わるなどの理由により使えなくなる可能性があります。現在はファインチューニングでも
response_formatで出力をEnumで定義することができるようなので、こちらを使った方が良いかも。 - 指定できるモデル名はこちらのページから確認できます。
- 現在は大量のデータを一括で処理できるBatch APIが登場していますが、このリアルタイム性の恩恵に与ろうとしたため今回は使用していません。
ブログの著者欄
採用情報


関連記事







KEYWORD
CATEGORY
-
技術情報(574)
-
イベント(219)
-
カルチャー(55)
-
デザイン(58)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- GPU
- GPUクラウド
- GTB
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-

【2025国際ロボット展 出展レポート】AI ❤ ROBOTs で描く、人とロボットが共存する社会
技術情報
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート前編】
イベント
-

【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-

ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

コールセンターでSpeech2Speech AIを繋ぐときに知っておきたい3つの接続方式
技術情報
-

ZTNAはVPNの代替にならない:失敗パターン3選と回避策
技術情報
採用情報
SNS FOLLOW
