
目次
はじめに
大規模言語モデル(LLM, Large Language Model)は、近年とても注目を集めています。しかしネット上の資料を見ていると、数式や数学的な手法の解説が多く「そもそもなんでこんなことをしているの?」という根本的な部分の説明が意外と少ないように感じます。私も最初に勉強したときはなかなかイメージを掴めず苦労しました。
そこで、今さらですが、LLMの基本的なアイデアや背景を振り返り、自分なりに整理してみました。正確さよりも直感的な理解を重視し、イメージを中心に書いています。細かい数式ではなく、概念や流れを掴むための参考として読んでいただければ幸いです。
私たちが機械学習を使うとき、いったい何をしているのか?
突然ですが、「機械学習の本質とは何か?」と考えたことはありますか?
私の捉え方としては、
「データをもとに、与えられた条件下で望ましい結果を導くための“仕組み”を学習し、それを新たな状況にも応用できる能力を機械に持たせること」
だと思っています。
そして、私が特に重要だと考えるのは次の2点です。
- “仕組み”を理解するに当たって十分なデータがあること
- 学習の方向性が明確で、モデル自身が答え合わせをしながら最適化していけること
現実社会だと、上司や取引先から「データも目標もないまま『いい感じでやっといて』と言われる」ような状況がよくありますよね。そうなると、人間だって何をどう頑張ればいいのか分からないものです。同じように機械学習でも、たくさんのデータと「どんな目標を目指すのか」という明確なゴール設定がないと、モデルはうまく学習できません。
さらに、機械は人間の五感とは違いあくまで「0」と「1」の情報(コンピュータが扱う数値)でしか物事を認識できません。たとえそれを拡張していろんな数値を扱えるようにしても、最終的にやり取りされるのはあくまでも数値のみです。
つまり、現実世界の問題を機械学習モデルに解かせるには、以下の要件を満たす必要があります。
- 条件としての「入力」と結果としての「出力」を数値(ベクトル・マトリックスなど)で表現できること
- 「入力」と「出力」の関係性を、何らかの数値計算(例:最も基本的な線形モデル y = wx + b など)として表現できること
以上を踏まえ、LLMにまつわる技術はどうやってここまで発展してきたのか、その重要なポイントを振り返ってみましょう。
テキストの数値化
LLMの出力は、文章生成や分類ラベルなど、タスクによって異なりますが、入力はほとんどテキスト(文章)です。
そのため、まずは前述の要件1を満たすために、テキストを数値として表す必要があります。
単語に番号を振る
主な目的
- テキストの単語や文字に一意のIDを割り振り、機械が扱える整数として表現する。
- 実際のLLMでは、厳密には「トークン」単位で処理が行われていますが、ここでは説明を簡略化するため「単語」という用語を使います。
主な仕組み
- 例えば、「あ」=1、「い」=2、「う」=3 … のように、文章に含まれる単語や文字ごとに単純な整数IDを割り振る。
主な問題点
- この方法では、数値演算が行われた場合に問題が生じます。
- 例えば、1 + 2 = 3 と計算すると、「あ」+「い」=「う」となり、単語本来の意味が保持されなくなってしまいます。
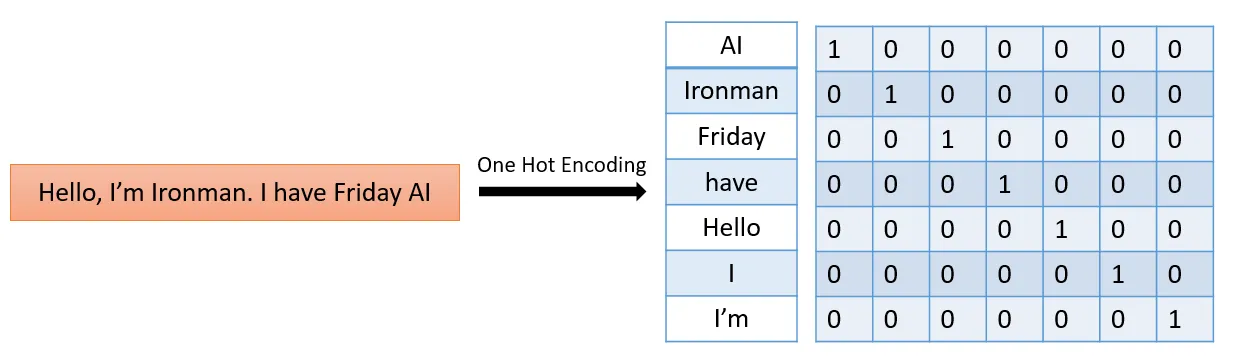
One-Hot Encoding
図の出典
Hema Kalyan Murapaka. 「Natural Language Processing: One-hot Encoding」, Medium. https://medium.com/@kalyan45/natural-language-processing-one-hot-encoding-5b31f76b09a0 (参照:2025年3月13日)
主な目的
- 各単語を、お互いに重なり合わあないベクトル(直交ベクトル)で表現し、計算時に単語の意味が混ざらないようにする。
主な仕組み
- あらかじめ用意した「語彙数」と同じ次元のベクトルを作り、該当する単語の位置を1、それ以外を0にする。
主な問題点
- 意味が重なりあわないため、どの単語同士を比べても類似度が常に0になり、「意味的な関係」が捉えられなくなります。
- また、単語数が増えれば増えるほど、次元も増えていくので、データが膨大になります。
そこで、機械学習でうまく「単語同士の意味合いの近さ」を学習させる方法が考案されました。
単語埋め込み(Word Embedding)

図の出典
Metin Bilgin, Izzet Fatih Senturk. (2017). Sentiment analysis on Twitter data with semi-supervised Doc2Vec. ResearchGate. https://www.researchgate.net/publication/320829283_Sentiment_analysis_on_Twitter_data_with_semi-supervised_Doc2Vec (参照:2025年3月13日)
主な目的
- 単語同士が「意味的にどれくらい似ているか」をベクトルの距離として扱えるようにし、数値計算が可能になるようにする。
Word Embeddingにより、意味的に類似する単語はベクトル空間でも近い位置にマッピングされ、「数値同士の距離」=「意味的類似度」として扱えるようになります。
主な仕組み
- Word2Vecなどの技術が代表的で、文章中の前後の文脈からターゲットとなる単語を推定するタスクをモデルに与え、その誤差を使って単語ベクトルを学習する。
- 大規模なコーパス(文章データ)が活用できるため、人間が手作業で作った同義語・対義語リストなどがなくても自然な文脈情報から学習が進むのが特徴。
Word2Vecで代表的な2つの学習手法は以下のとおりです。
CBOW (Continuous Bag of Words)
- 前後の文脈から中心となる単語を推定するなどして、単語ベクトルを学習する。
- 例: 「I ? coffee」では、「?」に入る単語(love)を当てるなどして学習し、その正解との誤差をもとに単語ベクトルが更新されます。
Skip-gram
- 中心の単語から周辺の文脈を推定するなどして、単語ベクトルを学習する。
- 例: 「I love coffee」の場合、中心単語「love」から前後の単語「I」や「coffee」が出現する確率が高くなるなどして学習されます。
なぜWord Embeddingがすごいのか?
- 仕組みを理解するに当たって十分なデータがある:
世界中に存在する無数のテキストデータを、そのまま「単語の前後関係」を捉える学習データとして利用できるなどして、大規模なデータが容易に活用できます。 - 習の明確な方向性がある:
「文脈から単語を当てる」または「単語から文脈を当てる」という明確なタスクが設定されるなどして、正解データ(答え合わせ)をもとに学習が進められます。
私は、「最終目的は“文脈から単語を当てる”ことではなく、学習の過程で得られる単語ベクトルを活用する」という発想が画期的だと思います。
主な問題点
- 固定された単語ベクトルでは「多義性」を扱いづらいことです。
- ここでの多義性とは、固定された複数の意味を持つ単語(例:「Apple」)だけでなく、文脈によって意味が大きく変化する代名詞(例:「it」)も含まれます。
文脈の取り入れ
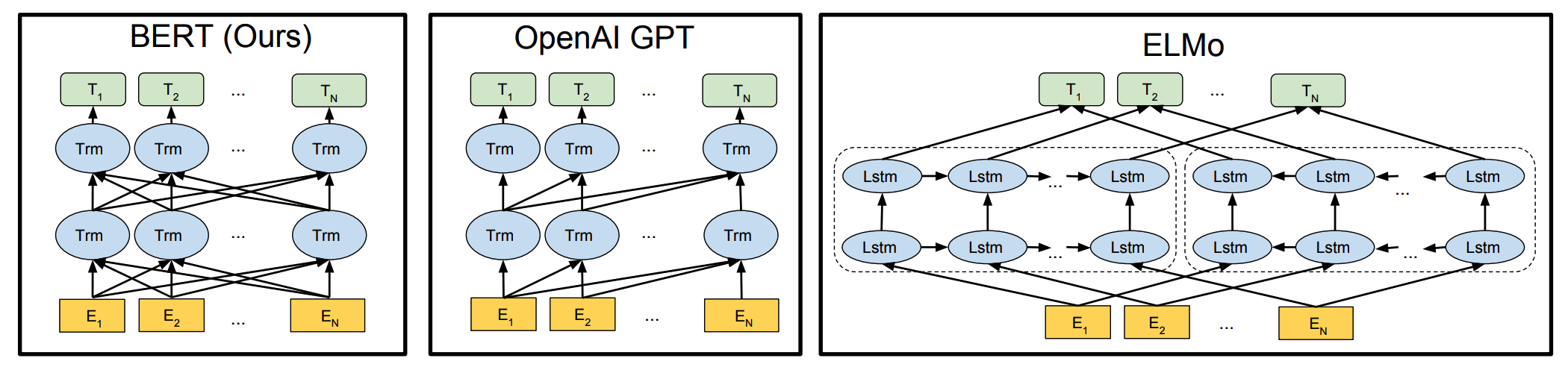
ELMo (Embeddings from Language Models)
図の出典
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805. https://arxiv.org/abs/1810.04805 (参照:2025年3月13日)
主な目的
- 文脈によって単語ベクトルを動的に変化させ、同じ単語でも前後関係に合わせて意味が変わるようにする。
主な仕組み
- LSTM(Long Short Term Memory)ベースの双方向言語モデルを使用して、文章全体から得られる文脈情報をもとに、各単語のベクトルを生成する。
ELMoのどこがすごいのか?
ELMoの革新性は、「入力として与える単語(または文書)の数値ベクトルと、出力として得られる文脈を考慮した数値ベクトルが 必ずしも一致する必要がない」という発想にあると思います。
この手法は、モデルに入力する単語(文書)の数値ベクトルと、出力で文脈を考慮した単語(文書)の数値ベクトルが必ずしも一致する必要がないという考え方に転換します。
また、Word2Vecが学習後の「単語ベクトル」だけを利用するのに対して、ELMoでは モデル自体、つまり文脈情報を取り入れるプロセスそのものが重要 となっています。
主な問題点
- RNN(LSTM)構造で文章を順次処理するため、並列化が難しく、長い文章では冒頭の情報が後半まで届きにくいという問題があります。
Attention
主な目的
- ELMoのような順次処理の欠点を一気に解決し、文章全体の単語同士の関係をうまく捉えられるようにする。
主な仕組み
- テキスト中の各単語について、「どの単語とどれくらい関連度が高いか」を重み(Attention Weight)で計算する。
- 具体的には、以下の3つのベクトルを用意する:
・Q (Query): 「どんな情報を探しているか」を示す
・K (Key): 単語の特徴やラベル
・V (Value): 単語の持つ実際の意味情報 - QとKの内積(類似度)から得られた重みに応じてVの情報を合成し、文脈を考慮したベクトルを得る。
Attentionのどこがすごいのか?
- 発想面:
単語自身の意味を表すVに加え、他の単語との関係性を計算するためのQとKを導入することで、文脈依存の情報を捉えることができます。 - 性能面:
全ての単語間で類似度計算を並列処理できるため、逐次計算の必要がなく、文書の長さに関わらず一定の計算処理で済むことができます。
並列計算が可能な構造であるため、GPUを用いた大規模学習に適しており、今日のような超巨大モデルが生まれることにもつながります。
- 厳密には、無限に長い文書を計算できるわけではなく、あらかじめ指定されたウィンドウサイズ(一般的には512トークン程度)の制限がありますが、現在の技術の進歩により、徐々にこの制限を突破できるようになっています。
主な問題点
- 全ての単語に対して他の全ての単語との類似度を計算するため、文書が長くなると計算量が二乗的(O(n^2))に増加します。
- そのため、学習や推論に大量の計算資源(GPU時間)が必要となります。
Self-Attention

図の出典
Jay Alammar. 「The Illustrated Transformer」, Jalammar’s Blog. https://jalammar.github.io/illustrated-transformer/ (参照:2025年3月13日)
Self-Attentionは、同じ系列(文章)内の単語同士の関連を捉えるAttentionの仕組みです。実際の大規模言語モデルで最も広く使用されています。
主な目的
- 単一の文章内で単語同士の関係を並列的に計算し、各単語を「文脈を踏まえた表現」に変換する。
主な仕組み
- 入力系列Xから同じ方法でQ、K、Vすべてを生成する。
- これにより、系列内のすべての単語が互いにどれだけ関連しているかを直接計算でき、文章中の全単語が互いに参照し合うことが可能になる。
- なお、マルチモーダルの応用では、テキスト入力だけでなく画像、音声、動画なども扱うため、Self-Attentionとは異なる仕組みを利用し、QとKVを別々の方法で生成する場合もあります。
Multi-Head Self-Attention


図の出典
Jay Alammar. 「The Illustrated Transformer」, Jalammar’s Blog. https://jalammar.github.io/illustrated-transformer/ (参照:2025年3月13日)
主な目的
- 単語が複数の解釈可能性を持つ場合、複数の異なる観点(Head)でAttentionを学習させることで、文脈理解をより柔軟にする。
主な仕組み
- 入力系列Xから複数の(Q, K, V)を作り(複数のHeadを持つ)、それぞれ独立にAttentionを計算した結果を結合する。
上の図例で示すように、2-head にした場合のヒートマップでは、「it」が 1つ目(オレンジ)のHeadでは「The animal」の意味情報を、2つ目(緑)のHeadでは「tired」の状態を重点的に反映している ことが示されています。
また、曖昧な句の例として、「John told Bill that he would win」という文章では、「he」が「John」または「Bill」のどちらを指すのか、複数のHeadで異なる視点から解釈することが可能となります。
Masked Self-Attention
図の出典
Jay Alammar. 「The Illustrated GPT-2 (Visualizing Transformer Language Models)」, Jalammar’s Blog. https://jalammar.github.io/illustrated-gpt2/ (参照:2025年3月13日)
主な目的
- 文章生成タスクなどで、まだ生成されていない未来の単語を参照しないようにする。
モデル学習時には前後の文脈すべてが利用できますが、実際のテキスト生成時には現在の単語以降は未知です。そこで、学習時に「未来の単語」をマスクして左から右へ単語を生成する状況を模擬し、推論でも同じマスクを適用することで、未来の単語情報を参照せずに順次文章を生成できるようにします。
主な仕組み
- 後の単語情報をマスク(重みを0に)して、予測時に矛盾が起きないように制御する。
Positional Encoding
図の出典
Jay Alammar. 「The Illustrated Transformer」, Jalammar’s Blog. https://jalammar.github.io/illustrated-transformer/ (参照:2025年3月13日)
主な目的
- Attentionでは捉えきれない単語の順序情報を補い、文章中での単語の位置関係を正しく考慮できるようにする。
主な仕組み
- 三角関数(Sin, Cos)の波形を利用した位置情報ベクトルを用意し、単語ベクトルに足し合わせて「単語の順序」を学習できるようにする。
なぜ三角関数を使うのか?
二つの単語の相対的な順序、すなわち両者の間に挟まれる単語の数は、三角関数の「加法定理」を利用した計算で反映できます。
- 個人的には、この仕組みが非常に巧妙だと感じています。興味がある方は、ぜひ数式を深掘りしてその魅力を実感してみてください。
モデル構造の革新
Transformer
図の出典
Jay Alammar. 「The Illustrated Transformer」, Jalammar’s Blog. https://jalammar.github.io/illustrated-transformer/ (参照:2025年3月13日)
Self-Attentionを中心とするネットワーク構造を持つ代表的モデルがTransformerです。
主な目的
- 機械翻訳など、入力言語から出力言語を生成するタスクを効率的に学習する。
主な仕組み
- オリジナルのTransformerはEncoder-Decoder構造で提案された。
– Encoder:入力文を読み取り、埋め込み表現(深い特徴)に変換する。
– Decoder:Encoderから得られた特徴をもとに出力文を生成する。
なぜEncoder-Decoder構造を使うのか?
翻訳タスクを念頭に、入力言語と出力言語を自然に分業する形で設計されたためです。
しかし、その後の研究により、EncoderのみまたはDecoderのみのモデルでも十分強力な自然言語処理が可能であることが示され、さまざまな派生モデルが生まれました。
BERT (Bidirectional Encoder Representations from Transformers)

図の出典
Ankur Kumar. 「The Illustrated BERT Masked Language Modeling」, https://ankur3107.github.io/blogs/masked-langauge-modeling/ (参照:2025年3月13日)
主な目的
- 「理解」タスクに強いモデルを目指し、文章の深層的な意味表現を獲得して、文章分類や質問応答などに応用しやすくする。
主な仕組み
- TransformerのEncoder部分のみを利用し、その層を深く積み上げる。
- MLM (Masked Language Modeling):
入力文の一部単語をマスクし、元の単語を当てるタスクで学習する。双方向の文脈情報を活用できるため、文全体の意味をより深く理解できる。 - NSP (Next Sentence Prediction):
2つの文が連続しているかを判定するタスクも同時に学習する。
BERTは「文書理解」寄りのタスクを大量にこなすことで、さまざまな下流タスクに対してファインチューニングで転用しやすいのが最大の利点です。
GPT (Generative Pre-trained Transformer)
主な目的
- 「生成」タスクに強いモデルを目指し、文章補完、要約生成、対話生成などに特化する。
主な仕組み
- TransformerのDecoder部分のみを利用し、その層を深く積み上げる。
- 巨大なパラメータ数で膨大なテキストデータを学習することで、高い生成性能を得る。
OpenAIがバージョンアップを重ねる中、GPT-3は当時驚異的とされた1750億パラメータを備え、大規模データによる学習効果(スケーリングの効果)を実証しました。
この流れを受け、「言語モデル(LM, Language Model)」の前に「大規模(large)」が付加され、「大規模言語モデル(LLM, Large Language Model)」という概念が広まりました。
主な問題点
- ハルシネーション:
ここまで述べた通り、言語生成モデルの本質はあくまで「今までの文書に続く最も可能性の高いテキストを生成する」ことにあるため、実際に存在しない内容や、回答が存在しない質問にも「それっぽい」テキストを生成してしまう性質があります。
これは、「無いものを無いと判断する」必要があり、いくらデータがあってもモデル自体が答え合わせを行うことができないため、LLMの学習の仕組み上、ハルシネーションを完全に避けることは困難です。
こうした問題を解決するために、事後学習 (post-training) によるアライメント技術が発展してきました。これは、LLMの出力を人間の好む方向に合わせるための仕組みとも言えます。
テキスト生成タスクの改善
教師ありファインチューニング(SFT, Supervised Fine-Tuning)
主な目的
- モデルの出力を、あらかじめ用意された「理想的な回答例」に近づけるように調整する。
主な仕組み
- 人間が作った高品質な「質問-回答」ペアを学習データとして与え、モデルがその正解と照らし合わせながらパラメータを更新する。
主な問題点
- 人間が膨大なデータ(高品質な文書)を用意するのは、非常に高いコストがかかります。
- 人間の回答を模倣するだけでは、未知のタスクへの汎化や人間を超える答えを出すことが難しい場合があります。
人間のフィードバックによる強化学習(RLHF, Reinforcement Learning from Human Feedback)
主な目的
- 人間が「好む・望ましい」回答を、より効率的に学習させる。
主な仕組み
- 報酬モデル(Reward Model)の学習:
人間アノテータがモデルの出力例に順位付けを行い、「どの回答がより望ましいか」を学習データとして作成する。 - 強化学習による微調整:
報酬モデルを用いて出力の「良さ」を評価し、PPO (Proximal Policy Optimization)などの強化学習手法でモデルを更新する。
主な問題点
- 人間が膨大なデータ(高品質な文書)を用意するのは、非常に高いコストがかかります。
- 人間の回答を模倣するだけでは、未知のタスクへの汎化や人間を超える答えを出すことが難しい場合があります。
こうした技術によって、OpenAIがChatGPTをリリースし、非常に自然な対話や柔軟な文章生成が可能なチャットボットとして世界的に大きな注目を集めました。いわゆる「ChatGPT moment」がここで生まれたわけです。
推論(Reasoning)
近年は、LLMの「推論力」をいかに高めるかが大きなテーマになっています。代表例としてOpenAI o1が挙げられます。
主な目的
- 従来のLLMが苦手とする論理思考や複雑な推論タスクを、高い精度でこなす。
主な仕組み
- Chain-of-Thought と呼ばれる考え方を用いて、長い推論や計算を段階的に分割し、それぞれのステップで確からしい答えを積み重ねるように学習する。
なぜChain-of-Thoughtが効果的なのか?
簡単な問題(ステップ)は、世界中の言語データで頻繁に出現するため、生成されるテキストが正しい可能性が高いです。一方、複雑な問題は出現頻度が低いため、モデルは未知のパターンの解答を「それっぽく」生成してしまうことがあります。このように、複雑な問題を段階的なステップに分解することで、従来のモデルが一度に曖昧な回答を生成するのを避け、各ステップごとに正答率を向上させることが可能となります。
周知のとおり、OpenAIはクローズドなAI企業であるため、o1の具体的な実装方法は公開されていません。しかし、世界中の科学者たちがOpenAIのレポートなどを分析した結果、非常に高コストで複雑な仕組みを採用していると推測されています。
DeepSeek-R1-Zero
「DeepSeek-R1」ファミリーは、「数学的タスクやコーディングタスクにおいてOpenAIの推論モデルo1と同等の性能を、超低コストで実現した」と直近の話題になっています。
主な仕組み
- あらかじめ、そこそこ高性能な学習済みベースモデル (DeepSeek-V3-Base) を用意し、そこからSFTを一切行わずに、強化学習のみで調整する。
- GRPO (Group Relative Policy Optimization) という独自の手法を採用し、従来の強化学習で必要とされる価値関数(一種のモデル)の学習を省略できるようにした。
- 強化学習時には、モデルに「理由を考えてから解答する」というシンプルなプロンプトのみを指示する。
なぜGRPOの仕組みが効果的なのか?
通常の強化学習(例: PPO)では、「現在の方策がどれくらい良いか?」 を判断するために、「状態価値関数」と呼ばれる指標を用います。一方、GRPOはこれまでの出力の平均的な良さを基準にして、「今回の出力の方が良いのか?」を判断しながら学習を進めます。これによって、モデルは複数回試行した結果を比較し、より良いものを選ぶことで、自らパラメータを調整し精度を向上させることができます。
ただし、ベースモデルが小さいと、最初の出力が不安定になりやすく、この手法が十分に機能しない場合もあると報告されています。これは、初期の生成結果がバラつきやすいため、比較の基準(ベースライン)が安定しにくくなるためです。
なぜ数学とコーディングに強いのか?
数学やプログラミングの問題は明確な正解が定義しやすいため、モデルが「自分で答え合わせしやすい」ことが大きな要因です。
終わりに
本稿でご紹介した内容は、LLMが扱う膨大な研究領域のうちのほんの一部分で、まだまだ重要な概念を多く省略しています。私自身も執筆しながら、漠然としていた知識が結びつき、研究者の方々の発想の素晴らしさをあらためて実感しました。本稿を通じて、少しでもそのエッセンスがお伝えできたのなら幸いです。今後もLLMやAIの世界は必ず進化し続けますので、私も皆さんと同じように新たな技術やアイデアに触れ、学びや発見の感動を一緒に味わっていければと思っています。
参考資料
- Attention Is All You Need
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- The Illustrated Transformer
- The Illustrated GPT-2 (Visualizing Transformer Language Models)
- What is Query, Key, Value (QKV) Attention ?
- 预训练语言模型的前世今生
- 《大型语言模型简史》
- 基于transformers的自然语言处理(NLP)入门
- Positional Encoding徹底解説:Sinusoidal(絶対位置)から相対位置エンコーディング
- DeepSeek R1 and V3 〜OpenAI o1級のオープンモデルの作り方〜
- LLMチューニングのための強化学習:GRPO(Group Relative Policy Optimization)
ブログの著者欄
杜 博見
GMOインターネットグループ株式会社
2023年 GMOインターネットグループ株式会社 新卒入社。 データサイエンティスト / デベロッパーエキスパート。 グループ横断の事業でAI技術を用いた解析支援に携わっている。
採用情報


関連記事






KEYWORD
CATEGORY
-
技術情報(579)
-
イベント(224)
-
カルチャー(57)
-
デザイン(60)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- Behind the Scenes
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOインターネットグループ陸上部 – GMOロボッツ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMOロボッツ
- GMO大会議
- Go
- Good Morning
- GPU
- GPUクラウド
- GTB
- Hack-1グランプリ
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 技術書典20
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 映像制作
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP





採用情報
SNS FOLLOW
