
この記事は GMOインターネットグループ Advent Calendar 2025 13日目の記事です。
GMOインターネット株式会社の春田と申します。
今回は、社内データの利活用を促進するためのデータ基盤を構築した話をしようと思います。
目次
はじめに
この記事では、Google Cloud + Snowflake + Tableau Cloud を組み合わせることで
- なるべく安価かつ柔軟にスケールするデータ基盤の構築
- 最終的に Tableau Cloud での可視化・レポーティング
- セマンティックレイヤーによるビジネス指標の一元管理
- 自然言語による分析(Snowflake Cortex 系の機能)
までを一気通貫で実行できるデータ基盤を構築した話を紹介いたします。
近年は、LLMやMCPなどの台頭によりデータ活用の必要性が改めて広く認識されていますが、なかなか実際に社内でデータを使いこなすに至れていないケースもあるかと思います。よくある課題としては次のようなものがあります。
- 部署ごと、プロダクトごとに保存場所が分散し、データがサイロ化している
- 部署によって同じ指標(たとえば「売上」)でも細かい意味合いが異なる
- レポートの作成がExcelやGoogle スプレッドシート上などでのコピペ作業になっている
こういった課題は、とりあえずデータを集積して保存する仕組み を作るだけでは解決できません。
重要なのは、データを統一的なルールで整理し誰でも再利用ができる状態を目指すことです。この状態を作るために必要なのがデータ基盤です。この状態を構築するのに重要となるのが次のポイントです。
- コストと柔軟性のバランス:必ずしも基盤を巨大に構築する必要はなく、必要な時に必要なだけ使える設計を考える。
- データ定義一元化:誰でも・どこからでも・いつ見ても 同じ指標は同じ意味合いの値を返す。
- 運用負荷を下げる仕組みづくり:ETLやデータ連携を一定のフローで自動化し属人化を未然に防ぐ。
本記事では、これらの課題に対して
Google Cloud(データ加工)× Snowflake(蓄積と意味づけ)× tableau(可視化)
という構成が、それぞれの役割をうまく分担しながら実現できることを、実際に構築するための設定やコード、クエリを交えて簡単に解説していきます。
全体アーキテクチャ概要
まず、今回の構成をざっくり図にすると以下のようなイメージです。
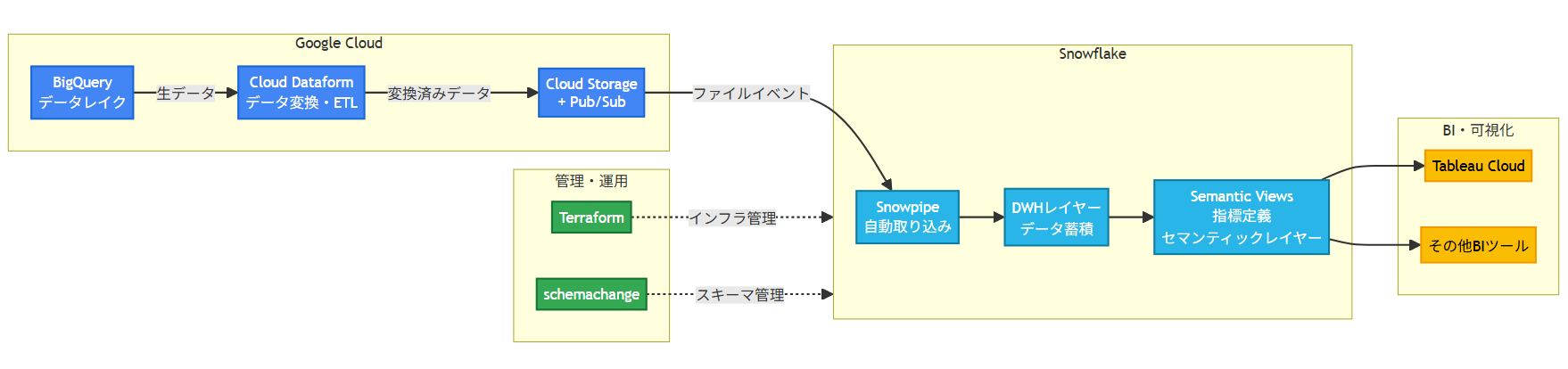
ポイント
- コストを抑えるため、Google Cloud 側での変換(Dataform + BigQuery)とSnowflake 側での格納・セマンティックレイヤーを棲み分ける。
- GCS バケットへのファイルアップロードをトリガーに、Snowpipe で Snowflake に自動取り込みすることで運用コストを削減。
- Snowflake Semantic Views を単一の真実の源泉(Single Source of Truth)として、BI ツールが何であっても同じ指標定義を共有可能にする。
- Snowflake のオブジェクトは Terraform + schemachange でコード管理し、インフラとスキーマ変更の責務を分離。
1. Cloud DataformでDWHレイヤーを構築する
最初のステップは、BigQuery上にDWHレイヤーまでをしっかり作ることです。ここでは、Cloud Dataform(以下 Dataform)を使って、SQLベースで変換パイプラインを管理していきます。また、加工する前の生データ(データレイクに相当)はすでにBigQuery上のテーブルに格納されていることを前提として進めます。
1.1. Dataform
DataformはBigQuery上でSQLベースの変換パイプラインを管理するためのツールであり、.sqlxという独自の拡張子ファイルに設定(config)とクエリを同居させられるのが特徴です。普段使用しているSQLクエリを書くのと同じような感覚でパイプラインを記述できます。
1.2. refやincrementalについて
テーブル同士の依存関係も ref関数 を使用すれば簡単に定義でき、DAGを自動構築できるメリットが強力です。Dataform 内で管理しない(依存関係を持たない)外部オブジェクトを参照したい場合は resolve関数 を使用できます。循環参照を回避したいときにも有効な手となります。
config {
type: "table",
schema: "analytics"
}
select
t.*
from ${ref("stg_orders")} t -- 依存関係あり
left join ${resolve("some_external_tbl")} e -- 依存関係なし
on t.id = e.id
ref関数で参照されたテーブル・ビュー・declaration は、自動的に Upstream として扱われるので
- 実行順序の自動解決
- 部分実行時の「どこまで再計算するか」の判断
に効いてきます。さらに、configでtype: “incremental”を設定すれば、増分テーブルを定義することができます。たとえば日次データを格納するテーブルを定義したいが、更新を時間ごとやニアリアルタイムで実装したい場合で有効な手です。
config {
type: "incremental",
schema: "dwh_mart",
name: "fct_order_daily",
uniqueKey: ["order_date", "order_id"]
}
select
date(order_timestamp) as order_date,
order_id,
customer_id,
amount
from
${ref("orders")}
where
${when(
incremental(),
"order_timestamp > (select max(order_timestamp) from " + self() + ")"
)}これにより、フルロード・増分ロードを同じsqlxファイルで表現できます。
2. GCS → Snowpipeで自動連携する
次に、BigQueryに構築されたDWH相当のテーブルをGCSにエクスポートし、Snowflake Snowpipeを用いて自動ロードする流れを作ります。フローとしては以下のイメージとなります
- (Google Cloud側): Cloud Pub/Subを作り、GCSのイベントと紐づける
- (Snowflake側): GCSへの安全なアクセスのために、STORAGE INTEGRATIONを作成する。払い出されたサービスアカウントにGCSバケットの閲覧IAMロールを付与
- (Snowflake側): 外部ステージ(External Stage)を作成し、STORAGE INTEGRATIONと紐づける
- (Snowflake側): Pub/Sub連携のためにNOTIFICATION INTEGRATIONを作成する
- (Snowflake側): Snowpipeを作成する。AUTO_INGESTをTRUEに指定。
2.1. 統合(INTEGRATION)と外部ステージの作成
Snowflake側では、まずGCSバケットへの安全なアクセスのために STORAGE INTEGRATION を作成します。なお、INTEGRATIONとは外部システムとの連携に必要な設定(認証、接続、権限など)を Snowflake 側に定義し、ロールベースで制御するためのオブジェクトのようなものです。
CREATE OR REPLACE STORAGE INTEGRATION GCS_DATINF_INTEGRATION
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'GCS'
ENABLED = TRUE
STORAGE_ALLOWED_LOCATIONS = (
'gcs://my-bucket/dwh_export/'
)
COMMENT = 'Storage integration for GCS bucket';DESC INTEGRATION GCS_DATINF_INTEGRATIONを実行して詳細を確認すると、Snowflake 側で払い出された GCS サービスアカウントが確認できるので、Google Cloud 側でこの SA に対してバケットの読み取り権限を付与する必要があります。
次に外部ステージを作成します。先程作成したストレージ統合を指定します。また、取り込みファイル形式についてもいろいろあります。
CREATE OR REPLACE STAGE DWH_EXPORT_STAGE
STORAGE_INTEGRATION = GCS_DATINF_INTEGRATION
URL = 'gcs://my-bucket/dwh_export/'
FILE_FORMAT = (TYPE = PARQUET);最後に、Google Cloud側からファイルの作成や更新を通知するための NOTIFICATION INTEGRATIONを作成します。前提として、既にCloud Pub/Subのトピックとサブスクリプションを作成し、GCSバケット内のイブジェクトイベントをPub/Subトピックに通知する設定は済んでいるとします。
CREATE OR REPLACE NOTIFICATION INTEGRATION GCS_PIPE_NOTIFY
TYPE = QUEUE
NOTIFICATION_PROVIDER = GCP_PUBSUB
ENABLED = TRUE
GCP_PUBSUB_SUBSCRIPTION_NAME = '<projects/.../subscriptions/...>';2.2. Snowpipeの作成
最後に、外部ステージと通知統合を使ってSnowpipeを作ります
CREATE OR REPLACE PIPE DWH_ORDERS_PIPE
AUTO_INGEST = TRUE
INTEGRATION = GCS_PIPE_NOTIFY
AS
COPY INTO RAW.DWH_ORDERS_STAGE
FROM (
SELECT
$1:order_date::DATE AS order_date,
$1:order_id::STRING AS order_id,
$1:customer_id::STRING AS customer_id,
$1:amount::NUMBER AS amount
FROM @DWH_EXPORT_STAGE
);これにより
- GCSの dwh_export/ 以下にファイルが置かれる
- Pub/Sub経由でSnowflakeにイベントを通知される
- Snowpipeが自動で RAW.DWH_ORDERS_STAGE にロードする
という流れができます。
3. Snowflake Semantic Viewsでセマンティックレイヤーを構築する
3.1. Semantic Viewsの役割
SnowflakeのSemantic Viewsは、Snowflake上にビジネス指標(顧客、注文、商品など)とメトリクスを定義して、物理テーブルとビジネス概念の橋渡しを行うためのオブジェクトです。
- DWHのテーブルを論理テーブルとして登録
- 「顧客」「注文」「売上」などのビジネス的な概念をディメンションやメトリクスとして定義
- それらの関係をRELATIONSHIPS句で明示する
これを行うことで、以下のことが実現できます。
- BIツールから一貫した指標定義を利用できる
- Snowflake Cortex AnalystやSnowflake Intelligenceなどの自然言語インターフェースから問い合わせができる
今回はTableauとの連携を主軸に話すため詳しい設定方法などは取り上げませんが、Semantic Viewsを定義した時点でSnowflake上では自然言語を使ったデータへの問い合わせや分析が可能となっています。たとえばCortex Analystを用いたデータ問い合わせの例は以下のようになります。
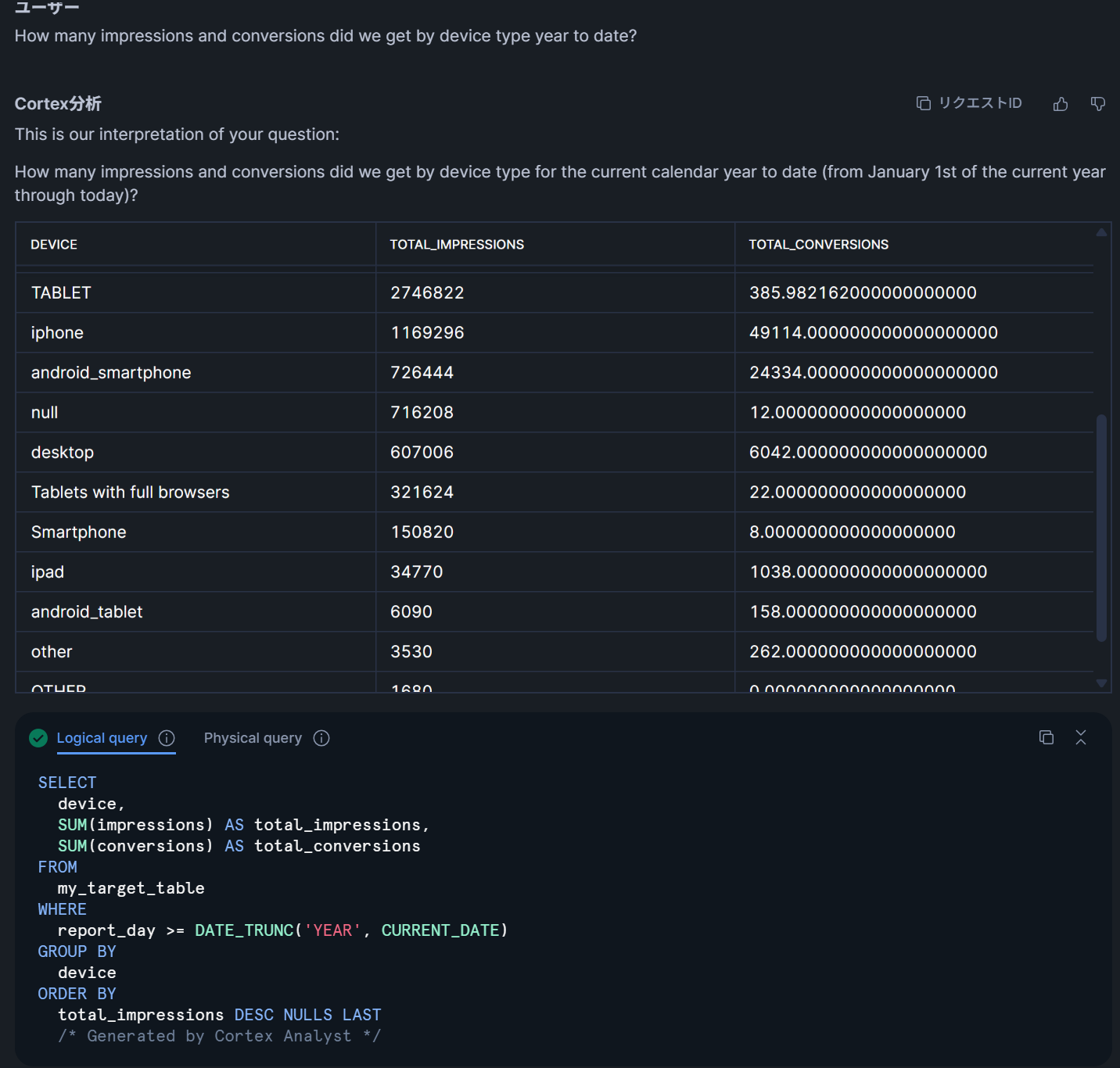
ここでは今年中のデバイスごとのインプレッションとコンバージョン数の合計を問い合わせています。例では英語にしていますが、日本語での問い合わせも可能です。DEVICEカラムなどはディメンションとして定義しているため、こういった切り口の分析が簡単に行えるようになっています。
自前でクエリを書いてデータに問い合わせするときには、以下のようにSEMANTIC_VIEW関数を通してデータにアクセスできます。
FROM semantic_view(
MART.SV_SALES
DIMENSIONS
orders.order_date,
customers.prefecture
METRICS
orders.total_gross_revenue
FILTERS
orders.order_date >= '2024-01-01'
ORDER BY
orders.order_date DESC
LIMIT 100
);3.2. Semantic Viewの定義
本記事では次のようなLogical Tableを想定してsemantic viewを定義します。
- lt_customers
- lt_orders_daily
CREATE OR REPLACE SEMANTIC VIEW MART.SV_SALES AS
LOGICAL TABLE lt_customers
DIMENSIONS (
customer_id STRING PRIMARY KEY,
customer_segment STRING,
prefecture STRING,
created_at DATE
)
SOURCE sql_table = DWH.DIM_CUSTOMER
LOGICAL TABLE lt_orders_daily
DIMENSIONS (
order_date DATE,
customer_id STRING
)
MEASURES (
order_count NUMBER,
gross_revenue NUMBER,
avg_order_value NUMBER
EXPRESSION = gross_revenue / NULLIF(order_count, 0)
)
SOURCE sql_table = DWH.FCT_ORDER_DAILY
RELATIONSHIPS (
lt_orders_daily.customer_id -> lt_customers.customer_id
);
この例では、lt_orders_dailyテーブルのcustomer_idカラムは、lt_customersテーブルのcustomer_idに依存しています。このように、テーブル間の依存性も含めて定義が可能です。
また、Semantic Viewsでは論理テーブル・ディメンション・メトリクスごとにSYNONYMSを定義できます。SYNONYMSは、検索やカタログでの見つけやすさを向上するために定義できる、同義語のメタデータです。
たとえば、「売上」と「売上高」、「revenue」は同じなのでSYNONYMSとすることができますし、サービス内で独立に定義される用語が存在するときに、どの概念と類似しているのかを明示することができます。以下はSYNONYMSの定義例です。
TABLES (
customers AS DWH.DIM_CUSTOMER
PRIMARY KEY (customer_id)
WITH SYNONYMS = (
'顧客',
'customer',
'client'
)
);3.3 Terraform + schemachangeでコード管理する
Snowflake環境の運用はGUIでも簡単に行うことができます。一方で、基盤で取り扱いたいデータの幅が広がってくると、作成したテーブルやビュー、INTEGRATIONなどの管理が煩雑になってくるかと思います。手作業でコンソールから作成したオブジェクトが散在するような状態は避けたいところです。
ここでは
- 変更頻度が低い「インフラ寄り」オブジェクト:Terraform
- 変更頻度が高い「スキーマ寄り」オブジェクト:schemachange
という使い分けによって管理する方針を採ります。本記事では、特にschemachangeを用いたDDLのバージョン管理について詳細に説明します。
schemachangeとは、Snowflake公式のPythonベースのデータベース変更管理(DCM)ツールです。migrationファイルを作成し、CI/CDツールとの組み合わせも容易にでき、DevOpsを実現できます。schemachangeによるディレクトリ構成例はたとえば以下のようになります。
snowflake/
schemachange/
config.yml
scripts/
V001__create_schema_dwh.sql
V002__create_table_fct_order_daily.sql
V003__create_dim_customer.sql
V010__create_semantic_view_sv_sales.sqlconfig.ymlでは接続先Snowflakeアカウントの情報や、使用するウェアハウス、アクセス先のdatabaseやschemaを指定できます。scriptsディレクトリは実行するDDLをsqlファイルとして作成でき、ファイル名にバージョンを指定することで、その順序を決定することができます。先程のsemantic viewの定義もこのsqlファイルとして書くことができます。
ただし、作成するスクリプトの名前は、バージョンファイルでは以下のルールでなければなりません。
V{バージョン番号}_{説明}.sqlバージョン番号の書き方は任意です。区切り文字として「ドット(.)」と「アンダースコア(_)」を使用することができ、たとえば
- V2.0.001
- V15_1
- V20251213_100000
などが指定できます。schemachangeは区切り文字で分割した左側の数値を優先的に見て、昇順にソートして実行してくれます。また、schemachageは履歴テーブル管理も自動で行ってくれるため、実行済みのクエリを再実行することもありません。
このようにTerraformやschemachangeを使い分けることで、GitHub ActionsなどからCI/CDを実現することが可能です。
4. Tableau CloudとSnowflakeを接続する
最後に、BIツールであるTableau Cloudとの接続方法とクエリ発行のやり方について説明します。本記事では例としてTableau Cloudを使用していますが、Snowflakeは様々なBIツールとの連携が可能ですので、必要に応じて読み替えていただければと思います。
4.1. 認証方式について
本記事ではサービスアカウント + カスタムロールを用いたSnowflake OAuth(Custom OAuth)での接続をイメージして進めていきます。
4.2. ロールとユーザ(サービスアカウント)作成
Snowflake側で、接続のためのサービスアカウントとロール、権限付与などを行います。これらはSnowflake運用の基礎となる部分であり、今後変更する可能性もかなり低いと思いますので、次のようなhclファイルを作成してapplyしてみましょう。
resource "snowflake_network_rule" "tableau_ipv4s" {
name = "TABLEAU_IPV4S"
mode = "INGRESS"
type = "IPV4"
value_list = ["141.163.208.0/23"]
comment = "Tableau Cloud連携用サービスアカウントに許可するIPv4の範囲"
}
resource "snowflake_network_policy" "tableau_cloud_unrestricted" {
name = "TABLEAU_CLOUD_UNRESTRICTED_POLICY"
allowed_network_rule_list = [snowflake_network_rule.tableau_ipv4s.name]
comment = "Tableau Cloud連携用ポリシー"
}
resource "snowflake_user" "tableau_svc" {
name = "TABLEAU_SVC"
login_name = "TABLEAU_SVC"
type = "SERVICE"
default_role = "ACCOUNTADMIN"
must_change_password = false
disabled = false
comment = "Tableau Cloud連携用サービスアカウント"
network_policy = snowflake_network_policy.tableau_cloud_unrestricted.name
}
resource "snowflake_grant_account_role" "grant_accountadmin_to_tableau_svc" {
role_name = "ACCOUNTADMIN"
user_name = snowflake_user.tableau_svc.name
}
この例では簡単のためにサービスアカウントtableau_svcのデフォルトロールとして”ACCOUNTADMIN”を指定していますが、実務上ではセキュリティ的に問題がありますので、カスタムロールを作成して必要な権限を付与することをお勧めします。
そのうえで追加でできるセキュリティ施策としてネットワークルール、ネットワークポリシーを作成し、Tableau Cloudの日本向けOutbound IP範囲のみを許可(Allow)しています。
4.3. Snowflake PATによる認証
次に、Tableau Cloud から Snowflake へパスワードレスで接続するためのPATを発行します。ただし、PATは最大でも1年の有効期限となるため、定期的にメンテナンスが必要になります。
新しいトークンを発行したらTableau Cloud側での認証設定も都度反映させる作業が必須です。そういった理由から、Snowflake上でのPAT発行からTableau Cloudの認証情報変更まではコード上の管理よりもドキュメント化して手動で対応するシステムを採用します。
注意点として、PATはトークン自身が権限を持つわけではないので、ROLE_RESTRICTIONを指定して制限する必要があります。ユーザ自身がACCOUNTADMINなどの強いロールを持っていても、PATでは特定の権限を持つカスタムロールのみを使用させるための仕組みがあり、以下のようなクエリを実行することで設定できます。
PATによるトークン発行をクエリで実行したい場合は以下の通り実行します。
ALTER USER IF EXISTS TABLEAU_SVC
ADD PROGRAMMATIC ACCESS TOKEN tableau_cloud_pat
DAYS_TO_EXPIRY = 90 -- 有効期限
ROLE_RESTRICTION = 'EXPAMPLE_ROLE'; -- このロールでのみ権限評価そうしたら、次のシステム関数を実行し、トークンを発行します。
SELECT SYSTEM$GENERATE_PROGRAMMATIC_ACCESS_TOKEN('TABLEAU_SVC', 'tableau_cloud_pat');
-- 以下は戻り値の例
{
"token": "v1.pat.xxxxxxxxx...",
"expires_at": "2025-12-13T12:34:56Z"
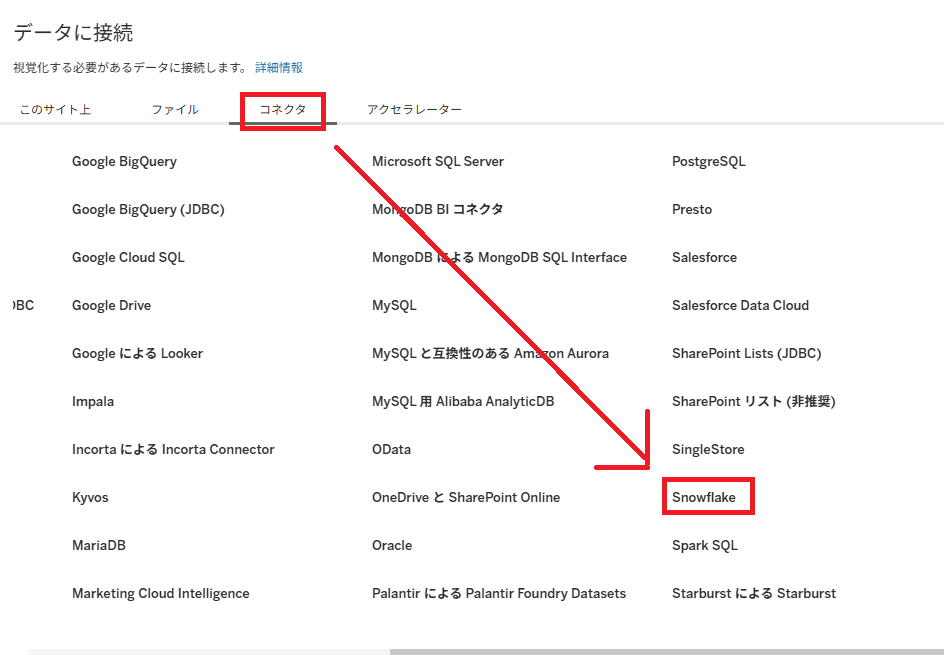
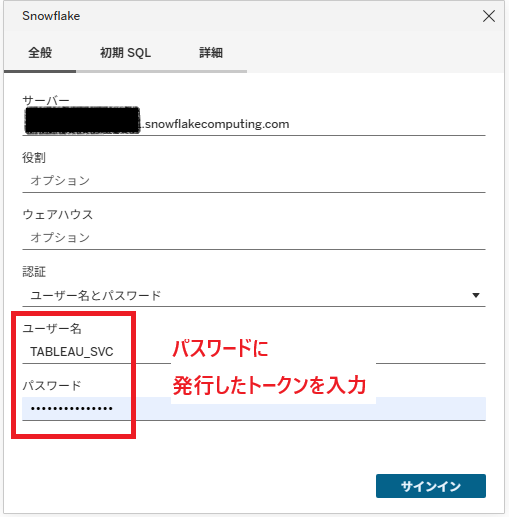
}トークンを控えつつ、今度はTableau Cloudの画面から新規データ接続、あるいは既存の接続の編集画面からSnowflakeを選択し、「サーバー」「ユーザー名」「パスワード」に適切な値を入力します。ただし
- 「ユーザー名」:さきほど作成したサービスアカウントの名前
- 「パスワード」:発行したトークン
4.4. Tableau Cloudからクエリを発行してみる
接続後は、以下のようなパターンでデータを参照できます。
- DWH / MART の物理テーブルやビューに直接接続する
- Tableau側から「カスタムSQL」で SEMANTIC VIEWを呼び出す
特に後者については以下のように「新しいカスタムSQL」から呼び出すことができます。必要に応じて、SEMANTIC VIEWをさらにラップしたビューか動的テーブルをTableauのデータソースとして公開し、それを参照することもできます。
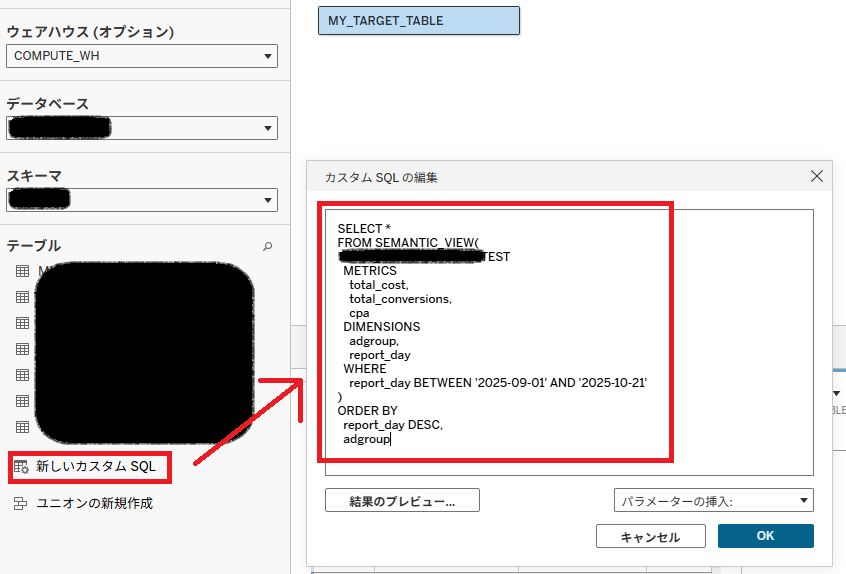
これにより、Tableau CloudからSnowflakeで定義したSemantic Viewを通して統一化された指標でデータにアクセスでき、ダッシュボードを構築できます。
5. おわりに
本記事では、
- Cloud Dataform + BigQueryでDWHレイヤーまでのETLを構築
- GCS → Snowpipe → Snowflake でスキーマ付きのデータを自動連携
- Snowflake Semantic Viewsでビジネス指標を意味づけ
- Terraform + schemachangeでSnowflakeオブジェクトをコード管理
- Tableau Cloudからサービスアカウント発行し、トークン経由で安全に接続
というところまでを、一気通貫で紹介しました。ポイントは「最初から巨大でなんでもできる基盤」を目指すのではなく
- 生データの置き場とDWHレイヤーをきちんと分離する
- Snowflake側には “意味づけ” と “配布” に集中してもらう
- 権限やスキーマ変更は Terraform / schemachange に寄せて人的運用コストを下げる
- BIツールはあくまで “窓口” として差し替え可能に保つ(Single Source of Truth は Snowflake Semantic Views に寄せる)
という役割分担を明確にしたことだと感じています。
この記事が、これから Google Cloud や Snowflake を使って社内のデータ活用を進めていきたい方の一助になれば幸いです。
ブログの著者欄
採用情報


関連記事







KEYWORD
CATEGORY
-
技術情報(574)
-
イベント(220)
-
カルチャー(55)
-
デザイン(58)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- GPU
- GPUクラウド
- GTB
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート後編】
イベント
-

【2025国際ロボット展 出展レポート】AI ❤ ROBOTs で描く、人とロボットが共存する社会
技術情報
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート前編】
イベント
-

【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-

ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

コールセンターでSpeech2Speech AIを繋ぐときに知っておきたい3つの接続方式
技術情報
採用情報
SNS FOLLOW
