
この記事は GMOインターネットグループ Advent Calendar 2025 8日目の記事です。
GMOエンペイのR.Sと申します。直近ではLLMを使った機能開発を行っており、そこで直面した課題と解決策に多くの実践的な学びが詰まっていたので、今回共有させていただきます。
目次
コンテキストエンジニアリングとは
最近「プロンプトエンジニアリング」という言葉をよく耳にしますが、ここではもう少し広い概念として「コンテキストエンジニアリング」という視点で話を進めます。
コンテキストエンジニアリングとは、LLMに対して「何を、どのような形で、どんな順序で渡すか」を設計する技術です。単にプロンプトの文言を工夫するだけでなく、以下のようなことを考えます。
- 入力データをどう前処理するか
- どのタイミングでどの情報をLLMに渡すか
- 複数のLLM呼び出しをどう連携させるか
- 出力の品質を安定させるためにどんな工夫が必要か
プロンプトを書くだけでは解決できない問題が実は多く、そこに「コンテキスト」の設計が重要になってきます。
誰に向けた記事か
この記事は、以下のような方に役立つと思います。
- LLMをプロダクトの機能として組み込もうとしているエンジニア
- 「LLMにExcelやCSVを読み込ませたらうまくいかない」と悩んでいる人
- プロンプトを何度調整しても出力が安定しないと感じている人
スプレッドシート形式かつフォーマットが決まっていないデータを読み込む、というユースケースのTipsは世の中に少ないので、特にそういった方には参考になるかもしれません。
LLMとスプレッドシートデータの相性問題
今回のケースでは、「ユーザーが独自に管理しているExcel/CSVファイルから、必要な情報を抽出してシステムに取り込む」という機能を開発しました。
一見、シンプルに「LLMにExcel/CSVを渡して『このデータを抽出して』と頼めばいいだけでは?」と思われるかもしれません。結論から言うと、それだけでは全然うまくいきませんでした。
LLMは自然言語処理が得意ですが、構造化されたデータ(特にスプレッドシート形式)を正確に扱うのは実は苦手です。いくつかの理由があります。
1. 位置参照の曖昧さ
CSVをテキストとして渡すと、人間には見える「行・列」の概念がLLMには曖昧になります。特に空セルが連続する場合、カンマの連続(,,,)をLLMが正しく解釈できず、セルの位置がズレてしまうことがあります。
2. コンテキストウィンドウの制約
大量のデータを一度に渡すと、トークン数の上限に達します。また、データ量が多いとLLMの「思考」に使うトークン(thinking budget)も圧迫され、処理の質が下がります。
現状、inputで大量のデータを読み込むことが可能なモデルは増えており、各モデルもinput tokenの分量をアピールしていることが多い印象です。一方で、output tokenの上限は相対的に低く、今回検証していた中でも、上限に達してしまったのはoutput tokenで、output tokenの大部分をthinking budgetで消費していることが要因でした。
これの解決策としては後述するTips2・3が有効でした。
3. 複雑なタスクの品質低下
「ヘッダー行を特定して、構造を理解して、不要な行を除外して、データを抽出して」と一度に複数のことを頼むと、各タスクの品質が低下します。

実践で効いたTips
ここからは、検証を通じて見つけた具体的な解決策を紹介します。
Tips 1: 空セルには明示的なプレースホルダを入れる
CSVで空セルが続くと、LLMは位置を見失いがちです。これを防ぐために、前処理として空セルに「null」などの文字列を入れるようにしました。
# Before
田中,1000,,,,100,,,,,2000,
# After
田中,1000,null,null,null,100,null,null,null,null,2000,nullプロンプト側でも「nullは空を意味する」というヒントを与えることで、LLMが正確にセルを参照できるようになりました。
地味な工夫ですが、これだけで参照ズレの問題が大幅に改善しました。
Tips 2: タスクは徹底的に分割する
「一つのプロンプトで一つのタスクだけ」という原則は、言葉では知っていても、実際にやってみないとその重要性はわかりません。
最初は一つのプロンプトで以下を全部やろうとしていました。
- ヘッダー行の特定
- データ構造の理解
- 不要行のフィルタリング
- データの抽出
結果として、各タスクの出力がお互いに影響し合い、「辻褄を合わせようとして間違える」という現象が起きました。例えば、ヘッダー行を間違えて特定した結果、それに合わせて構造理解も歪んでしまう、といった具合です。
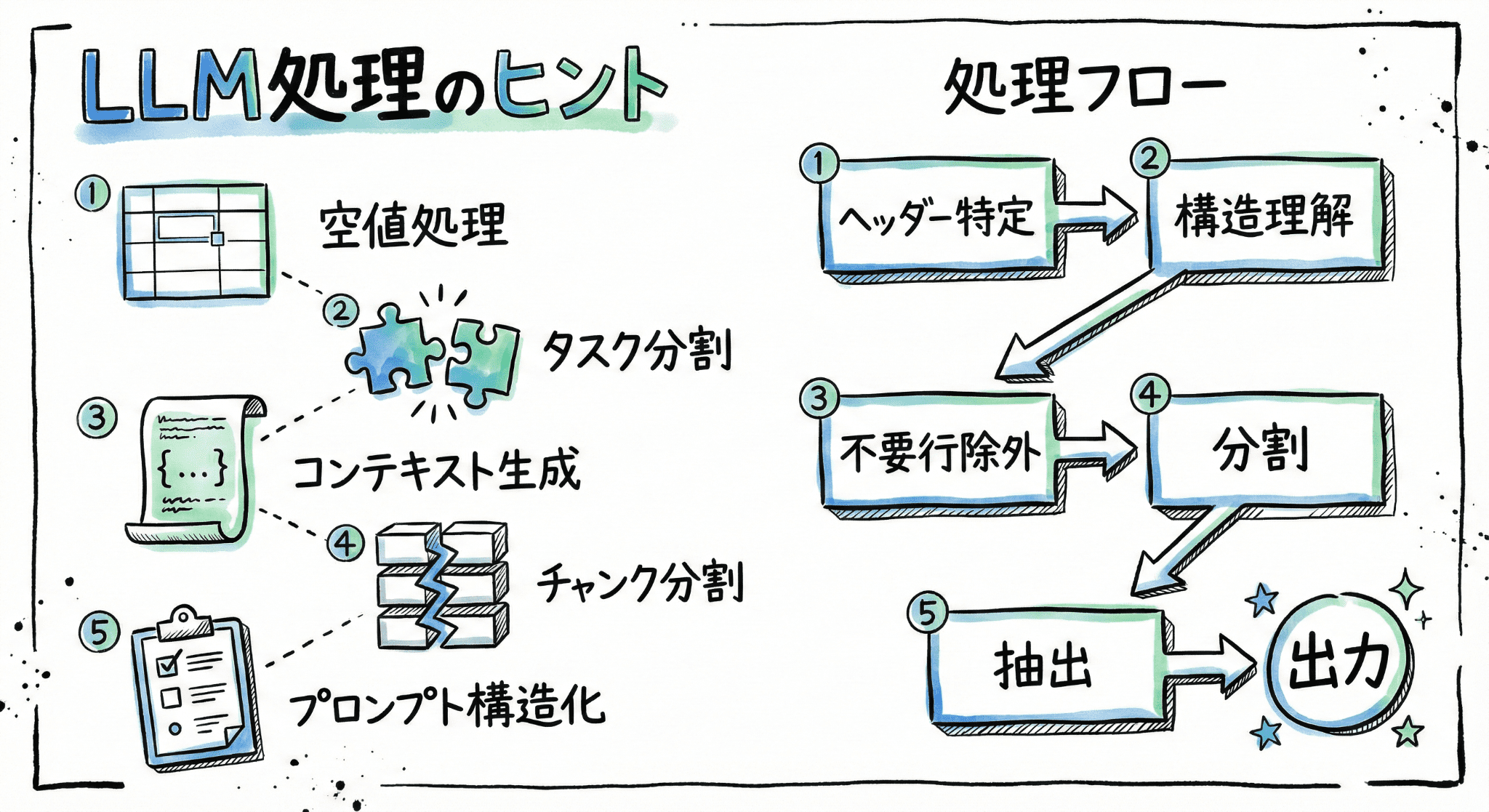
解決策として、処理を5つのステップに分割しました。
- ヘッダーとデータ開始行の特定
- 構造理解・コンテキスト情報の生成
- 不要行のフィルタリング
- チャンク分割
- メイン処理(データ抽出)
各ステップで一つのことだけに集中させることで、出力の品質が安定しました。
Tips 3: コンテキスト情報を中間生成物として持つ
ステップ2で生成した「コンテキスト情報」は、後続の処理で共通して使われます。これは「このExcelはこういう構造で、この列にはこういう意味がある」といったメタ情報です。
このコンテキスト情報をJSON形式で中間生成物として保存し、後続の処理に渡すことで、各チャンクの処理で一貫した解釈が可能になりました。
{
"context": {
"header_row": 5,
"columns": [
{"index": 0, "name": "氏名", "type": "string"},
{"index": 1, "name": "金額", "type": "number"},
// ...
],
"notes": "列Gは合計列のため抽出対象外"
}
}Tips 4: チャンク分割でトークン制限を回避
大きなデータを扱う場合、一度にすべてをLLMに渡すとトークン上限に到達してしまいます。データを適切なサイズに分割し、チャンクごとに処理を実行することで、この制限を回避できます。
分割した各チャンクに対して処理を実行し、最後に結果を統合して出力します。前述のコンテキスト情報を各チャンクに渡すことで、分割しても一貫した解釈が可能になります。
各チャンクの処理は並列実行可能なので、処理時間の短縮にもつながりました。
Tips 5: プロンプトの構造化
プロンプト自体も構造化することで、LLMの理解を助けます。
# タスク
以下のinputデータについて、○○を出力してください。
# inputデータ
(データ)
# 出力形式
JSON形式で以下の要素を含める
- field1: 説明
- field2: 説明
# 注意事項
- 注意点1
- 注意点2
# 手順
1. まず○○を確認
2. 次に○○を実行
3. 最後に○○を出力特に「手順」を明示することで、LLMが段階的に処理を進められるようになり、出力の安定性が上がりました。
検証プロセスについて
今回の検証では、以下のような流れで進めました。
- サンプルデータの収集 – 様々なパターンのExcelファイルを用意
- 正解データの作成 – 各ファイルに対する期待される出力を手作業で作成
- 処理の実行 – 開発した処理を実行
- 結果の比較 – 正解データとの差分を確認
- 改善 – 問題があれば処理やプロンプトを修正
- 回帰テスト – 過去に成功したファイルでも再度確認
この「実行→比較→改善」のサイクルを高速に回すために、比較処理やサマリー出力もコード化しています。
おわりに
今回紹介した、複雑なExcelファイルから必要な情報を自動抽出する仕組みですが、基礎的な検証をクリアし、機能化するめどが立ちました。現在は画面を組み合わせたベータ版のリリースに向けて開発を進めているところです。
本番環境での安定性・精度の向上、コスト最適化など、まだ乗り越えるべき壁はありますが、そのあたりの話はまた別の機会に書ければと思います。
この記事が、LLMを使った機能開発に取り組んでいる方の参考になれば幸いです。
ブログの著者欄
技術広報チーム
GMOインターネットグループ株式会社
イベント活動やSNSを通じ、開発者向けにGMOインターネットグループの製品・サービス情報を発信中
採用情報


関連記事
-

コードレビュー不要論 ーハーネスが人間の目を代替するとき
技術情報
-

第3回GMO大会議・春 サイバーセキュリティ2026を開催!産官学で守り抜く、AI時代のサイバーセキュリティ【イベントレポート後編】
イベント
-

【2025国際ロボット展 出展レポート】AI ❤ ROBOTs で描く、人とロボットが共存する社会
技術情報
-

【協賛レポート】JJUG Cross Community Conference 2025 Fall
技術情報
-

ハーネスで縛れ、AIに任せろ ーAIエージェントの出力品質は“構造”で守る
技術情報
-

【イベントレポート・後編】GMO Developers Day 2025 -Creators Night-|共創するデザイン組織と次世代クリエイターの可能性
デザイン

KEYWORD
CATEGORY
-
技術情報(579)
-
イベント(224)
-
カルチャー(57)
-
デザイン(60)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- Behind the Scenes
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOインターネットグループ陸上部 – GMOロボッツ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMOロボッツ
- GMO大会議
- Go
- Good Morning
- GPU
- GPUクラウド
- GTB
- Hack-1グランプリ
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 技術書典20
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 映像制作
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP






採用情報
SNS FOLLOW
