
お客様窓口に日々寄せられる多種多様な問い合わせ――その“声”をAIで整理・可視化する「ブロードリスニング」技術に注目が集まっています。本記事では、GMOインターネットグループの代表電話に寄せられたお問い合わせを例に、言語モデル(LLM)による要望抽出とHDBSCAN+UMAPによるクラスタリングを組み合わせた、最新の問い合わせ分析フローを詳しく解説。ブロードリスニングの仕組みを基に、Stremalitを活用して可視化ダッシュボードとして構築したところから、パラメータ調整の工夫、実務での成果まで、自然言語処理を業務に活かすリアルな実践例を紹介します。
目次
TL;DR
GMOインターネットグループ代表電話窓口に寄せられる多種多様な問い合わせを効率的に分析するため、「ブロードリスニング」という言語モデル(LLM)を活用した取り組みを実践しました。
Pythonで実装し、問い合わせを要約・要望抽出し、言語ベクトル埋め込みや次元圧縮(UMAP)、クラスタリング(HDBSCAN)などを組み合わせて可視化しています。
問い合わせの多彩さゆえにクラスタ数が増えがちで、パラメータ調整が難しいという課題もある一方、専門チームの知見に近い分析結果が得られ、問い合わせ仕分けをほぼ自動で実行できる可能性が見えてきました。
1. GMOインターネットグループ代表電話窓口と分析の背景
窓口の役割・特徴
GMOインターネットグループ代表電話窓口は、グループ全体の問い合わせ先が分からない場合の“駆け込み寺”として機能しています。たとえば、お名前.comの適切な窓口が不明な場合や、人事関連の各種お問い合わせ、グループ内各部門の基本情報に関する問い合わせなど、多種多様な相談が寄せられています。
問い合わせ例
- お名前.comの窓口の電話番号を知りたい
- 採用に関する営業の提案をしたい、退職者からの相談など
- GMOインターネットグループの金融関連サービスについて
- グループ内の異なる部門について基本的な情報を尋ねた
現状の課題
- 商材の多様性: GMOインターネットグループ100社以上から想定される商材が無数にあるため、問い合わせ内容が非常に幅広い
- 商材以外の問い合わせ: 営業・採用系など「誰々さんに繋げたい」「こういう情報が欲しい」といった問い合わせも多い
- ルールベース仕分けの限界: 問い合わせの多様性により、従来のルールベースでの仕分けでは効率的な処理が困難
分析の目的
多様な問い合わせを効率良く分析するため、言語モデルを活用した「ブロードリスニング」技術の試行利用を通じて、問い合わせ分析業務においてどのような活用ができるかを模索することを目的としています。
今回使用したデータについて
初回実施分
- データ規模: 約2,000件
- 期間: 3ヶ月分の問い合わせデータ
- データ形式: 通話の文字起こしデータ
- 処理環境: ConoHa VPS GPUプランでデータ分析を実行
2. 実装について
まず 安野貴博さんの note 記事「【地上波世界初】都知事選で使ったブロードリスニングの技術で衆院選を解析してみた」を読み、“これは自分のプロジェクトにも取り入れたい” と感じたことが今回の着手動機です。
ブロードリスニング自体は、台湾の元デジタル担当大臣 オードリー・タン(Audrey Tang) 氏が 「broadcast(一方向の発信)」に対置して提唱した “多方向の傾聴” フレームワークで、AIで大量の声を整理・可視化し合意形成を支援する手法として知られています。
実装面では、安野さんのチームが公開している GitHub リポジトリ ntv-experiment-public/shugiinsenyo2024-tttc をベースに、データ収集から可視化までのパイプラインをカスタマイズしながら進めていきます。
- 本家: The good hacker: can Taiwanese activist turned politician Audrey Tang detoxify the internet? | Taiwan | The Guardian
- 記事: 【地上波世界初】都知事選で使ったブロードリスニングの技術で衆院選を解析してみた
- リポジトリ:shugiinsenyo2024-tttc

処理の流れ
リポジトリからコードを読んだところ、おおむね以下の内容の処理が行われていました。
- キーフレーズ抽出 (Extraction)
- ベクトル埋め込み生成 (Embedding)
- クラスタリング (Clustering)
- 次元圧縮と座標算出
- クラスタラベル付与 (Labelling)
- 総合的な要約 (Takeaways)
- 結果データの出力 (Output)
- レポート(散布図)の生成
- ブラウザでのレポート表示用にローカルサーバー起動
そこで今回の目的に合わせて以下の内容でパイプラインを定義し、分析ダッシュボードとして再構成しています。
- Stremlit上のUIから分析するファイルを選択
- 問い合わせからLLMで要約を作成
- 要約からLLMを使用し、要望を抽出
- 抽出した要望を言語ベクトルに埋め込み
- 作成したベクトルデータをUMAPで2次元に圧縮
- 次元を圧縮したデータに対して、HDBSCANでクラスタリング
- クラスタから代表点を選出し、LLMでラベルを作成
- グラフ化(圧縮後の2次元データで散布図を作り、クラスタごとに色分け・ラベルづけ)
- Stremlit上でグラフを表示し、詳細を確認
変更・工夫したポイント
- ConoHa VPS GPUプランでセルフホスト
- vLLM で Qwen-2.5-72B を起動し、社内リソースのみで推論を実現
- Dify に接続して「通話Log要望抽出」「クラスタ概要ラベル生成」など各フローを稼働
(該当ステップ: 1,2,6)
- OpenAI-API から Dify への置換
- 既存コードの LLM 呼び出しを Dify 経由に変更
- Prompt/Flow 定義をコード外へ切り離して運用を簡素化
(該当ステップ: 1,2,6)
- 要望 Embedding
- 名古屋大学公開 ruri-large をローカルホストして日本語類似度計算に使用
(該当ステップ: 3)
- クラスタリングを HDBSCAN に変更
- K-means と比べた利点
- クラスタ数を事前に決める必要がない
- ノイズ(外れ値)を自動で切り分けられる
- 要望データは件数・分布が都度変動するため、柔軟な HDBSCAN が適合
- クラスタ数を事前に決める必要がない
- ノイズ(外れ値)を自動で切り分けられる
- 要望データは件数・分布が都度変動するため、柔軟な HDBSCAN が適合
(該当ステップ: 5)
- 分析ダッシュボード化
- 単発ツールを Streamlit でインタラクティブなダッシュボードへ再構成
- すべて Python で実装し、結果を即時確認可能
3. UIについて
と、いうわけで完成したアプリのWebUIがこちらになります。
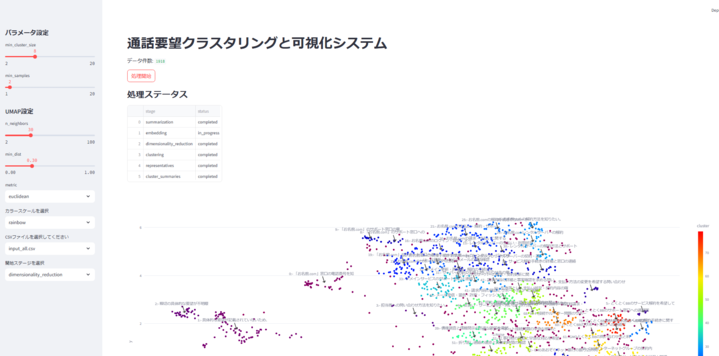
Streamlitの機能を利用し、データの処理のパラメータおよび、フロントエンド側の表示する際のパラメータ変更も簡単にできるようにしています。
- クラスタリングのパラメータと次元圧縮のパラメータ
- クラスタの色のパターン
- 入力ファイル選択
- 開始ステップ

グラフはPlotlyの標準機能を活用
- 点の詳細表示
- 拡大/縮小
- 画像保存
などなどが簡単にできる機能があります。
StreamlitとPlotlyに感謝ですね

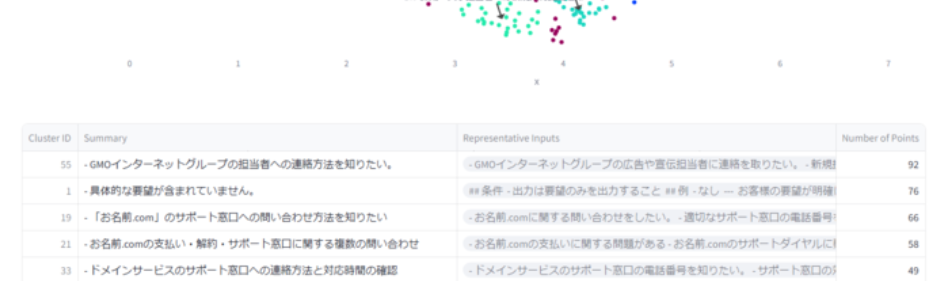
グラフの下にはサマリのテーブルがあり、詳細を確認できるようになっています。
4. 結果と考察
4.1 「団子になる」失敗パターン
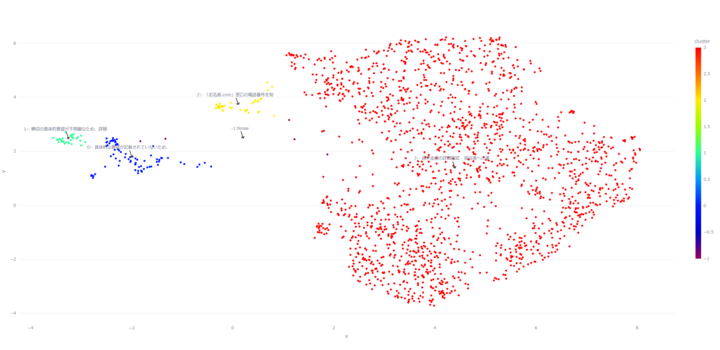
パラメータを既定値のまま適用したところ、複数のクラスタが重なり一塊となる「団子になる」現象が確認されました。
4.2 分析がうまくいったケース
今回はパラメータ調整を手作業で行ったため、調整には何度かの試行錯誤を経て以下のようなクラスタを出力することができました。
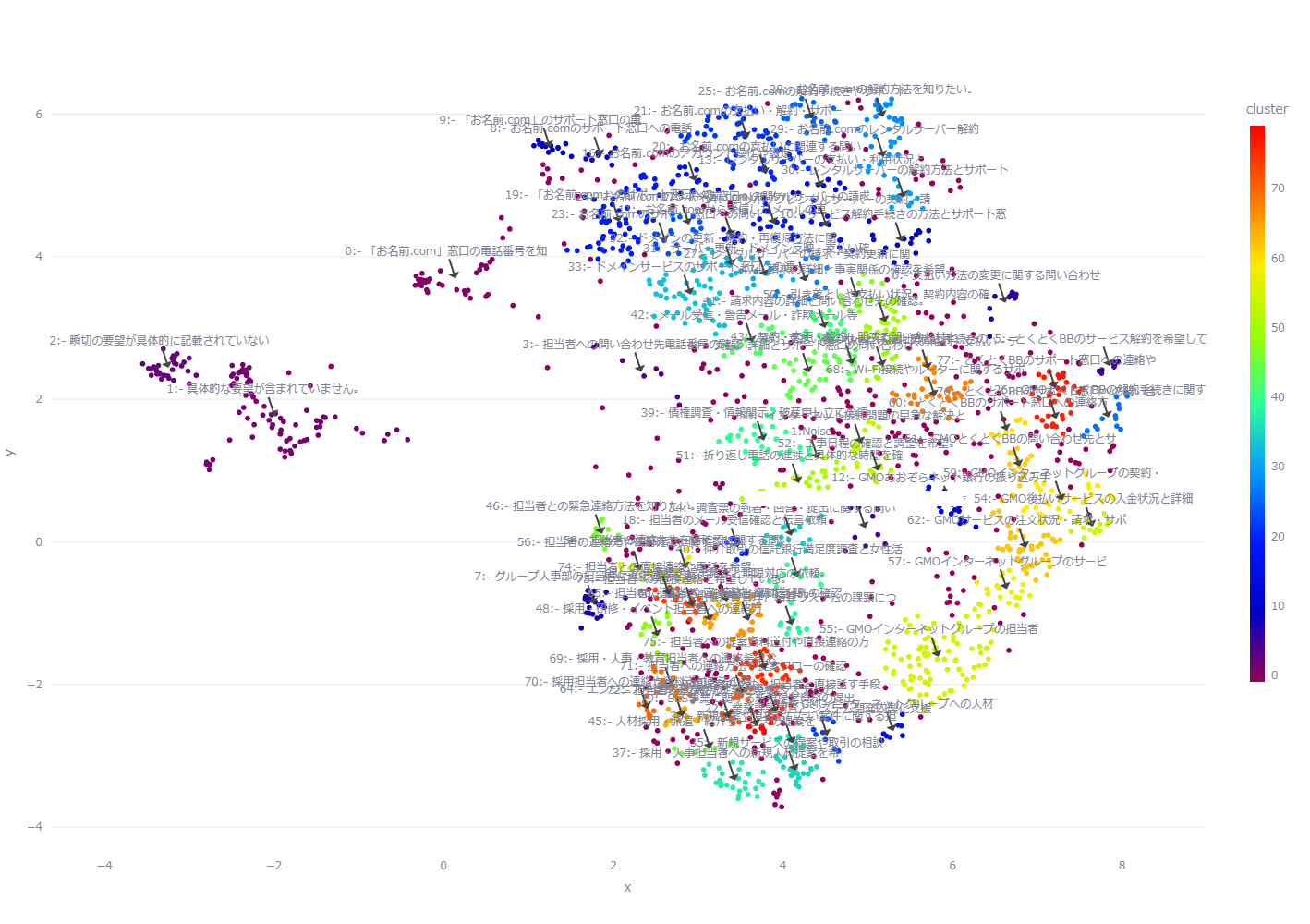
カテゴリなどに関する事前設定を行わなくても、内容に応じてクラスタが自然に分かれることが確認できました。
この画像の場合、クラスタが100近く形成されています。
一般的なクラスタリング視点では失敗に近い状態ではありますが、問い合わせが多種多様なカテゴリに分類できるので、この出力も一定の意味を持ったものとなっております。
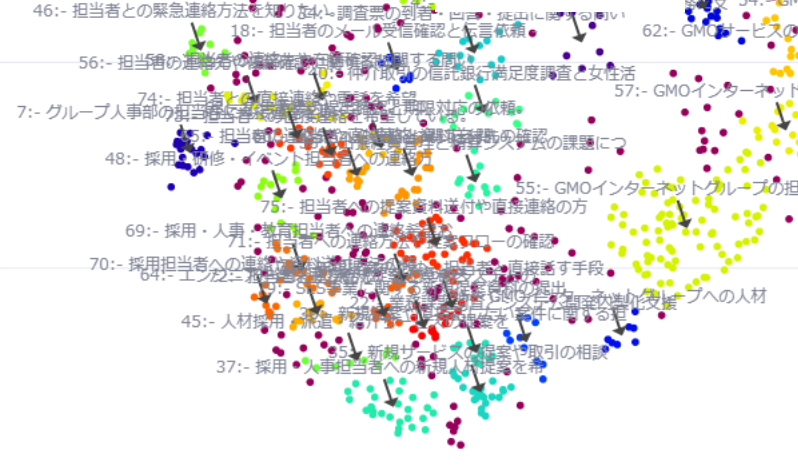
拡大してみると各クラスタごとに内容に応じて詳細に分離されていることが確認できます
お名前.com関連のお問い合わせ

人事や採用担当者への連絡希望など
5. まとめ
今回の取り組みにより、窓口業務の全体像をつかみ、問い合わせの傾向を分析するための基盤が整いました。実装では、約 2,000 件のデータを 10〜20 分ほどで処理できます。
人手で行うには負荷が大きく、実行が難しかった分析も、ブロードリスニングを使うことで現実的な施策になりました。さらに、ドメインエキスパートの確認を経て、実務に利用可能な精度を備えていることも確認できています。今回の分析で、お名前.comに関するお問い合わせが非常に大きなボリュームを占めていることがわかりました。
この結果をもとに該当窓口での取り組みを計画し、分析実施からこの記事の公開までの間に成果を出すという実績を作ることができました。ブロードリスニングによって得られた結果をもとにきちんと成果につなげることができ、確かな手ごたえを感じることができました。
一方で、調整可能なパラメータが多く、完全自動化にはまだ壁が残っています。調整の際にも試行錯誤の要素が多く、使うのにも一定の技術理解が求められるようなものになってしまいました。
今後は、ほかの窓口データへの横展開や追加手法の検証を進め、活用の幅を広げていく予定です。
みなさんも、ブロードリスニングを一度試してみてはいかがでしょうか。
ブログの著者欄
採用情報


関連記事







KEYWORD
CATEGORY
-
技術情報(579)
-
イベント(224)
-
カルチャー(57)
-
デザイン(60)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- Behind the Scenes
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOインターネットグループ陸上部 – GMOロボッツ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMOロボッツ
- GMO大会議
- Go
- Good Morning
- GPU
- GPUクラウド
- GTB
- Hack-1グランプリ
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 技術書典20
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 映像制作
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP






採用情報
SNS FOLLOW
