
こんにちは、GMOインターネットでサーバインフラを担当している小島です。今回は弊社で採用しているNFSを用いたクラスタシステムで、NFSのI/Oが極端に遅くなるトラブルに対処したときの話をしたいと思います。
目次
はじめに
みなさん、NFS使ってますか?NFSって便利ですよね。どんな時に便利かというと、複数のサーバで一つのファイルシステムを共有する時です。ではなぜこんなことをするのでしょうか。それはサーバの一つが落ちた時でもシステム全体ではサービスを維持する、つまり耐障害性向上のためです。
昨今ではVMのリブートなら20-30秒で上がってきますし、最悪VMが起動しなくてもボリュームを別のVMにアタッチして起動することも簡単にできます。そのため以前に比べると、シングル構成でも耐障害性が上がってきてはいるのは確かです。
一方でクラウドの利用が進み、スケールアップではなくスケールアウトの考え方が浸透し、システム間で共有する一意なデータの置き場所に悩む場面も増えてきたのではないかと思います。
データ共有アーキテクチャの比較
さて、耐障害性向上のため一つのデータ領域を複数のサーバで共有する仕組みには、いくつか種類があります。まずはこれらをおさらいしておきましょう。
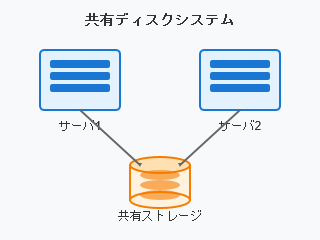
一つのディスク装置(ストレージ)を複数のサーバ機器にSCSI等で接続したシステムです。それぞれのサーバからはストレージをローカルディスクのように扱うことができます。昔から基幹データベースなどに用いられていた構成で、性能も高いですが価格も高くなります。
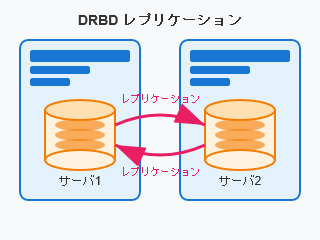
二台のサーバ上のディスクをレプリケーションさせ、仮想的な共有ディスクをソフトウェアで実現する仕組みです。DRBDのソフトウェアそのものは無償で利用できますが、安定した運用を行うには技術が必要だと思います。また、基本的には二台限定の構成になります。
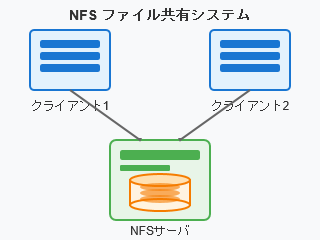
NFSサーバとクライアントによって、ネットワーク越しのファイルシステムをローカルファイルシステムにマウントし、読み書きできるようにするものです。
一つのファイルシステムを複数のクライアントから同時にマウントする、それも2台限定ではなく3台4台・・・と多くのクライアントで共有することも問題なく行えます。
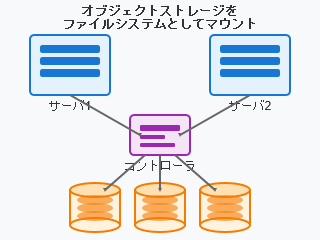
オブジェクトストレージそのものはREST APIを通じてファイルの読み書きをすることが一般的ですが、そのAPI層をラップしてローカルファイルシステムにマウントする(したように見せる)仕組みがあります。s3fs等ストレージ側との通信はあくまでAPIによって行われるため、複数のクライアントで一つのファイルシステムを同時にマウントすることもできますが、I/O性能は著しく低いため汎用ファイルシステムとして利用するのは厳しいでしょう。
読み書きは遅くてもいいから安く大容量のストレージを使いたいといった限定的な用途では役に立つ場面もあると思います。
過去のNFSトラブルとその対処
さてそんな理由で、20年以上前からレンタルサーバーシステムでもNFS上にDocumentRootを置いたwebシステムやNFS上にメールボックスを配置したメールシステムを稼働させてきました。
ケース1 diskのI/O性能不足
まだSSDが普及する前のこと、73GBのSCSI HDDを束ねたストレージでは容量的に限界を迎えており、500GB SATA HDDを数十本搭載したストレージに移行しました。しかしほどなくしてNFSサーバの応答遅延に悩まされることになります。
応答遅延に悩まされたのはメールボックスを置いたNFSサーバの方で、特に多くの人が週末に溜まったメールのチェックを始める月曜の朝が顕著でした。NFSサーバの状況を見ると数十本のHDDのそれぞれのI/O waitが100%に張り付き、キャッシュヒット率も低迷している状態です。我々のメールサービスではメール1通が1ファイルとなるMaildir形式を採用しており、何千何万というファイルに対する読み込み要求が殺到します。HDDは磁気ヘッドがプラッタ上のデータがある場所を探しに行くという構造上、このようなランダムアクセスにはどうしても弱くなります。
この時はメモリを追加して読み込みキャッシュを拡張し、キャッシュヒット率を改善させてHDDへのアクセスが極力発生しないようにしました。
ケース2 ネットワーク輻輳
上記のケース改善後しばらくの間、順調にサービスも拡大しNFSサーバとweb/メールサーバの台数も増え続けていました。当時のシステムではサーバ用ラックとNFS用(ストレージ用)ラックを分け、それぞれに増設を行っている状態でした。
そんなある日、急にNFSの応答性能が遅延する事態になりました。この時はNFSサーバ側も負荷は上がっておらず余裕がある状態で、NFSサーバ側から見ると受け取った要求には迅速に応答している状態。しかしマウントしているサーバ側から見ると応答が遅延している状態でした。この時はサーバ用ラックとストレージラックを結ぶネットワークの帯域が限界に達していたのが原因でした。
これ以降、NFSサーバとそれをマウントするサーバは基本的に同一ラック同一スイッチに接続する方針に改めました。
直近の問題と対応
このように紆余曲折ありながらも長年運用してきたシステムを、この度リプレースすることになりました。
これまでの経験を活かし、NFSサーバのdiskは全てSSDかつ十分なキャッシュ用メモリを搭載、NFSサーバとそれをマウントするサーバは同じスイッチに接続しNWの遅延は起こらない、なおかつサーバスペックも上がりOSやその他ソフトウェアのバージョンも上がり、NFSも最新のv4.2になる。
このように割と自信を持って構築し、事前の性能検証も問題なくいざ本番となったのですが、稼働後1~数時間で極端にI/O性能が劣化するというトラブルに見舞われました。再マウントやリブートで一旦は復旧するものの、しばらく時間を置くと不定期に発生し、一度発生してしまうと再マウントやリブートするまで直らないという状態です。
その時のNFSサーバとの間の通信をモニタすると、以下のような状態でした。
延々とTEST_STATEIDのリクエストを投げています。
25 0.441018 172.16.XXX.YYY → 172.16.XXX.ZZZ NFS 218 V4 Call TEST_STATEID
26 0.441090 172.16.XXX.ZZZ → 172.16.XXX.YYY NFS 166 V4 Reply (Call In 25) TEST_STATEID
27 0.481149 172.16.XXX.YYY → 172.16.XXX.ZZZ NFS 218 V4 Call TEST_STATEID
28 0.481220 172.16.XXX.ZZZ → 172.16.XXX.YYY NFS 166 V4 Reply (Call In 27) TEST_STATEID
29 0.520711 172.16.XXX.YYY → 172.16.XXX.ZZZ NFS 218 V4 Call TEST_STATEID
30 0.520914 172.16.XXX.ZZZ → 172.16.XXX.YYY NFS 166 V4 Reply (Call In 29) TEST_STATEID通常NFS上のファイルを読み込むときは以下のようになるはずです。
GETATTR,OPEN,READ,CLOSEという基本的な流れですね。
57 72.276233415 172.16.XXX.YYY → 172.16.XXX.ZZZ NFS 250 V4 Call GETATTR FH: 0xe91f0f38
58 72.276513199 172.16.XXX.ZZZ → 172.16.XXX.YYY NFS 310 V4 Reply (Call In 57) GETATTR
59 72.276531322 172.16.XXX.YYY → 172.16.XXX.ZZZ TCP 66 809 → 2049 [ACK] Seq=1229 Ack=1961 Win=7613 Len=0 TSval=364771848 TSecr=1008280430
60 72.276621742 172.16.XXX.YYY → 172.16.XXX.ZZZ NFS 330 V4 Call OPEN DH: 0x22d71008/
61 72.276730044 172.16.XXX.ZZZ → 172.16.XXX.YYY NFS 422 V4 Reply (Call In 60) OPEN StateID: 0xe470
62 72.276817378 172.16.XXX.YYY → 172.16.XXX.ZZZ NFS 278 V4 Call READ StateID: 0x5324 Offset: 0 Len: 4096
63 72.276973612 172.16.XXX.ZZZ → 172.16.XXX.YYY NFS 186 V4 Reply (Call In 62) READ
64 72.277031738 172.16.XXX.YYY → 172.16.XXX.ZZZ NFS 270 V4 Call CLOSE StateID: 0xe470
65 72.277095753 172.16.XXX.ZZZ → 172.16.XXX.YYY NFS 182 V4 Reply (Call In 64) CLOSEさて、なぜこのような状態になったのか。結論から言うとNFSv4.2ではデフォルトで有効になっているdelegation機能が原因と考えられます。
delegation機能が有効になっているとNFSクライアントは対象ファイルに対して一定時間NFSサーバと通信することなくファイルに対する操作を行えます。そして同じファイルをマウントしている他のクライアントが対象ファイルへの要求をNFSサーバに送信すると、 NFSサーバはdelegationを許可していたクライアントに権限移譲の返却を求めます。またクライアントは手元の情報とサーバ側の情報の間に不整合が出ないよう、NFS通信に問題があったときはtest_stateidを送って確認を行います。
しかしこのtest_stateidばかりを延々送り続けるのは、クライアントから見てサーバ側でのファイル変更(他のNFSクライアントからの変更)によって手元の情報との乖離が発生し、同期をうまく取り直せない、取り直すのに時間がかかる状態だったと思われます。
対応としてはdelegationの無効化を行いました。まずオンラインで変更するには以下のようにします。
echo 0 > /proc/sys/fs/leases-enableまたNFSサーバの再起動時にも反映されるよう、/etc/sysctl.confに以下の記述を追加しました。
fs.leases-enable=0まとめ
この設定が効いたのか、それ以降は大きな問題は発生していません。delegationは同時にアクセスするNFSクライアントが一つだけの構成ならば性能面で大きな助けになるでしょう。しかし複数のNFSクライアントから一つのファイルシステムを読み書きする構成、それも細かな大量のファイルに読み書きが発生する用途には不向きと言えます。
このdelegation機能、NFSv4.0の頃はNFSサーバからNFSクライアントに向けて、2049とは別のポートで接続を行っていました。NFSクライアント側では明示的に許可したポートの接続しか受け付けていないので、リプレース前のシステムでは意識せずdelegationが機能しなくなっていたためこの問題が発生しなかったと思われます。
NFSv4.0からv4.2差分としては機能が増えたわけでもなく、デフォルトで有効・無効が変更されたわけでもなく、元々別ポートで動いていた機能のポートの統合というあまり意識しない変更によって思わぬ影響が出た事例となりました。
ブログの著者欄
小島 慶一
GMOインターネットグループ株式会社
2002年GMOインターネットグループ株式会社入社。 interQ、bekkoame等のホスティング商材の運用から、お名前.comレンタルサーバSDの開発、z.com webhostingを開発を担当。 最近はConoHa WING,お名前RSの開発運用の傍ら、グループのホスティング商材全般と関わりを深めたいと思っている。
採用情報

関連記事







KEYWORD
CATEGORY
-
技術情報(594)
-
イベント(237)
-
カルチャー(60)
-
デザイン(70)
TAG
- 5G
- AI
- AI TALK
- AI 機械学習強化学習
- AI/機械学習
- AIエージェント
- AIコーディング
- AI人財
- AI駆動
- Behind the Scenes
- BIT VALLEY
- blockchain
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CNDO
- CNDT
- CODE BLUE
- ConoHa
- ConoHa VPS
- CSS
- CTF
- Designship
- developer
- DevRel
- DevSecOpsThon
- Docker
- DTF
- Engineering Journey
- expert
- EXPERT CROSS
- GMO AI&ロボティクス商事
- GMO AIR
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティ byイエラエ
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMO大会議
- GMO天秤AI
- Go
- Good Morning
- GPUクラウド
- GTB
- Hack-1グランプリ
- iOS
- IoT
- ISUCON
- Japan Drone
- JapanDrone
- Java
- JJUG
- K8s
- Kaigi on Rails
- Kids VALLEY
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- OpenStack
- Perl
- PHP
- PHPcon
- PHPerKaigi
- Python
- RPA
- Ruby
- SECCON
- Selenium
- Spectrum Tokyo Meetup
- splunk
- SRE
- Takumi byGMO
- Terraform
- TypeScript
- UI/UX
- vibe
- VPN
- VS Code
- XSS
- ZTNA
- アドベントカレンダー
- インターンシップ
- インハウス
- お名前.com
- クリエイターインタビュー
- クリエイティブ
- コンテナ
- サイバーセキュリティ
- サマーインターン
- スクラム
- スペシャリスト
- セキュリティ
- ソフトウェアサプライチェーン
- チームビルディング
- デザイン
- ネットのセキュリティもGMO
- ハーネスエンジニアリング
- バックエンド
- ヒューマノイド
- ヒューマノイドロボット
- プログラミング教育
- ブロックチェーン
- フロントエンド
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 国際ロボット展
- 基礎
- 多拠点開発
- 宮崎オフィス
- 応用
- 技育プロジェクト
- 技術広報
- 技術書典
- 新卒
- 新卒研修
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 機械学習
- 決済
- 生成AI
- 脆弱性診断
- 開発者
PICKUP
-

デザインカンファレンス「Yoitoi Summit 2026」をGMOYours・フクラスにて開催!
デザイン
-

攻撃者優位の時代に問われる「使命感」 GMO Flatt Security&GMOサイバーセキュリティ byイエラエが描く、AI時代のセキュリティ構想(後編)ーEngineering Journey
技術情報
-

頂上と裾野の両方から「底上げ」 GMO Flatt Security&GMO サイバーセキュリティ byイエラエが支える、日本のサイバーセキュリティ(前編)ーEngineering Journey
技術情報
-

【開催レポート】八幡小学校 社会科見学 at GMO kitaQ
カルチャー
-

デザインコンテスト「GMO DESIGN AWARD 2026」開催決定!3年目のテーマは「トキメキ」
デザイン
-

ソフトウェアサプライチェーン攻撃から「エンジニアの背中」を守る。Takumi byGMO・「Guard」機能「Runner」機能 開発の舞台裏ーEngineering Journey
技術情報
採用情報

SNS FOLLOW
