
この記事は GMOインターネットグループ Advent Calendar 2025 16日目の記事です。
こんにちは。
GMOインターネット / GMOインターネットグループ エキスパートの石丸です。
2025年8月にOpenAIがオープンウェイト言語モデルの gpt-oss-120b と gpt-oss-20b をリリースし、大きな話題となりました。
本記事では、Mac Studio(M3 Ultra / 96GBメモリ)上で LM Studio を利用して gpt-oss を動かした手順と、実際の推論速度や使用感を紹介します。
目次
ローカルLLMとは
ローカルLLMは、ChatGPT などのクラウド型のLLMサービスとは異なり、手元の端末などのローカル環境で動作する LLM(大規模言語モデル)です。
ローカルLLMは以下のような特徴があります。
- データを外部サーバーに送信しないため、機密情報を扱う用途でも利用しやすい
- APIの従量課金に依存しない
- モデルをダウンロードしておけばオフライン環境でも利用可能
- モデルの選択やパラメータ調整の自由度が高い
ローカルLLMとして利用できるモデルは多数ありますが、今回はOpenAIが公開した gpt-oss を動かしてみます。
gpt-ossとは
gpt-ossは、OpenAIが公開したオープンウェイトの言語モデルです。
Apache 2.0 ライセンスの下で利用可能で、以下の2つのモデルが提供されています。
| モデル | 総パラメータ数 | アクティブパラメータ | 性能目安 |
| gpt-oss-20b | 21B | 3.6B | o3-mini相当 |
| gpt-oss-120b | 117B | 5.1B | o4-mini相当 |
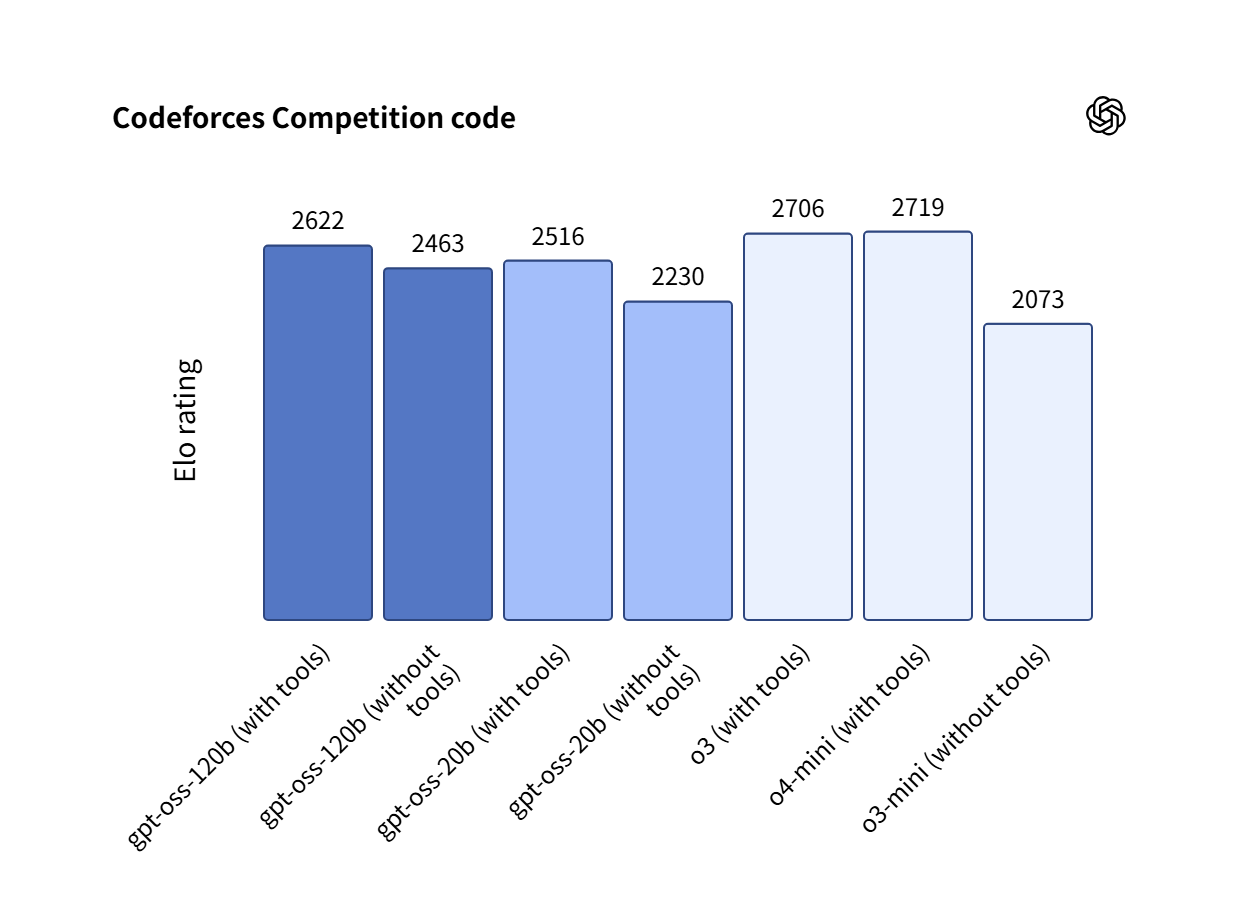
性能評価としては、gpt-oss-120b では競技コーディング(Codeforces)ではOpenAI o3‑mini を上回り、OpenAI o4-mini に匹敵または上回ると報告されています。
gpt-oss-20b は、軽量ながら OpenAI o3‑mini に匹敵または上回る性能と紹介されています。
検証環境
今回検証した環境は以下の通りです。
- マシン:Mac Studio(2025)
- SoC:Apple M3 Ultra
- メモリ:96GB Unified Memory
- ストレージ:1TB SSD
- OS:macOS Sequoia 15.7.2
- ツール: LM Studio 0.3.33
Mac Studio(M3 Ultra)の特徴
ローカルLLMを動かす上で、Mac Studio M3 Ultra には以下の特徴があります。
- 819GB/sの高速なメモリ帯域幅により、大規模モデルの推論がスムーズに行える。
- Unified Memoryアーキテクチャにより、CPUとGPUがメモリを共有するため、GPUメモリの制約を受けにくい。
- メモリ96GBモデルはカスタマイズ不要で購入可能で、Macのため複雑なセットアップも必要ありません。
Mac Studio(M3 Ultra)は最小構成でも60万円を超えますが、VRAM 容量やメモリ帯域幅、自作マシンで同等環境を構築する手間を考えると、コストパフォーマンスに優れたマシンだと考えています。
LM Studio
LM Studioは、ローカル環境でLLMを簡単に実行できるアプリケーションです。
GUIで操作が可能で、モデルの検索やダウンロードも直感的に操作することができます。
チャットUIも標準で実装されているため、モデルとの対話や性能の確認をすぐに試すことができます。
セットアップ
まずは LM Studio をインストールします。
LM Studio – Local AI on your computer
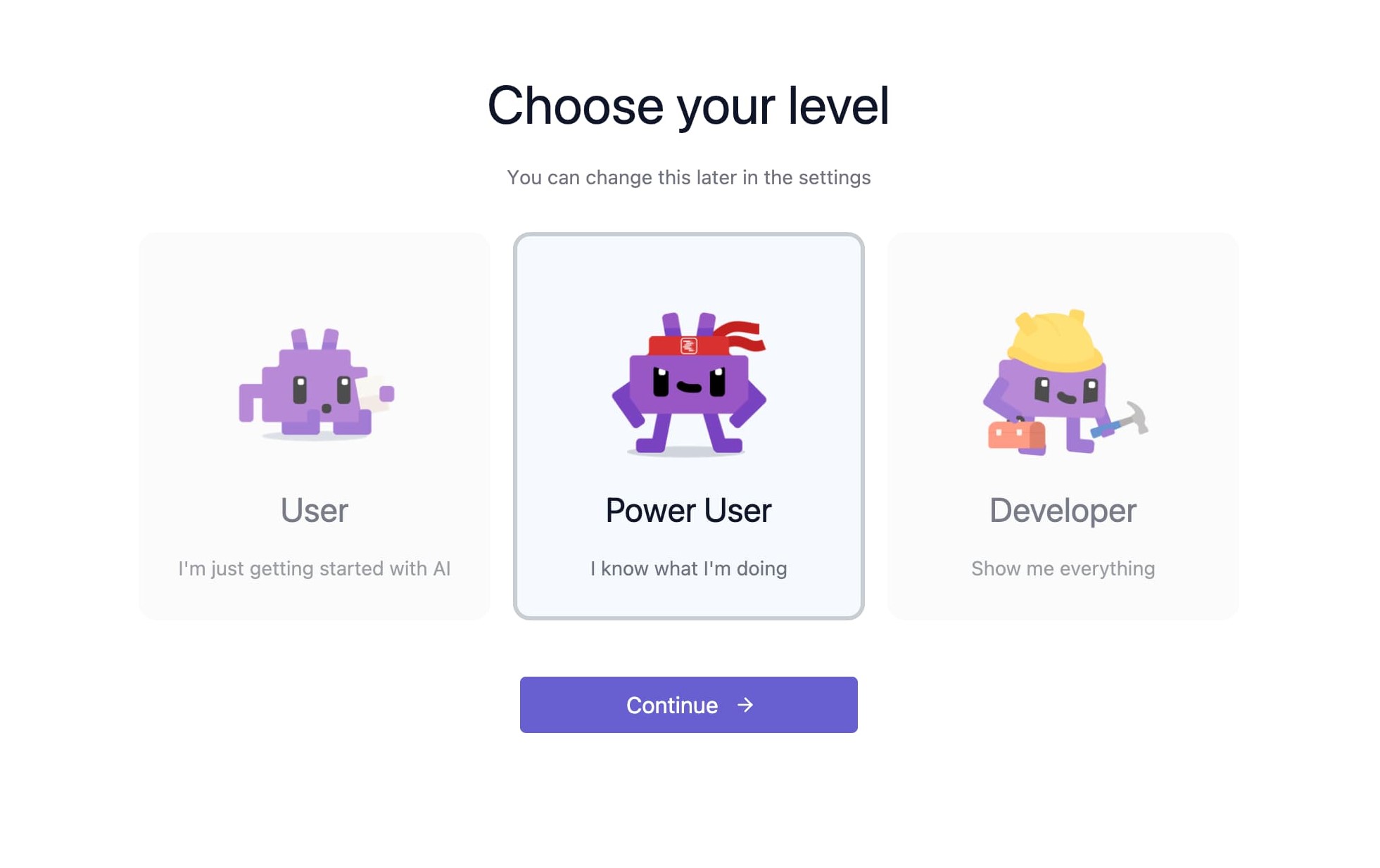
アプリを起動し画面を進めると、「Choose your level」の選択が表示されます。
この選択によってLM StudioのUIがカスタマイズされ、User -> Power User -> Developer の順で設定の自由度が高くなります。
今回は初回の動作確認で、最低限のパラメータを確認できればよいので「Power User」を選択します。
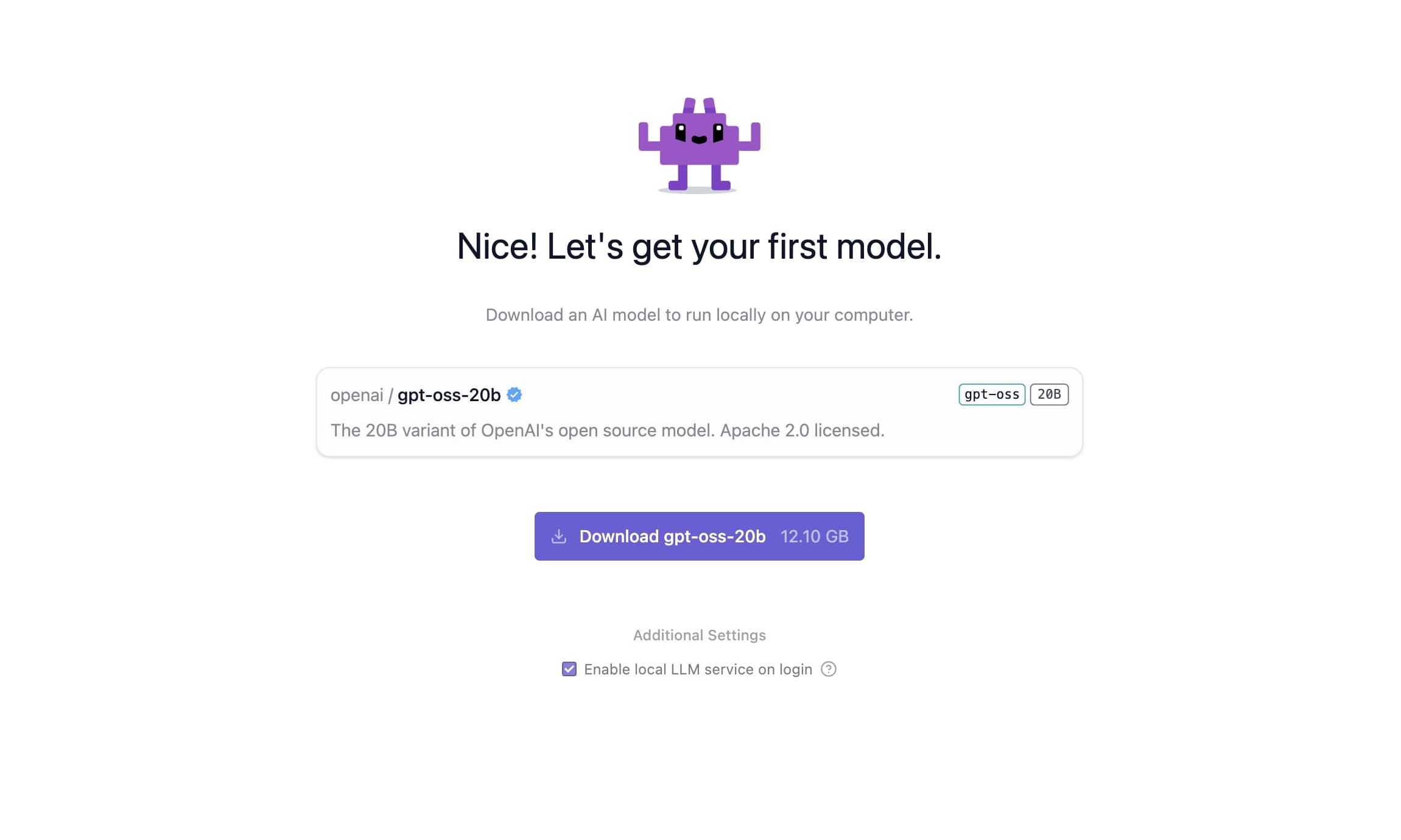
「first model」としてgpt-oss-20bのダウンロード画面が表示されます。
今回検証したいモデルなので早速ダウンロードします。
容量が 12.10GB あるので、ダウンロードの環境にはご注意ください。
セットアップが完了するとチャットUIの画面が表示されます。
画面上部の「Select a model to load」からダウンロード済みのモデルを選択することが可能です。
モデルのダウンロード
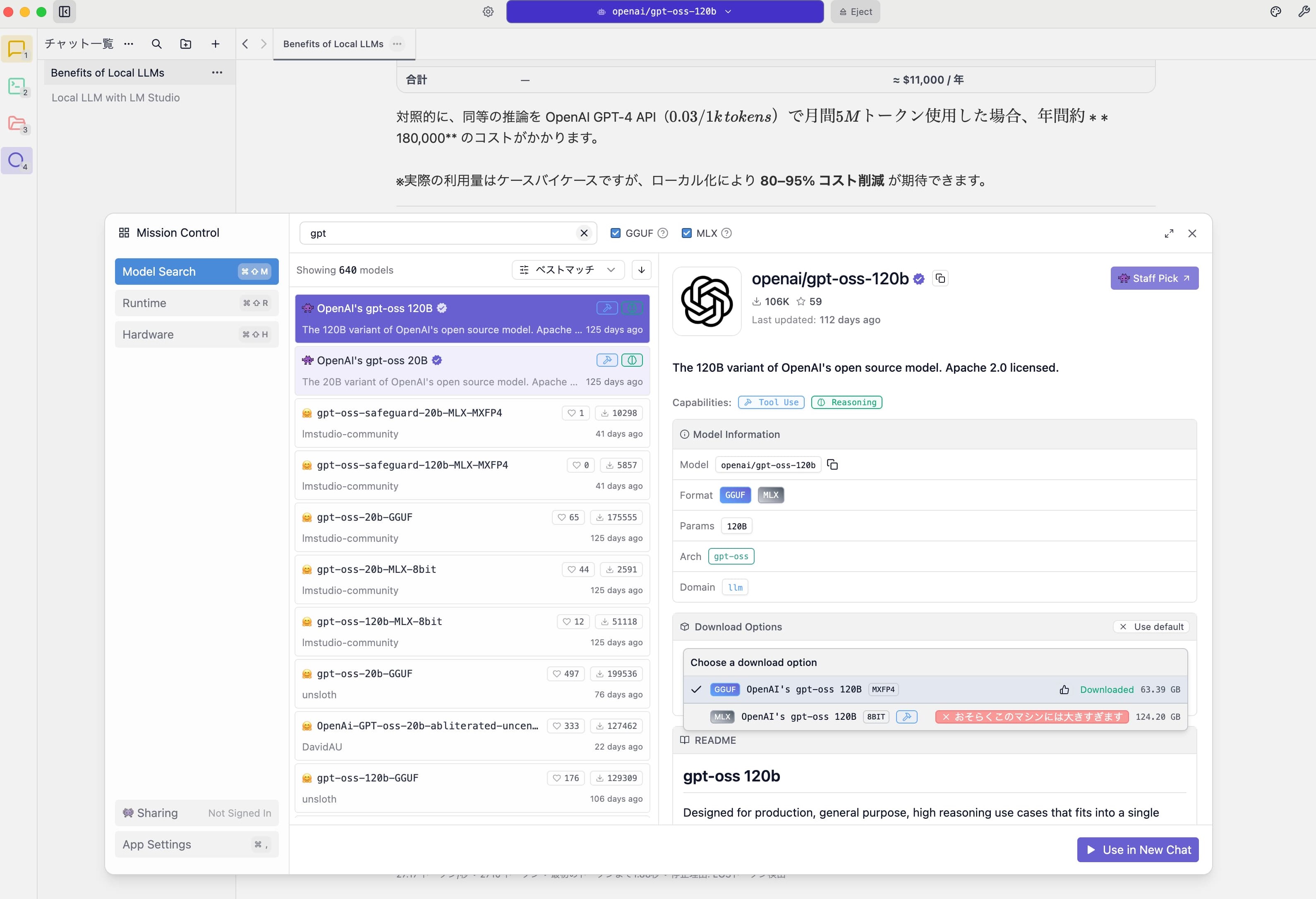
画面左の紫の虫眼鏡アイコンからモデルのダウンロードが可能です。
追加でgpt-oss-120bをダウンロードしてみます。
執筆時点では2つのオプションが用意されていましたが、今回はメモリ96GBの環境なので、GGUF / MXFP4 形式(4bit量子化)の 63.39GB のオプションを選択しました。
ハードウェア情報の確認
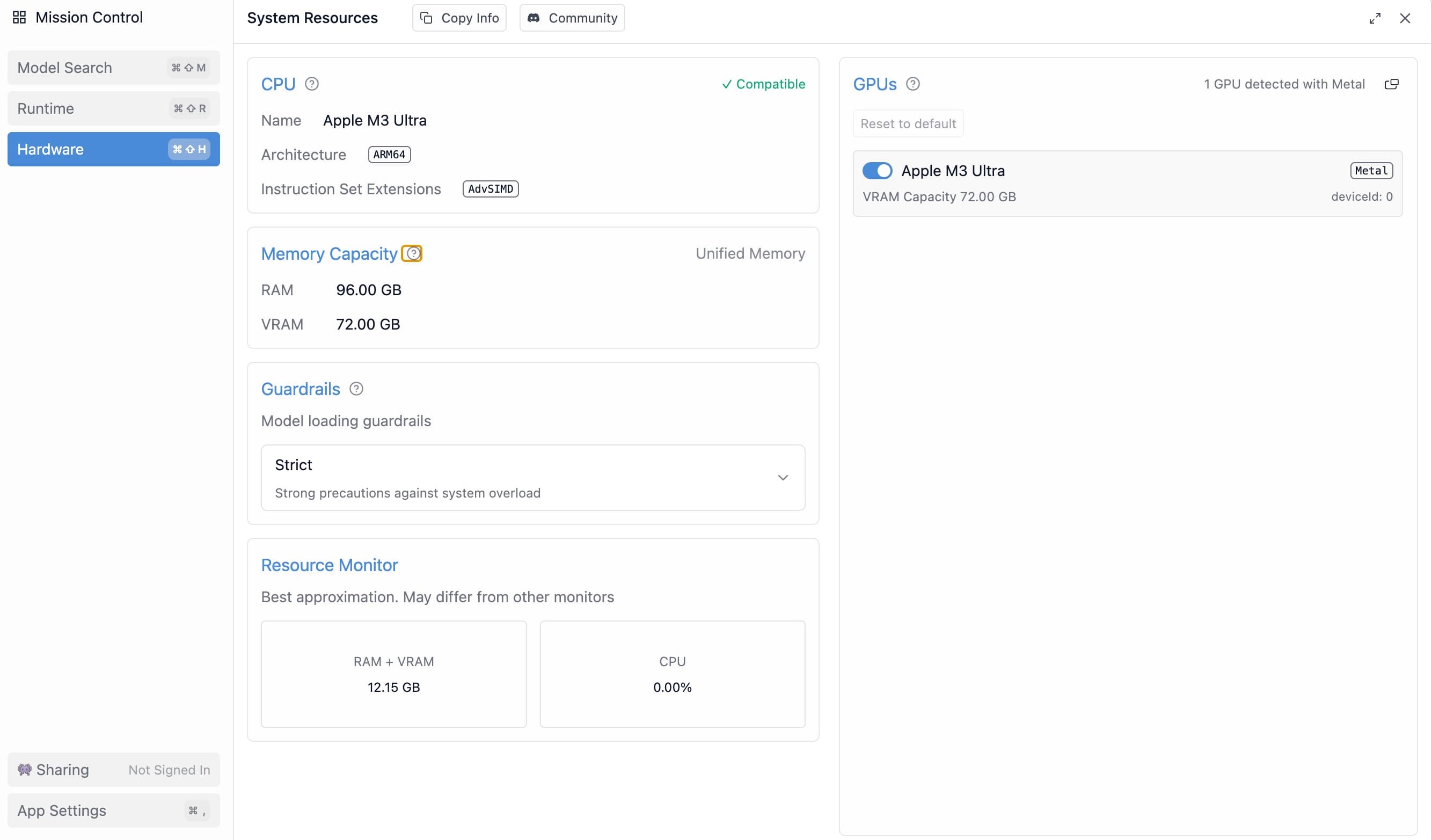
Mission Controlの「Hardware」からハードウェア情報を確認することが可能です。
今回検証した 96GBメモリの Mac Studio(M3 Ultra) では、LM Studio 上で VRAM Capacity が 72.00 GB と表示されました。
Apple Silicon の Unified Memory は CPU/GPU でメモリを共有するため、この値はGPUが利用可能なメモリ容量の目安として理解するとよさそうです。
gpt-ossの動作確認
gpt-oss-20b
まずは gpt-oss-20b の動作を確認してみます。
LM Studio には標準でチャットUIが用意されているため、ChatGPT と同じ感覚でプロンプトを入力し、レスポンス速度や生成の品質を確認することが可能です。
筆者の環境で検証したところ、実行時の推論速度は 約 115 tok / sec で、体感ではChatGPTのInstantモードより高速に感じました。
gpt-oss-120b
続いて、より大規模なモデルの gpt-oss-120b の動作も確認してみました。
今回使用したのは GGUF / MXFP4(4bit量子化) モデルで、メモリ 96GB の環境で問題なく読み込みが可能でした。
推論速度はおよそ 25 tok / sec で、ChatGPTのThinkingモードよりやや遅いものの、実用的な速度で返答が返ってきました。
macOS での gpt-oss-120b の検証記事はメモリ128GB以上の環境が多いため、メモリ96GBでも問題なく動作を確認できたのはいい発見でした。
なお、LM Studio の設定ではデフォルトでコンテキスト長 4096 トークンが設定されていました。
gpt-oss-120b 自体は最大 128k tokens のコンテキスト長に対応していますが、ロード設定の値が小さい場合、複数ターンの会話でコンテキスト上限に達し、以下のようなエラーが発生するケースがありました。

※日本語訳
メッセージの送信に失敗しました
コンテキスト長が4096トークンに到達しましたが、このモデルはアーキテクチャが gpt-oss のため、生成途中のコンテキストあふれ(mid-generation context overflow)には現在対応していません。
より大きいコンテキスト長で読み込み直すか、プロンプト/チャットを短くしてみてください。
まとめ
今回は Mac Studio M3 Ultra(96GBメモリ)の環境で、LM Studio 経由で gpt-oss を動かす方法や各モデルの推論速度について紹介しました。
LM Studio はローカル環境で手軽にLLMを実行できるため、モデルを事前にダウンロードしておけばオフライン環境でも利用できる点がメリットです。
加えて、LM Studio には OpenAI 互換の API サーバー機能も用意されています。
OpenAI Compatibility Endpoints | LM Studio Docs
既存の OpenAI クライアントは base_url を切り替えるだけで接続でき、アプリケーションやスクリプトなどからも手軽にローカルLLMを呼び出すことができます。
外部に送信したくないデータの処理や、従量課金に依存しない形でLLMを利用したい場合に活用できそうですね。
今回の記事はセットアップや動かしてみての所感の紹介が中心となりましたが、次回は LM Studio の APIサーバー機能や、LM Studio 以外のツールでの動作方法、各パラメータのチューニングなどについても紹介できればと思います。
ブログの著者欄
技術広報チーム
GMOインターネットグループ株式会社
イベント活動やSNSを通じ、開発者向けにGMOインターネットグループの製品・サービス情報を発信中
採用情報


関連記事







KEYWORD
CATEGORY
-
技術情報(590)
-
イベント(233)
-
カルチャー(59)
-
デザイン(67)
TAG
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI TALK
- AI 機械学習強化学習
- AI/機械学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI活用事例
- AI駆動
- AMD
- APT攻撃
- AWX
- Behind the Scenes
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- ConoHaVPS
- CS
- CSS
- CTF
- DC
- Designship
- Desiner
- developer
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- engineering
- Engineering Journey
- eVTOL
- expert
- EXPERT CROSS
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOインターネットグループ陸上部 – GMOロボッツ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- Good Morning
- GPU
- GPUクラウド
- GTB
- Hack-1グランプリ
- Hack‐1グランプリ
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- Japan Drone
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- エージェンティックAI
- オブジェクト指向
- オンボーディング
- お名前.com
- クリエイター
- クリエイターインタビュー
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ハーネスエンジニアリング
- バックエンド
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- フロントエンド
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- ロボティクス
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 技術書典20
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 映像制作
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 空飛ぶクルマ
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP
-

【後編】デザイナーとしての自分を形作る「気合と反復」。対話を通じて実践する、豊田恵二郎の制作哲学
デザイン
-

【前編】創業時から変わらない「一貫性」で業界をリード GMO Flatt Security CCO・豊田恵二郎が語る、「エンジニアの背中を預かる」姿勢
デザイン
-

【第2回・AI TALK】GMOサイバーセキュリティ byイエラエ・三村 聡志さんに聞く、AI時代の攻撃と防御のいま
技術情報
-

【中編】Hack-1グランプリ2026 デモデーレポート|ついにグランプリ決定!最優秀賞チームに開発秘話を聞く
デザイン
-

【前編】Hack-1グランプリ2026 デモデーレポート|AI時代の学生ハッカソンに圧倒される2日間。「小さくなる日本」をどう表現する?
デザイン
-

【Expert Cross #1】“人生2周目”のエキスパートが挑む、「つながり」の構築と認知拡大
技術情報
採用情報
SNS FOLLOW
