
GMOインターネットグループが、12月6日(火)~7日(水)の2日間にわたり開催した「GMO Developers Day 2022」。東京・渋谷フクラスにおけるリアル登壇とオンライン配信のセッションを組み合わせたハイブリッドで開催された今回のイベントでは、Web3、AI、セキュリティ、クリエイティブといった「技術の拡張(Add on)」を、スペシャリストたちが紹介しました。
今回はその中から、「プライバシー保護連合学習技術と活用方法について」と題したオンラインセッションをお届けします。登場するのはGMOサイバーセキュリティ byイエラエ株式会社から、AI開発部スペシャリストの伊藤一明です。
目次
登壇者
- 伊藤 一明
GMOサイバーセキュリティ by イエラエ株式会社
AI開発部 スペシャリスト

連合学習に暗号技術を「Add on」したDeepProtect
インターネット技術の中でもサイバーセキュリティなどに関する事業を展開するGMOサイバーセキュリティ byイエラエ。「誰もが犠牲にならない社会を創る~デジタルネイティブの時代を生きるすべての人が安全に暮らせる社会作りに貢献します~」をミッション&バリューとして掲げています。
現代の課題の1つとして、伊藤は「複数の組織がデータを持ち寄って分析しないと解決できない課題に対して、データを共有したり開示したりできないという二律背反がある」と指摘します。
これを解決するための技術としてイエラエ社が社会実証・ビジネス化を進めているのが、連合学習と呼ばれる機械学習の手法に、暗号化したまま計算できる特性を持つ準同型暗号を「アドオン」したプライバシー保護連合学習技術である「DeepProtect」です。複数の組織が持つデータセットを互いに秘匿し、プライバシーや機密性を保ったまま共同で機械学習を行える、独自のプライバシー保護連合学習技術となります。
では、そのDeepProtectとはどんな技術でしょうか。
鍵となる技術である「連合学習」は、2017年にGoogleが提唱した機械学習モデルの手法です。Googleでは、キーボードアプリである「Gboard」の予測変換の精度向上に活用しています。
この技術は、機械学習に必要な学習用データを、1つの拠点やサーバに集約せずに作成できるという点が最大の特徴です。散在した学習用データを使っても、作成されたモデルは集約した場合と同等の性能があるとされています。
例えばGboardでは、各スマートフォン上で入力されたテキストデータと入力サジェストのクリック状況等から学習データを生成するのですが、キーボードで入力された文字列やクリック状況は機密性の高いデータになります。この学習データから機械学習を実行し更新モデルを作成するのですが、ここまではGboardをインストールしたスマートフォン内で行われ、学習データはローカルにとどまっています。
その後、更新モデルの差分情報のみがクラウドに送信され、他のユーザーの更新モデルと平均化されて、すべてのユーザーで共有する共有モデルを作成、改善されたモデルを再び共有します。これが個々のスマートフォンにダウンロードされて、再びローカルでの改善、更新モデルの作成に活用されます。これが繰り返されることで、キーボード入力の予測精度が向上する、というのがGboardの連合学習です。学習データ自体はスマートフォン内にとどまり、サーバに集約する必要がありません。
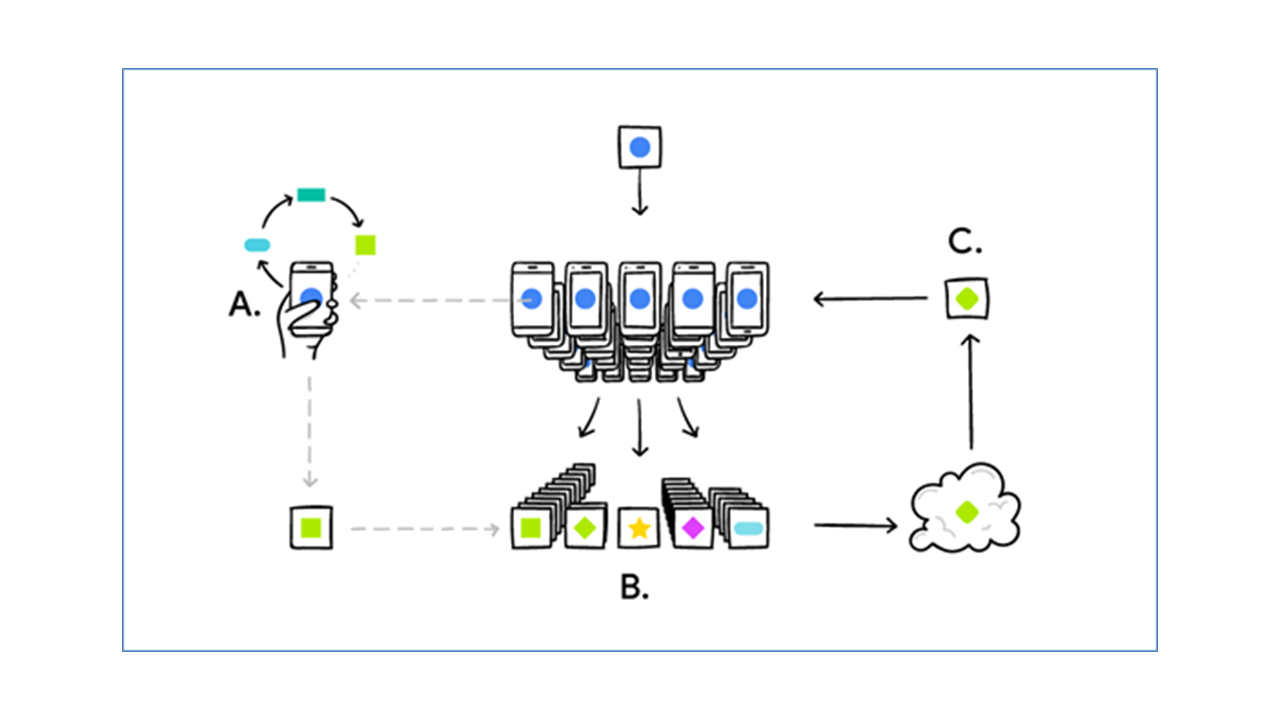
このように、学習モデルを作成する際には個人情報を含むデータの送信が行われず、学習によって得られた差分パラメータ(勾配情報)のみを送信することで、個人情報などの機密データを開示することなく学習モデルを構築できるのが連合学習です。
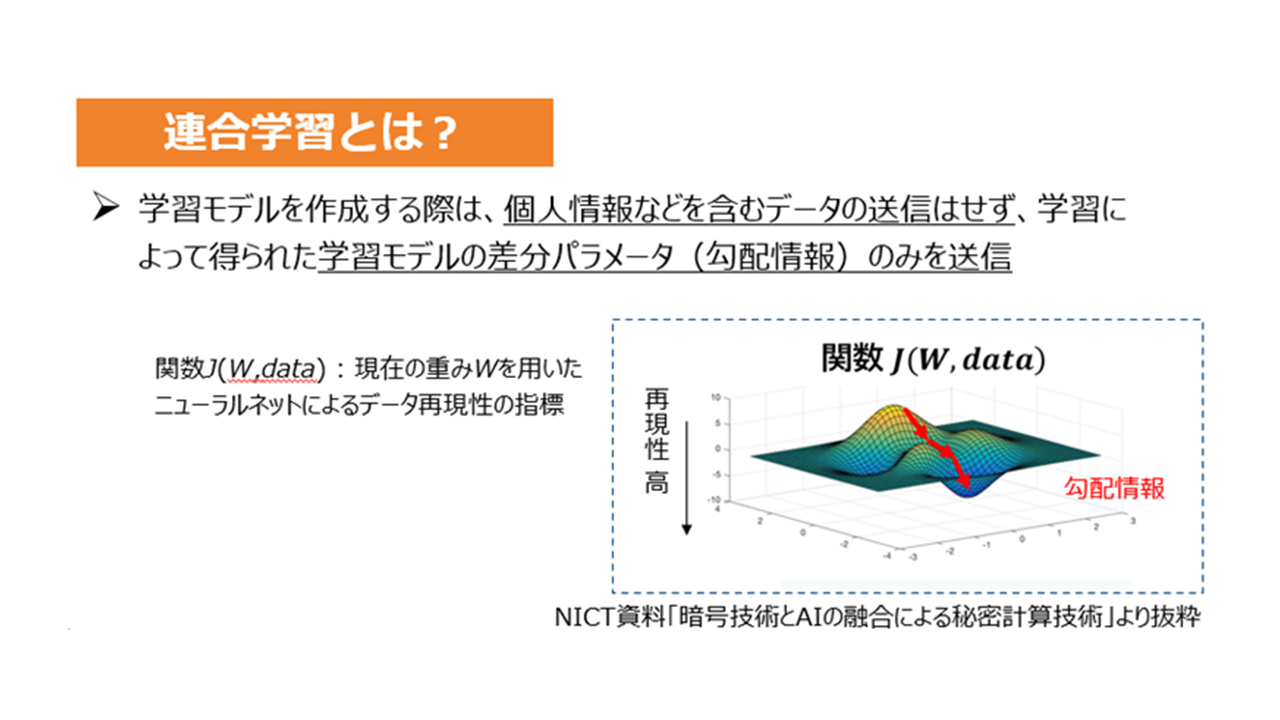
送信されるのは、プライバシーに関わるような個人情報などではなく、学習モデルの差分パラメータ(勾配情報)のみになります
これに「アドオン」する準同型暗号は、その名の通り代数学で知られる「準同型(homomorphic)」の性質を持った暗号方式です。暗号化されたデータに対して加算や乗算といった演算を行った場合、復号した結果が、暗号化しない場合と同じデータ演算結果になる暗号方式です。
例えばEnc(m_1)とEnc(m_2)という暗号化されたデータがあった場合、復号をしない状態でEnc(m_1+m_2)、Enc(m_1×m_2)といった計算が可能で、復号した結果は、もともとの暗号化されていないデータの演算結果と同じとなっています。こうした特性から、暗号化した状態で中身を隠したままデータ処理ができるわけです。
連合学習技術と準同型暗号を組み合わせると、学習モデルの勾配情報を暗号化したまま計算して、その結果を集約して更新するため、データの漏えいを防ぐことができます。送信されるのが勾配情報に限られる上にそのデータは暗号化されているので、中身を見ることができないからです。

厳格なセキュリティ、プライバシー保護によって、組織を横断したデータの利活用が妨げられるという課題に対して、プライバシー保護連合学習技術の「DeepProtect」であれば、個人情報などの機密性の高いデータを開示しなくても、組織を横断したデータ利活用が可能になります。
金融機関における不正取引検知で利用に期待
実例を見てみましょう。JST CRESTでの実証実験として、金融機関における不正取引検知でDeepProtectが活用されました。複数の銀行のデータを使って不正検知の学習モデルを作成するには、これまでは各銀行のデータを集約する必要がありました。口座情報や取引履歴などが含まれるため、通常は外部に出せない情報です。
DeepProtectでは、各銀行内で学習したモデルの勾配情報のみを暗号化し、中央サーバへアップロードします。中央サーバでは集約された勾配情報を、準同型暗号によって暗号化されたまま統合し、集約された勾配情報として更新をします。
各銀行では、この更新された学習モデルをダウンロードして、それぞれの学習モデルをまた更新します。このサイクルを繰り返すことで、精度の高い学習モデルが共同で構築できます。1つの銀行のデータだけではなく、複数の銀行のデータによる連合学習モデルを構築することで、より精度の高い不正取引検知ができるというわけです。
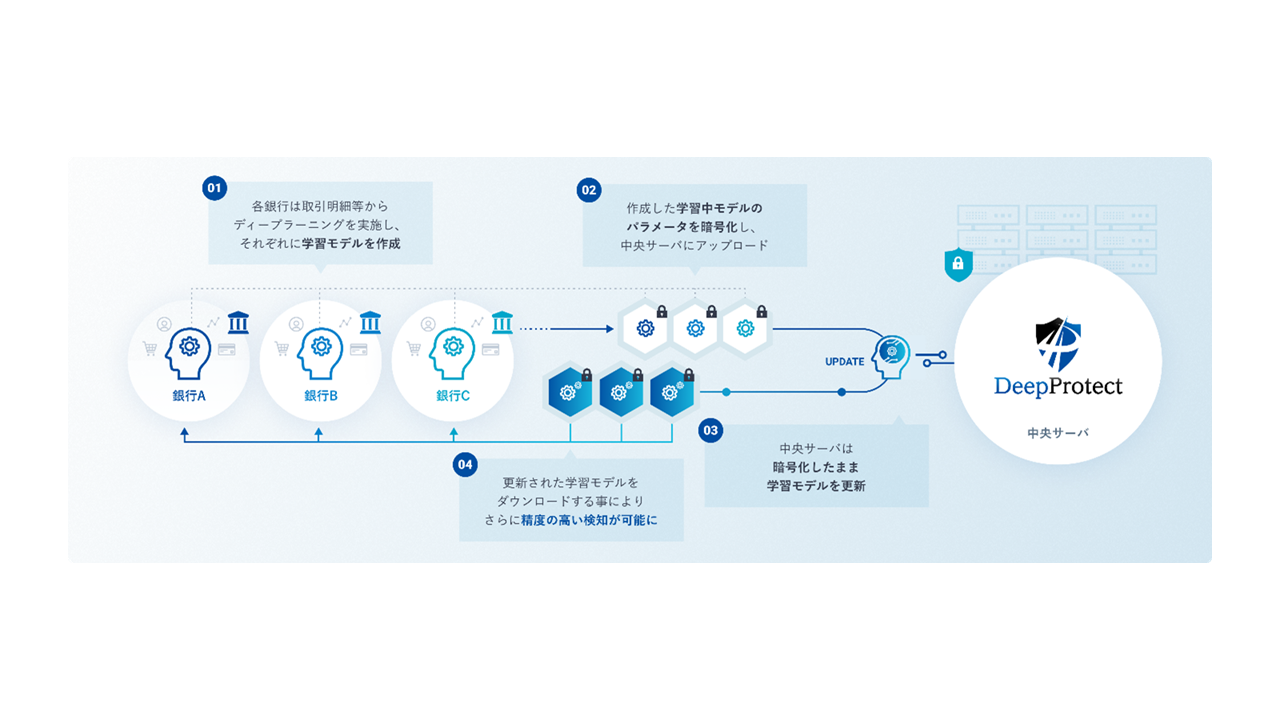
実データ自体は外部に送信されず、あくまで差分パラメータという勾配情報のみが、しかも暗号化されたまま処理されるため、データの機密性やプライバシーが確保されているというのがメリットです。
実証実験の結果は、各銀行での被害取引の検知率で比較されています。1つの銀行のデータだけを用いた個別学習モデルと、DeepProtectの連合学習モデルを使った検知精度の比較では、検知率が個別の84%に対して85.3%と、1.3ポイントの向上が見られました。個別学習モデルでは検知できなかった不正取引が検知された事例も確認されました。
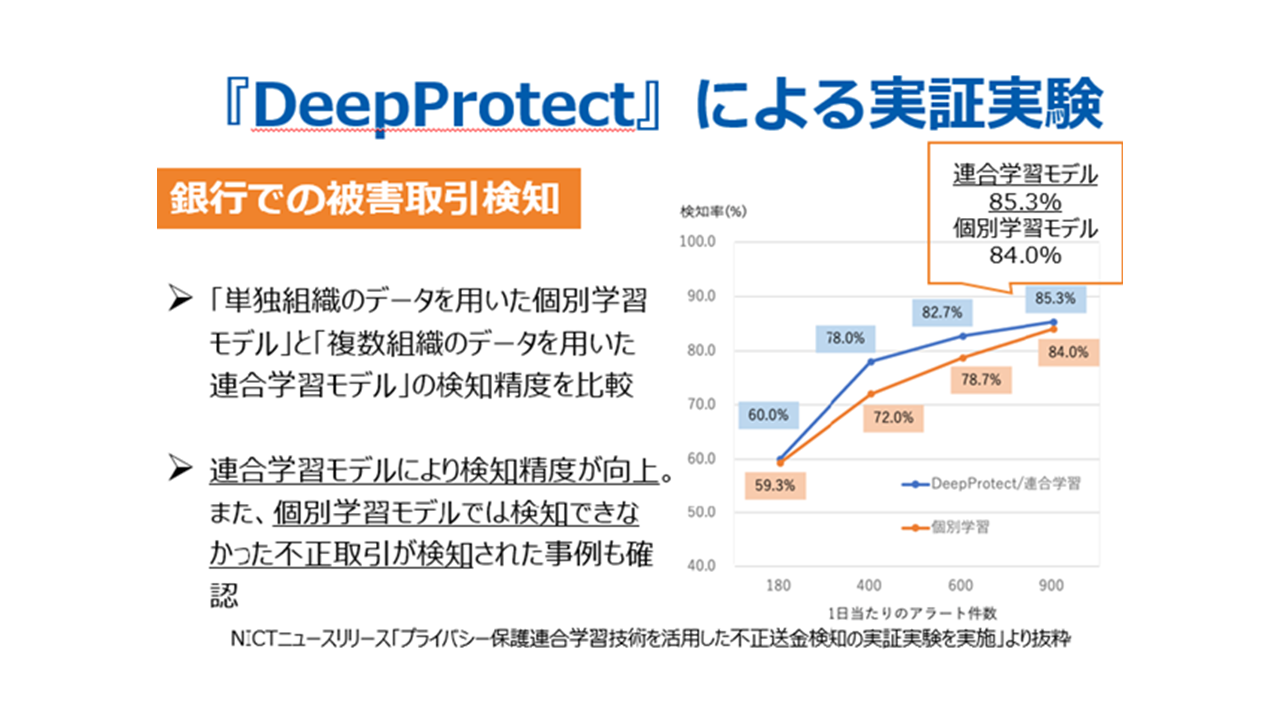
銀行における不正取引の被害額は、把握されているものだけで約300億円程度とみられており、1ポイントの向上で3億円程度の不正が防げるということになります。表に出ている被害額は氷山の一角とも言われていますので、実際はもっと被害額を減らせる効果があると考えられます。
実証実験で示されたDeepProtectの高いポテンシャル
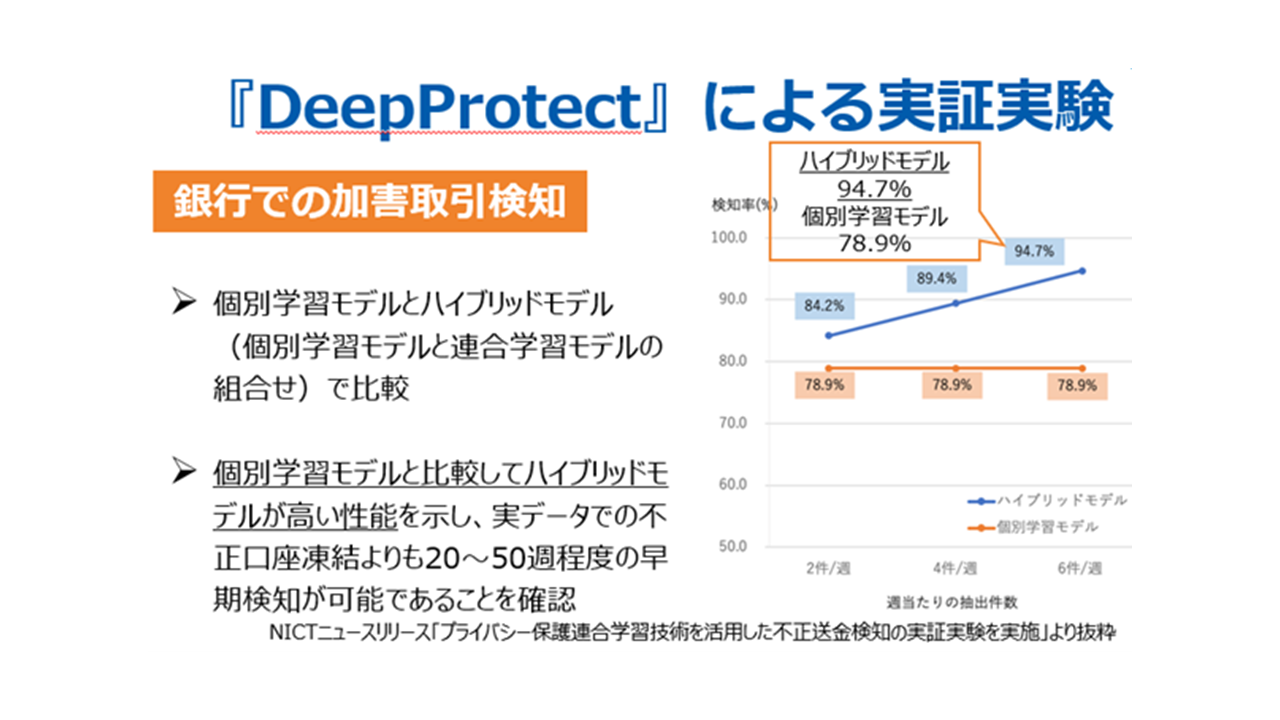
不正取得された口座が振り込め詐欺などの金融犯罪に使われる、といった加害取引検知の実証実験では、個別学習モデル単独と、個別学習モデルと連合学習モデルを組み合わせたハイブリッドモデルで検証。加害取引が検知されるとその口座を凍結するのですが、その口座凍結が個別学習モデルと比べて20~50週程度、早く検知できていたそうです。検知率も個別学習モデルで78.9%が、ハイブリッドモデルだと94.7%で15.8ポイントの向上。実証実験によって、DeepProtectの高いポテンシャルが証明されました。
金融機関に対する攻撃は複雑化、巧妙化しています。マネーロンダリングや不正送金、振り込め詐欺などが相次ぐ中、単独のデータだけでは不正対策が間に合わなくなっています。複数の金融機関にまたがってデータの解析を行うことで、不正の検知率が向上すれば、犯罪を未然に防ぐ可能性が高まります。
そのほかにも様々な分野での応用が期待されます。例えば医療・ライフサイエンスの分野では、ウェアラブルデバイスの普及で計測できるバイタルデータが急拡大。電子カルテシステムなどの環境整備も進み、大量のデータが収集されています。こうした極めて機密性の高いデータでも、セキュアに複数の機関やデバイスをまたいだ統合分析が可能になり、医療やライフサイエンスの進歩に貢献できる、と伊藤は話します。
マーケティング分野では、単独企業だけでなくグループ企業や業界内を横断した豊富なデータをベースにした学習モデルを構築。詳細なインサイトやターゲットの発見といった精度の高い分析の実現が期待できる、としています。
製造現場でも貢献できそうです。IoTの導入が進んだ製造現場では、AIを使ったデータ分析も始まっています。これによって、設備などの故障予知、部品の品質管理、製品の異常検知などの分野で活用が期待されています。こうした分析には、1社、1工場のデータだけでは不十分なので、複数企業の工場データを活用できるDeepProtectが「課題解決を支援します」と伊藤は言います。
サービスの分野にも応用できます。電力やガスなどの公益サービスでの需給バランスの最適化、自動翻訳、スパムメールの検出、カスタマーサービスのチャットボット、バーチャルアシスタントサービス、自律走行を制御する車両運行システムなど、伊藤は様々なサービスでの利用を例に挙げ、広く活用が期待できるとアピールします。
さいごに
もともと今回の技術「DeepProtect」は、発明した情報通信研究機構(NICT)から技術移転された(ニュースリリース:https://www.nict.go.jp/press/2022/03/17-1.html)もので、サイバーセキュリティや暗号技術、機械学習に関して高い技術力を持つことからイエラエ社が移転先として選ばれました。社会実証やビジネス化を進めていますが、伊藤は、幅広い分野の多くの課題を解決できる可能性がある技術として、「今後に是非とも期待して欲しい」と締めくくりました。
アーカイブ
映像はアーカイブ公開しておりますので、
まだ見ていない方、もう一度見たい方は 是非この機会にご視聴ください!
ブログの著者欄
技術広報チーム
GMOインターネットグループ株式会社
イベント活動やSNSを通じ、開発者向けにGMOインターネットグループの製品・サービス情報を発信中
採用情報

関連記事
-

デザインコンテスト「GMO DESIGN AWARD 2026」開催決定!3年目のテーマは「トキメキ」
デザイン
-

【第2回・AI TALK】GMOサイバーセキュリティ byイエラエ・三村 聡志さんに聞く、AI時代の攻撃と防御のいま
技術情報
-

【イベントレポート・後編】GMO Developers Day 2025 -Creators Night-|共創するデザイン組織と次世代クリエイターの可能性
デザイン
-

【イベントレポート・中編】GMO Developers Day 2025 -Creators Night-|変化に挑むクリエイターのキャリアと成長
デザイン
-

【イベントレポート・前編】GMO Developers Day 2025 -Creators Night-|AI時代の「クリエイティブ」を探る夜
デザイン
-

GMO Developers Day 2025 -Creators Night-開催決定!
デザイン

KEYWORD
CATEGORY
-
技術情報(594)
-
イベント(236)
-
カルチャー(60)
-
デザイン(69)
TAG
- 「Guard」機能
- 「Runner」機能
- 5G
- Adam byGMO
- AdventCalender
- AGI
- AI
- AI TALK
- AI 機械学習強化学習
- AI/機械学習
- AIエージェント
- AIコーディング
- AIコーディングエージェント
- AI人財
- AI活用事例
- AI駆動
- AMD
- APT攻撃
- AWX
- Behind the Scenes
- BIT VALLEY
- Blade
- blockchain
- Canva
- ChatGPT
- ChatGPT Team
- Claude Team
- cloudflare
- cloudnative
- CloudStack
- CNDO
- CNDT
- CODEBLUE
- CODEGYM Academy
- ConoHa
- ConoHa VPS
- ConoHa、Dify
- ConoHaVPS
- CS
- CSS
- CTF
- DC
- Designship
- Desiner
- developer
- DevRel
- DevSecOpsThon
- DiceCTF
- Dify
- DNS
- Docker
- DTF
- engineering
- Engineering Journey
- eVTOL
- expert
- EXPERT CROSS
- Felo
- GitLab
- GMO AI&ロボティクス商事
- GMO AIR
- GMO AIロボティクス大会議&表彰式
- GMO DESIGN AWARD
- GMO Developers Day
- GMO Developers Night
- GMO Flatt Security
- GMO GPUクラウド
- GMO Hacking Night
- GMO kitaQ
- GMO SONIC
- GMOアドパートナーズ
- GMOアドマーケティング
- GMOインターネット
- GMOインターネットグループ
- GMOインターネットグループ陸上部
- GMOインターネットグループ陸上部 – GMOロボッツ
- GMOクラウド]
- GMOグローバルサイン
- GMOコネクト
- GMOサイバーセキュリティ byイエラエ
- GMOサイバーセキュリティbyイエラエ
- GMOサイバーセキュリティ大会議
- GMOソリューションパートナー
- GMOデジキッズ
- GMOブランドセキュリティ
- GMOペイメントゲートウェイ
- GMOペパボ
- GMOメディア
- GMOリサーチ
- GMO大会議
- GMO天秤AI
- Go
- Good Morning
- GPU
- GPUクラウド
- GTB
- Hack-1グランプリ
- Hack‐1グランプリ
- Hardning
- Harvester
- HCI
- INCYBER Forum
- iOS
- IoT
- ISUCON
- Japan Drone
- JapanDrone
- Java
- JJUG
- JJUG CCC
- K8s
- Kaigi on Rails
- Kids VALLEY
- KidsVALLEY
- Linux
- LLM
- MCP
- MetaMask
- MySQL
- NFT
- NVIDIA
- NW構成図
- NW設定
- Ollama
- OpenStack
- Perl
- perplexity
- PGP
- PHP
- PHPcon
- PHPerKaigi
- PHPカンファレンス
- Python
- QUIC
- Rancher
- RPA
- Ruby
- SECCON
- Selenium
- Slack
- Slack活用
- Spectrum Tokyo Meetup
- splunk
- SRE
- sshd
- SSL
- Takumi byGMO
- Terraform
- TLS
- TypeScript
- UI/UX
- vibe
- VLAN
- VPN
- VS Code
- Webアプリケーション
- WEBディレクター
- XSS
- ZTNA
- アドベントカレンダー
- イベントレポート
- インターンシップ
- インハウス
- エージェンティックAI
- オブジェクト指向
- オンボーディング
- お名前.com
- クリエイター
- クリエイターインタビュー
- クリエイティブ
- コーディング
- コンテナ
- サイバーセキュリティ
- サマーインターン
- システム研修
- スクラム
- スペシャリスト
- セキュリティ
- セキュリティ診断
- ゼロトラスト
- ソフトウェアサプライチェーン
- ソフトウェアサプライチェーン攻撃
- ソフトウェアテスト
- チームビルディング
- デザイナー
- デザイン
- テスト
- ドローン
- ネットのセキュリティもGMO
- ネットワーク
- ハーネスエンジニアリング
- バックエンド
- ビジネス職
- ヒューマノイド
- ヒューマノイドロボット
- フィジカルAI
- プログラミング教育
- ブロックチェーン
- フロントエンド
- ベイズ統計学
- マイクロサービス
- マルチプレイ
- ミドルウェア
- モバイル
- ゆめみらいワーク
- リモートワーク
- レンタルサーバー
- ロボット
- ロボティクス
- 京大ミートアップ
- 人材派遣
- 出展レポート
- 動画
- 協賛レポート
- 国際ロボット展
- 基礎
- 多拠点開発
- 宮崎オフィス
- 展示会
- 広告
- 強化学習
- 形
- 応用
- 情報伝達
- 技育プロジェクト
- 技術広報
- 技術書典
- 技術書典20
- 採用
- 採用サイトリニューアル
- 採用活動
- 新卒
- 新卒研修
- 日本科学未来館
- 映像
- 映像クリエイター
- 映像制作
- 暗号
- 業務効率化
- 業務時間削減
- 機械学習
- 決済
- 物理暗号
- 生成AI
- 空飛ぶクルマ
- 脆弱性診断
- 色
- 視覚暗号
- 開発生産性
- 開発生産性向上
- 開発者
- 階層ベイズ
- 高機能暗号
PICKUP
-

攻撃者優位の時代に問われる「使命感」 GMO Flatt Security&GMOサイバーセキュリティ byイエラエが描く、AI時代のセキュリティ構想(後編)ーEngineering Journey
技術情報
-

頂上と裾野の両方から「底上げ」 GMO Flatt Security&GMO サイバーセキュリティ byイエラエが支える、日本のサイバーセキュリティ(前編)ーEngineering Journey
技術情報
-

【開催レポート】八幡小学校 社会科見学 at GMO kitaQ
カルチャー
-
デザインコンテスト「GMO DESIGN AWARD 2026」開催決定!3年目のテーマは「トキメキ」
デザイン
-

ソフトウェアサプライチェーン攻撃から「エンジニアの背中」を守る。Takumi byGMO・「Guard」機能「Runner」機能 開発の舞台裏ーEngineering Journey
技術情報
-

【後編】Hack-1グランプリ2026 デモデーレポート|グランプリ&オーディエンス賞をW受賞!オンライン部門優勝チームにインタビュー
デザイン
採用情報

SNS FOLLOW
