
RL(強化学習)によるロボティクスの進化は、単なるアルゴリズムの改善にとどまらず、データパイプラインや表現学習、さらにはVLA(Vision-Language-Action)との融合へと広がっています。本記事では、RLパイプラインの全体像を整理しながら、sim-to-realから拡張された6つの代表的アーキテクチャパターンを解説。さらに、蒸留の一般化や潜在空間での汎化、スポーツ領域での応用など、最新トレンドを俯瞰し、今後の方向性を考察します。
目次
はじめに
ここ数年で、ヒューマノイドロボットのハードウェアが急速に実用レベルに近づきました。
Unitree、Fourier、AgiBotなど複数メーカーから開発可能なヒューマノイドが登場し、研究者が手の届く選択肢が一気に広がり、sim-to-real(シミュレーションで訓練した学習データを実機に移行する)パイプラインが現実的な選択肢になっています。
加えて、ヒューマノイドは人間と骨格が近いため、人間のモーションデータを教師信号として直接活用しやすいという利点があり、模倣ベースの学習パイプラインが急速に発展しています。
現在実用的なヒューマノイドの学習方法は、大きく次の2つに分かれます。
・RL(強化学習)ベース: シミュレーション上でロボットに試行錯誤させ、良い動作を実現した場合に高い報酬を与えるように設計することで、より良い報酬を得られる方法を学習させる手法
・VLA(Vision-Language-Actionモデル)ベース: 事前学習済みの大規模Vision-Language Modelを活用し、言語指示から直接行動を生成する手法
それぞれ長所短所があり、2026年3月現在ではどちらも注目されている技術ではありますが、本記事ではRLベースの学習方法について、そのトレンド・核となる技術や、共通するアーキテクチャについて紹介します。
RLパイプラインの全体像
近年のヒューマノイドRL手法は、以下の3つのレイヤーの組み合わせになっていることがほとんどです。
(手法によって各レイヤーで用いている手法が異なったり、一部レイヤーが無かったりします。)
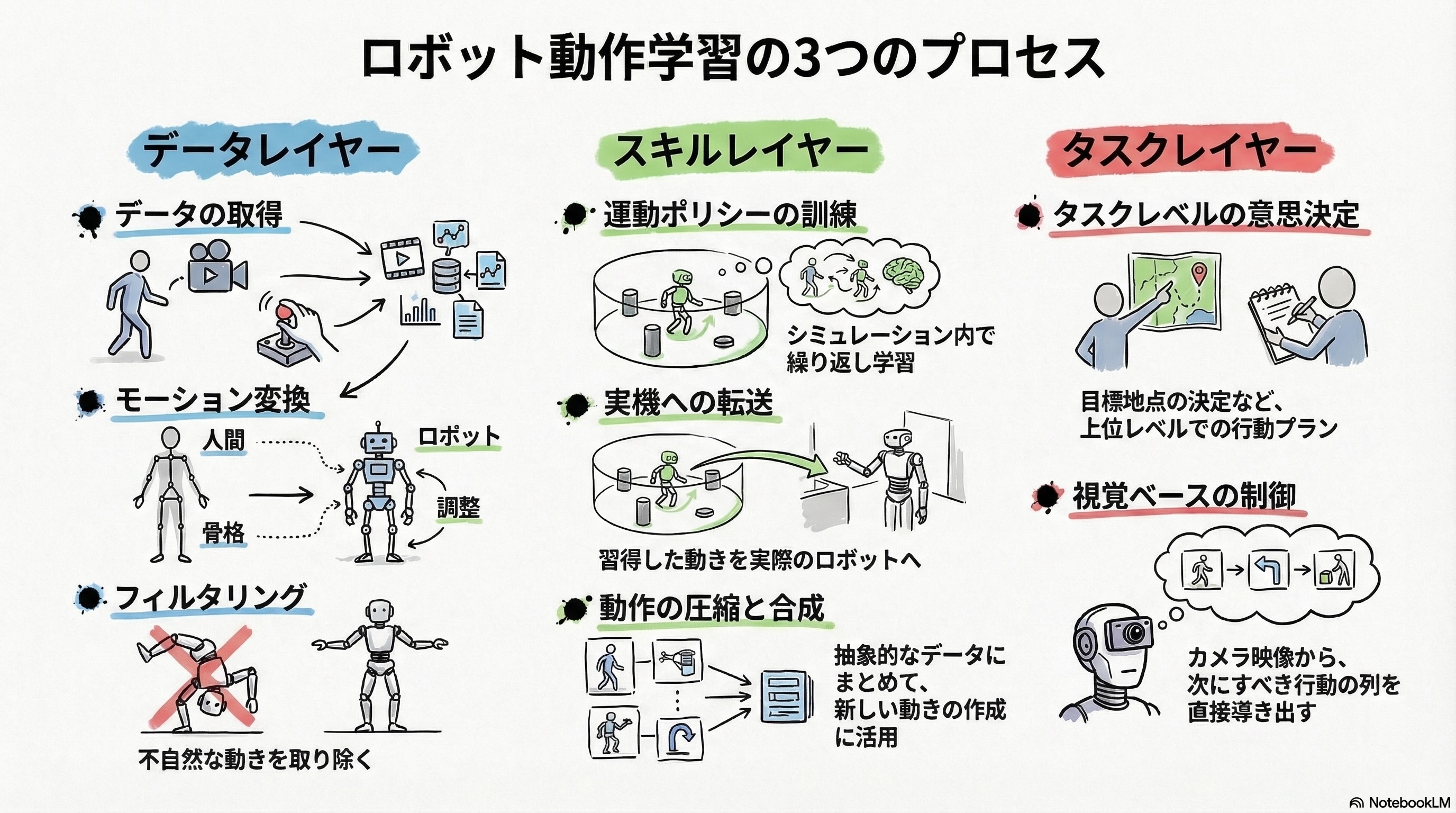
データレイヤーは、訓練データの取得から前処理までを担います。MoCap(モーションキャプチャ)データセットの利用が最も一般的ですが、YouTubeなどの普通の動画から抽出する手法、人間が遠隔操作(テレオペレーション)で動きを教える手法、少数のお手本から自動的に大量のデモを作る手法など、データソースの多様化が進んでいます。取得したデータは、人間の骨格とロボットの骨格の違いを吸収するモーション変換(Retargeting)と、ロボットが物理的に実行できないモーションを除外するフィルタリングを経て、スキルレイヤーに渡されます。
スキルレイヤーは、シミュレーション内で運動ポリシーを訓練し実機に転送するまでを担います。変換済みのモーションを追従するポリシーをPPO等で訓練し、多くの手法が敵対的学習やStudentポリシーへの蒸留を組み合わせています。一部の手法はモーションを潜在空間(コンパクトな抽象表現)に圧縮し、新しい動きの合成に活用します。
タスクレイヤーは、スキルレイヤーの上に載るタスクレベルの意思決定層です。階層的RLでは「どこにボールを打つか」を決めるプランナー、視覚ベースの制御ではカメラ入力から直接行動列を出力するDiffusion Policyがここのコアを握ります。単純なモーション追従のみの手法ではこのレイヤーは多くの場合必要ありません。
本記事では、近年注目を集めた手法が各レイヤーにどんな技術を取り込んでいるのか、どんな風に進化してきたのかを概説し、トレンドとなる強化学習関連技術を抑えていきます。
タスク達成のためのアーキテクチャの分類
これまで提案されてきた代表的な手法を、「主にどのレイヤーに革新的な要素を持つか」と、「全体の構造的な複雑さ」に着目すると大きく以下の6つの構成パターンに整理できます。
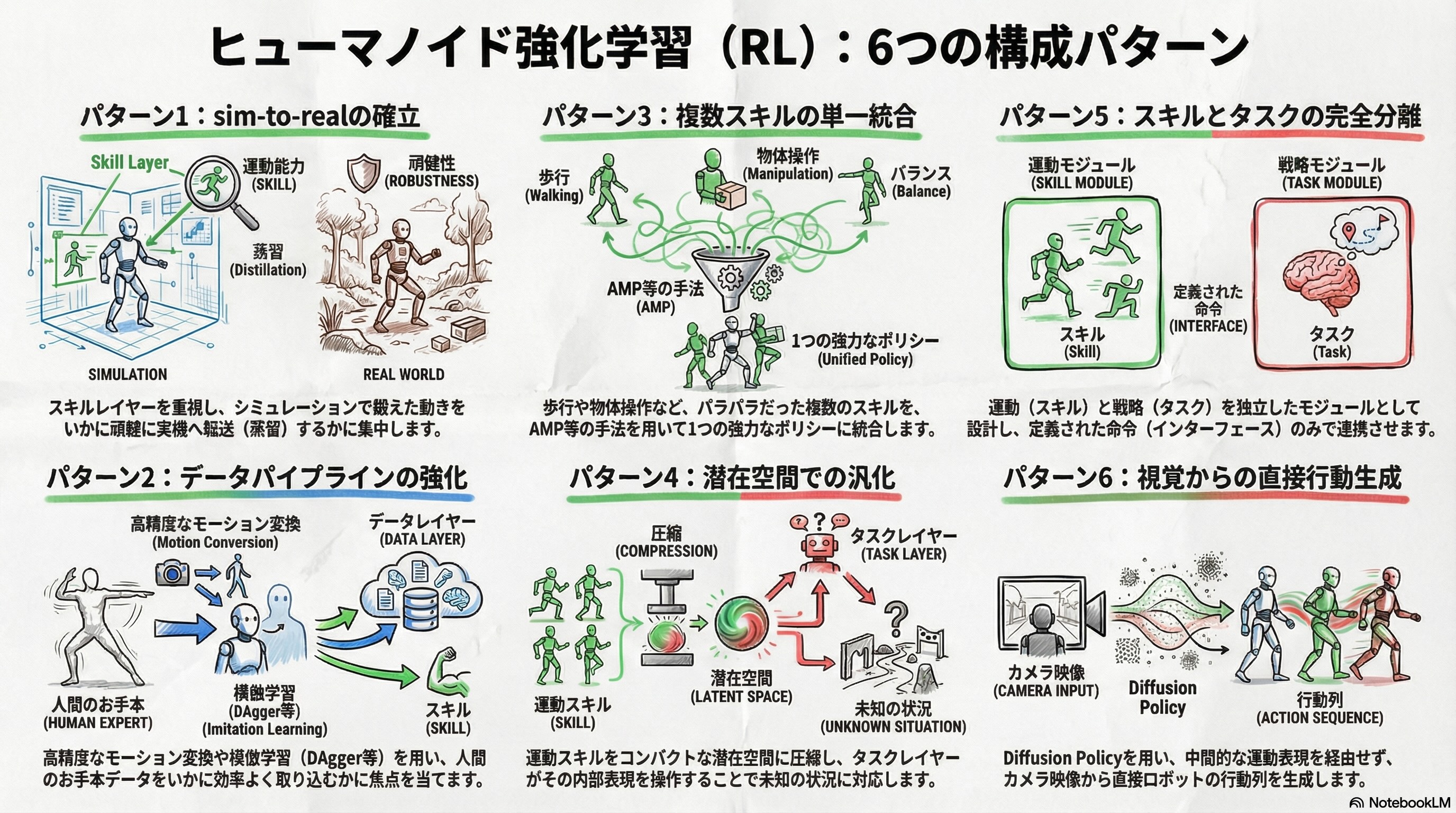
ここではパイプラインのどこの改善に焦点を当てるか、という設計上の分類を示していますので、これは厳密な手法の発展の時系列とは異なります。
(前半の手法が必ずしも古い手法というわけではありません!)
以下では、この整理した構造の順にパターンを詳しく紹介します。
パターン1: sim-to-realの始まり
ヒューマノイドRLの出発点であり、スキルレイヤーの工夫が主戦場です。データレイヤー・タスクレイヤーに特段大きな工夫は無く、「シミュレーションでスキルレイヤーを鍛え、いかに頑健に実機へ転送するか」に集中したパターンで、パルクールやロコマニピュレーション(移動しながらの物体操作)など、全身を使ったダイナミックなタスクの実現例が多い構成です。
このパターンの大半で重要になる技術がTeacher-Student学習(蒸留)です。まずシミュレーション内で、地形マップ・物体の正確な位置・接触力など「実機では取得できないが、訓練には便利な情報」(特権情報)を使える教師ポリシーをPPOと呼ばれる標準的な強化学習アルゴリズムで訓練します。次に、この教師の行動を模倣する生徒ポリシーを、実機で使えるセンサ(関節角度・カメラ・深度センサ等)だけで動くように訓練します。
sim-to-realのギャップを埋める、もう一つの定石となるアイデアがDomain Randomization (DR)です。
シミュレーション中に物理パラメータ(質量、摩擦、遅延等)や視覚条件(照明、テクスチャ等)をランダムに変動させ、「どんな環境でも動く」頑健なポリシーを育てます。
代表的な手法の詳細とリンク
・具体的な技術名が記載されているレイヤーが主要な貢献
・○は利用しているが主要な新規性ではないレイヤー
・記載のないレイヤーは非該当/導入していない
- Humanoid Locomotion (Science Robotics 2024)
- WoCoCo (CoRL 2024)
- VIRAL (RSS 2025)
- ASAP (RSS 2025)
- Humanoid Parkour (CoRL 2024)
パターン2: データパイプラインの強化
sim-to-realの転送手法が整備された後、「何を学習させるか」= 訓練データと、その取り込み方に注目が集まりました。
特に、人間の行動をデータ化し、ロボットに学習させる手法は成功例が多く、その後現在に至るまで用いられる、標準的なデータレイヤーの処理が確立されています。
人間の行動を模倣する上では、Motion Retargetingと呼ばれる人間の動作を元に作成した関節データの骨格構造をロボットに合わせて変形する技術も重要となってきます。
単純な関節角マッピングでは足が地面を滑ったり(足滑り)手が物体を貫通したりするため、各手法が独自の工夫を加えています(OmniRetargetのInteraction Mesh、VideoMimicの4D再構成、GBCのDifferentiable IK等)。
また、「どのように人間のデモデータを学習するか」という点も重要で、模倣学習手法であるBehavior Cloning (BC)や、その改良手法であるDAggerといった技術も注目されています。特に近年の流行であるDAggerは「学習者を実際に走らせて、実際に起こった場面で教師に正解を聞き、その経験を訓練データに追加する」という訓練方法で、ミスからの回復を学びやすいという利点があります。ヒューマノイドRL分野では、DAggerはTeacher-Student学習で教師の知識を生徒に蒸留する手段としても広く使われています。
代表的な手法の詳細とリンク
・具体的な技術名が記載されているレイヤーが主要な貢献
・○は利用しているが主要な新規性ではないレイヤー
・記載のないレイヤーは非該当/導入していない
- HumanPlus (CoRL 2024)
- H2O (IROS 2024)
- OmniH2O (CoRL 2024)
- OmniRetarget (ICRA 2026)
- VideoMimic (CoRL 2025)
- GBC (2025)
パターン3: 複数スキルを単一ポリシーに統合
複数のモーションスキルを学習した上で、それらを1つの統合ポリシーにまとめるパターンです。
データレイヤーが整備され個別スキルのポリシーは作れるようになりましたが、歩行用・操作用・全身表現用とスキルレイヤーがスキルごとに分立する問題が浮上しました。
その問題を克服するために、複数モードの専門ポリシーを1つの統合ポリシーに蒸留する手法(HOVER)や統合訓練(ULC)など、歩行・操作・全身表現など多様なモードをシームレスに切り替えられるよう、統合することを目指した手法群がここに属します。
このパターンで報酬設計によく使われるのがAMP(Adversarial Motion Prior)です。AMPは「モーションの自然さ」を自動的に評価する仕組みで、GANの識別器と同じアイデアを使います。「本物の人間のモーションか、ポリシーが作った動きか」を見分ける識別器を訓練し、ポリシーにはこの識別器を騙す方向の報酬を与えます。「腕の角度が何度ずれたら減点」のような細かい報酬を手作業で設計しなくても、全体として自然な動きが学習できます。
代表的な手法の詳細とリンク
・具体的な技術名が記載されているレイヤーが主要な貢献
・○は利用しているが主要な新規性ではないレイヤー
・記載のないレイヤーは非該当/導入していない
- HOVER (ICRA 2025)
- ExBody2 (RSS 2025 Workshop)
パターン4: 潜在空間での汎化
スキルレイヤーで学習済みのスキルを潜在空間(多数の動きを少数の変数で表すコンパクトな表現)に圧縮し、タスクレイヤーがその内部表現に直接介入して見たことのない状態に対応することを目指すパターンです。
例えば、BeyondMimicが採用するClassifier Guidanceという手法は、拡散モデルが段階的にノイズを除去して出力を生成する過程に「こっちに行きたい」という目標の勾配を注入することで、スキルレイヤーのデノイズ結果が目標を達成するように誘導します。
またULTRAが採用するSparse Goalは、訓練済みモデルをさらにRLで追加学習することでスキルレイヤーの潜在空間を目標に引き寄せます。
いずれも、モーション追従を「ゴール」ではなく「運動スキルの土台」として捉え、その上にタスクレイヤーを載せて訓練時に観測しなかった動きへの汎化を狙います。
代表的な手法の詳細とリンク
・具体的な技術名が記載されているレイヤーが主要な貢献
・○は利用しているが主要な新規性ではないレイヤー
・記載のないレイヤーは非該当/導入していない
- BeyondMimic (2025)
パターン5: スキルとタスクの分離
パターン4では、タスクの目標を変えるとスキルレイヤーの潜在空間も作り直しになります。両者を独立モジュールとして設計し、差し替え可能にする構成が次に登場しました。
スキルレイヤーとタスクレイヤーを分けて設計し、定義済みのインターフェース(目標座標や速度指令)だけで通信する手法群がこのパターンに属します。スキルレイヤーにはAMP(パターン3)や模倣学習で動きの自然さを保証し、タスクレイヤーで「どこにボールを打つか」などタスク固有の戦略をRLで最適化します。
パターン4ではタスクレイヤーがスキルレイヤーの内部表現(潜在空間)を知っている必要がありましたが、ここではスキルレイヤーをブラックボックスとして扱い、タスクレイヤーでは、例えば「指示した速度での移動を目指す命令が既にある」といったようにスキルの獲得を前提としてどのようにタスクを処理するかのみを考えます。
このように設計することで、タスクレイヤーは戦略を考えることに専念できます。
特にスポーツ系のタスクにおいては、身体操作と戦略のモデルを切り分けることで、それぞれのモデル設計が簡潔になるというメリットがあり、多く採用されています。
それぞれの手法の工夫は様々で、例えばLATENTは3段構成(動き追従→DAggerで生徒ポリシーに蒸留→戦略ポリシー学習)のパイプラインを持ち、Badminton HumanoidはManifold Expansion(少数の打点データを連続的な打撃空間に拡張する手法)でモーションのバリエーションを増やします。
代表的な手法の詳細とリンク
・具体的な技術名が記載されているレイヤーが主要な貢献
・○は利用しているが主要な新規性ではないレイヤー
・記載のないレイヤーは非該当/導入していない
- Learning Agile Soccer Skills (Science Robotics 2024)
- スキル: Multi-skill RL + Self-play / タスク: Game Strategy
- arXiv
- Project
- 小型ヒューマノイド(OP3)で1対1のサッカーを実現した手法です。歩行・転倒回復・キック・ターンなどの個別スキルをまずRL訓練し、policy distillation(方策蒸留)で単一のマスターポリシーに統合した後、self-play(自己対戦)でゲーム戦略を最適化します。明示的なタスクポリシーを持つ後続のスポーツ手法とは構成が異なりますが、「スキルの獲得」と「戦略の学習」を段階的に行う枠組みを示した先駆的研究です。MuJoCo上で訓練した後、zero-shotで実機に転送しています。
- LATENT (2026)
- Badminton Humanoid (2026)
- データ: ○ / スキル: AMP + Manifold Expansion / タスク: Strike RL
- arXiv
- バドミントンのショットを行う手法。人間データからAMPベースのモーションプライア(自然な動きの事前知識)を構築し、コンパクトな状態表現に蒸留。少数の打点データをManifold Expansionで連続的な打撃空間に拡張してバリエーションを増やし、実機への追加訓練なし(zero-shot)転送でリフト・ドロップショットを実現しました。
パターン6: カメラから行動列を直接生成するDiffusion Policy
最後は(記事執筆時点では)ちょっと特殊な手法です。ここまでのパターンはスキルレイヤーを土台にしてきましたが、このパターンではDiffusionモデルを用いてカメラ入力から直接関節角度の行動列を生成し、スキルレイヤーとタスクレイヤーが一体となる設計を持ちます。
スキルとタスクの連携という意味では、パターン4との違いがわかりにくいかと思いますが、パターン4では、RLで訓練したスキルレイヤーとタスクレイヤーの2つが存在し、後者が前者の「中」を操作する構成でした。一方、パターン6ではこの2つの区別自体がありません。
このパターンではDiffusion Policyがカメラ入力から直接関節角度の行動列を生成し、RLで学んだ運動スキルという中間表現を経由しません。
具体的な実現方法はそれぞれ大きく異なります。
iDP3はスキルレイヤーを持たず完全な一体型となっている一方で、FALCONは移動と操作を別々のDiffusion Policyとして訓練し、VLM(Vision-Language Model)がこれらを協調させる特殊な構成を採用しています(これはVLAではなく、RLパイプラインにVLMを組み込んだ事例です)
またDiffusion Policyはノイズから段階的にデノイズ(ノイズ除去)することで、ひとまとまりの行動列(アクションチャンク)を生成する手法です。通常のガウシアン方策(行動を正規分布の平均として1つだけ出力する方策)が「1つの正解」を出すのに対し、Diffusion Policyは「正解が複数ある状況」でも破綻しないのが強みです。まだヒューマノイド向けの事例は少ないですが、今後の発展に期待したいところです。
代表的な手法の詳細とリンク
・具体的な技術名が記載されているレイヤーが主要な貢献
・○は利用しているが主要な新規性ではないレイヤー
・記載のないレイヤーは非該当/導入していない
- iDP3 (IROS 2025)
傾向と今後のトレンド
最後に、本記事で紹介した手法群を俯瞰してみて、感じた最近の傾向と、これからの注目技術について書いていきたいと思います。
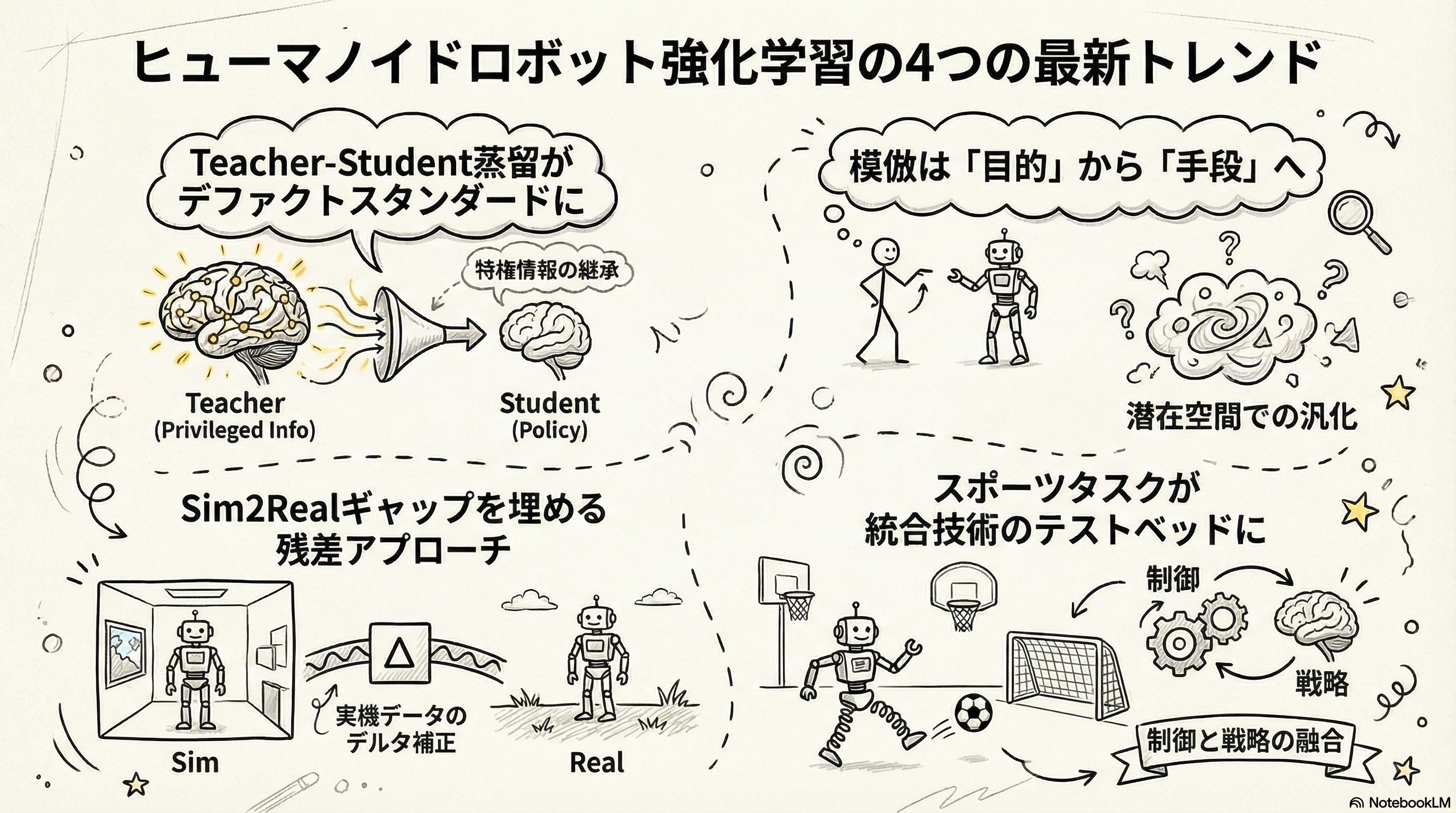
Teacher-Student型の蒸留が普及した
HOVER、VIRAL、OmniH2O、ExBody2、PHCなど、sim-to-realを伴うほぼ全ての手法がTeacher-Student学習を採用しています。シミュレーション内の特権情報で教師を訓練し、実機で使えるセンサだけで動く生徒に蒸留するこの手法は、スキルレイヤーの訓練・転送における設計原則として、パターンを問わず広く共有されています。
模倣は目的から手段になりつつある
初期のヒューマノイドRLは「人間のモーションをいかに正確に再現するか」が中心でしたが、BeyondMimicやULTRAに見られるように、スキルレイヤーで獲得した運動能力を潜在空間に圧縮し、タスクレイヤーが未見の動きへの汎化に活用する流れが生まれています。これはパターン4(潜在空間での汎化)の核心思想であり、「模倣はゴールではなく、スキルレイヤーの土台を作るための手段」という認識が分野全体に浸透しつつあります。
sim-to-realギャップを埋めるのは残差アプローチ
ASAPはsimとrealの動きの差をデルタアクションモデルで学習してシミュレータ側を補正し、RobotDancingやMOSAICはベースポリシーの出力に小さな残差を加算して実機の挙動を補正します。Domain Randomizationだけでは越えられないギャップを、少量の実機データでピンポイントに埋めるアプローチは、シンプルながら痒いところに手が届くノウハウとなるでしょう。
スポーツタスクが統合技術の試験場になってきた
サッカー(Learning Agile Soccer Skills, Science Robotics 2024)に始まり、テニス(LATENT)、バドミントン(Badminton Humanoid)、卓球(HITTER)と、2024〜2026年にかけてスポーツタスクへの応用が急増しました。「動きの自然さ」と「ゲーム戦略」の両方が同時に要求されるため、スキルレイヤーとタスクレイヤーの分離パターン(パターン5)の実践的な検証場として機能しています。
(球技に興味のある・経験のあるエンジニアがsim-to-realを完遂できるようになってきた頃合いが最近というだけの可能性もありますね)
VLAとの融合は?
本記事のスコープ外ですが、WholeBodyVLA(ICLR 2026)は潜在アクションモデルとロコマニピュレーションRLを組み合わせ、言語指示からの全身制御を実現しました。また2026年3月に公開されたΨ₀は、人間の動画で事前学習した視覚-言語基盤モデルに少量の実機データで追加訓練を行うアプローチを採り、オープンソースで公開されています。本記事で紹介したRLベースの運動スキルと、VLAベースの高次意思決定の融合を、誰がどんなクオリティで完成させるか、注目です。
最後に
GMOインターネットグループでは、Unitree社製のヒューマノイドG1を使って実際に学習・開発ができるインターンシップを開催しています!
ヒューマノイドロボット「G1」を使った AI・ROBOTICS INTERNSHIP
ご応募をお待ちしております!

ブログの著者欄
真次彰平
GMOインターネットグループ株式会社 グループ研究開発本部 AI研究開発室
GMOインターネットグループにてエキスパートとして活動中。 巡回ロボットを用いた新規物体検出、およびヒューマノイドにおける強化学習を用いたモーションの獲得に関する研究に従事しております。
採用情報

関連記事
-

【EXPERT CROSS #2】暗号技術の可能性を未来につなぐ、「暗号のおねぇさん」の歩み(後編)
技術情報
-

【EXPERT CROSS #2】「暗号のおねぇさん」が国際標準化の場で残していく、インターネットへの「爪痕」(前編)
技術情報
-

【第2回・AI TALK】GMOサイバーセキュリティ byイエラエ・三村 聡志さんに聞く、AI時代の攻撃と防御のいま
技術情報
-

【Expert Cross #1】“人生2周目”のエキスパートが挑む、「つながり」の構築と認知拡大
技術情報
-

【第1回・AI TALK】SUZURI・minne事業部CTO 黒瀧さんに聞く、AI活用の現在地と未来
技術情報
-

SUZURI APIを使ってSUZURI MCP Serverを作った話
技術情報

KEYWORD
CATEGORY
-
技術情報(598)
-
イベント(237)
-
カルチャー(60)
-
デザイン(70)
TAG
- 5G
- AI
- AI TALK
- AI 機械学習強化学習
- AI/機械学習
- AIエージェント
- AIコーディング
- AI人財
- AI駆動
- Behind the Scenes
- BIT VALLEY
- blockchain
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CNDO
- CNDT
- CODE BLUE
- ConoHa
- ConoHa VPS
- CSS
- CTF
- Designship
- developer
- DevRel
- DevSecOpsThon
- Docker
- DTF
- Engineering Journey
- expert
- EXPERT CROSS
- GMO AI&ロボティクス商事
- GMO AIR
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティ byイエラエ
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMO大会議
- GMO天秤AI
- Go
- GPUクラウド
- GTB
- Hack-1グランプリ
- IETF
- iOS
- IoT
- ISUCON
- Japan Drone
- JapanDrone
- Java
- JJUG
- K8s
- Kaigi on Rails
- Kids VALLEY
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- OpenStack
- Perl
- PHP
- PHPcon
- PHPerKaigi
- Python
- RFC
- RPA
- Ruby
- SECCON
- Selenium
- Spectrum Tokyo Meetup
- splunk
- SRE
- Takumi byGMO
- Terraform
- TypeScript
- UI/UX
- vibe
- VPN
- VS Code
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- お名前.com
- クリエイターインタビュー
- クリエイティブ
- コンテナ
- サイバーセキュリティ
- サマーインターン
- スクラム
- スペシャリスト
- セキュリティ
- ソフトウェアサプライチェーン
- チームビルディング
- デザイン
- ネットのセキュリティもGMO
- ハーネスエンジニアリング
- バックエンド
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- フロントエンド
- ペアリング暗号
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 京都大学
- 国際ロボット展
- 国際標準化
- 基礎
- 多拠点開発
- 大阪公立大学
- 宮崎オフィス
- 強化学習
- 応用
- 技育プロジェクト
- 技術広報
- 技術書典
- 拡張知能
- 新卒
- 新卒研修
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 機械学習
- 決済
- 生成AI
- 産学連携
- 研究開発
- 耐量子暗号
- 脆弱性診断
- 開発者
PICKUP
-

【開催レポート・後編】第6回 京大ミートアップ|集合的予測符号化から見る人間とAIの共生
技術情報
-

【開催レポート・前編】第6回 京大ミートアップ|フィジカルAIとAI時代の知性
技術情報
-
【EXPERT CROSS #2】暗号技術の可能性を未来につなぐ、「暗号のおねぇさん」の歩み(後編)
技術情報
-
【EXPERT CROSS #2】「暗号のおねぇさん」が国際標準化の場で残していく、インターネットへの「爪痕」(前編)
技術情報
-

デザインカンファレンス「Yoitoi Summit 2026」をGMOYours・フクラスにて開催!
デザイン
-

攻撃者優位の時代に問われる「使命感」 GMO Flatt Security&GMOサイバーセキュリティ byイエラエが描く、AI時代のセキュリティ構想(後編)ーEngineering Journey
技術情報
採用情報

SNS FOLLOW
