
こんにちは。
GMOインターネット ネットワークソリューション事業本部 ソリューションパートナー事業部の横手です。
2025年05月20日、Microsoft Build 2025 にて今後のWindowsでMCP(Model Context Protocol)がサポートされるというMicrosoftの発表がありました。
すでにAnthropic、Figma、Perplexityらと協力して、MCPの機能を統合したWindows対応のAIアプリケーションを開発する動きも出ています。
今後、顧客への直接的なサービス提供や、顧客向けサービスを作成するために、MCPと連携した開発の機会は増えていくと考えられます。
そこで今回は、業務でそういった機会があった場合に迅速に対応できるよう、MCPとの連携機能の開発入門をまとめました。
目次
はじめに
2025年以降、AIエージェントやAIアプリケーションの開発現場でMCP(Model Context Protocol)との連携が重要になってきます。
本記事では、MCPの概要と、TypeScriptでMCPサーバーを構築し、AIクライアント(今回はClaude Desktop)と連携するまでの流れを解説します。
MCPとは
MCPとはModel Context Protocolの略で、AIエージェントやアプリケーションと外部ツール・データ・プロンプトを連携するための通信プロトコルです。
MCPのアーキテクチャモデルはクライアント・サーバモデルを採用しており、MCPクライアント(例: VSCode, Claude Desktop)とMCPサーバー(各種AIツールやデータ連携サーバー)が連携します。
MCPサーバーは主に以下の3つの機能を提供します。
- Prompts: AIに問い合わせるプロンプトの生成(テンプレート化可能)
- Resources: AIが参照するファイルやデータの提供
- Tools: AIに実行させるアクション・関数の定義
有名なMCPサーバーとしては Playwright MCP server (Microsoft公式) や GitHub’s official MCP Server (GitHub公式) などがあり、CloudflareやAzureなど一部クラウドではMCPサーバーのホスティングにも対応し始めています。
今回作成するMCPアプリケーション
MCPサーバーをTypeScriptで作成し、Claude DesktopをMCPクライアントとして連携・検証します。
MCPクライアント
今回はClaude Desktopを利用します。
MCPサーバー
fastmcp (TypeScript製のMCPサーバー) を使い、以下2つのサンプルアプリケーションを構築します。
- 1. UUIDを返すだけの簡素なもの
- 2. 用意したCSVファイルに対して分析処理を行うもの
1. UUIDを返すだけの簡素なもの
fastmcpのREADME.mdの内容に従い、最小構成のMCPサーバーを作成します。
import { FastMCP } from "fastmcp";
import { randomUUID } from "node:crypto";
import { z } from "zod"; // Or any validation library that supports Standard Schema
const server = new FastMCP({
name: "My Server",
version: "1.0.0",
});
server.addTool({
name: "generate-uuid",
description: "Generate a UUID",
parameters: z.object({}),
execute: async () => {
return randomUUID();
},
});
server.start({
transportType: "stdio",
});Claude Desktopでの連携設定
公式手順: For Claude Desktop Users – Model Context Protocolを参考に、Claude Desktopの設定ファイルにMCPサーバーを登録します。
{
"mcpServers": {
"prac-mcp-typescript": {
"command": "npx",
"args": [
"tsx",
"/PATH/TO/YOUR_PROJECT/src/index.ts"
// "/PATH/TO/YOUR_PROJECT/src/index.mts" // ESMの場合
],
"env": {
}
}
}
}Claude Desktopを使った確認
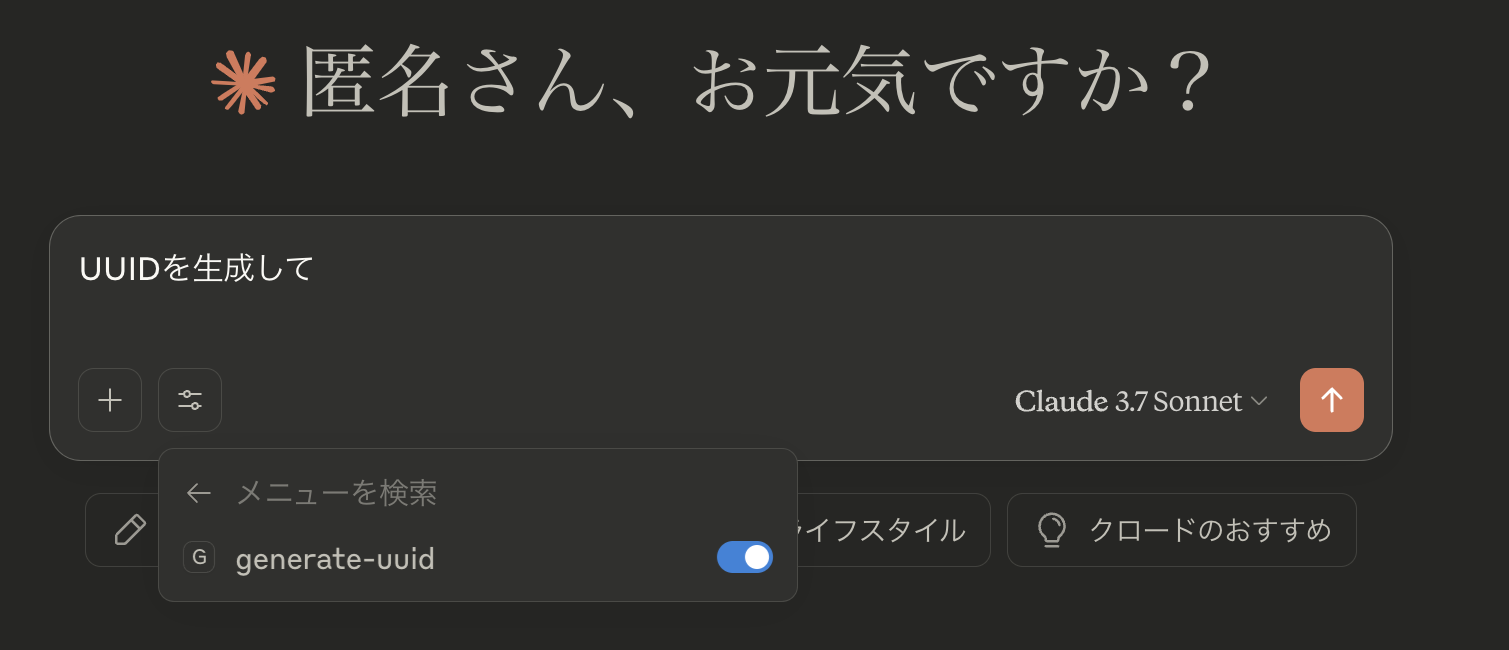
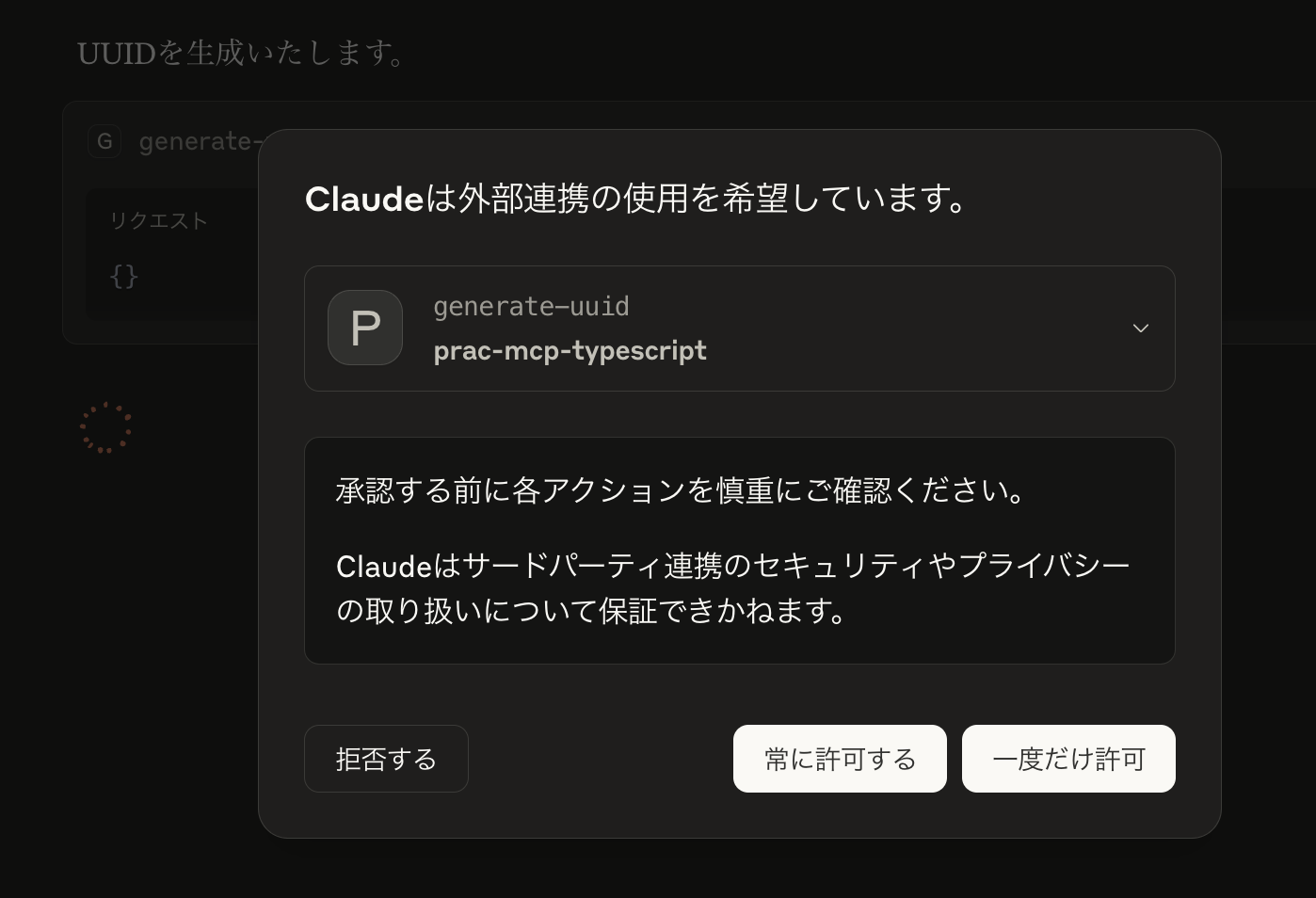
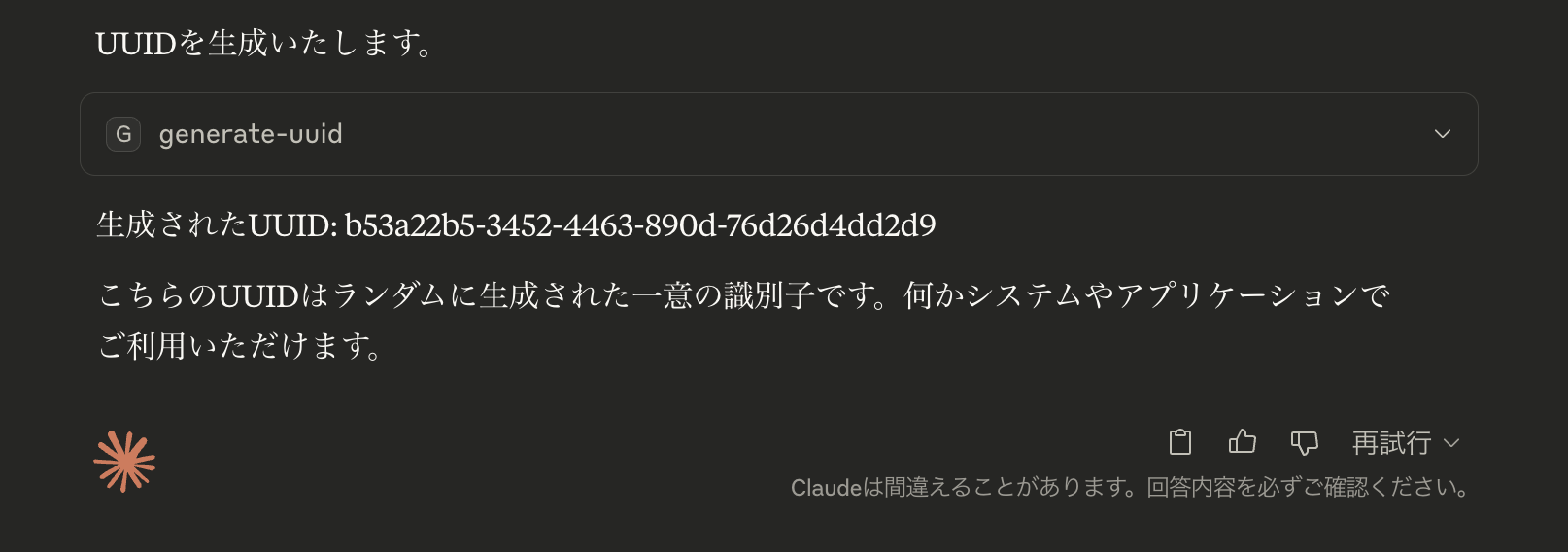
ClaudeクライアントでMCP利用スイッチをONにし、「UUIDを生成して」とプロンプトを入力すると、uuidが生成されることを確認できます。
2. CSVファイル分析AIアプリ
サンプルCSVとしてオープンデータ取組済自治体資料|デジタル庁の「市区町村」「都道府県」データを利用します。
ファイル名と名称の対応は以下list.csvの通りです。
"name","file"
"都道府県一覧","20250318_resources_opendata_lg_pref_list_02.csv"
"市区町村一覧","20250318_resources_opendata_lg_mani_list_03.csv"CSVのデータ処理
CSVファイルは DuckDB (OLAP向けのデータベースシステム) を使って読み込み、SQLでデータ操作を行います。
ライブラリは duckdb-async (Node.js製ライブラリ) を利用します。
MCPサーバー
Prompts, Resources, Tools を連携させて分析を行うMCPサーバーを構築します。
import { FastMCP } from "fastmcp";
import { Database } from "duckdb-async";
import { z } from "zod"; // Or any validation library that supports Standard Schema
import * as fs from 'node:fs';
const PWD = "/path/to/repo"
// DuckDB接続の初期化
const db = await Database.create(
':memory:', // メモリ内DBまたはファイルパスを指定
);
// FastMCPサーバーの作成
const server = new FastMCP({
name: "CSV Data Analysis Server",
version: "1.0.0",
});
// 特定のCSVファイルをリソースとして追加
server.addResource({
uri: `file://${PWD}/data/list.csv`,
name: "利用ファイル一覧",
mimeType: "text/csv",
async load() {
// CSVファイルの内容を返す
return {
text: await fs.promises.readFile(`${PWD}/data/list.csv`, "utf-8"),
};
},
});
server.addTool({
name: "get-enable-file-list",
description: "利用ファイル一覧",
parameters: z.object({}),
execute: async (args, { log }) => {
// CSVファイルの内容を返す
return {
text: await fs.promises.readFile(`${PWD}/data/list.csv`, "utf-8"),
type: "text"
};
}
})
server.addTool({
name: "load-csv",
description: "CSVファイルをDuckDBに読み込む",
parameters: z.object({
filename: z.string().describe("CSVファイル名"),
tablename: z.string().describe("作成するテーブル名"),
}),
execute: async (args, { log }) => {
try {
log.info(`${args.filename}を読み込んでいます...`);
// CSVファイルをDuckDBテーブルに読み込む
await db.exec(`
CREATE TABLE IF NOT EXISTS ${args.tablename} AS
SELECT * FROM read_csv_auto('${PWD}/data/${args.filename}')
`);
// テーブル情報を取得
const result = await db.all(`
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = '${args.tablename}'
`);
log.info(`テーブル ${args.tablename} が作成されました`);
return `${args.tablename} テーブルが作成されました。\n列情報: ${JSON.stringify(result, null, 2)}`;
} catch (error) {
log.error(`CSVファイルの読み込みに失敗しました: ${error.message}`);
throw new Error(`CSVファイルの読み込みに失敗しました: ${error.message}`);
}
},
});
server.addTool({
name: "run-query",
description: "DuckDBでSQLクエリを実行する",
parameters: z.object({
query: z.string().describe("実行するSQLクエリ"),
}),
execute: async (args, { log, reportProgress }) => {
try {
log.info(`クエリを実行しています: ${args.query}`);
reportProgress({ progress: 0, total: 100 });
// クエリ実行
const result = await db.all(args.query);
reportProgress({ progress: 100, total: 100 });
log.info('クエリが完了しました');
// 結果を整形して返す
if (Array.isArray(result) && result.length > 0) {
// 結果がある場合はテーブル形式で返す
return `クエリ結果 (${result.length}行):\n${JSON.stringify(result, null, 2)}`;
}
// 結果がない場合
return "クエリは正常に実行されましたが、結果はありません。";
} catch (error) {
log.error(`クエリ実行エラー: ${error.message}`);
throw new Error(`クエリ実行エラー: ${error.message}`);
}
},
});
server.addTool({
name: "aggregate-data",
description: "テーブルのデータを集計する",
parameters: z.object({
tableName: z.string().describe("集計するテーブル名"),
groupByColumn: z.string().describe("グループ化するカラム名"),
aggregateColumn: z.string().describe("集計するカラム名"),
aggregateFunction: z.enum(["SUM", "AVG", "MIN", "MAX", "COUNT"]).describe("集計関数"),
}),
execute: async (args, { log }) => {
try {
log.info(`${args.tableName}のデータを集計しています...`);
const query = `
SELECT
${args.groupByColumn},
${args.aggregateFunction}(${args.aggregateColumn}) AS result
FROM ${args.tableName}
GROUP BY ${args.groupByColumn}
ORDER BY result DESC
`;
log.debug(`実行クエリ: ${query}`);
// クエリ実行
const result = await db.all(query);
return `${args.tableName}の${args.groupByColumn}ごとの${args.aggregateColumn}の${args.aggregateFunction}:\n${JSON.stringify(result, null, 2)}`;
} catch (error) {
log.error(`データ集計エラー: ${error.message}`);
throw new Error(`データ集計エラー: ${error.message}`);
}
},
});
server.addTool({
name: "get-table-info",
description: "テーブルの構造情報を取得する",
parameters: z.object({
tablename: z.string().describe("情報を取得するテーブル名"),
}),
execute: async (args, { log }) => {
try {
// テーブル構造の取得
const columns = await db.all(`
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = '${args.tablename}'
`);
// サンプルデータの取得
const sampleData = await db.all(`
SELECT * FROM ${args.tablename} LIMIT 5
`);
return {
content: [
{
type: "text",
text: `テーブル: ${args.tablename}\n\n列情報:\n${JSON.stringify(columns, null, 2)}\n\nサンプルデータ:\n${JSON.stringify(sampleData, null, 2)}`
}
]
};
} catch (error) {
log.error(`テーブル情報取得エラー: ${error.message}`);
throw new Error(`テーブル情報取得エラー: ${error.message}`);
}
},
});
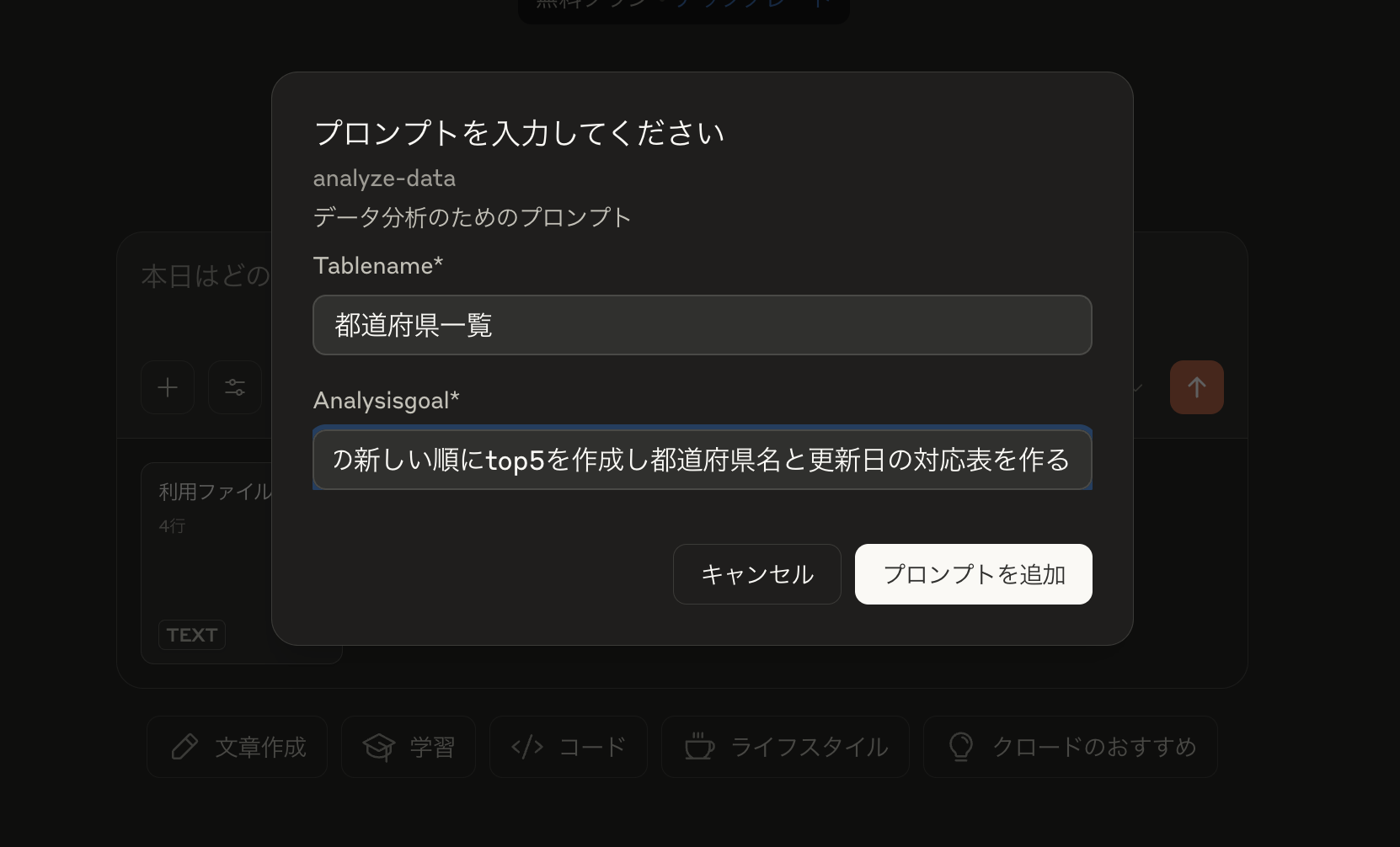
server.addPrompt({
name: "analyze-data",
description: "データ分析のためのプロンプト",
arguments: [
{
name: "tableName",
description: "分析するテーブル名",
required: true,
},
{
name: "analysisGoal",
description: "分析の目的",
required: true,
},
],
load: async (args) => {
// テーブル構造の取得
const columns = await db.all(`
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = '${args.tableName}'
`);
return `
テーブル「${args.tableName}」のデータを分析し、${args.analysisGoal}を達成するためのSQLクエリを作成してください。
テーブル構造:
${JSON.stringify(columns, null, 2)}
分析目標: ${args.analysisGoal}
適切なSQLクエリを提案し、その結果の解釈方法を説明してください。
`;
},
});
// サーバー起動
await server.start({
transportType: "stdio", // CLIツールとして使用する場合
});検証
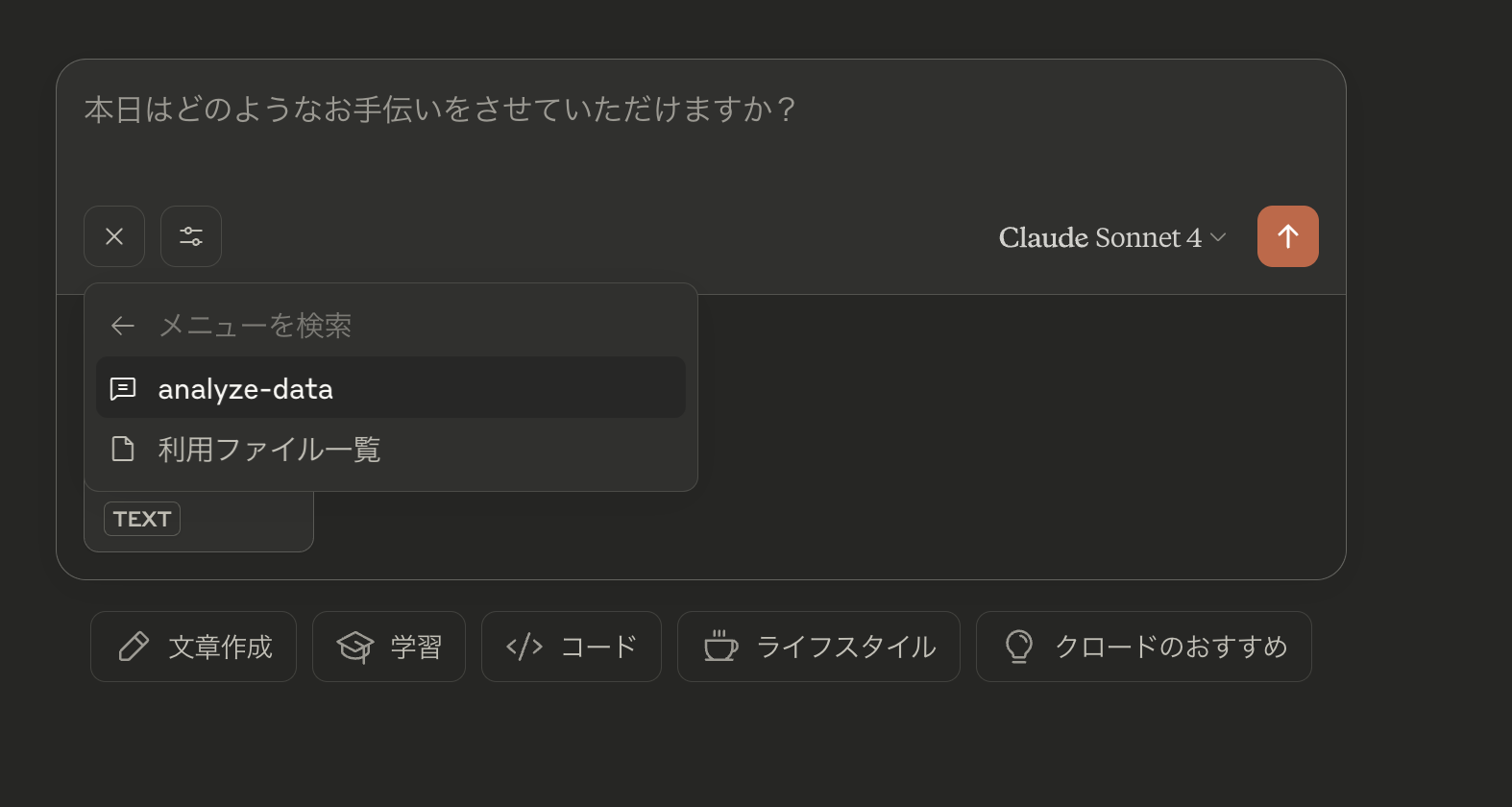
例として「都道府県一覧から更新日の新しい順にtop5を作成し都道府県名と更新日の対応表を作る」流れを指定し、Resources/Prompts/Toolsの連携を確認します。
Resources

Prompts
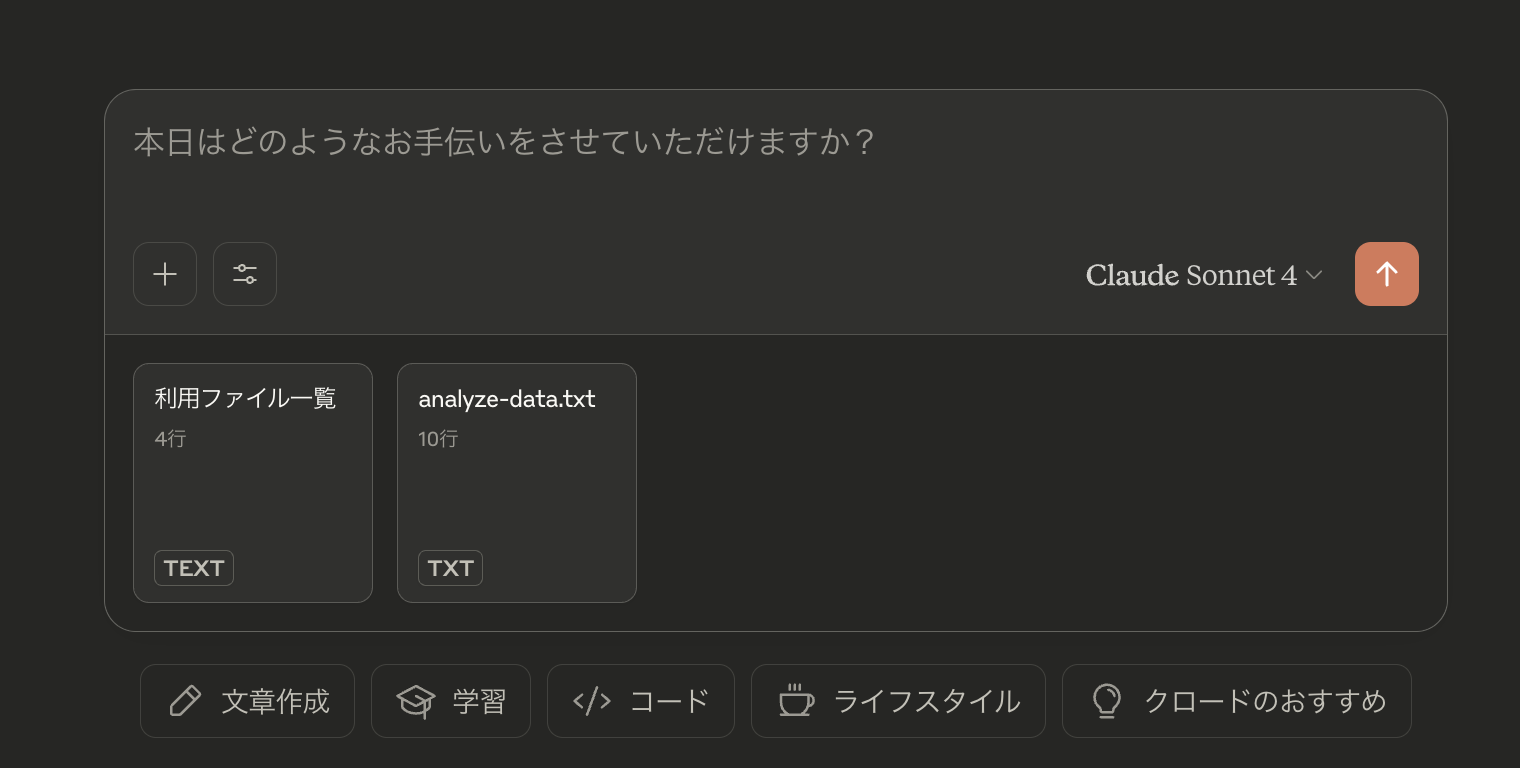
Tools
get-enable-file-list以外のload-csv,run-query等に対しても許可します
最終的な結果
無事Resourcesを参照し、Promptsを構築、Toolsに定義された処理を駆使し目的の検索操作を行うことができました。
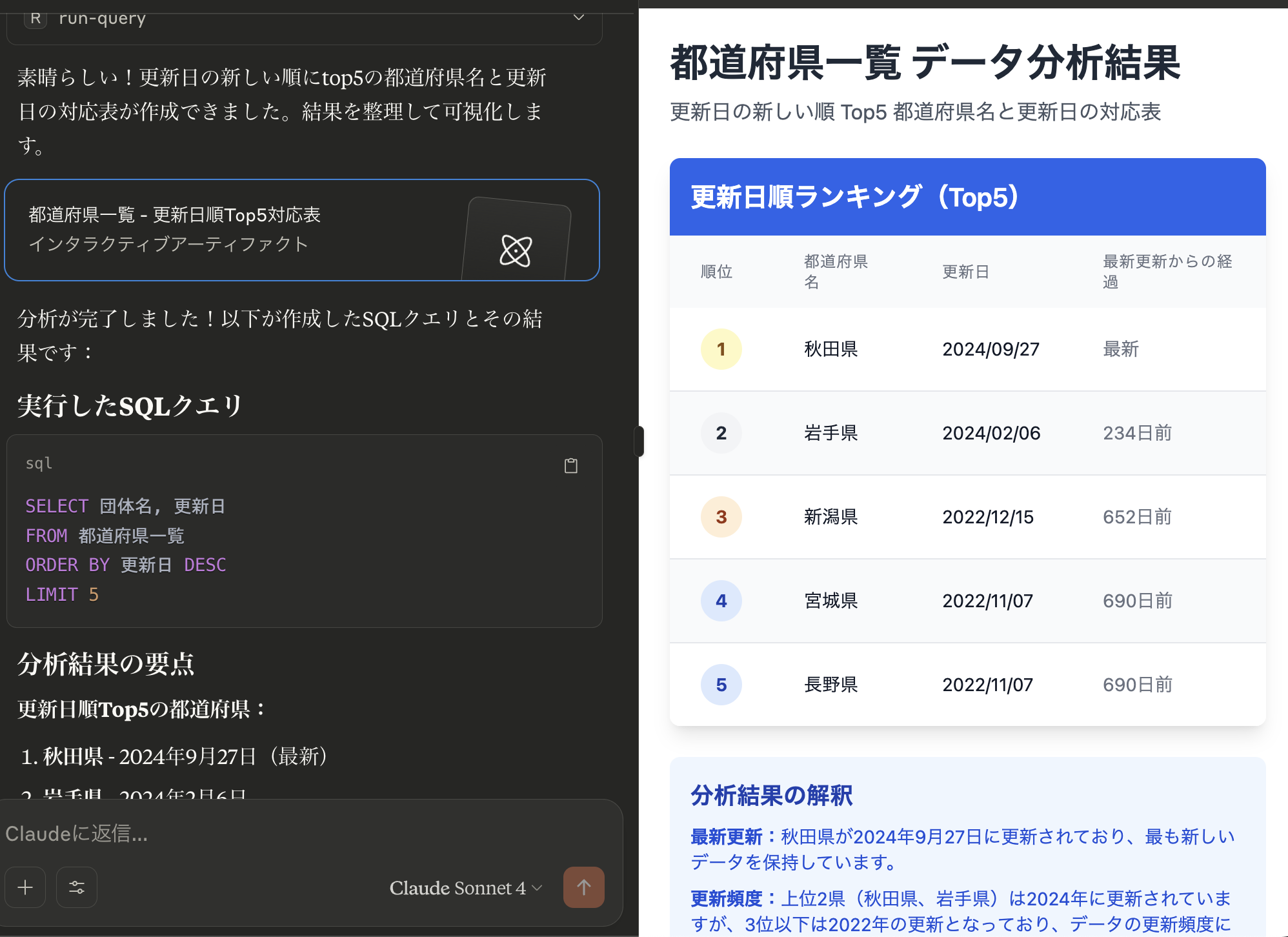
結論
比較的少ないコード量で汎用的な分析が可能な環境を構築できました。
プロダクション環境に組み込む場合、下記課題は最低限解決が必要です。
- SQLがチャットに漏れ出ているためセキュリティ設計が必要
- データソースの拡充
- クラウドへのホスティングや認証機能の追加
MCPを含めたAIエージェントは始まったばかりなので、今後も定期的にキャッチアップしていきたいと思います。
ブログの著者欄
横手 聡
GMOインターネット株式会社
2024年7月GMOソリューションパートナー株式会社(現GMOインターネット株式会社 ネットワークソリューション事業本部 ソリューションパートナー事業部)入社。GMO順位チェッカー、F-Station、AI SEO ディレクター by GMO の開発業務を担当。業務では主にバックエンドやインフラを担当しています。
採用情報


関連記事
-

コードレビュー不要論 ーハーネスが人間の目を代替するとき
技術情報
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート後編】
イベント
-

【2025国際ロボット展 出展レポート】AI ❤ ROBOTs で描く、人とロボットが共存する社会
技術情報
-

【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-

ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

【イベントレポート・後編】GMO Developers Day 2025 -Creators Night-|共創するデザイン組織と次世代クリエイターの可能性
デザイン

KEYWORD
CATEGORY
-
技術情報(578)
-
イベント(223)
-
カルチャー(57)
-
デザイン(59)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- Behind the Scenes
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOインターネットグループ陸上部 – GMOロボッツ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMOロボッツ
- GMO大会議
- Go
- GPU
- GPUクラウド
- GTB
- Hack-1グランプリ
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 映像制作
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-

RubyKaigi 2026にトップスポンサーとして協賛いたします
イベント
-

なぜ「日本一の走り」をヒューマノイドへ生かすのか――「GMOインターネットグループ陸上部 – GMOロボッツ」発足の背景|後編
カルチャー
-

なぜ「日本一の走り」をヒューマノイドへ生かすのか――「GMOインターネットグループ陸上部 – GMOロボッツ」発足の背景|前編
カルチャー
-

学生向けハッカソンHack-1グランプリにTOPスポンサーとして協賛決定!
イベント
-

【イベントレポート・前編】インハウス動画サミット2026|「愛」がつなぐ、インハウス動画クリエイターの未来
イベント
-

100名以上が渋谷に集まった「インハウス動画サミット2026」── 企画の裏側と満足度97.3%の理由
技術情報
採用情報
SNS FOLLOW
