
この記事は GMOインターネットグループ Advent Calendar 2024 24日目の記事です。
目次
はじめに
こんにちは!GMOペパボ株式会社に新卒入社した永田です。社内ではてつをと呼ばれています。普段はロリポップ! for GamersのエンジニアとしてGoを用いた開発に携わっています。今回は12月17日にリリースされたばかりの「リソース可視化機能」について実装を担当したので、考えた点と工夫した点について紹介します!普段、Goを用いた開発を行っている方や、ロリポップ! for Gamersがどのような技術で作られているか興味がある方はぜひご覧ください!
ロリポップ! for Gamers とは?
はじめにサービスについて紹介させてください。弊サービスはGMOペパボ株式会社が運営する、簡単に構築できるマルチプレイ専用ゲームサーバーを提供するサービスです。リリースの話やテスト戦略に関しては GMOインターネットグループ Advent Calendar 2024 15日目の記事である「短期間での新規プロダクト開発における「コスパの良い」Goのテスト戦略」で詳しく記載されているのでぜひご覧ください。
.jpeg)
リソース可視化機能とは?
さて、私が今回実装した機能である「リソース可視化機能」はサーバーのコントロールパネルにおいてユーザーが使用しているサーバーのリソース情報(CPU使用率、メモリ使用量、ディスク使用量)を確認できる機能です。
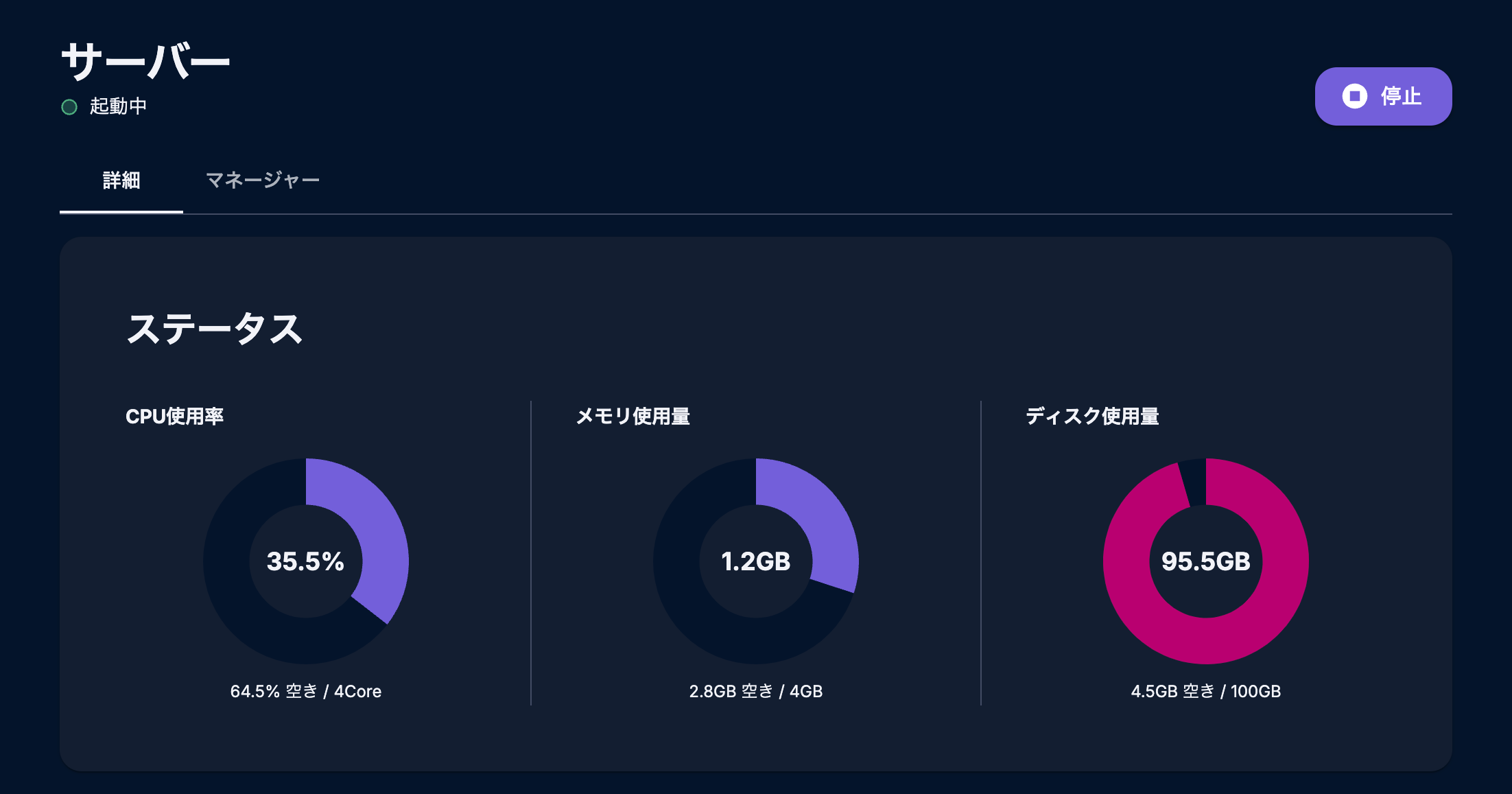
リリース前の課題
現状の課題としてユーザーが「サーバー重いな〜」と感じた時にそれが「ネットワークの原因」なのか、「サーバーのリソース不足」なのか問題の切り分けをすることができず、お問い合わせにつながってしまうという問題がありました。
そこでサーバーのリソースを「見える化」することで、ユーザーに解決の手助けをすることができるかつ、プランアップの訴求にも繋がるようになります。
要件定義と設計
ここから実装するにあたって考えたことと工夫したことをお話ししていきます。
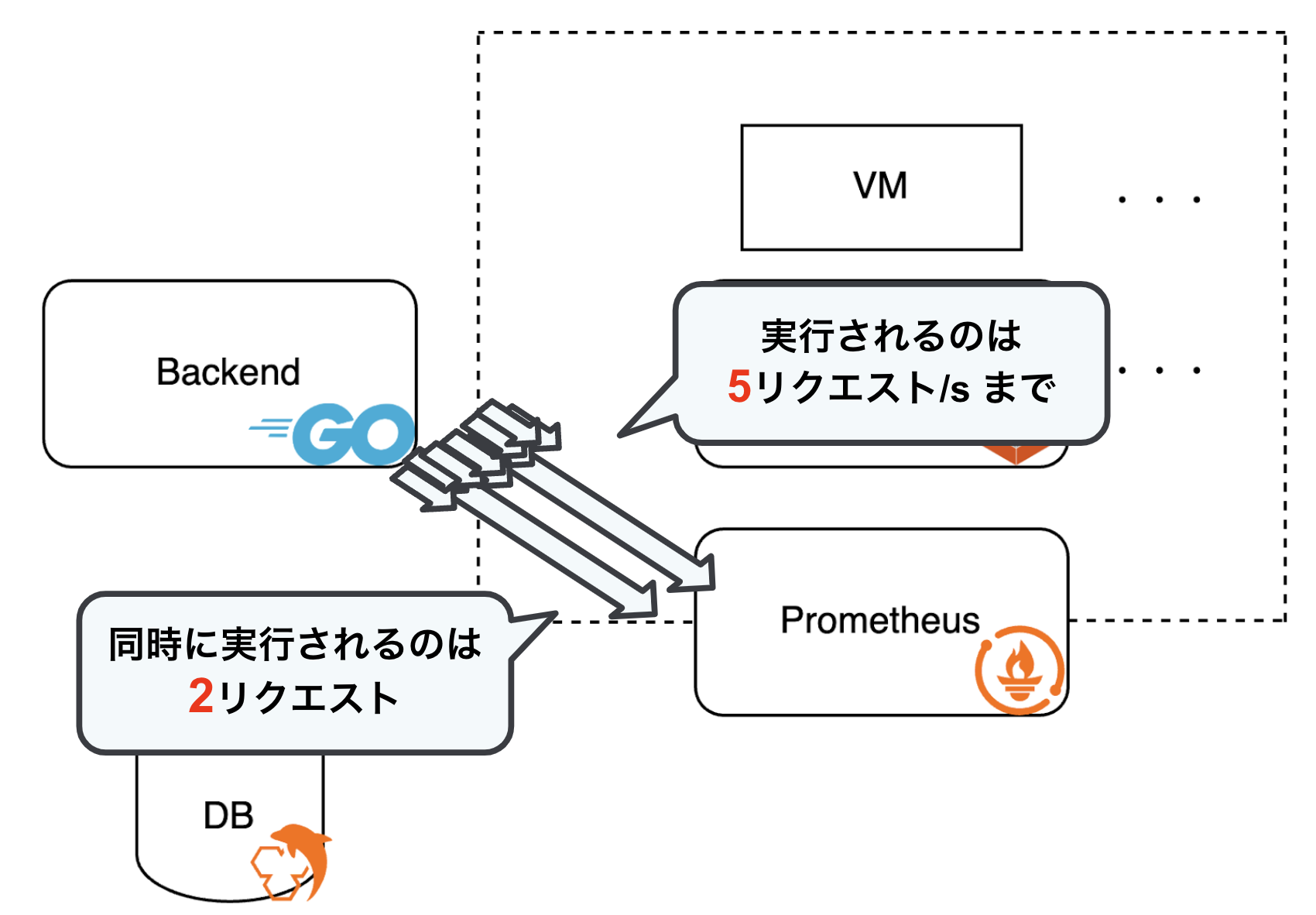
下の図はサービスのアーキテクチャの簡略図です。実装範囲のみを示しているので、今回はこちらの図を用いて説明します。
先述した通りロリポップ! for GamersのバックエンドはGoで実装されておりユーザーがコントロールパネルで設定した内容はバックエンドからLXDを経由してユーザーが実際にゲームをするサーバーに反映されます。ここにある、LXD(Linux Container Daemon)とはコンテナ、VMのオーケストレーターのことです。
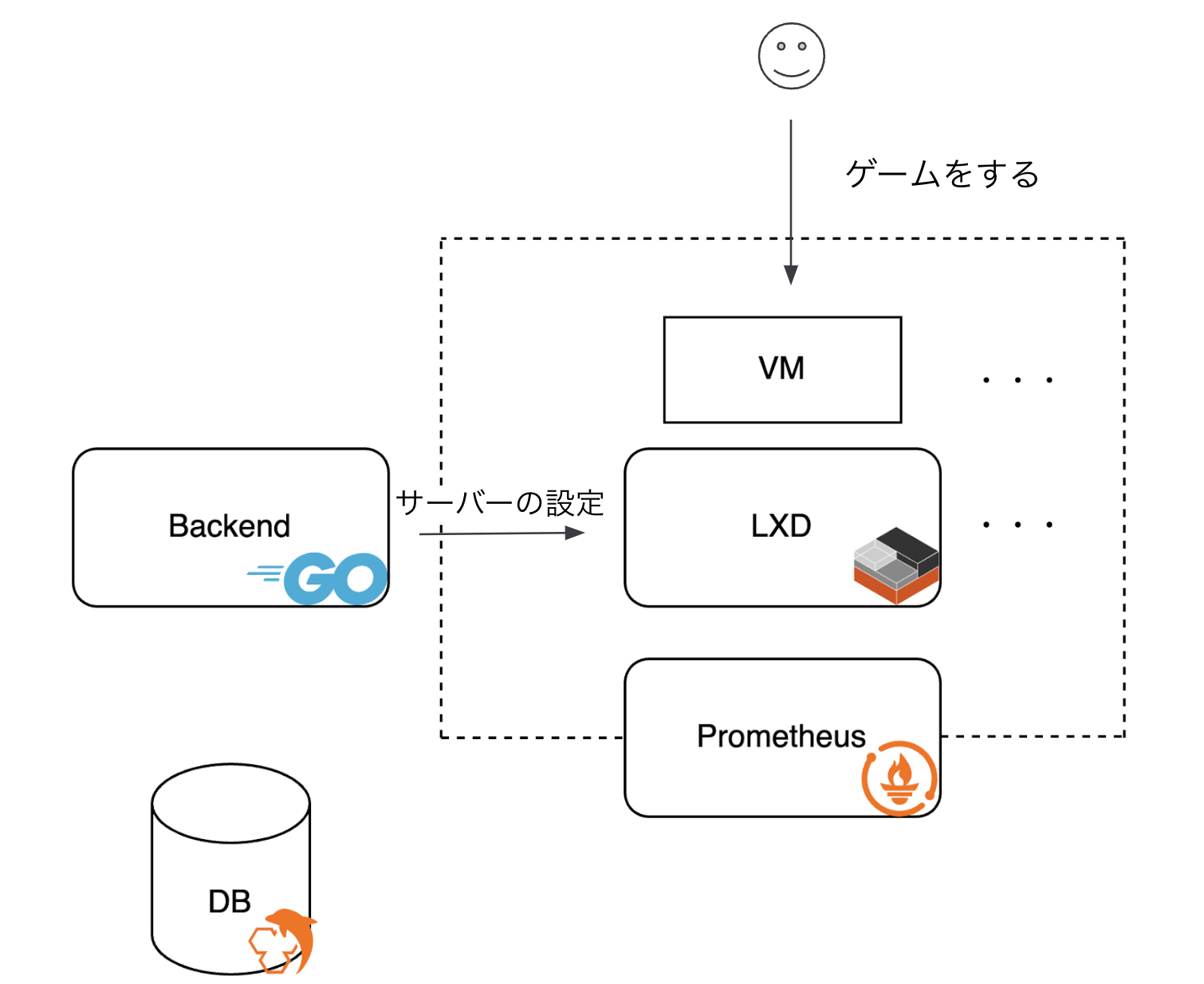
メトリクスの収集方法
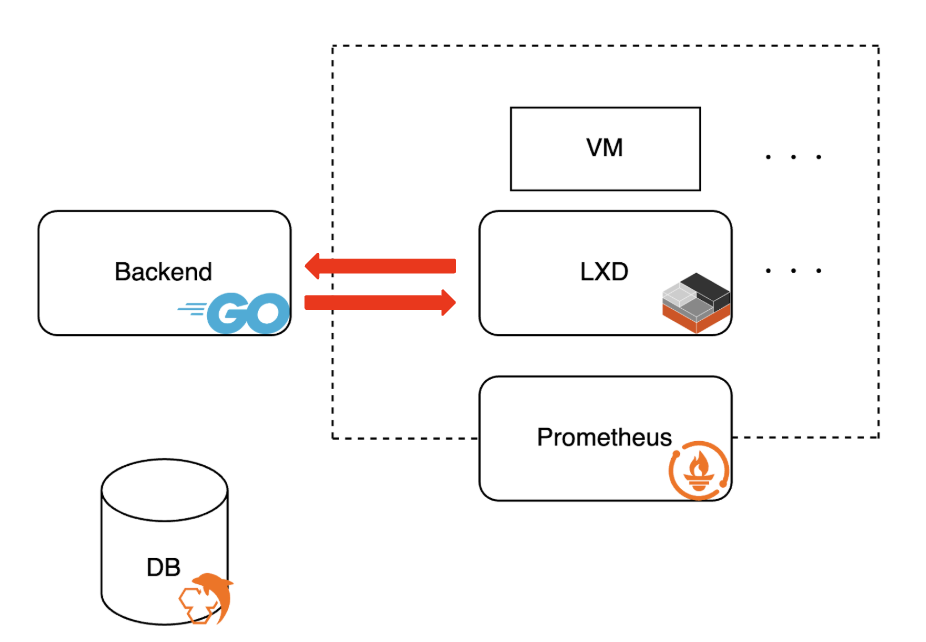
サーバーのリソース情報を表示するためにはまず、メトリクスの収集を行う必要があります。メトリクスとはシステムやサービスの状態やパフォーマンスを示す指標でありますが、ここでは特にサーバーのリソースやパフォーマンス情報、例えばCPU使用時間やメモリ使用量といったデータを指します。
そのメトリクス収集方法には以下の方法があります。
1.LXDが提供しているAPIを使用する方法
LXDのREST APIエンドポイントに lxc query /1.0/metrics があります。このAPIを使用することで、LXDが管理するコンテナやVM、ホストシステムのメトリクス情報を取得することが可能です。
ただし、このAPIで得られるメトリクスは以下の例に示すように累積値であり、時系列でデータを取得することはできません。例えばCPU使用率は、ある時間におけるCPUの稼働状況を示し、タスク処理に費やした時間とそうでない時間(idle時間など)を基に算出されます。これを正確に把握するには少なくとも2点以上でデータを取得して、その経過時間の差分を基に算出する必要があるため実際の値とズレが生じたり、制約が生じる可能性がありました。
teppei0717@lxdcluster1-1:~$ lxc query /1.0/metrics | grep 01234567890ABCDEFGHIJKLMNO | grep cpu | grep system | sort
lxd_cpu_seconds_total{cpu="0",mode="system",name="01234567890ABCDEFGHIJKLMNO",project="default",type="virtual-machine"} 46.49
lxd_cpu_seconds_total{cpu="1",mode="system",name="01234567890ABCDEFGHIJKLMNO",project="default",type="virtual-machine"} 45.99
lxd_cpu_seconds_total{cpu="2",mode="system",name="01234567890ABCDEFGHIJKLMNO",project="default",type="virtual-machine"} 32.4
lxd_cpu_seconds_total{cpu="3",mode="system",name="01234567890ABCDEFGHIJKLMNO",project="default",type="virtual-machine"} 42.62
lxd_cpu_seconds_total{cpu="4",mode="system",name="01234567890ABCDEFGHIJKLMNO",project="default",type="virtual-machine"} 47.06
lxd_cpu_seconds_total{cpu="5",mode="system",name="01234567890ABCDEFGHIJKLMNO",project="default",type="virtual-machine"} 47.26 # <- 累積CPU使用時間2.Prometheusサーバーを用いる方法
LXDのAPIでは時系列データの取得ができない制約を補う方法として、Prometheusサーバーからメトリクスを収集する方法を考えました。Prometheusは、定期的にメトリクスを収集してCPU使用率やメモリ使用量などのメトリクスを時間の経過とともに追跡でき、瞬間的な値だけでは得られない情報を取得することが可能です。
さらに、Prometheusでは独自のクエリ言語であるPromQLを用いることで、柔軟かつ高度なデータ取得や分析が可能です。たとえば、ある期間における特定のCPUの特定のコアの平均使用時間を求めたり、特定のリソースの異常値を検出したりするような複雑な分析も簡単に行うことができます。これにより、システムの状態やリソース使用状況を詳細に把握することができます。
以上の理由から、LXDが提供するAPIでのメトリクス取得ではなく、Prometheusサーバーを用いる方法を採用しました。

しかし、既存のPrometheusサーバーをリソース情報の取得に活用するには、以下の課題がありました。
- このサーバーは、主にシステムを監視し、安定した運用を支援する目的で構築されている。
- ユーザーに対してデータを提供する用途は想定されていない。
そのため、このサーバーはユーザーからの大量のリクエストを処理することを前提としていません。特に、必要以上にリクエストを送信すると、想定外の負荷がかかり、監視や運用に支障をきたす可能性があるため、この点に配慮する必要がありました。
そこでバックエンドで必要以上のリクエストを抑制するためにキャッシュとレートリミットを実装しました。
バックエンドで工夫したこと
キャッシュ
まず、キャッシュの手法としてGoのin-memoryキャッシュパッケージ(bigcache、freecache、golang-lruなど)を検討しました。これらのパッケージを使用することで、高速かつ効率的なデータキャッシュが可能です。しかし、Podが複数存在する環境では、各Pod間でキャッシュを同期することが困難となります。この問題が原因でデータの一貫性が保てなくなる可能性があるため、in-memoryキャッシュの利用は採用しませんでした。
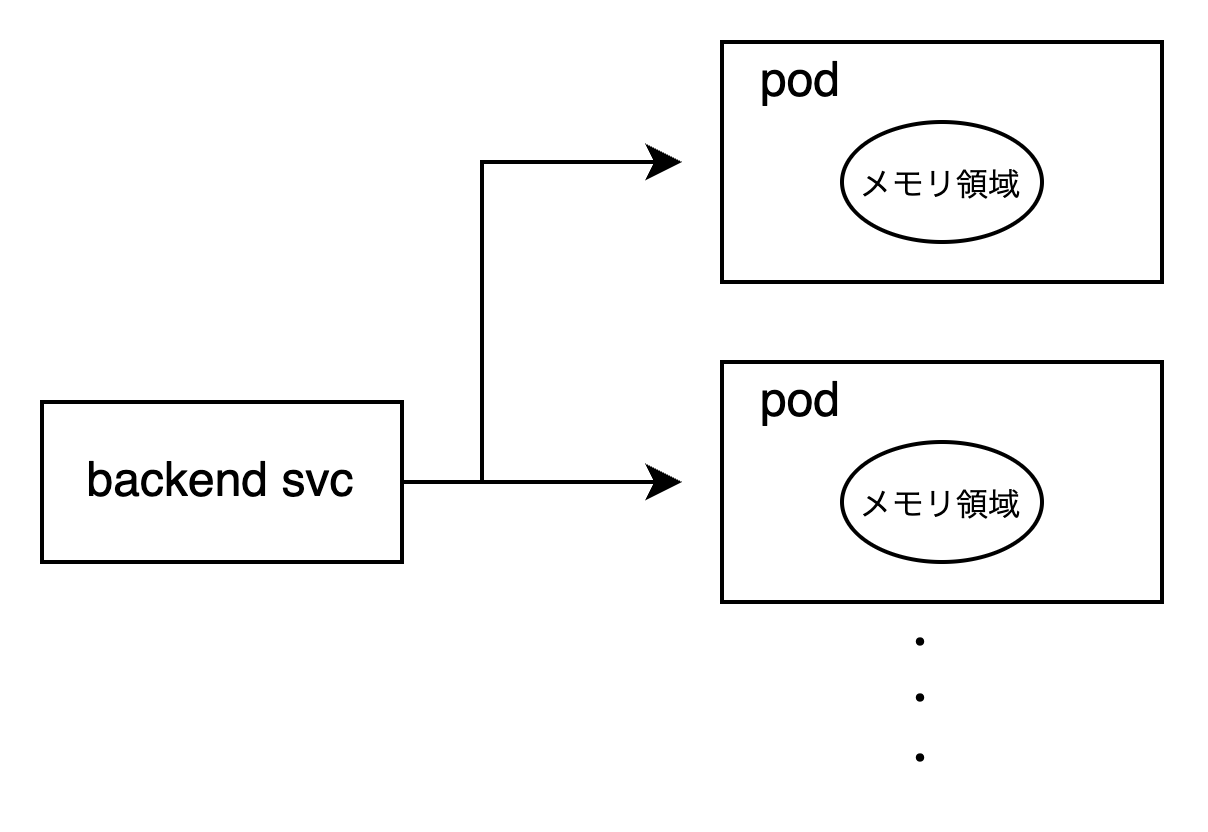
次に、キャッシュの手法としてRedisの利用を検討しました。Redisは高性能なインメモリデータストアであり、分散環境でも問題なく動作するため有力な選択肢でした。しかし、将来的には取得したメトリクスをグラフとして可視化する予定があり、そのために時系列データを保持できる専用のデータベースを別途導入する予定があります。そのため、Redisは今回のスコープ内でしか使用されない一時的な選択肢となり、長期的な視点では適していないと判断しました。この理由から、Redisの採用は見送りました。
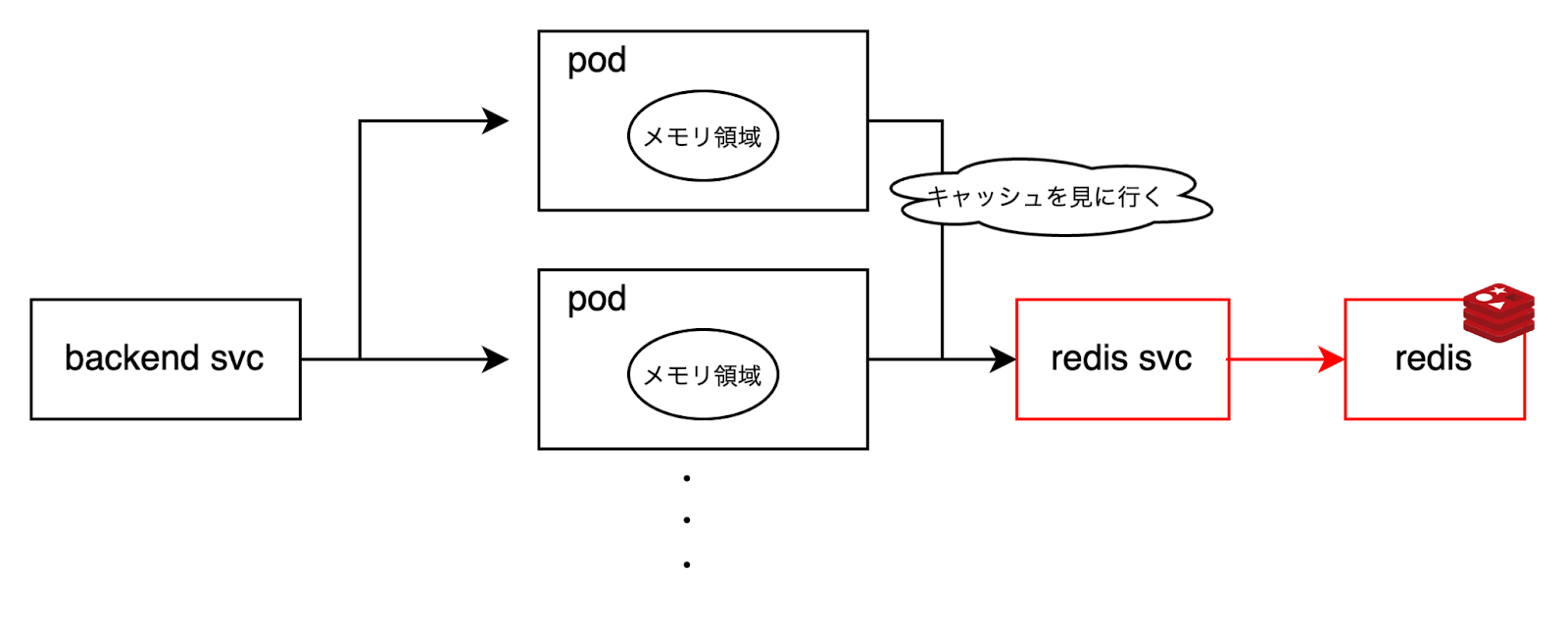
最終的に、キャッシュの手法としてDB(MySQL)を利用することにしました。DB(MySQL)は既に運用中の環境で利用されており、今回のスコープ内で新たな導入コストを抑えることができます。また、リリース期日を考慮した際、DB(MySQL)を用いることで迅速に実装を進められることも大きなメリットです。
これらの理由から、今回の要件に対してDB(MySQL)を利用することが最善の選択であると判断し、取得したリソース情報をキャッシュする手法として以下の方針としました
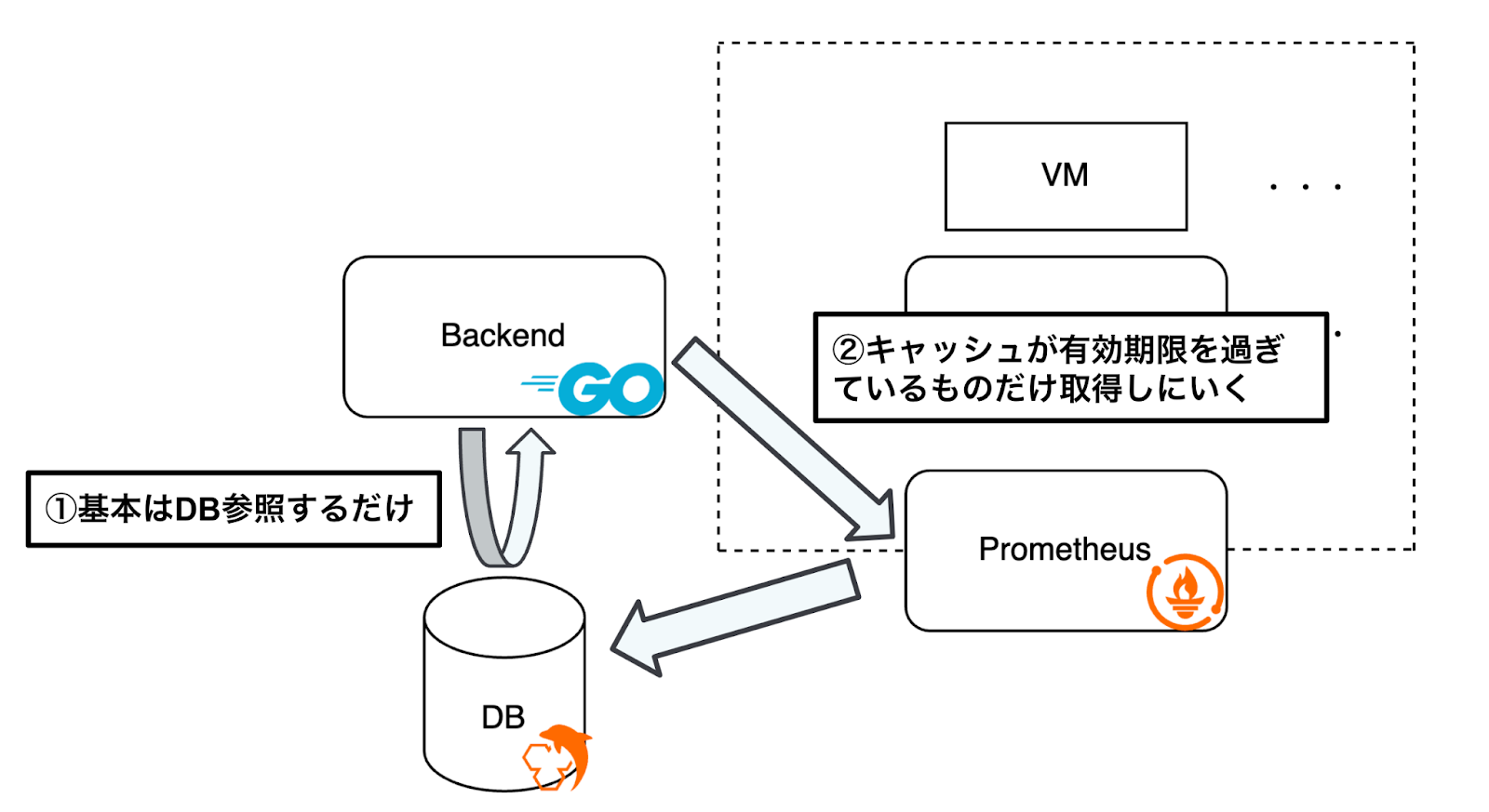
①基本はDB参照するだけ
バックエンド(Goアプリケーション)は基本的にDBを参照することでデータを取得します。
これにより、Prometheusへのリクエストを極力減らし、サーバーに過剰な負荷をかけないようにしています。キャッシュがDBに保存されているため、繰り返しのアクセスや同じデータの取得要求に対して、即座に応答することが可能になります。
②キャッシュが有効期限を過ぎているものだけ取得しにいく
DBに保存されているキャッシュの有効期限が切れている場合のみ、バックエンドはPrometheusに新しいデータを取得しに行きます。これにより、データが最新であることを担保しつつ、Prometheusへのリクエスト数を最小限に抑えることができます。
具体的には、
- キャッシュの有効期限が切れていない場合 → DBからデータを返す
- 有効期限が切れている場合 → Prometheusからデータを取得し、DBを更新する
この2つの方針を組み合わせることで、Prometheusへのアクセスを最小限に抑えつつ、必要なリソース情報を効率的に取得・提供できる仕組みを構築しました。
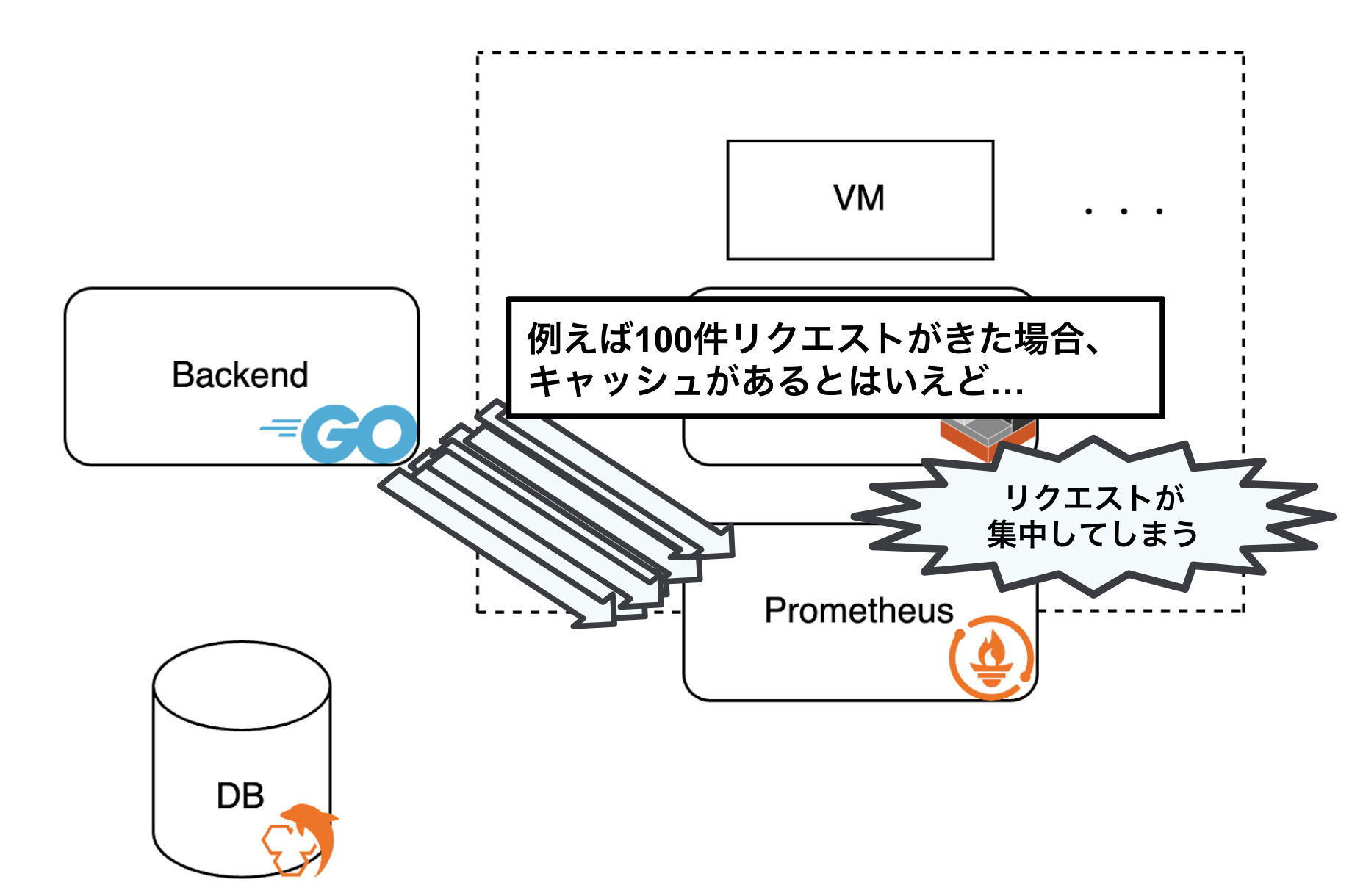
レートリミット
複数のリクエストが同時に発生し、キャッシュの有効期限が切れている場合に一斉にPrometheusへアクセスが集中してしまうため、サーバーに過負荷がかかる問題が生じます。
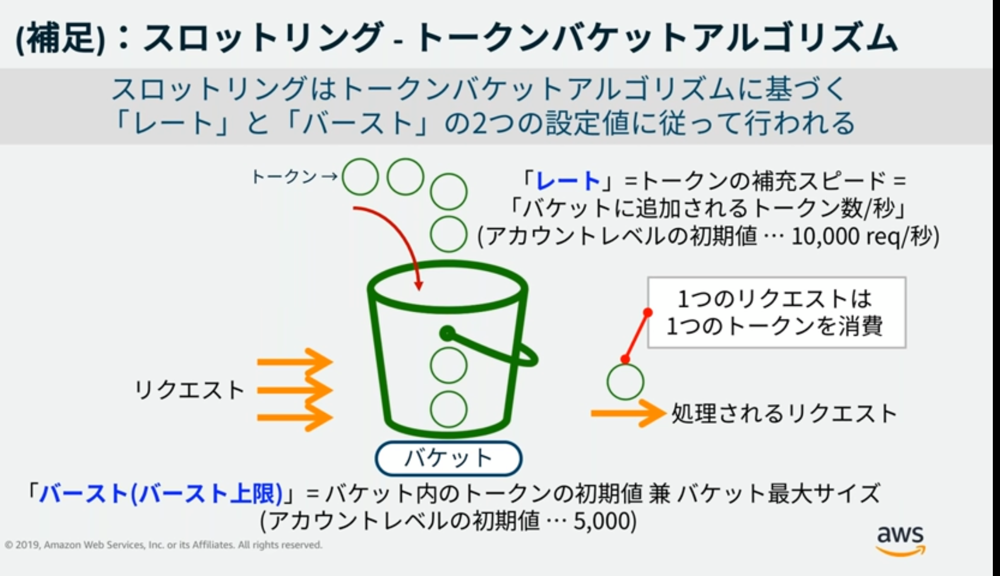
そこで、リクエストの集中を防ぐためにレートリミットとして golang.org/x/time/rate ライブラリを採用しました。このライブラリはトークンバケットというアルゴリズムを用いており、一定間隔で発行されるトークンを消費する形でリクエストを制限します。これにより、短時間に過剰なアクセスが発生することを防ぎ、Prometheusへの負荷を抑えることが可能になります。
以下は、レートリミットのコード例です:
// レートリミットの設定
limiter := rate.NewLimiter(5, 2)
// リクエスト処理
for i := 0; i < 10; i++ {
go func(id int) {
limiter.Wait(context.Background()) // トークンを取得するまで待機
fmt.Printf("Request %d: allowed\n", id) // リクエスト処理
}(i)
}rate.NewLimiter(5, 2) は、1秒間に最大5回のリクエストを許可し、同時に実行可能なリクエスト数を2つに制限します。
limiter.Wait(ctx) は、トークンが発行されるまで待機し、取得後にリクエストを実行します。これにより、リクエストの集中を防ぎながら、過負荷を軽減します。
レートリミットの実装により、Prometheusへのリクエスト数と同時実行数を制限しました。これにより、リクエストが集中する状況でもPrometheusサーバーへの過負荷を防ぎつつ、安定したデータ取得が実現できるようになりました。
まとめ
リソース可視化機能の実装においては、サーバーの負荷をアプリケーションの実装で対処する方針を取りました。特にGo言語には、レートリミットを実装するための扱いやすいライブラリとメソッドが揃っており、比較的簡単に機能を組み込むことができました。今後も運用を通して得た知見をもとに、より効率的で安定したシステムを目指して改善を続けていきます!
ブログの著者欄
採用情報


関連記事







KEYWORD
CATEGORY
-
技術情報(574)
-
イベント(219)
-
カルチャー(55)
-
デザイン(58)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- GPU
- GPUクラウド
- GTB
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-

【2025国際ロボット展 出展レポート】AI ❤ ROBOTs で描く、人とロボットが共存する社会
技術情報
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート前編】
イベント
-

【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-

ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

コールセンターでSpeech2Speech AIを繋ぐときに知っておきたい3つの接続方式
技術情報
-

ZTNAはVPNの代替にならない:失敗パターン3選と回避策
技術情報
採用情報
SNS FOLLOW
