
GMOペパボ株式会社のデータ基盤チームは、社内外のデータを収集・統合して意味づけを行い、そこで得た情報を社内に循環させるという機能を担っています。GMOペパボは事業部制を採用し複数サービスを運営していますが、同チームは組織横断部門である技術部の1チームとして、他部門と連携しながら事業に貢献しています。GMOインターネットグループが12月6日(火)~7日(水)に渋谷フクラスおよびオンラインにて開催したテックカンファレンス「GMO Developers Day 2022」では、GMOペパボのデータ基盤チームの役割やデータ基盤「Bigfoot」のアップデート内容、データ活用を後押しする仕組みづくりについて、同チームの堤利史氏が紹介しました。
目次
登壇者
- 堤 利史
GMOペパボ株式会社
技術部データ基盤チーム シニアエンジニア

組織横断的な取り組みを行うデータ基盤チームのミッション
データ基盤チームは、データサイエンティスト1名、データアナリスト1名、データエンジニア3名で構成されており、下記のようなミッションを掲げ、データを切り口とした組織横断的な取り組みを行っています。
「ペパボ内のあらゆるデータに意味をつけ、そのデータによって意思決定の支援を行えるプラットフォームを構築し、ペパボの全パートナーに提供する。」
堤氏は、このミッションの言葉を紐解く形で、同チームの取り組みについて紹介していきました。
まずは「ペパボ内のあらゆるデータ」について。収集対象のデータを主に管理しているのは各事業部とCS室であり、データ基盤チームは必要なデータを収集する作業を担当しています。欲しいデータがない場合には、該当部門とともに新たにつくるという流れで作業を進めます。具体的なデータとしては、各事業用のデータベース、アクセスログや行動ログ、広告やSEOの運用に関わるデータなどといった事業データ、問い合わせデータおよび問い合わせ対応の業務記録といったCSデータがあります。これらのデータは社内のデータ基盤「Bigfoot」に集められます。
<参考>
・問い合わせ対応の生産性を計測・可視化する
https://tech.pepabo.com/2022/06/13/customer-service-productivity/
・ペパボのログ活用基盤『Bigfoot』を使った Zendesk のデータ可視化
https://tech.pepabo.com/2021/02/10/zendesk-data-visualization-with-bigfoot/
続いて「ペパボの全パートナーに提供」について。GMOペパボでは、自らSQLを書いたりダッシュボードをつくったりするパートナーが多いため、基本的にデータの提供はセルフサービス形式となっています。複雑な集計処理が必要な場合など、個別にやるよりも共通化したほうが効率的な場合にはデータ基盤チームが担当します。アクセス権限はTerraformで管理し、GitHub Enterprise Serverに対するプルリクエストでセキュリティ管理者へ申請する形となっており、3か月間利用していない権限があれば自動的に検知・停止されます。
「プラットフォームを構築」という言葉は、Bigfootを表しています。Bigfootは、主にGoogle Cloud Platform(GCP)を用いて構築されています。堤氏によると、GCPで提供されているサービスだけではニーズを叶えられない場合は、自社でOSSを開発して組み込むというスタンスを取っているといいます。
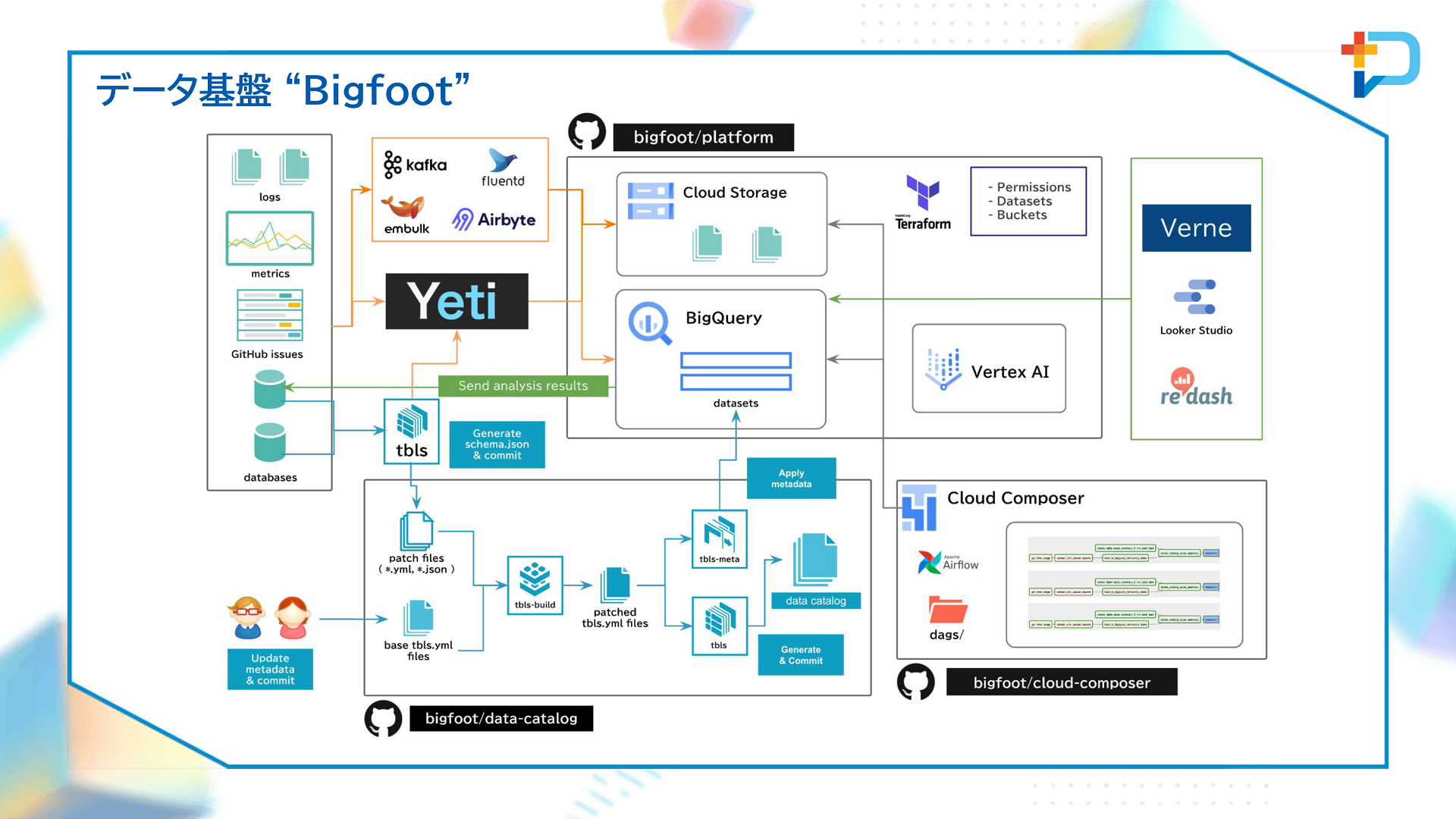
データ基盤「Bigfoot」のアップデート
Bigfootについては2021年のGMO Developers Dayでも紹介されています。そこで堤氏は、この1年間でのアップデート内容を中心に説明しました。
<参考>
・GMOペパボのサービスと研究開発を支えるデータ基盤の裏側
https://www.youtube.com/watch?v=Kxlchi9fa3I
データ基盤チームがまず取り組んだのは、データ抽出に特化した基盤「Yeti」の構築です。GMOペパボでは各事業部でRDBMSを運用していますが、データエンジニアリングに関するノウハウの蓄積と共有、マスキングやポリシータグ管理手法の共通化、事業を横断したデータ活用の推進という主に3つの目的に向けて、その共通基盤をつくりデータ抽出に特化した機能を持たせることにしました。
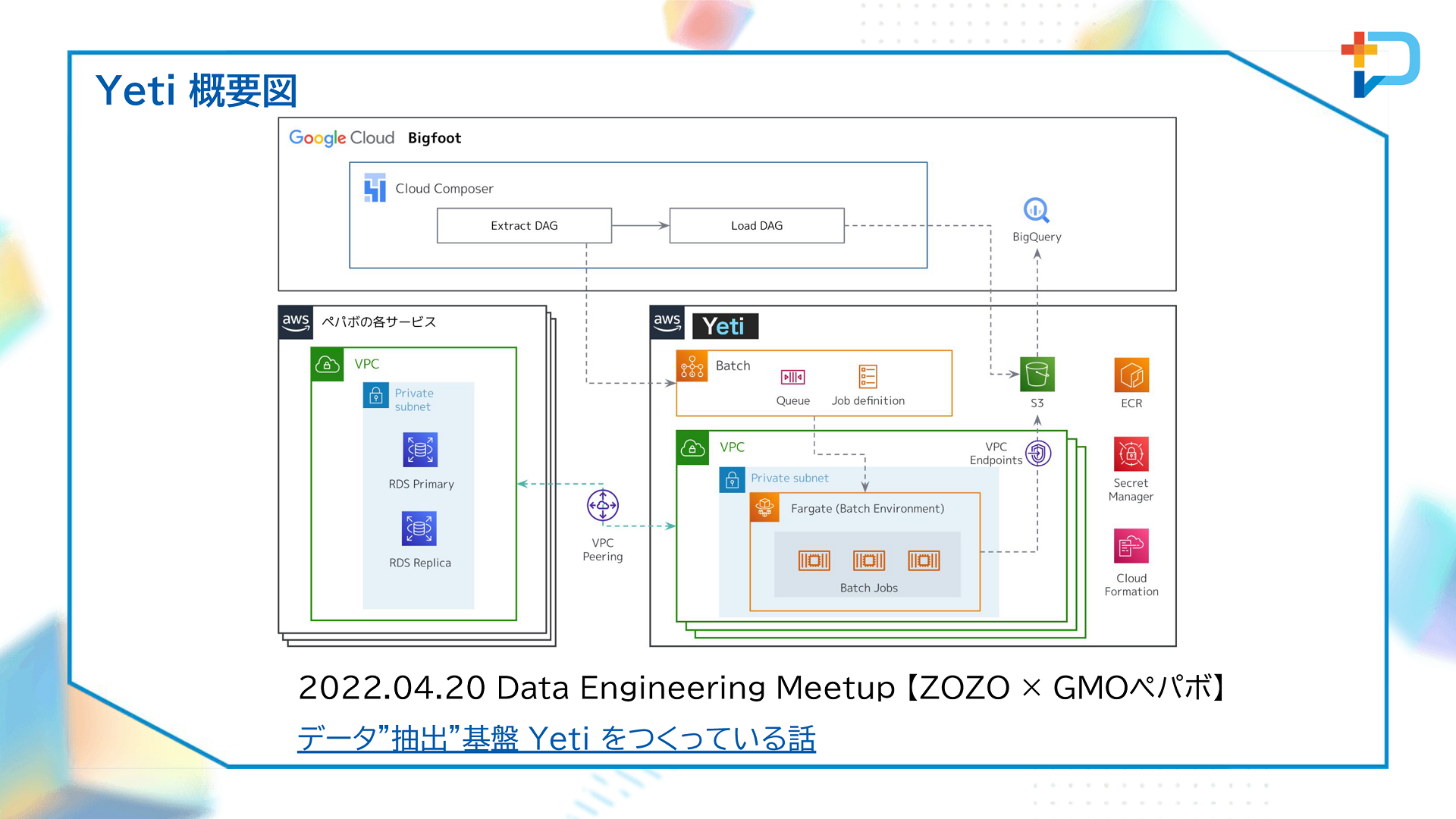
Yetiは基本的にAWSで構築されています。特長は、各事業のデータベースへアクセスする際にパブリックネットワークを一切利用していない点にあります。Yetiについては、2022年4月にZOZOと共催した「Data Engineering Meetup」で詳しく触れられています。
<参考>
・データ抽出基盤Yetiをつくっている話
https://speakerdeck.com/tosh2230/yeti-yet-another-extract-transfer-infrastructure
データ基盤チームは、生産性指標であるFour Keysの計測にも取り組みました。Four keysとは、Googleが考案したソフトウェア開発チームのパフォーマンスを示す下記4つの指標です。
- デプロイの頻度(組織による正常な本番環境へのリリースの頻度)
- 変更のリードタイム(commitから本番環境稼働までの所要時間)
- 変更障害率(デプロイが原因となり本番環境で障害が発生する割合)
- サービス復元時間(組織が本番環境での障害から回復するのに掛かる時間)
Four Keysは事業や期間別にダッシュボード上に可視化され、誰でも閲覧できるようになっているといいます。
<参考>
・エンジニアの活動情報からFour Keysを集計、可視化した話
https://tech.pepabo.com/2022/01/06/four-keys-dashboard/
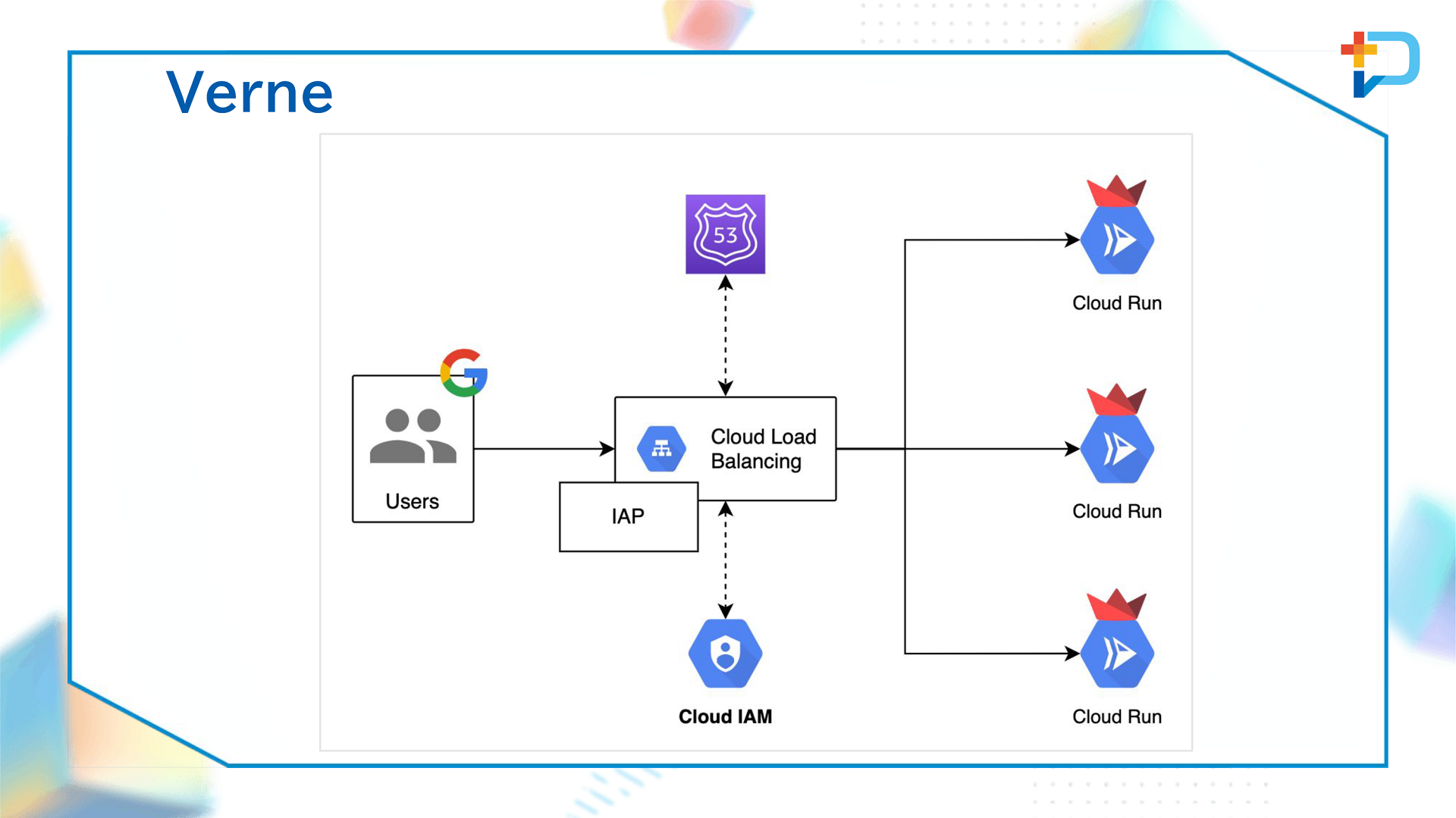
また、Four Keysの可視化がきっかけとなり、データ基盤チームは汎用Webアプリケーション基盤「Verne」の構築も行いました。Verneは、Cloud Load Balancing、Cloud Run、IAPをつなぎ合わせたものであり、Four KeysダッシュボードはVerneで稼働している形となります。現在では、GoogleアナリティクスのUTMパラメーターが適切に設定できているかチェックできるツールなど、ダッシュボード以外のアプリケーションもVerne上で働いているといいます。
機械学習の活用も進んでいます。ハンドメイド通販サービス「minne」では、作品情報がアップロードされた際に、Apache Beamで説明文の形態素解析を行い、Vertex AIでトピックモデリングを行うという取り組みを行っています。こちらも、2022年4月にZOZOと共催した「Data Engineering Meetup」のなかで紹介されました。
<参考>
・BigQueryの日本語データをDataflowとVertexAIでトピックモデリング
https://speakerdeck.com/zaimy/topic-modeling-of-japanese-data-in-bigquery-with-dataflow-and-vertex-ai
また、オリジナルグッズの作成・販売サービス「SUZURI」には、バンディットアルゴリズムが実装されています。バンディットアルゴリズムは、静的A/Bテストで発生しうる機会損失を防ぐもので、minneでもすでに導入済みです。堤氏は、「バンディットアルゴリズムを複数の機能に適用していき、サービスを改善していきたい」と話していました。
データ活用を後押しする仕組み
データ活用をするうえでは、データ品質が重要となります。データ基盤チームは、データ品質を向上するための取り組みとして3つのアプローチを取っています。
1つめは、データカタログです。GMOペパボでは、tblsというツールを用い、BigQueryにあるテーブル・列のDescriptionをGitHub Enterprise Serverのリポジトリで管理して誰でも更新できるようにしています。各事業部のRDBMSで利用している場合は、データ収集時にカタログも同期するという使い方ができます。
2つめはデータバリデーションです。データバリデーションは、Load/Transformとテーブルの状態確認の2種類です。前者では、Cloud Composer DAGでBigQueryのASSERT文を実行し、実行したジョブによるデータ操作が期待どおりであるかどうかを検査します。後者は、Querygazerをベースに「Shoegazer」というWebアプリを独自で構築。テーブルに格納されたレコード全体をみて、利用者が期待する状態であるかを定期的にRSpecで検査しています。
3つめはデータリネージです。データリネージでは、堤氏が開発した「Stairlight」というツールを使っています。これは、Cloud Composerにデプロイしているソースコード群からSQLを解析してデータのつながりを見つけるというもので、堤氏によるとVerneやRedashに入っているクエリなどにも展開できるといいます。
また、データ基盤チームでは、データ活用を後押しする取り組みとしてSQLパフォーマンス改善サポートも行っています。具体的には、RedashなどのBIツールにおけるSQL実行履歴から所要時間を確認して、より効率的なクエリになるようデータ基盤チームで支援するというものです。Redashであれば、データが格納されているPostgreSQLからクエリ実行履歴をYetiで抽出し、BigQueryにロード。これをVerneでモニタリングしていきます。
他部門とのさらなる連携とMLOps基盤の構築を目指す
講演の最後に、堤氏は「Bigfootが抱えるデータの量・種類が増えていくと、さらなる組織横断的な動きが求められる。連携をより強化するなかで、収集・付与するデータのバリエーションも増やしていきたい」と今後の展望について語りました。さらに、MLOps基盤の構築を進めていく考えについても次のように話していました。
「現在、機械学習を行いたい場合には各事業部で個別に対応しているが、今後はデータ基盤チームが中心となって基盤という形で共通化して使えるようにしていきたい。具体的には、機械学習パイプラインの整備と展開を進める。また、データリネージとモデルモニタリングを統合して、一気通貫で確認できるようにもしていければ」(堤氏)
アーカイブ
映像はアーカイブ公開しておりますので、
まだ見ていない方、もう一度見たい方は 是非この機会にご視聴ください!
ブログの著者欄
技術広報チーム
GMOインターネットグループ株式会社
イベント活動やSNSを通じ、開発者向けにGMOインターネットグループの製品・サービス情報を発信中
採用情報


関連記事
-

【イベントレポート・後編】GMO Developers Day 2025 -Creators Night-|共創するデザイン組織と次世代クリエイターの可能性
デザイン
-

【イベントレポート・中編】GMO Developers Day 2025 -Creators Night-|変化に挑むクリエイターのキャリアと成長
デザイン
-

【イベントレポート・前編】GMO Developers Day 2025 -Creators Night-|AI時代の「クリエイティブ」を探る夜
デザイン
-

Google Workspace カードが店頭販売の棚に並ぶ!~リリースを支えるSagaパターンの分散トレーシングとコンテキスト管理~
技術情報
-

配信コメントのストリーミング処理における、WebSocketとSSEの両立と設計について
技術情報
-

Dify × GASで実現する実用的なAIシステム – Gmail自動返信の事例 –
技術情報

KEYWORD
CATEGORY
-
技術情報(573)
-
イベント(218)
-
カルチャー(55)
-
デザイン(58)
-
インターンシップ(2)
TAG
- "eVTOL"
- "Japan Drone"
- "ロボティクス"
- "空飛ぶクルマ"
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI 機械学習強化学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI駆動
- AMD
- APT攻撃
- AWX
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CM
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- CS
- CSS
- CTF
- DC
- design
- Designship
- Desiner
- DeveloperExper
- DeveloperExpert
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- Excel
- Expert
- Experts
- Felo
- GitLab
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Developers ブログ
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOイエラエ
- GMOインターネット
- GMOインターネットグループ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOサイバーセキュリティ大会議&表彰式
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- Go
- GPU
- GPUクラウド
- GTB
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- オブジェクト指向
- オンボーディング
- お名前.com
- カルチャー
- クリエイター
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- ゼロトラスト
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 基礎
- 多拠点開発
- 大学授業
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 第3回GMO大会議・春 サイバーセキュリティ2026
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 階層ベイズ
- 高機能暗号
PICKUP






採用情報
SNS FOLLOW
